מבוא לסטטיסטיקה היסקית
כפי שדיברנו ב סטטיסטיקה תיאורית , אנחנו אוספים מידע על מדגם מתוך אוכלוסייה. כיוון שהמידע הוא רק על מדגם ולא על האוכלוסייה כולה, צריך לבצע הסקת מסקנות כלשהי באמצעות כלים הסתברותיים.
בעצם סטטיסטיקה היסקית היא הקשר בין תורת ההסתברות לבין תהליך ההסקה.
דגימה , אוכלוסייה , מדגם הם שלושת המרכיבים העיקריים של כל בעיית הסקה.
כאשר המדגם נעשה בצורה מקרית יש בידינו כלים מתמטיים שמאפשרים לנו לקבוע את מידת הדיוק של אומדן כזה.
דגימה מקרית
דגימה מקרית של מדגם בגודל
לדוגמה: פיקוד העורף מעוניין לבדוק את כשירותם של המקלטים באזור גוש דן.
האוכלוסייה תהיה כלל המקלטים בגוש דן ומתוכם יבחר פיקוד העורף מדגם יחסית קטן של 200 מקלטים בשיטת דגימה מקרית.
דוגמה נוספת: משרד התחבורה מעוניין לבדוק מהו אחוז כלי הרכב הבלתי תקינים הנעים בכבישי הארץ ולכן הוא עורף בדיקות פתח ל
זאת דוגמה יחסית פשוטה. נסתכל על דוגמה מעט מבלבלת יותר,
מכון התקנים מעוניין לבדוק את איכות נורות החשמל המיוצרות במפעל מסויים, כלומר מה אחזור הנורות התקינות היוצאות מקו הייצור של המפעל.
נשאלת כאן השאלה, מי היא בכלל האוכלוסייה שכן מכון התקנים מעוניין להעריך את איכות הנורות שיווצרו בעתיד בנוסף לאלה שכבר נוצרו.
ניעזר ב משתנה מקרי ופונקציות ההסתברויות שלו, כדי לענות על השאלה הזאת.
אם כן, נוכל להגדיר משתנה מקרי אינדיקטור
בדיקה שכזו נקראת תצפית מתוך המ״מ
כמובן שתצפית אחת לא תספיק ולכן יש צורך לערוך תצפיות רבות
כאשר
כלומר קיבלנו כאן סדרה של משתני אינדיקטור בלתי תלויים עם אותה פונקציית הסתברות ולכן
כלומר לקחנו סדרת תצפיות בלתי תלויות שהניבו ערך כלשהו בהסתברות כלשהי וביצענו חישוב מתמטי על ההסתברות של כל אחת מהתצפיות שנתנה לנו את ההסתברות הכוללת.
מדגם מקרי בגודל
משפט
דגימה מקרית עם החזרה של
נסתכל למשל על הדוגמה הראשונה עם המכוניות
נסמן את התקינות של כלי רכב כמשתנה מקרי אינדיקטור
נשים לב שמתקיים
כאשר
באותו אופן :
וכמובן ש
כלומר היחס בין כלי הרכב הבלתי תקינים לבין כלי הרכב בישראל שקולה לפונקציית ההסתברות הרצויה.
אם כן מה שיקרה בניסוי הוא :
נדגום רכב כלשהו-->נחזיר אותו לאוכלוסיית כלי הרכב-->נדגום כלי רכב נוסף
כל דגימה תהיה
כיוון שמחזירים את הרכב לאוכלוסייה הרי שפונקציית ההסתברות שקולה בין כל דגימה והם בלתי תלויים זה לזה ולכן קיבלנו את השקילות שרצינו.
ההחזרה נועדה להבטיח שהאוכלוסייה הנדגמת לא תשתנה מדגימה לדגימה. אי החזרת איבר משנה את האוכלוסייה ואז התצפיות הופכות להיות תלויות.
רק כאשר הדגימה קטנה מאוד ביחס לאוכלוסייה ניתן להזניח את ההבדל הזה.
גם דגימה מקרית מתוך מ״מ
התפלגות דגימה
השאלה העיקרית לאחר שהבנו מהו מדגם מקרי תהיה
מה וכיצד ניתן ללמוד מהמדגם על האוכלוסייה או על המ״מ שממנו נלקח?
נדגיש כי תהליך הדגימה הוא ניסוי מקרי וכל אחת מהתוצאות
המשמעות היא, חזרות על תהליך הדגימה יניבו מדגמים שונים.
נרצה להסיק מתוך מדד כלשהו במדגם כל מה שניתן על המדד המתאים באוכלוסוייה.
למדד באוכלוסייה או במ״מ קוראים פרמטר
הפרמטר הוא גודל קבוע המאפיין את האוכלוסייה או את התפלגות המ״מ.
התוחלת למשל היא פרמטר של משתנה מקרי
נעזר במה שנקרא התפלגות דגימה כדי ללמוד ממדדי המדגם (הסטטיסטים) על תכונות האוכלוסייה (הפרמטרים).
אם כן, התפלגות הדגימה של סטטיסטי מסויים (סטטיסטי יכול להיות שונות של מדגם, ממוצע של מדגם וכו׳) היא פונקציית ההסתברות שלו. התפלגות זו תלויה בצורתו המתמטית של הסטטיסטי, בגודל המדגם ובתכונות האוכלוסייה שממנה נדגם.
נגדיר מספר מונחים:
- התפלגות אוכלוסייה: הקשר בין ערכי משתנה מסויים
לבין שכיחותו באוכלוסייה או שכיחותו היחסית. המדדים בהתפלגות זו מכונים פרמטרים. - פונקציית ההסתברות של משתנה מקרי
: הקשר בין ערכים אפשריים של לבין ההסתברות לקבלתם. - התפלגות המדגם: הקשר בין ערכי משתנה מסויים
לבין שכיחותו במדגם או שכיחותו היחסית. אלו מכונים סטטיסטים. - התפלגות דגימה: הקשר בין הערכים האפשריים של סטטיסטי מסוים לבין ההסתברות לקבלתם.
במה תלויה צורת ההתפלגות הדגימה?
א. בהתפלגות האוכלוסייה שדוגמים ממנה.
ב. בגודל המדגם. למשל אם המדגם הוא בגודל 1 אז התפלגותו תהיה זהה להתפלגות האוכלוסייה ולמדגמים בגודל כל האוכלוסייה אין כלל התפלגות דגימה.
ג. בסוג הסטטיסטי שאותו מחשבים במדגמים השונים.
לכן מקפידים לומר:
״התפלגות הדגימה של סטטיסטי מסוים, למדגמים בגודל
נסתכל על דוגמה:
יש לנו אוכלוסייה של
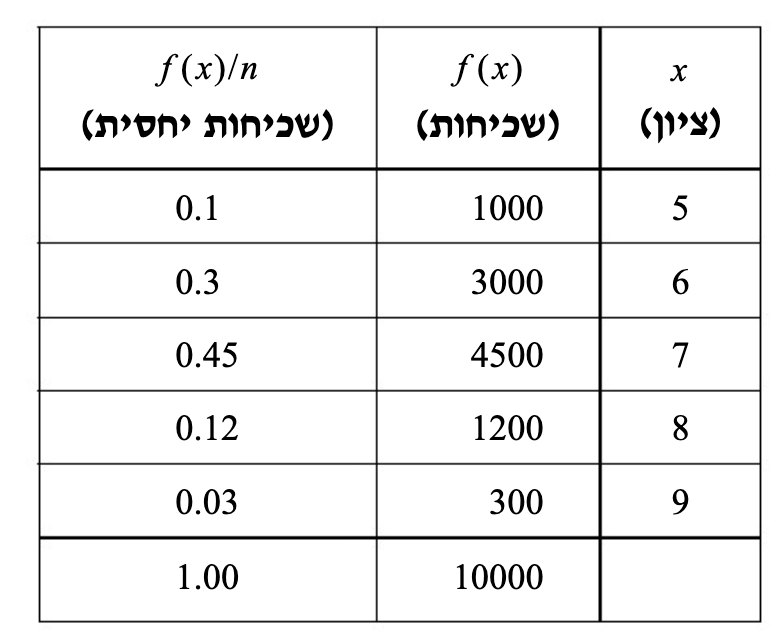
זוהי ההתפלגות באוכלוסייה של מ״מ
אם נדגום מהאוכלוסייה
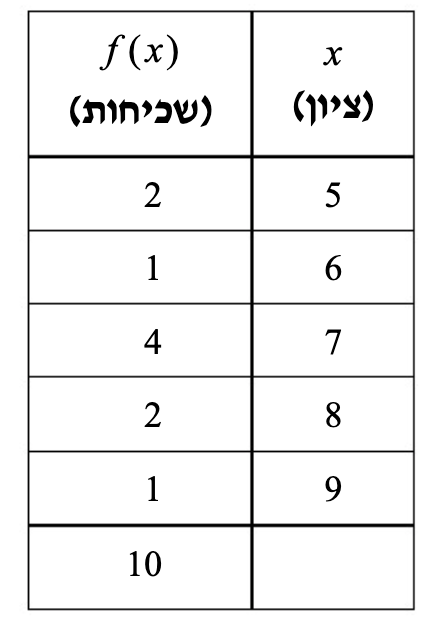
זוהי התפלגות השכיחויות במדגם , ואף עבורה אפשר לחשב מדדים למשל
אם נסתכל על מדגם בגודל
מהתפלגות האוכלוסייה אפשר לראות שבמדגם בין שני תלמידים הממוצע
ישנם דרכים לחשב את ההסתברות של כל ממוצע אפשרי במדגמים הללו בגודל

דוגמה 2:
התוצאות של הטלת קובייה תקינה הן מ״מ
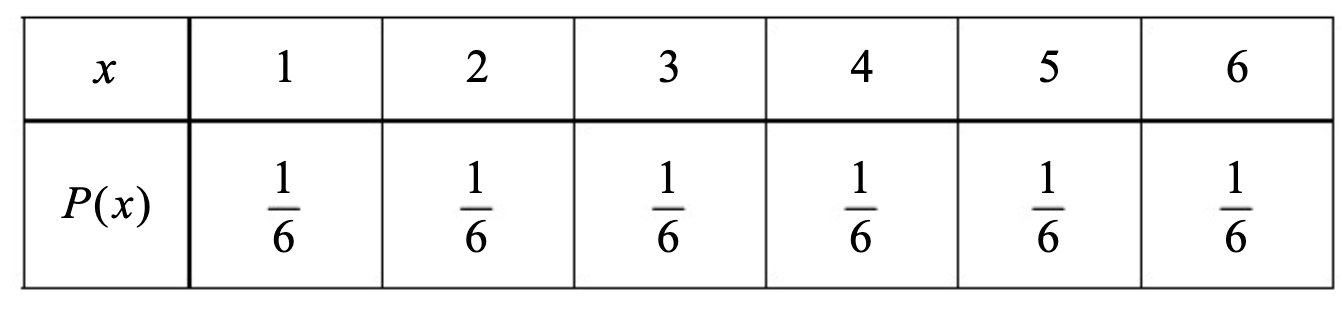
דגימה בגודל
נניח שהקובייה מוטלה פעמיים ונתעניין בסטטיסטי שהוא ממוצע התוצאות של שתי ההטלות.
נגדיר
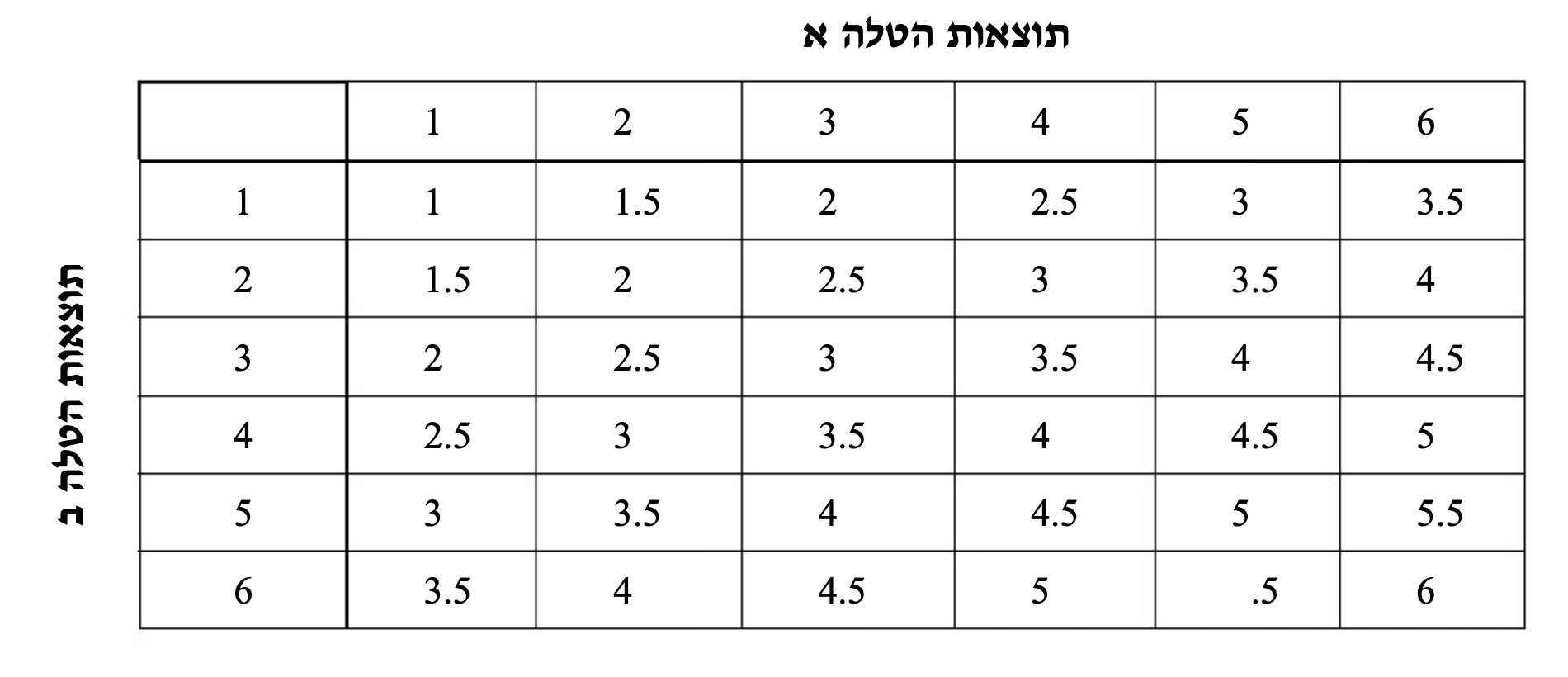
ההסתברות לקבל כל אחד מזוגות אלו היא זהה, כיוון שיש

אם כן, זוהי התפלגות הדגימה של
נסתכל על התוחלת והשונות של המ״מ של התפלגות הדגימה הנ״ל
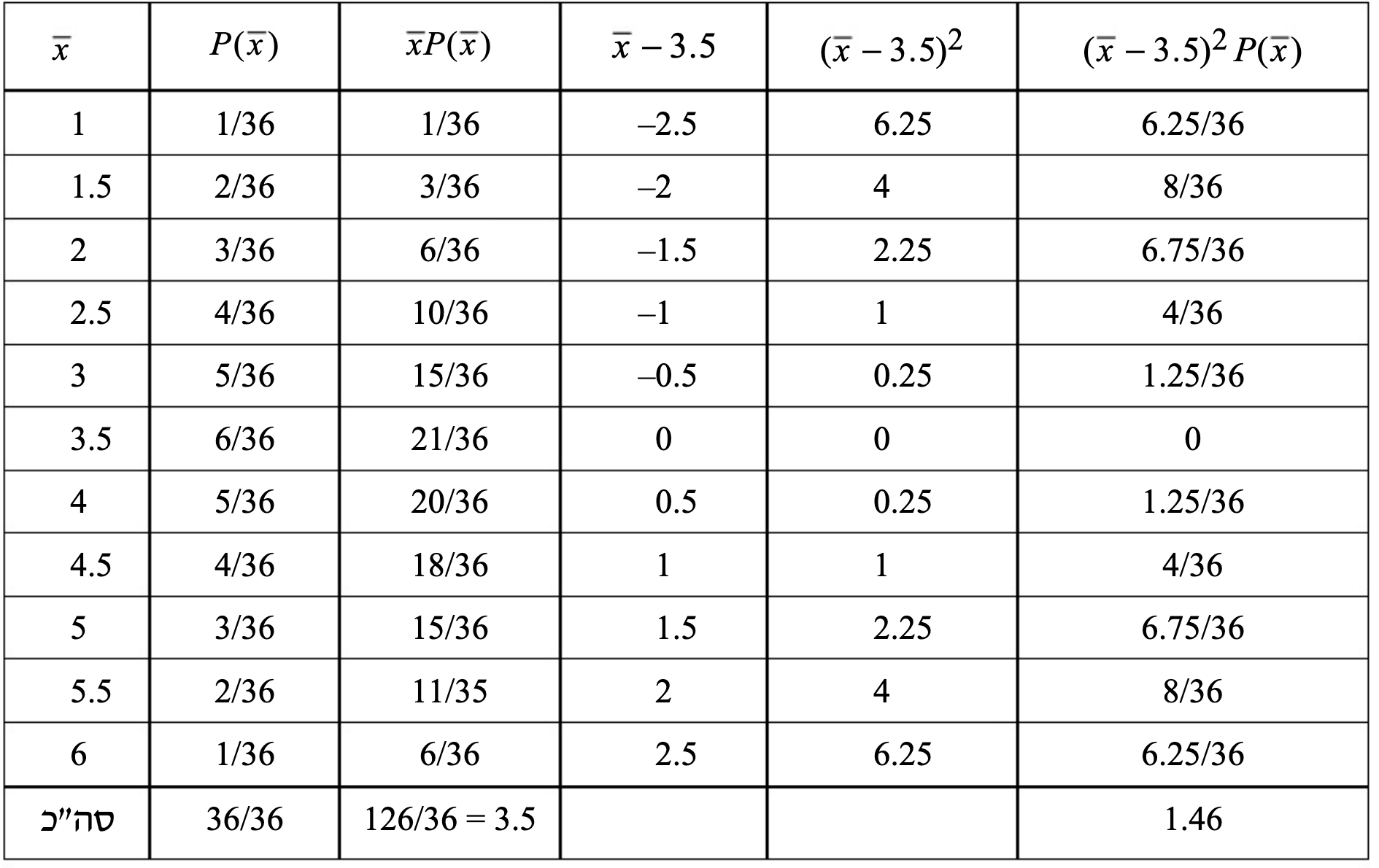
תחילה חישבנו את התוחלת של התפלגות הדגימה. לשם כך הכפלנו כל ממוצע בהסתברותו, קיבלנו מכך את הטור השלישי. סכום הטור השלישי מבטא את התוחלת, על פי הנוסחה שאנחנו מכירים
נוכל גם לחשב את השונות של המ״מ של התפלגות הדגימה עם הטבלה הנ״ל
התפלגות הדגימה של הממוצע
כאמור, ממוצע המדגם
תוחלת
נזכיר שלכל
ובמילים: תוחלת הסטטיסטי ״ממוצע המדגם״ שווה לתוחלת המ״מ שממנו דוגמים.
אם
אם נחשב את התוחלת של דוגמת הקוביות ממקודם נקבל
נשים לב, במדגמים שונים מאותה אוכלוסייה יכולים להתקבל ממוצעי מדגם שונים, אך אם נדגום הרבה מאוד מדגמים ובכל אחד מהם נחשב את הממוצע, אזי ממוצע הממוצעים יהיה קרוב מאוד לממוצע האוכלוסייה.
אנחנו רוצים להבין אם כן, מהי הסבירות שממוצע המדגם שלנו סטה בהרבה מממוצע האוכלוסייה.
מכיוון שממוצע האוכלוסייה זהה לממוצע הממוצעים
אם כן, שואלים על מידת הפיזור של התפלגות הדגימה של הממוצע.
מדד הפיזור המקובל ביותר הוא השונות ולכן נחשב את השונות על התפלגות הדגימה של הממוצע
המעבר האחרון נובע מכך ש
אנחנו יודעים ש השונות של סכום משתנים בלתי תלויים שווה לסכום של השונויות שלהם . כיוון שכל
ובעצם נקבל סך הכל ש
ובמילים: סטיית התקן של ממוצע המדגם שווה לסטיית התקן של המ״מ שממנו דגמנו, מחולקת בשורש הרובעי של גודל המדגם.
המסקנה העיקרית היא שכככל שהמדגם גדול יותר כך שונות ממוצע המדגם קטנה יותר, ושעל ידי בחירת מדגם גדול נוכל להקטין שונות זו כרצוננו.
בתצורה גרפית ניתן לראות שפונקציית הצפיפיות של
למשל עבור
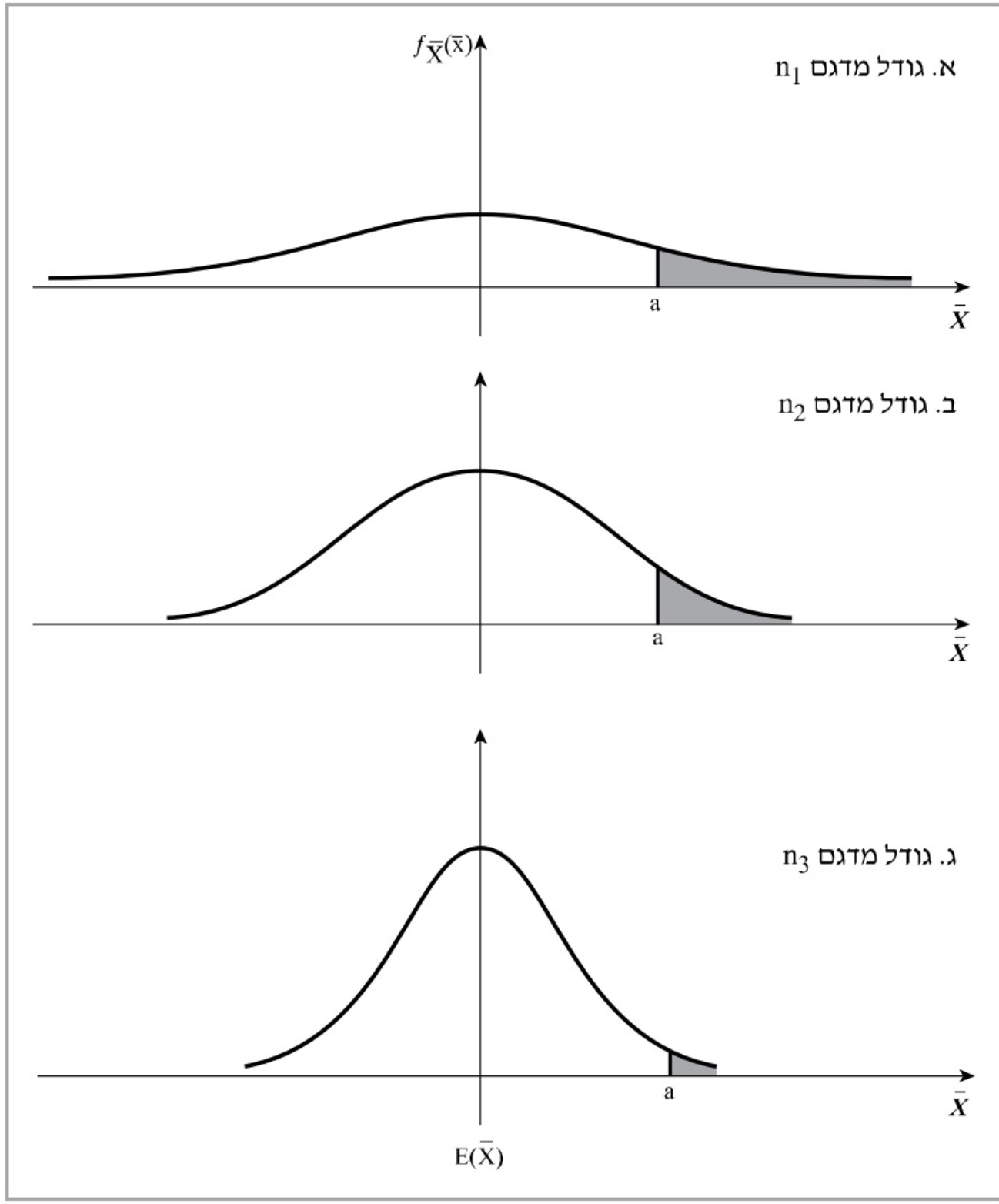
לגודל סטיית התקן יש השפעה ישירה על ההסתברות שהמשתנה המקרי יקבל ערכים רחוקים מהתוחלת. למשל ההסתברות שממוצע המדגם
הסתברות זו הולכת וקטנה ככל שסטיית התקן קטנה. כלומר ממוצע המדגם בתרשים השלישי יהיה בסבירות גבוה הרבה יותר קרוב לתוחלת
המסקנה הזו מכונה חוק המספרים הגדולים וביטויה הכמותי מבוסס על מה שמכונה אי שיוויון צ׳בישב .
אי-שיוויון צ׳בישב
לכל משתנה מקרי
ביטוי שקול יכול להיות:
והמשלים:
למשל עבור
ככל ש
דוגמה:
התפלגות מנות המשכל של סטודנטים הלומדים בבר אילן היא בעלת ממוצע
אם נציב
כלומר מנת המשכל של לפחות
אי שיוויון צ׳בישב נכון לכל מ״מ בעל שונות סופית, ללא כל קשר לפונקציית ההסתברות שלו. מכאן נובע יתרונו הגדול- אפשר להפעילו מבלי לדעת את פונקציית ההסתברות שלו. מכאן נובע יתרונו הגדול- אפשר להפעילו מבלי לדעת את פונקציית ההסתברות. נשים לב שבגלל שהוא כל כך כללי הוא לא מפורט במידה מספקת. למשל, הוא לא נותן לנו הערכה משמעותית לגבי ההסתברות בקירוב של פחות מסטיית תקן אחת.
כעת, נפעיל את אי שיוויון צ׳בישב כדי ללמוד על ההתנהגות של ממוצע המדגם
מהכלים שלמדנו על ההתנהגות של השונות והתוחלת של ממוצע המדגם נקבל כי
חוק המספרים הגדולים
נשים לב שאת
עבור כל גודל חיובי קטן כרצוננו,
כעת נוכל לקרב את גודל האגף בימין ל
חוק זה נקרא חוק המספרים הגדולים שמבטיח לנו שעל ידי בחירת מדגם גדול כל צורכו נוכל להיות כמעט בטוחים שהממוצע שלו יהיה קרוב מאוד לממוצע האולכוסייה.
באופן מתמטי מדוייק יותר מתקיים
אבל הסתברות היא תמיד קטנה מ
וסך הכל מכללי אי שיוויון מתקיים
מסקנה חשובה
נתבונן בניסוי מקרי כלשהו, יהי
נסתכל על ממוצע המדגם
וזוהי בידיוק השכיחות היחסית של
עתה, נתבונן במדגם של
לפי אי שיוויון צבישב יתקיים על ממוצע המדגם:
נוכל גם לרשום את זה כך
ולגבי המאורע המשלים
נשים לב כי לכל
ואם נציב במקום
במילים: אם מבצעים
אפשר לומר שעם עליית מספר החזרות, שואפת השכיחות היחסית של הופעת מאורע להסתברותו. עובדה זו נקראת התופעה האמפירית אשר שימשה לנו השראה לבניית המודל של תורת ההסתברות
דגימה מתוך התפלגות נורמלית
ציינו שאי-שיוויון צ׳בישב הוא גס למדי ובדרך כלל אינו מעניק מידע מספיק. נרצה להעזר בכלים מתמטיים חזקים יותר כדי לקבל מידע מפורט יותר על האוכלוסייה ממדגם בודד.
כמו כן, חסרון נוסף של הערכות לפי אש״צ היא בכך שאלו הערכות הסתברותיות בטווחים סימטרים סביב התוחלת. לעתים נתעניין בהסתברות מאורעות שאינם מן הצורה הזו דווקא. למשל, נרצה לדעת מהי ההסתברות שממוצע המדגם יהיה במרחק שבין סטיית תקן אחת לבין שתי סטיות תקן מעל לתוחלת האוכלוסייה.
למעשה, היינו רוצים לדעת בנוסף לתוחלת ולסטיית התקן של ממוצע המדגם , גם את פונקציית ההסתברות שלו. באמצעות פונקציית הצפיפות ניתן לחשב בידיוק את ההסתברות של כל מאורע על ממוצע המדגם.
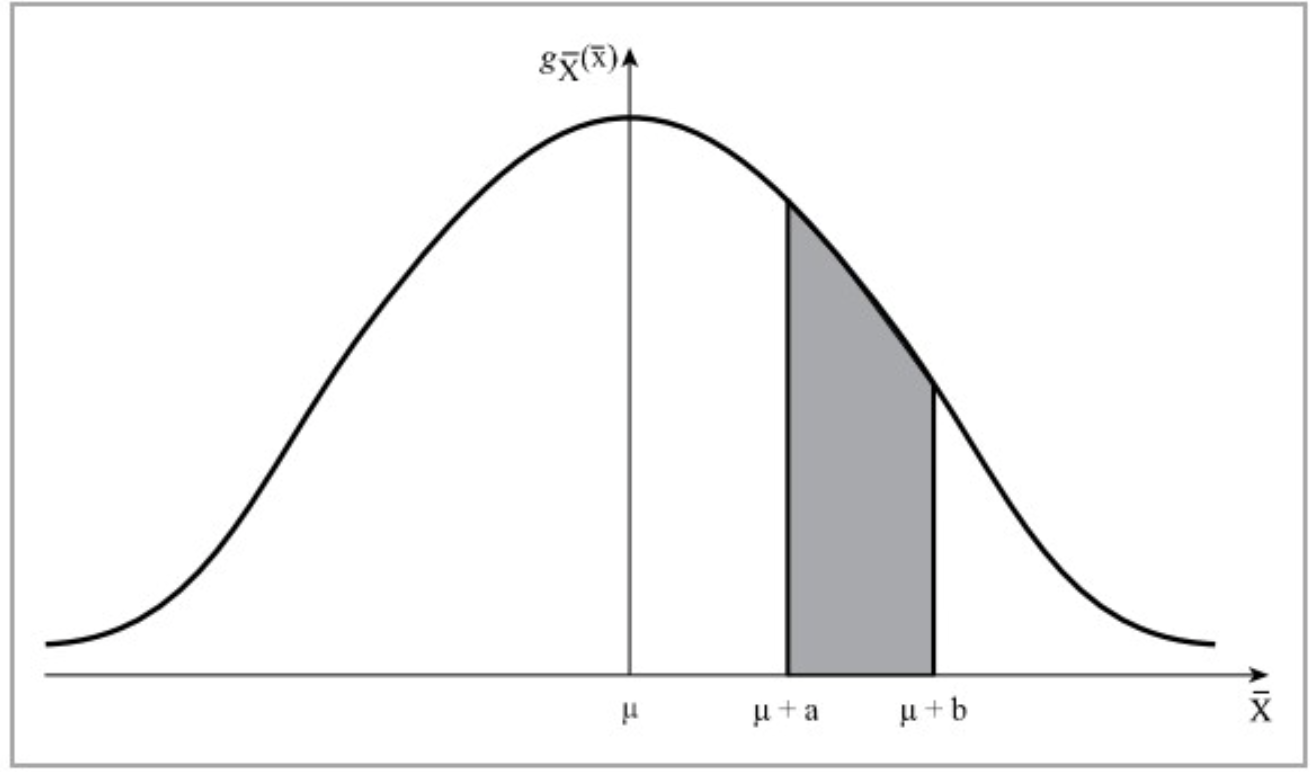
השטח המקווקו הוא הסתברות כפי שאנחנו מכירים ממשתנים מקריים רציפים והשטח המקווקו בתמונה למעלה אינו ניתן להערכה באמצעות אש״צ.
קשה מאוד לחשב את פונקציית ההתפלגות אבל במקרה מיוחד של התפלגות נורמלית הדבר אכן אפשרי.
תזכורת: התפלגות נורמלית
זאת פונקציה דמויית פעמון שיש לה שני פרמטרים: תוחלת
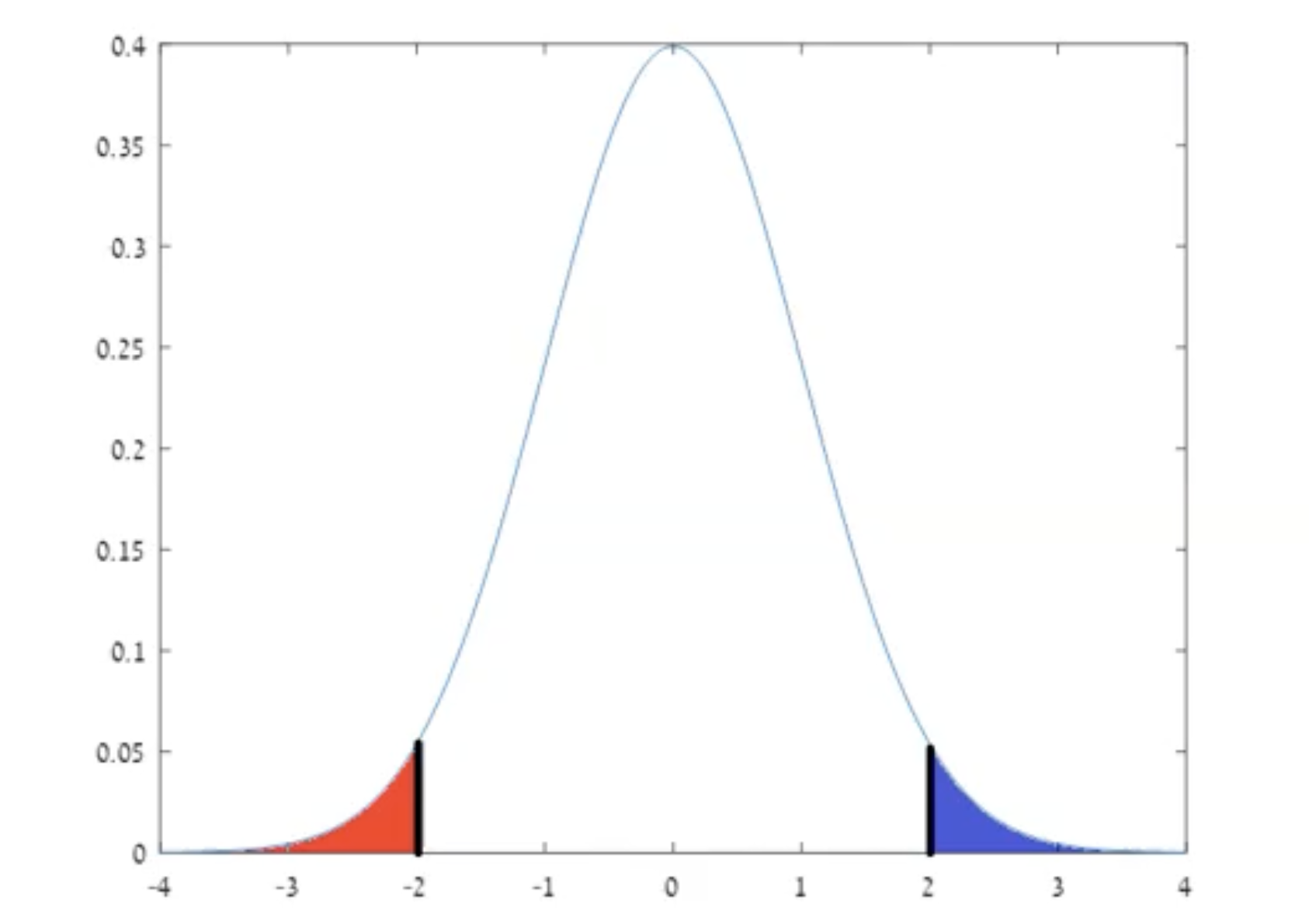
מכל התפלגות נורמלית של משתנה מקרי
נוכל לעשות זאת באמצעות ציון תקן
נזכיר גם שמסמנים ב
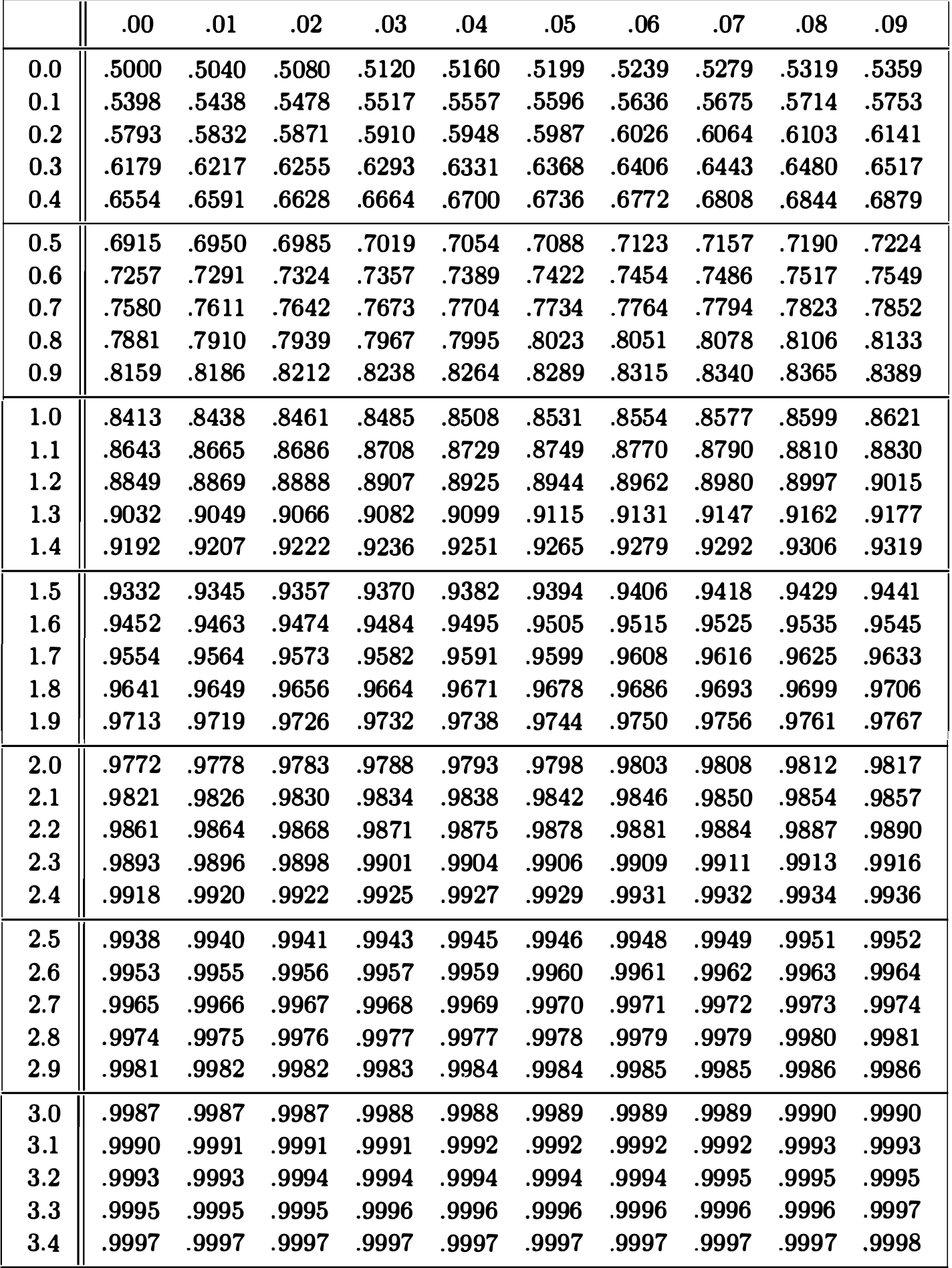
כמו כן, נזכיר את התכונה ש
בדגימת מדגם שגודלו
כלומר:
כלומר נוכל לקחת פרמטר מתפלג נורמלי מהאוכלוסייה ויתקיים עבור ממוצע המדגם שלו
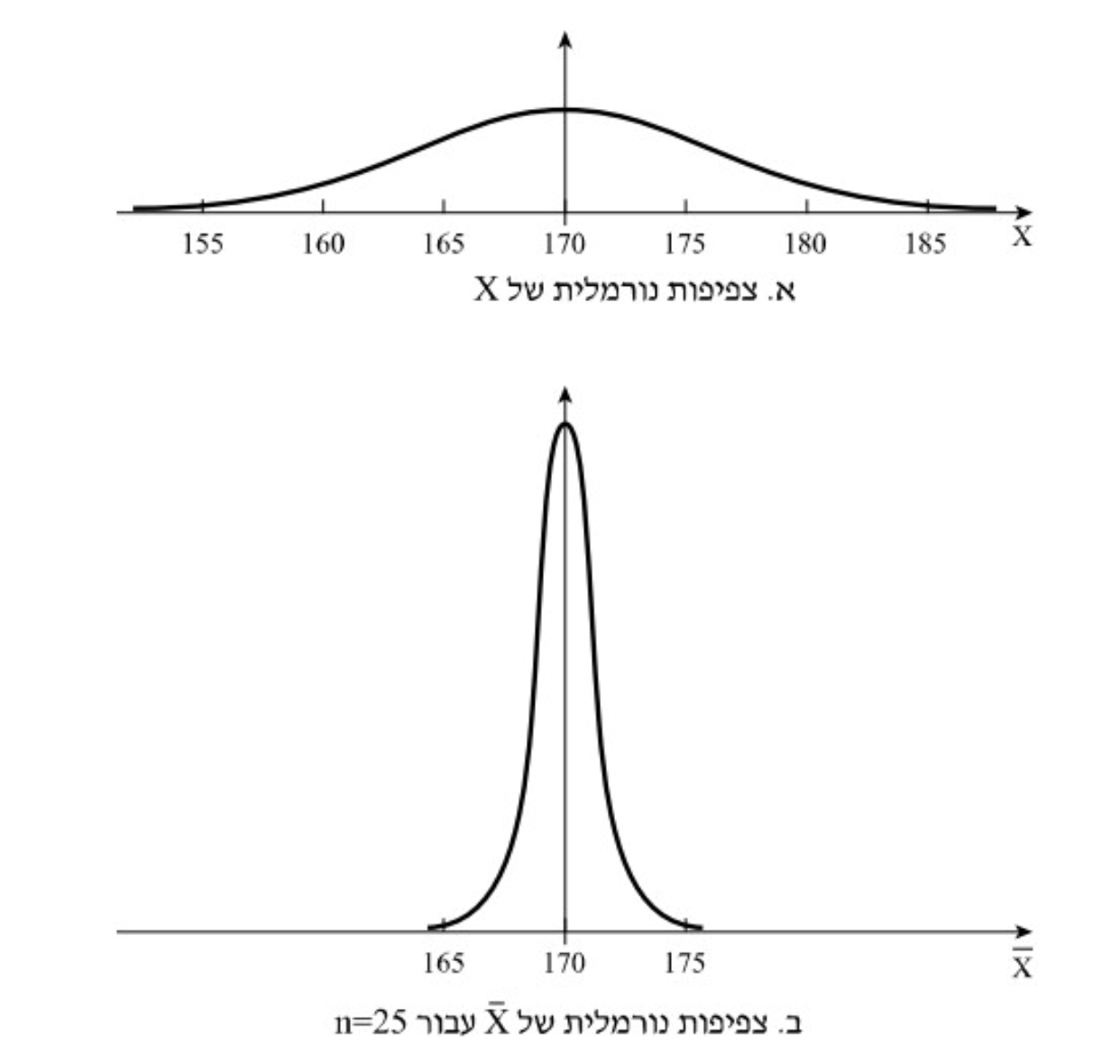
משפט הגבול המרכזי
ראינו כמה דברים שאפשר לומר על התפלגות הדגימה של
א. תוחלת התפלגות זו שווה לתוחלת
ב. שונות התפלגות זו שווה לשונות
ג. ממוצע המדגם מתפלג נורמלית אם
מסתבר, שגם אם
הרעיון זה שאם נבחר מדגם גדול ונחזור על הדגימה פעמים רבות מאוד ונרשום בכל פעם את
יהי
במונחים של גבולות נקבל
זהו אחד המשפטים ההסתברותיים החשוב ביותר לסטטיסטיקה.
הוא מאפשר לנו לחשב הסתברויות הנוגעות לממוצע המדגם הלקוח מתוך מ״מ או מאוכלוסייה כלשהי, גם כאשר המשתנה הנחקר אינו בעל התפלגות נורמלית דווקא, כפי שקורה ברוב המקרים המעשיים. באופן מעשי מתברר שגודל מספיק הוא יותר מ 30.