OCaml
OCaml זאת שפת תכנות נוחה לתכנות פונקציונלי אם כי היא תומכת בתכנות מונחה עצמים גם כן.
OCaml ותכנות פונקציונלי ככלל ישמש את הצעד הראשונה לכניסה אל מאחורי הקלעים של שפות תכנות, פרדיגמות וקונבנציות שמשתמשים בהם כאשר ניגשים לעבוד עם שפות תכנות או לפתח אחת כזו.
חמשת הזוויות של שפות תכנות
לפני שנכנס ל OCaml עצמה. חשוב להכיר את חמשת האספקטים של שפות תכנות:
syntax - מילות מפתח, הגדרות, סימונים. כיצד שפת התכנות בנויה ברמה הבסיסית ביותר.
semantics - החוקים הלא כתובים שקובעים את האופן בו התוכנה תרוץ ותתנהג. כשמדברים על סמנטיקה מתייחסים לשני אספקטים. הדינמית שמתארת את ההתנהגות בזמן ריצה של התוכנית. ו הסטטית שקשורה לבדיקות בזמן קומפילצייה.
idioms- קונבנציות שבהם מפתחים מנוסים משתמשים כדי לתאר התנהגות מסוימת באמצעות השפה.
libraries- מהם הכלים שמפתחים אחרים פיתחו שעומדים ברשותך. יכול לעזור בבחירת שפה מתאימה עבור פרוייקט מסויים.
Tools- קומפיילר, אינטרפטר, IDE וכו׳
The OCaml Toplevel
הTopLevel הוא כמו מחשבון או CLI ל-OCaml. זה דומה ל-JShell עבור Java, או הinterpreter האינטראקטיבי של Python. הוא שימושי לניסיון של פיסות קוד קטנות מבלי לטרוח ולהפעיל את מהדר OCaml. אבל אל תסתמכו על זה יותר מדי, כי יצירה, קומפילציה ובדיקה של תוכניות גדולות ידרשו כלים חזקים יותר. שפות אחרות יקראו לרמה העליונה REPL, אשר מייצג read-eval-print-loop: הוא קורא קלט מתכנת, מעריך אותו, מדפיס את התוצאה ואז חוזר. המומלץ ביותר עבור OCaml הוא utop
Expressions, Values and Types
בתכנות פונקציונלי ובפרט ב OCaml. היחידה הבסיסית ביותר של תוכנית נקראת expression.
שפות תכנות שכאלה נקראות expression oriented. בעולם הImperative Programming שפות כאלה נקראת command oriented.
תוכניות בOCaml הן בעצם expressions, כלומר, הצהרות בקוד לא מתארות פעולות שצריך לבצע על data כלשהו כמו בשפות אחרות אלא הקומפיילר מבצע evaluation בזמן ריצה של הביטויים שבסופם מתקבל ערך (value).
כל expression מורכב מ:
- syntax
- semantics:
- type - checking (static semantics)
- evaluation rules (dynamic semantics)
אפשר להסתכל על value כ expression שלא צריך חישוב דינמי
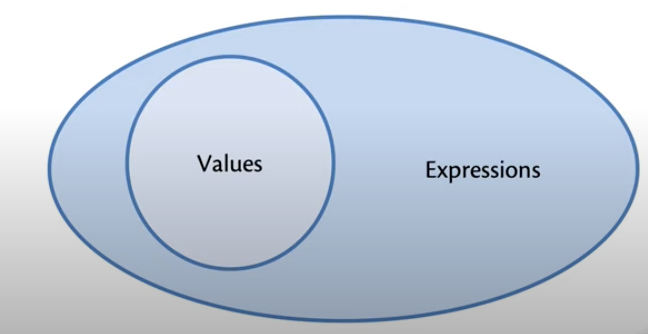
נסתכל על דוגמה פשוטה:
# 42;;
- : int = 42
כאשר נרשום ב utop את השורה ;;42 נקבל את הפלט הנ״ל. ננתח אותו מימין לשמאל
א) 42 זה הvalue
ב) int זה הטיפוס של הvalue.
ג) כיוון שלא הגדרנו שום שם לערך הוא יקבל symbol דיפולטי -
דוגמאות נוספות:
# "Every expression has a type";;
- : string = "Every expression has a type"
# 2 * 21;;
- : int = 42
# int_of_float;;
- : float -> int = <fun>
# int_of_float (3.14159 *. 2.0);;
- : int = 6
# fun x -> x * x;;
- : int -> int = <fun>
# print_endline;;
- : string -> unit = <fun>
# print_endline "Hello!";;
Hello!
- : unit
האריתמטיקה של float ב OCaml שונה בסינתקס שלה מהאריתמטיקה של integers, בניגוד לשפות אחרות אם נרצ לבצע אריתמטיקה בין floats נצטרך להוסיף נקודה אחרי הפעולה למשל .* יהווה כפל בין מספרים עם נקודה עשרונית. ההחלטה לעשות זאת היא design choice של המפתחים כדי למנוע overload של אופטורים ולמנוע דו משמעות.
הטיפוס של ביטוי לפני evaluation והטיפוס של הערך הנוצר לאחר חישוב הביטוי הם זהים. בצורה זו הקומפיילר לא צריך לבדוק בזמן ריצה את הטיפוסים. ב OCaml הקומפיילר משמיט את המידע על הטיפוס כך שהוא כלל לא זמין בזמן ריצה. הקונספט הזה נקרא subject reduction
הקומפיילר של OCaml מבצע הבחנה לטיפוסים (type inference) כלומר אנחנו לא מחוייבים להצהיר על הטיפוס מפורשות (למשל כמו ב Java). החישוב של הטיפוסים נעשים בזמן קמפול ותהיה שגיאה אם לא ניתן להעריך מהו הטיפוס בזמן קימפול. גם ב OCaml אפשר להצהיר על הטיפוס מפורשות, באמצעות הסינטקס
Let Definition
היכולת להצמיד value ל name (בשפות אחרות, הצהרת משתנה).
חשוב לשים לב שכאן, בגלל הסיבה שאנחנו עובדים בתכנות פונקציונלי, ברגע שהצהרתי על משתנה ערכו נשאר קבוע. ב OCaml מצהירים באמצעות let למשל let x = 42.
אם נריץ את זה ב utop נקבל val x : int = 42. כלומר הפלט הוא val שערכו הוא 42 והשם שלו הוא
definition אינם expressions אלא מכילים ביטוי בצורה סינתקטית בלבד
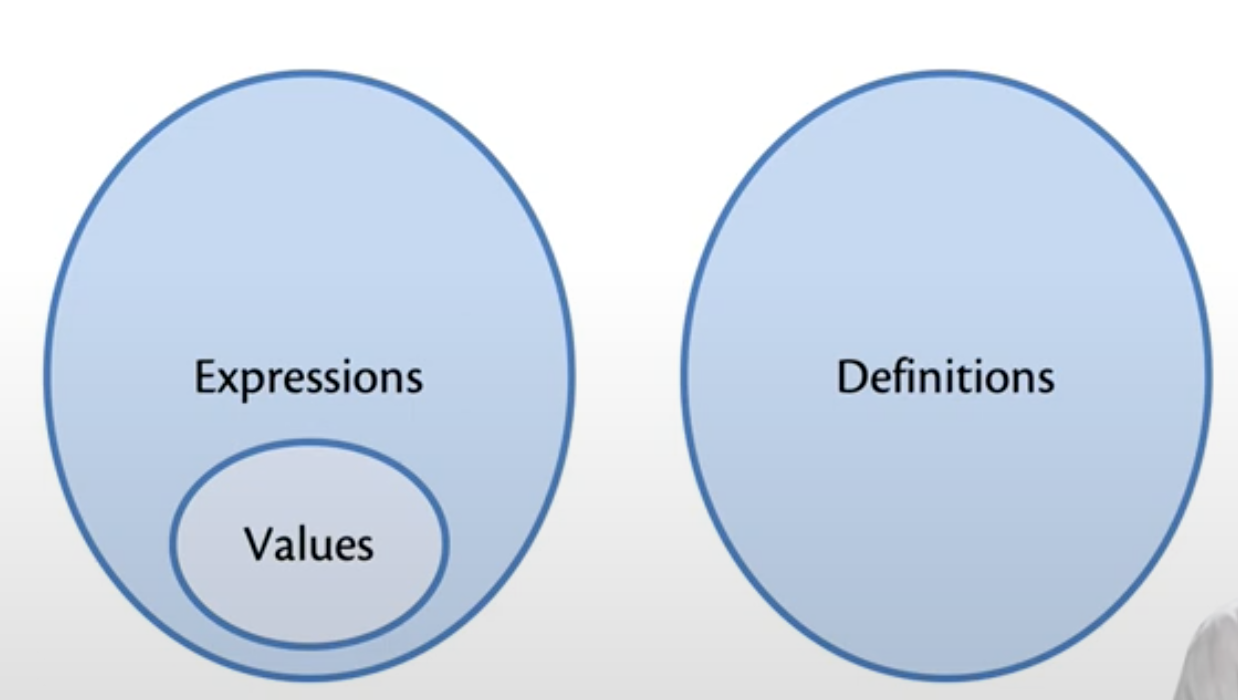
local definition זה דרך שבה מצמידים שם בתוך expression (למשל אם נרצה להשתמש בשם מסויים מביטוי א בתוך ביטוי ב).
למשל:
# let d = 2 * 3 in d * 7;;
- : int = 42
# d;;
Error: Unbound value d
חשוב לשים לב שה name bound הגלובלי לפני ה in במקרה הזה in. כלומר , השם
השגיאה למעלה קוראת בגלל שאין global definition, ניסינו לגשת ל
כמו כן, גם חשוב לשים לב שתמיד יבוצע הערכה למה שלפני ה in במקרה הזה
הסינתקס הוא let ... = ... in.
ניתן לבצע שרשור להצהרות מקומיות
# let d = 2 * 3 in
let e = d * 7 in
d * e;;
# d;;
Error: Unbound value d
# e;;
Error: Unbound value e
ניתן גם לעשות nesting
# let d =
let e = 2 * 3 in
e * 5 in
d * 7;;
- : int = 210
# d;;
Error: Unbound value d
# e;;
Error: Unbound value e
המשמעות של in זה למעשה scope שבו לשם של המשתנה יש משמעות. כאשר לא רושמים in לשם יש משמעות באופן גלובלי (מאחוריי הקלעים utop מוסיף לזה in ומכניס לתוכו את כל הקוד שכתוב מתחת להשמה).

מאחורי הקלעים הרעיון הוא די פשוט:
let x = 1 + 4 in x * 3
--> (evaluate e1 to a value v1)
let x = 5 in x * 3
--> (substitute v1 for x in e2, yielding e2')
5 * 3
--> (evaluate e2' to v2)
15
(result of evaluation is v2)
בעצם מבצעים החלפה של x מימין ל in בערך שהתקבל עבורו משמאל...
ההחלפה הזאת קורת בסמנטיקה הדינמית וצריך לשים לב איך מחליפים אם אנחנו נתקלים במצב של Overlapping scope למשל
let x = 5 in
((let x = 6 in x) + x)
"will evaluate to"
let x = 5 in
((let x = 6 in 6) + 5)
נשים לב שבאמצעות הכלל הזה אנחנו יכולים להבין למה משתנים בOCaml הם immutable.
למשל אם נרשום את הקוד
let x = 1;;
let x = 2;;
זה שקול ל
let x = 1 in
let x = 2 in
x
כפי שאמרנו ההצהרה החיצונית רלוונטית רק למה שבתוך הin אבל בעצם לא עשינו בו שום שימוש ולכן x מסתכם ב 2.
If Expressions
הביטוי if eq then e2 else e3 מחשב את e2 אם e1 = true ויחשב את e3 אחרת.
בניגוד להצהרת if else בשפות אימפרטיביות, ב OCaml מתייחסים לביטוי הזה כמו כל ביטוי רגיל וניתן לשים אותם בכל מקום שניתן לשים כל ביטוי אחר (בדומה ל סינתקס המקוצר של תנאים בשפות אחרות :?). נשים לב שלמשל הביטוי הבא 4 + (if 'a' = 'b' then 1 else 2) הוא תקים לגמרי ב OCaml.
נשים לב שגם לביטויי if ניתן לבצע nesting:
if e1 then e2
else if e3 then e4
else if e5 then e6
...
else en
ה else האחרון הוא חובה מסיבות של expression evaluation של השפה. אם נשמיט אותו סביר שנקבל שגיאה.
Function
מתודות ופונקציות הם לא אותו דבר. מתודה היא חלק מאובייקט שיכולה לשנות את הdata של אותו אובייקט באמצעות גישה ל this. פונקציות בשפות תכנות מונחות עצמים הם high order citizens כלומר הם משתנים לכל דבר והם גם הרמטיים, הם אינם משנים שום data חיצוני
הפונקציה הבסיסית ביותר בOCaml היא פונקציה אנונימית ההצהרה עליה היא על ידי הסינתקס: (fun x -> x+1) אם נכתוב את זה ב utop נקבל
- : int -> int = <fun>
הפלט <> מסמל משהו unprintable כלומר הוא לא יכול להדפיס בידיוק מה הפונקצייה עושה אלא הוא יודע שזה פונקצייה. הסינקס int->int מסמל את ערך הקלט של הפונקציה וערך החזרה של הפונקציה.
כדי להפעיל את הפונקציה פשוט שמים את הקלט ליד הפונקציה עצמה (לכן עטפנו פונקציה אנונימית בסוגריים) 3110 (fun x -> x+1) ללא הסוגריים היינו מקבלים שגיאת סינתקס.
הסינתקס באופן כללי של פונקציה אנונימית הוא fun x1 ... xn -> e
פונקצייה היא value - אין חישוב שנעשה בזמן ריצה כלומר
פונקציה אנונימית נקראת גם פונקצית למבדה ובכתיב מתמטי
ניתן כמובן לתת לפונקציה גם שם למשל val inc = fun x -> x + 1.
וב syntactic sugar:
let inc x = x+1 , פשוט שמים את הארגומנטים לפני ה
חישוב של הפעלת פונקציה:
הסינתקס להפעלת פונקציה הוא פשוט e0 e1 e2 e3 ... en בלי סוגריים אלא אם כן צריך סדר מסויים.
הפעולת חישוב של פונקציה נעשית באופן הבא:
א) המר כל fun x1...xn->e .
ב) החלף
ג) חשב
פונקציות רקורסיביות
באקומל חייבים להגדיר באופן מפורש על פונקציה רקורסיבית: let rec f .למשל נכתוב פונקצייה שמחשבת עצרת :
(* requires: [ n >= 0]*)
let rec fact n =
if n = 0 then 1
else n * fact (n-1)
כיוון שבאופן כללי הניתוח של הביטוי הוא מימין לשמאל אם לא נגדיר את הפונקציה כרקורסיבית הקומפיילר לא ידע בזמן ריצה את המשמעות של fact ולא יוכל להפעיל אותה.
הנה פונקצייה רקורסיבית נוספת:
(** [pow x y] is [x] to the power of [y].
Requires: [y >= 0]. *)
let rec pow x y = if y = 0 then 1 else x * pow x (y - 1)
ב utop נקבל פלט
val pow : int -> int -> int = <fun>
אם יש פונקציות רקורסיביות שמפעילות אחד את השני נוכל להשתמש ב and בסינתקס הבא-
let rec f x1 ... xn = e1
and g y1 ... yn = e2
לדוגמה-
(** [even n] is whether [n] is even.
Requires: [n >= 0]. *)
let rec even n =
n = 0 || odd (n - 1)
(** [odd n] is whether [n] is odd.
Requires: [n >= 0]. *)
and odd n =
n <> 0 && even (n - 1);;
Function types
פונקצייה יכולה להיות מטיפוס
פונקצייה יכולה להיות גם מטיפוס
באופן כללי פונקצייה היא מטיפוס
ל
בtype checking (הסמנטיקה הסטטית) שקובעת את טיפוס הפונקצייה פשוט מתבצעת בדיקה על טיפוס הקלטים (לאחר התהליך שנקרא type inference). באופן כללי פשוט בודקים
if assuming x1:t1, ..., xn:tn;
we can conclude:
e:u
Then
(fun x1...xn->e): t1->...->tn->u
בפונקציה רקורסיבית הבדיקה הייתה :
if assuming x1:t1, ..., xn:tn; AND f : t1 -> t2 -> ... -> tn -> u
we can conclude:
e:u
Then
(fun x1...xn->e): t1->...->tn->u
באופן דומה גם הפעלת פונקציות מנותחת ב type checking.
if e0 : t1 -> ... -> tn -> u
AND
e1 : t1,
e2 : t2,
.
.
.
en : tn
THEN e0 e1 ... en : u
אין סמנטיקה דינמית בהגדרה של פונקציות שכן לא נעשה שום חישוב איתן עד שלא מפעילים אותן.
Application operators
נסתכל על הפונקציה let succ x = x+1 . נשים לב שבסמנטיקה הדינמית OCaml הפענוח של פונקצייה הוא הדוק יותר מהפענוח של אופרטור כך שאם נרצה לחשב את succ 2 * 10 המהדר בעצם מפרש את זה כ 10 * (succ 2) . יכול להיות שהתכוונו ל succ (2 * 10) . אופרטורים של הפעלת פונקציות הן מעין סינתקס סוכר למנוע מאיתנו לכתוב את הסוגריים למשל
succ @@ 2 * 10 נקרא application operator והוא מפריד בין הקלט לפונקציה לקריאה שלה.
אופרטור נוסף הוא reverse application operator או pipeline.
נניח שנרצה להפעיל את הריבוע חזקה של succ 5 כלומר square (succ 5) . אם לא היינו עושים זאת , היינו מקבלים שגיאה כי המהדר היה מפרש את זה כ 5(square succ) שזה לא קלט תקין לפונקציה שמקבלת int. נוכל להשתמש בreverse operator שדומה בעקרון שלו ל pipeline בתוכנות CLI. מעין דרך לשרשר value כקלט לפונקצייה הבאה אחריו ולאפשר קריאה רציפה משמאל לימין למשל במקרה שלנו
5 |> succ |> square
ייקח את 5 ישרשר אותו כקלט ל succ ואת הפלט שיווצר ישרשר ל square. האופרטור <| נקרא אופרטור pipeline.
Polymorphic Functions
נגדיר את פונקצייה הזהות let id x = x פונקציה שמחזירה את הקלט שאותו היא מקבלת.
הטיפוס שנקבל עבור הפונקציה הזאת הוא val id : 'a -> 'a . המשמעות של a' הוא type variable : והמשמעות של זה היא ״טיפוס לא ידוע/גנרי״. לשם הנוחות ארשום את המשתנים הללו באותיות לטיניות
הרעיון מאחורי היכולת הזאת היא פולימורפיזם - כתיבת פונקציות שעובדות עבור מספר משתנים בלי קשר לטיפוסים שלהם. הסינתקס של פונקציות הזהות למשל מבטיח שבהינתן קלט מטיפוס כלשהו הפלט יהיה מאותו טיפוס בדיוק ולכן במצבים אלה פולימורפיזם יכול לעבוד.
זה מאוד מתאים לעבודה עם מבני נתונים שכן אין חשיבות ל data הנשמר במבנה הנתונים למשל ברשימה או במחסנית, פונקציות הפועלות על מבנה הנתונים לא אמורים להיות תלויות במידע הנשמר בתוכן.
נתבונן למשל בהצהרה הבאה
fun (f,g) -> (fun x -> f(g x)))
זהו משתנה גלובלי אנונימי, ננסה לנתח את הטיפוס שלו , קל לראות שזאת אכן פונקצייה פולימורפית שכן לא ניתן לפרש את הטיפוס. אין ספק שהטיפוס הוא מסוג פונקציה, אך מה הקלט והפלט שלה? לשם כך צריך להכיר את הקלט והפלט של
ניתן לראות ש
לכן
מה לגבי הפלט? אם כן הפלט הוא גם כן פונקציה שמקבלת את הטיפוס של
Partial Application
נסתכל על הפונקציה הבאה add x y = x + y פונקצית הוספה פשוטה. בOCaml יש פיצ׳ר שמאפשר לנו להפעיל פונקציות באופן חלקי כלומר אם נריץ add 2 3 נקבל
אבל אם נריץ add 2 נקבל טיפוס מסוג int -> int. בעצם הפעלה באופן חלקי מחזירה פונקצייה שנוכל להפעיל עם שאר הפרמטרים כדי לקבל את הפונקציה המקורית. אם נריץ 3 (add 2) נקבל
למעשה אפילו נוכל לשמור את הפונקציה הזאת, לדוגמה:let add2 = add 2.
הסיבה שזה עובר היא בגלל ש באוקמל, פונקציות לא מקבלות באמת מספר פרמטרים אלא מה שעשינו עד כה היה מעין syntactic sugar. למשל:
fun x y -> e
is syntactic sugar for
fun x -> (fun y -> e)
כלומר פונקציות הן אסוציטיביות בOCaml בעצם
let f x1 x2 ... xn = e
(*is semantically equivilant to*)
let f =
fun x1 ->
(fun x2 ->
(...
(fun xn -> e)...))
(*the type of such function*)
t1 -> t2 -> t3 -> t4
(*really means the same as*)
t1 -> (t2 -> (t3 -> t4))
ולכן כל פונקצייה מרובת משתנים היא בעצם שרשור של פונקציות שמקבלות פרמטר אחד כל פעם. העובדה שזה אפשרי היא בגלל ש פונקציות הן ערכים אפשר להעביר פונקציות כפרמטר ולהחזיר פונקציות כפלט.
curry
זה קונספט של תכנות פונקציונלי שבו פונקציה שמקבלת מספר ארגומנטים היא מהווה בעצם רצף פעולות שכל אחד בה מקבל ארגומנט אחד.
let curry f x y = f (x, y)
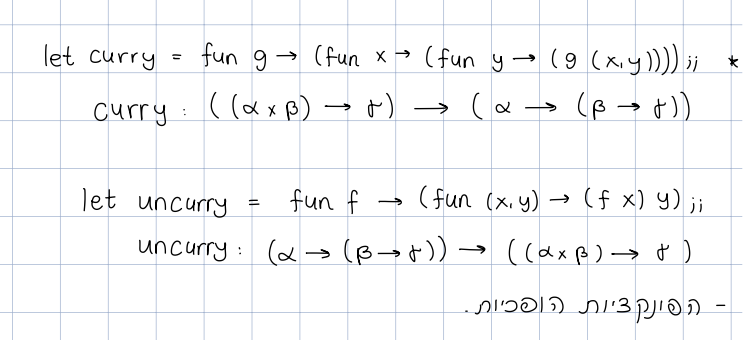
Loops
באוקמל אין באמת מימוש שדומה ללולאות בשפות אימפרטיביות (יש, אבל בImperative OCaml). הסיבה הכי קלאסית שאפשר לחשוב עליה שעבורה נרצה יכולת כזאת היא אלגוריתם פיבונאצ׳י שבמימוש הריקורסיבי שלו זמן הריצה שלו הוא מעריכי. אך באמצעות תכנות דינמי אפשר להגיע לזמן ריצה ליניארי.
נתחיל מלהגדיר פונקציה iter משלנו ונסביר אותה.
let rec iter = fun n f x -> match n with
| 0 -> x
| n -> (f(iter (n-1) f x)
בעצם בנינו פה פונקציית איטרציה גנרית באמצעות ריקורסיה. הפונקציה מקבל את
כעת כדי לפתור את fib נוכל להגדיר
let f = fun (x,y) -> (x+y,x);;
let second = fun (x,y) -> y;;
let fib = fun n -> second(iter n f (1,1));;
While
נבנה פונקצייה שמממשת while :
let rec _while = fun p f x -> if (p x) then x else (_while p f (f x))
כאשר p x = false ו
_while p id x
אכן קיימים לולאות בOCaml אך הן לרוב באות יד ביד עם mutability שזה קונספט שאנסה להתרחק ממנו בסיכום זה כיוון שאנחנו מדברים על OCaml תחת הכובע של תכנות פונקציונלי שבו אין mutability בכלל
Data and Types
Lists
רצף של ערכים מאותו טיפוס.
מאחורי הקלעים ממומשים בצורה של Linked list. רשימות בOCaml הן מאוד אינטואיטיביות , קלות להצהרה ולעבודה איתן, כך שאין צורך בעבודה מול ספרייה כדי להשתמש בהן, למשל כמו ב JAVA או C.
בנייה של רשימה היא באמצעות הסינתקס הבא
[]
e1 :: e2
[e1; e2; ...; en]
כאשר מקבלים רשימה elt::lst . הסוגריים המרובעות זה סינתקס נוח אך אינו חובה. כמו כן, כיוון שרשימות הן סוג של expression ניתן לבצע nestingשל רשימות עמוק ככל הניתן.
סמנטיקה דינמית של רשימות:
if e> v1 and if e2>v2 then e1::e2 ==> v1::v2
כאשר ==> שקול ל evaluate to.
באופן כללי נוכל לרשום את הנ״ל כך:
סמנטיקה סטטית של רשימות:
א) [] הוא מטיפוס
ב) שרשור של איבר עם רשימה מאותו איבר תייצר רשימה חדשה מאותו טיפוס.
פונקציות חשובות ברשימות
List.fold_left f acc lst - פונקציה שרצה על רשימה מפעילה על כל איבר את הפונקציה f ומאפשרת לצבור את המידע מכל הפעלה במשתנה acc. למשל אפשר לסכום את כל המערך על ידי let sum = List.fold_left (fun acc x -> acc + x) 0 lst.
הטיפוס של הפונקציה val fold_right : ('a -> 'b -> 'b) -> 'a list -> 'b -> 'b.
List.fold_left f acc lst- אותו דבר רק מימין לשמאל.
List.map f lst - מחזירה רשימה חדשה שכל איבר בה הוא הפעלה של f על האיבר המתאים ב lst.
let squared_lst = List.map (fun x -> x * x) lst
List.filter f lst - מחזירה רשימה חדשה של כל האיברים שעבורם הפרדיקט f מחזיר true.
let even_numbers = List.filter (fun x -> x mod 2 = 0) lst
Pattern matching
אחת הדרכים הנוחות ביותר לעבוד עם רשימות: Pattern matching. זאת הוא תכונה רבת עוצמה המאפשרת לנו לפרק ולהתאים מבני נתונים מורכבים בצורה תמציתית ואקספרסיבית. הוא משמש בדרך כלל עם סוגי נתונים כמו tuples, רשימות, variants וrecords. התאמת דפוסים משפרת את קריאות הקוד ומקלה על הטיפול במקרים שונים.
ישנו דמיון רב בין Pattern matching ל switch case אך ההבדל הגדול הוא שכאן יש התאמה גם ב ״shape of data" ולא רק בערך עצמו, ובנוסף ניתן באמצעות pattern matching גם לחלץ חלק או חלקים מdata מסויים, מה שהופך את הכלי הזה לחזק הרבה יותר.
סינתקס: באמצעות שימוש במילת המפתח match
match expression with
| pattern1 -> result1
| pattern2 -> result2
| pattern3 -> result3
patterns:
כולל בתוכו - קבועים, משתנים, קונסטרקטורים, tuples , רשימות וכו׳.
קבועים ומשתנים תמיד מתאימים לעצמם וקונסטרקטורים מתאימים לערכים עם אותו קונסטרקטור.
נסתכל על מספר דוגמאות
(*matching constants*)
let check_number n =
match n with
| 0 -> "Zero"
| 1 -> "One"
| _ -> "Other"
(*matching tuples*)
let get_coordinates point =
match point with
| (x, y) -> "X: " ^ string_of_int x ^ ", Y: " ^ string_of_int y
(*matching lists*)
let rec sum_list lst =
match lst with
| [] -> 0
| head :: tail -> head + sum_list tail
(*match records*)
type person = { name: string; age: int }
let get_name_age p =
match p with
| { name = n; age = a } -> "Name: " ^ n ^ ", Age: " ^ string_of_int a
(*matching variant*)
type shape = Circle | Rectangle of int * int | Square of int
let area s =
match s with
| Circle -> 3.14
| Rectangle (width, height) -> width * height
| Square side -> side * side
היכן שמסומן _ זה בעצם כמו default ב switch בשפות אימפרטיביות. זה נקרא wildcard
Pattern matching with lists
רשימה יכולה להיות או ריקה, או שרשור של אלמנט עם תת רשימה.
לכן נוכל לנצל את התכונה הזאת כדי לבנות סינתקס קבוע לסריקה של רשימה. למשל נבנה פונקצייה שבודקת אם הרשימה ריקה
let empty lst =
match lst with
| []->true
| h::t -> false
באותו אופן נוכל לסכום את האיברים ברשימה
let rec sum lst =
match lst with
| [] -> 0
| h :: t -> h + sum t
אפשר לשרשר איבר ורשימה עם הסינתקס :: או לשרשר שתי רשימות עם הסינתקס @ .
רשימות אינן ניתנות לשינוי. אין דרך לשנות רכיב של רשימה מערך אחד למשנהו. במקום זאת, מתכנתי OCaml יוצרים רשימות חדשות מתוך רשימות ישנות. לדוגמה, נניח שרצינו לכתוב פונקציה שהחזירה את אותה רשימה כמו רשימת הקלט שלה, אבל עם האלמנט הראשון (אם יש כזה) מוגדל באחד. יכולנו לעשות את זה:
let inc_first lst =
match lst with
| [] -> []
| h :: t -> h + 1 :: t
אין צורך לחשוש מזכרון מקום, כיוון ש t משותפת בין הרשימה הישנה לחדשה כך שכמות הזכרון היחידה שמתווספת היא הזכרון הדרוש כדי לשרשר את h+1 לרשימה.
הקומפיילר עושה את זה בגלל שכל דבר בתכנות פונקציונלי הוא בלתי ניתן לשינוי וכך גם האיברים ברשימה ולכן אין חשש מכך ששיתוף זכרון ייצור שינוי באמינות המידע. שכן כל שינוי של משתנה מייצר עותק שלו.
בסמנטיקה הstatic, כאשר מדובר ב pattern matching הקומפיילר יעיר לנו אם לא כיסינו את כל הpatterns הדרושים בקוד שלנו. כמו כן , נקבל גם הערה אם יש לנו כפילויות בpatterns.
Variants
זה טיפוס נתונים שמייצג ערך אחד מתוך מספר אפשרויות. בבסיס שלהם , השימוש מאוד דומה ל enum ב C.
type day = Sun | Mon | Tue | Wed | Thu | Fri | Sat
let d = Tue
כל אחד מהערכים שהtype מקבל נקרא constructors. אם נרצה לגשת לconstructor המתאים עבור ערך כלשהו המימוש הוא פשוט באמצעות pattern matching
let int_of_day d =
match d with
| Sun -> 1
| Mon -> 2
| Tue -> 3
| Wed -> 4
| Thu -> 5
| Fri -> 6
| Sat -> 7
במצב שבו יש שני קונסטרקטורים עם אותו שם עבור שתי וריאנטים הטיפוס שהוצהר אחרון מבנהם מנצח.
לכל קונסטרקטור אפשר להצמיד ערכים באמצעות מילת המפתח of.
type commit =
| Hash of string
| Tag of string
| Branch of string
| Head
| Fetch_head
| Orig_head
| Merge_head;;
type commit =
Hash of string
| Tag of string
| Branch of string
| Head
| Fetch_head
| Orig_head
| Merge_head
אפשר להעביר מספר פרמטרים באמצעות הסינטקס p1*p2 ואפשר להצהיר עליהם כ tuple באמצעות סוגריים (p1*p2).
הכוח האמיתי של variant הוא באמצעות טיפוסים רקורסיביים למשל עצים
type 'a tree =
| Leaf
| Node of 'a * 'a tree * 'a tree
(* the code below constructs this tree:
4
/ \
2 5
/ \ / \
1 3 6 7
*)
let t =
Node(4,
Node(2,
Node(1, Leaf, Leaf),
Node(3, Leaf, Leaf)
),
Node(5,
Node(6, Leaf, Leaf),
Node(7, Leaf, Leaf)
)
)
כעת אפשר לבצע פעולות על המבנה הרקורסיבי שהגדרנו
let rec preorder = function
| Leaf -> []
| Node {value; left; right} -> [value] @ preorder left @ preorder right
נשים לב שבנינו את העץ שלנו גם רקורסיבי וגם פולימורפי. זה אפשרי כפי שאפשר לכתוב פונקציות פולימורפיות
רשימות הן גם variant שמוגדר באופן הבא:
type a' list = Nil | Cons of a' * (a' list)