סטטיסטיקה תיאורית
סטטיסטיקה - תחום ידע העוסק באיסוף,תיאור ועיבור נתונים ובניתוח והצגת מסקנות מהנתונים.
עיבוד הנתונים וניתוחן יכול להעשות בשתי רמות:
- סטטיסטיקה תיאורית: איסוף, ארגון, סיכום והצגת הנתונים.
- סטטיסטיקה היסקית: הסקה מנתוני מדגם לאוכלוסייה כולה, תוך שימוש בתורת ההסתברות.
בסטטיסטיקה תיאורית נרצה לזהות ולהבליט תכונות המאפיינות את אוסף הנתונים, כגון: היכן הם מתרכזים ומהו הפיזור שלהם.
סולמות מדידה
מדידה היא ייצוג מערכת אמפירית על ידי מערכת של ערכים מספריים, כאשר הקשרים בין העצמים המיוצגים חייבים להשתקף ביחסי המספרים המותאמים להם (הקלאסי ביותר הוא יחס סדר). זה נקרא עקרון הייצוגיות.
ישנם מספר מערכות מספריות ולא כולם הם בגדר ״מדידה״. ישנם סולמות מדידה שמנחים אותנו בבחירת המערכת המספרית.
סולם שמי
הצמדה של מספר מזהה לכל יישות במערכת. למשל תיאור של מכונית לפי מספר לוחית הרישוי.
סולם סדר
סולם שמי שיש בין המספרים גם יחס סדר כשלהו. למשל, דרגות בצבא.
נשים לב שאומנם יש יחס סדר בדרגות בצבא אבל אין בין דרגות הפרש מספרי כלשהו כלומר פשוט אנחנו יודעים ש״סרן״ יותר גבוה מ ״טוראי״ אבל לא יודעים בכמה.
סולם רווחים
סולם רווחים הוא סולם סדר שבו לכל שני מספרים ביחס סדר יש פער ברור. למשל במדידות טמפרטורה אנחנו יודעים שאם במדידה הראשונה
סולם מנה
סולם רווחים, שיש לו נקודת אפס קבועה מוחלטת, המבטאת את היעדך התכונה.
נשים לב שבסולם זה כל רמה בסולם מקיימת את כל התכונות של הסולמות שנמוכים יותר ממנה
הצגת התפלגות נתונים בטבלאות ובעקומות
מספר מושגים שחשוב להגדירם:
- קבוע- גודל שערכו אינו משתנה.
- משתנה בדיד- משתנה שיכול לקבל מספר סופי של ערכים
- משתנה רציף- משתנה שיכול לקבל מספר אינסופי של ערכים.
הצגה בטבלאות
נניח שאנחנו מודדים את הטמפרטורה בכל יום במשך חודש וקיבלנו את המדידה הבאה

אומנם זה נראה לנו יחסית נוח לקריאה, אבל אם היינו אוספים דגימות בכמות גבוהה יותר כבר לא היינו מצליחים להבין את המדדים שלנו ולכן נרצה לארגן אותם בצורה נוחה יותר.
טבלת שכיחויות
דרך נוחה לארגן את הנתונים היא ב טבלת שכיחויות
נרשום את ערכי המשתנים מהקטן לגדול בסדר עולה בעמודה אחת ובעמודה השנייה את השכיחות שלהם, כמה פעמים הם הופיעו במדידה שלנו.
אם נסמן את הטמפרטורה כ
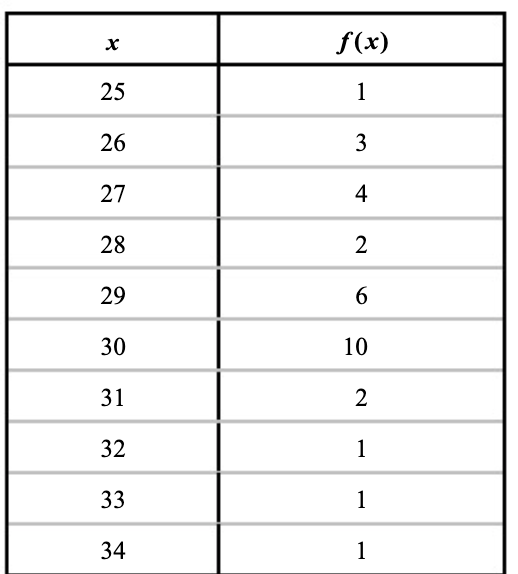
אומנם זה מקל עלינו אבל עדיין, כאשר לוקחים מספר רב של דגימות נקבל טבלה ענקית ולא נוכחה ולכן נגדיר מחלקות של ערכי
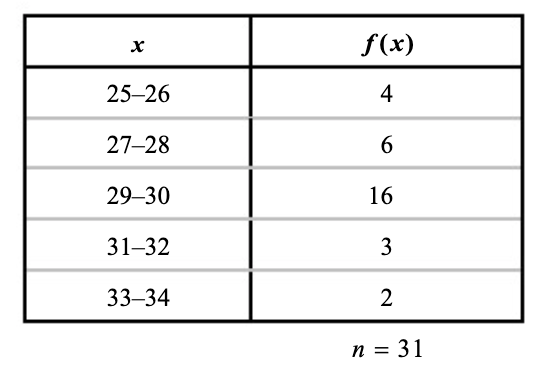
- מחלקות חייבות להיות זרות כלומר בלי איברים משותפים
- החלוקה חייבת להיות ממצה כלומר לכל ערך
ניתן לשייך למחלקה כלשהי
אנחנו משלמים פה מחיר של דיוק במדידה כאשר אנחנו ממירים את טבלת המדידה שלנו מערכים בודדים לטבלה של מחלקות אבל מקבלים תמונה מגובשת ותמציתית יותר של הנתונים
למשל זאת חלוקה שתוביל למדידות לא מדויקות
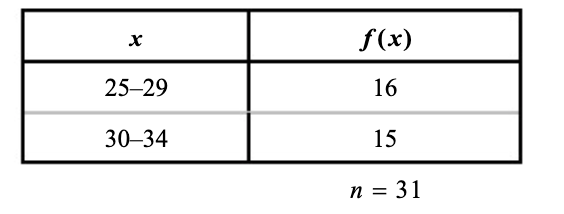
לכל מחלקה יש:
גבול עליון - המספר הגדול ביותר בטווח.
גבול תחתון - המספר הקטן ביותר בטווח.
כאשר הגבול העליון של מחלקה מסויימת אינו זהה לגבול התחתון של המחלקה הבאה, זה נקרא מצב של גבול מדומה.
ניתן לקבל טבלה עם גבולות אמיתיים פשוט על ידי שינוי הטווחים, הקטנת כל גבול תחתון ב
הגדרות על מחלקות
- נסמן את נקודת האמצע של המחלקה כממוצע בין הגבול העליון לגבול התחתון שלה. למשל בטבלה שלנו, במחלקה האחרונה נקודת האמצע תהיה
- לעתים נתקל במחלקות פתוחות בקצוות הטבלה שבהן חסר להן את אחת הגבולות, למשל מחלקה של
עבור ציוני בחינה גבוהים מ . - רוחב של מחלקה
מוגדר להיות ההפרש בין הגבול העליון לגבול התחתון.
כללים לבניית טבלת שכיחויות עם מחלקות ברוחב שווה
- הגדר מספר רצוי של מחלקות
, בהתאם לפיזור הנתונים ובאופן כזה שאיכות החישוב לא תפגע. - נחשב את רוחב המחלקה על ידי
. כלומר, הערך הגבוה ביותר של פחות הערך הנמוך ביותר של חלקי מספר המחלקות הרצוי. יהיה הגבול העליון המדומה במחלקה הגבוהה ביותר. - יש להפחית מערך זה את
ולרשום את הערך שמתקבל כגבול העליון המדומה של המחלקה שמתחתיו, וכן הלאה. - יש להוסיף יחידה (לא תמיד זה
תלוי לפי מה מגדירים) לכל גבול עליון מדומה ולרשום מה הערך שהתקבל כגבול התחתון המדומה של המחלקה שמעליו.
למשל נבנה את הטבלה הנ״ל של נתוני הטמפרטורה ,
נחשב את
נתחיל מ
נשים לב ש
את
| x | f(x) |
|---|---|
| 4 | |
| 6 | |
| 2 |
שכיחות מצטברת
לעתים, בנוסף לשכיחות של כל מחלקה, נרצה לדעת גם מהי השכיחות של הנתונים שהתקבלו מתחת לערך מסויים.
לשם כך אנחנו מגדירות את התפלגות שכיחויות מצטברות. זה מסומך ב
למשל עבור הטבלה שלנו נקבל
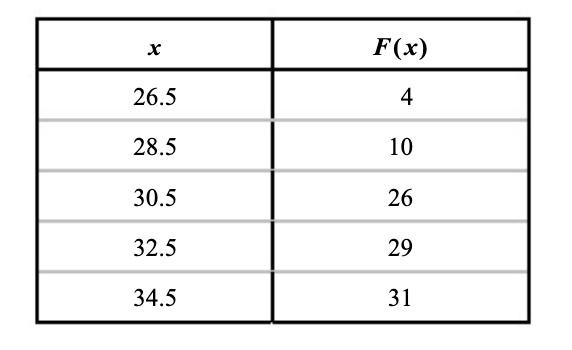
נוכל להעזר ב
כלומר השכיחות המצטברת של אותה מחלקה פחות השכיחות המצטברת של המחלקה הקודמת לה.
נשים לב שמתקיים
כאשר
שכיחות יחסית
התפלגות השכיחות יחסית מוגדרת להיות
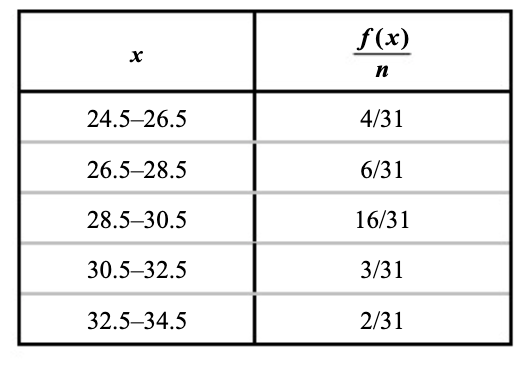
הצגה חזותית של התפלגות נתונים
דיאגרמת עמודות
תרשים במערכת צירים כאשר באופקי נמצאים ערכי המשתנה
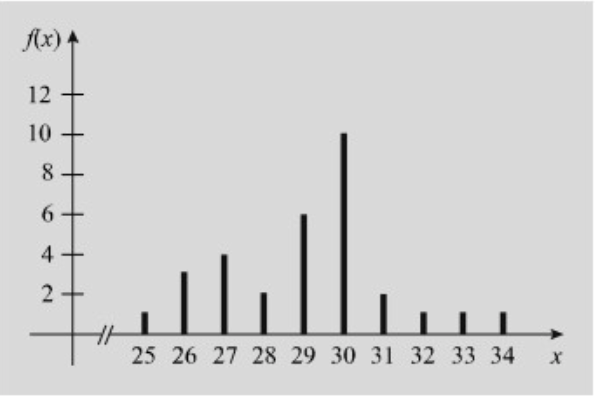
וכמובן שאפשר גם לתאר דיאגרמה דומה עבור מחלקות.
היסטוגרמה
זהה לדיאגרמת עמודות רק שטח המלבן מייצג את שכיחות המחלקה
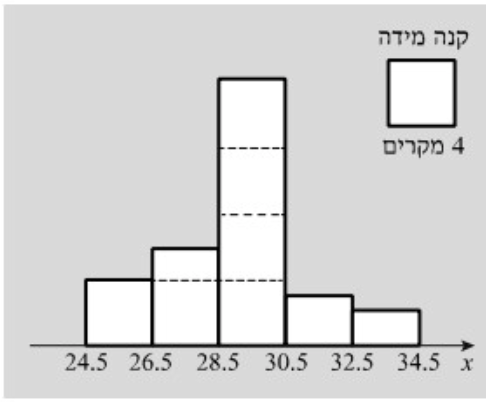
דיאגרמת עוגה
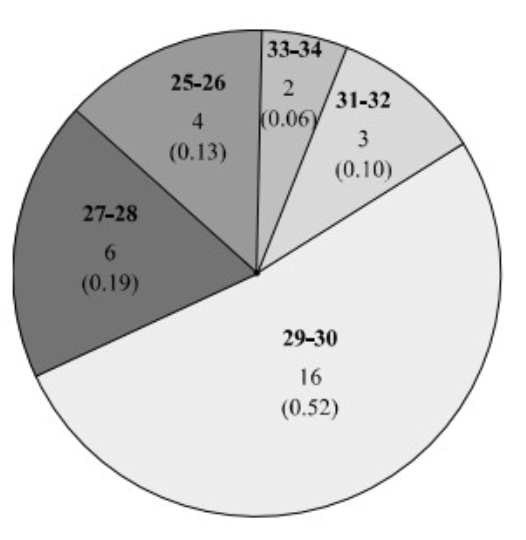
דיאגרמה זו נוחה לתיאור של שכיחויות יחסיות כאשר העיגול הכולל מייצג
בדיאגרמת מקלות נהוג לחבר בקטעים ישרים את ראשי המקלות, ובהיסטוגרמה נהוג לחבר את מרכזי הבסיסים העליונים של המלבנים. הקו השבור המתקבל נקרא מצולע
המטרה היא להגיע לעקומה כמה שיותר חלקה, זה יקרה ככל שההיסטוגרמה מפורטת יותר.
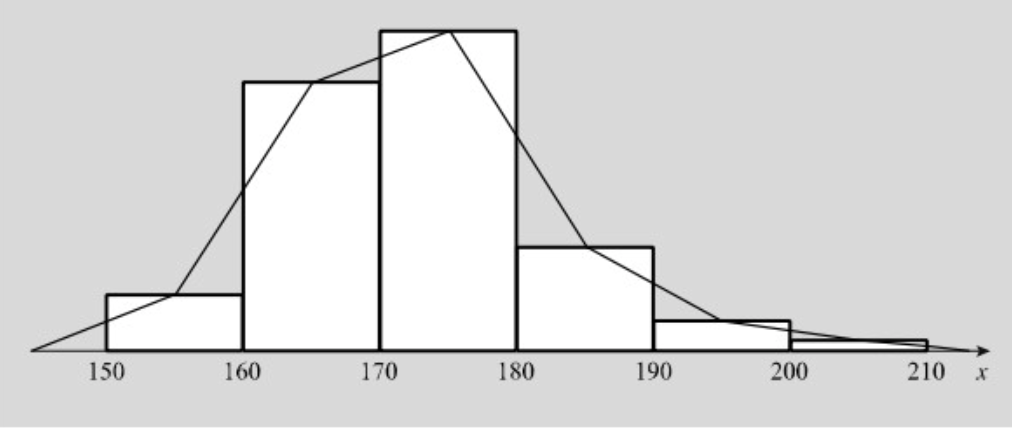
סוגי עקומות
כאשר מציירים עקומה רציפה לתיאור נתוניפ אמפיריים, מהווה הקו הרציף רק קירוב טוב למצולע. הקירוב יהיה טוב ככל במספר הנתונים במדגם גדול יותר ורוחב המחלקות קטן יותר.
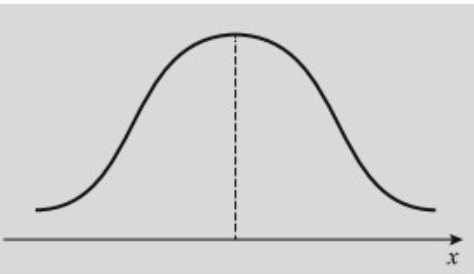
נהוג להבחין בין סוגי עקומות שונות:
עקומה סימטרית פעמונית: מצב בו רוב התצפיות מצטופפות במרכז ערכי
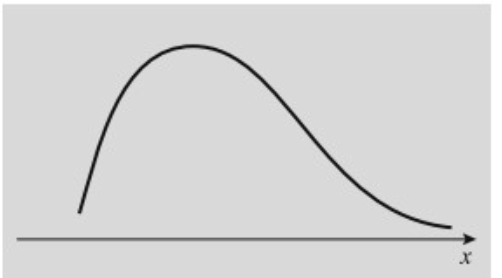
עקומה אסימטרית חיובית/ימנית: מצב בו הסטיות הגדולות הן כלפי ערכים גבוהים של
עקומה אסימטרית שלילית/שמאלית: הסטיות הגדולות הן כלפי ערכים נמוכים של
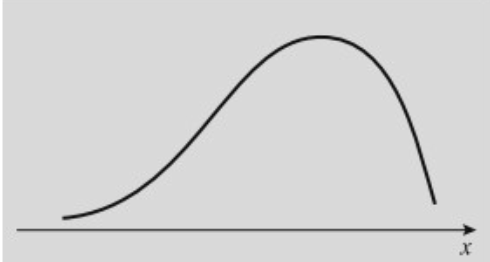
עקומה אחידה: כאשר ערכי

עקומת U: מרבית התצפיות נמצאות בשוליים.
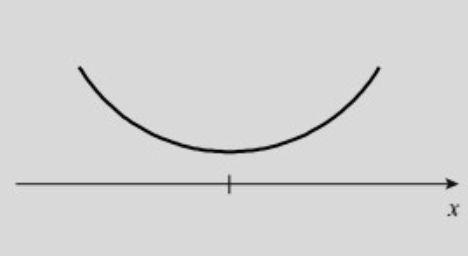
מדדי מיקום מרכזי
כעת שאנחנו יודעים לתאר את הנתונים באופן חזותי, נרצה לענות על שאלות העוסקות במיקום הנתונים ובערכים מסויימים שסביבם הם מתרכזים.
מדדי מיקום מרכזי הם מדדים המצביעים על מיקומו של ״המרכז״ והנטייה למרכז.
קיימים ארבעה מדדים כאלה:
שכיח
אמצע הטווח
חציון
ממוצע
נרצה לדעת אילו מהמדדים הללו יהיה ההולם ביותר לייצר את ה״מרכז״ בהתאם לנתונים שלנו. לשם כך מקובל להעזר פונקציית הפסד או ב פונקציית סיכון והמדד ההולם יהיה המדד שיפחית את ההפסד או הסיכון למינימום.
פונקציות הפסד
מתייחסים למדד
נגיד שהניבוי/ייצוג יהיה קולע יותר ככל ש
לא נוכל בעזרת בחירה מתאימה אחת להקטין את כולן גם יחס וכן נכנס לתמונה פונקציית ההפסד או פונקציית הסיכון. שאלו פונקציות שהקלט שלהן הוא סדרת ההפרשים
מספר שגיאות
פונקציית ההפסד היא סה״כ מספר השגיאות כאשר שגיאה מוגדרת להיות מצב שבו
קל לראות, שבמצב הזה השכיח הוא המדד הטוב ביותר מבין כל המדדים האפשריים.
גודל שגיאה מקסימלית
נגדיר את פונקציית ההפסד להיות
כלומר המרחק המקסימלי מהמדד.
במצב זה, אמצע הטווח
סכום השגיאות המוחלטות
לגבי כל תצפית בודקים מהו גודל השגיאה ונגדיר את ההפסד להיות סכום כל השגיאות כלומר
במצב זה, החציון הוא המדד הטוב ביותר לניבוי.
סכום ריבועי השגיאות
באותו אופן נגדיר את פונקציית ההפסד להיות
במצב זה, הממוצע הוא המדד הטוב ביותר לניבוי מבין כל המדדים האפשריים.
לסיכום:
| פונקציית הפסד | |
|---|---|
| מינימום מספר שגיאות | |
| מינימום שגיאה מקסימלית | |
| מינימום סכום שגיאות מוחלטות | |
| מינמום סכום ריבועי השגיאות |
חישוב המדדים
שכיח
שכיח הוא פשוט הערך שיקיים
אמצע הטווח
חציון
כאשר נתונה רשימת תצפיות שסודרו בסדר עולה, החציון הוא ערך התצפית המרכזית אם מספר התצפיות הוא אי זוגי. אם מספרן זוגי, החציון הוא ממוצע ערכיהן של שתי התצפיות המרכזיות.
למשל עבור סדרת התצפיות הבאות
מספר התצפיות הוא אי זוגי ויתקיים ש
עבור סדרת התצפיות
סדרת התצפיות כעת היא
ערכי התצפיות במיקום אלו הם
באופן כללי:
חציון כאשר נתונה טבלת שכיחויות
כאשר נרצה למצוא את החציון בהינתן טבלת שכיחויות עם מחלקות, המקרה קצת מורכב יותר. החציון הוא אותה נקודה בהיסטוגרמה אשר השטח משמאלה שווה לשטח מימינה.
כאשר:
לדוגמה עבור טבלת השכיחויות הבאה
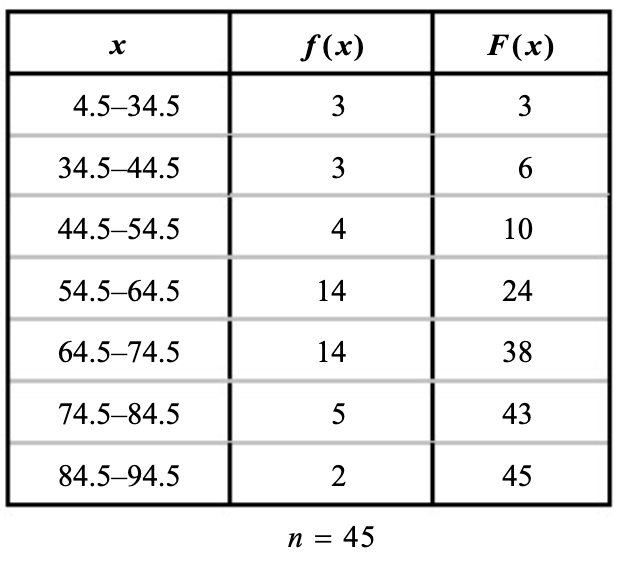
נשים לב שישנן
כדי לדעת באיזה מחלקה נמצא ערך זה נשתמש בהתפלגות מצטברת
עד ל
ברגע שמצאנו את המחלקה, כבר קל להציב את כל מה שצריך בנוסחה.
ניתן להכליל את הנוסחה עוד יותר כדי למצוא את
ממוצע
ממוצע בהינתן
כלומר סכימה של התצפיות וחלוקה במספרן.
במצב של טבלת שכיחויות/שיכחות יחסית שבה לכל מחלקה יש רק ערך אחד
כאשר ישנם
אנחנו משלמים פה מחיר של סטייה כלשהי מהממוצע שכן לא בהכרח שנקודת האמצע היא מדד אמין למה קורה בתוך המחלקה. אך זה מחיר שאנחנו מוכנים לשלם.
סכום הסטיות מהממוצע הוא
למעשה זאת גם ההגדרה של הממוצע, הממוצע הוא אותו ערך שסכום הסטיות ממנו שווה לאפס
רגישות לערכים קיצוניים של מדדים
כבר דיברנו על תכונה אחת של מדדים שהיא הפחתת פונקציית ההפסד המתאימה לו למינימום.
כעת נסתכל כיצד המדדים משתנים בהתאם להתפלגויות השונות.
כאשר ההתפלגות פעמונית
כל המדדים שווים אחד לשני ומתלכדים באותה נקודה.
כאשר ההתפלגות אסימטרית חיובית
הממוצע ואמצע הטווח גדולים מהחציון ומהשכיח כלומר
כאשר ההתפלגות אסימטרית שלילית
הממוצע ואמצע הטווח קטנים מהחציון ומהשכיח כלומר
הדבר נובע מכך שהשכיח והחציון נשענים יותר על השכיחות של ערכים ואילו הממוצע ואמצע הטווח נשענים יותר על הערכים עצמם. כלומר האחרונים יותר מושפעים מערכים קיצוניים.
לכן גם יש סולמות מדידה שבהם לא ניתן לחשב בכלל ממוצע ואמצע טווח כמו סולם שמי.
ממוצע וטרנספורמציה ליניארית
טרנספורמציה ליניארית מ
האיפיון העיקרי של טרנספורמציה כזו היא שייצוגה הגרפי הוא קו ישר בעל שיפוע
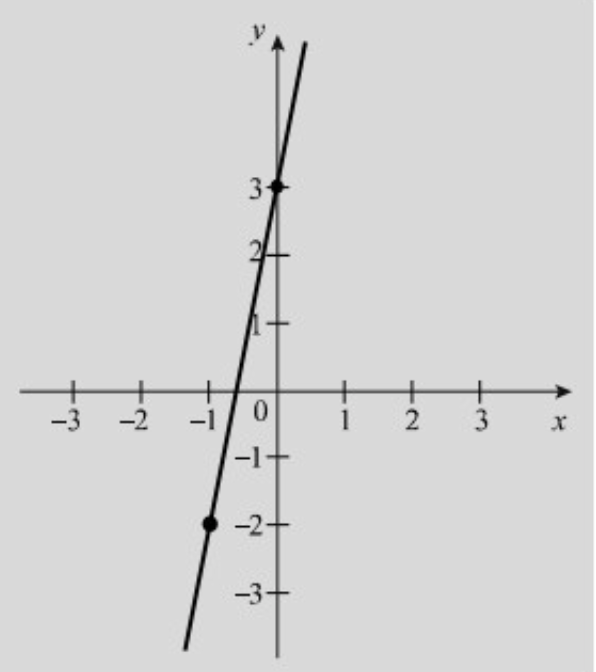
משפט
בהינתן משתנה
מדדי פיזור
בהתפלגויות מבוססות שכיחויות, מלבד המיקום המרכזי של מרכז ההתפלגות חשוב מאוד גם לעקוב אחר מידת הפיזור. למשל ההתפלגויות בתמונה למטה מתלכדות באותו מיקום מרכזי אך במידת פיזור שונה.
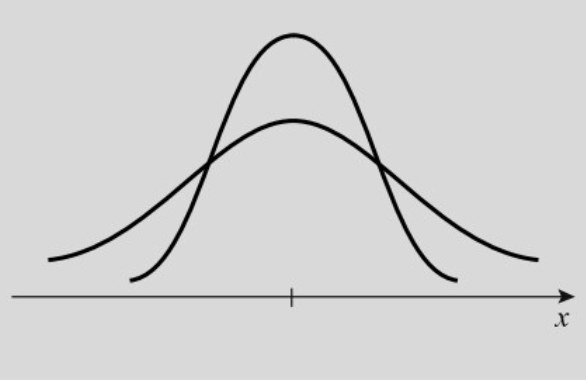
מדדים אלו נועדו לתאר את מידת השוני או האחידות בין נתונים.
הביטוי ״פיזור״ משמש אותנו לציון מרחק הערכים השונים של המשתנה ומרחק ממדד כלשהו למיקום מרכזי.
חוקי מדדי הפיזור
א. מדד פיזור חייב להיות בעל ערכים אי שליליים
ב. מדד הפיזור מתאפס אמ״מ כל התצפיות זהות זו לזו.
ג. הוספת קבוע לכל התצפיות לא תשנה את ערכו של מדד הפיזור.
אחוז השגיאות
אחוז התצפיות שבהן מתקבל ערך שונה מערך השכיח.
מבוסס על פונקציית ההפסד המוגדרת על פי מספר השגיאות.
גודל השגיאה המקסימלית
זהה לפונקציית ההפסד עליה כבר דיברנו. מוגדר על ידי
מדד זה מינימלי כאשר אם המדד למיקום המרכזי הוא אמצע הטווח
הטווח
נגדיר את
מדד זה דומה בטבעו למדד הפיזור הקודם, אך מקובל יותר. כלומר
נשים לב שגודל הסטייה המקסימלי מאמצע הטווח הוא
נשים לב שגם הטווח וגם גודל השגיאה המקסימלית מורכב רק מערכים קיצוניים ולכן שגיאות אלו יכולות להיות בעיתיות כאשר הצפיפות היא רובה במרכז ויש מיעוט בקצוות מרוחקים
הטווח הבינרבעוני
נסמן את הטווח הבינרבעוני כ
כלומר, כדי לחשב את מדד הפיזור, רושמים את ההפרש בין הערך ש
בעצם זה זהה לנוסחה של מציאת החציון רק שהפעם אנחנו עובדים עם המחלקה הרלוונטית לאותו רבעון, המחלקה הקודמת לה, והגבולות הרלוונטים.
את הטווח הבינרבועני אפשר לתאר באמצעות דיאגרמת boxplot
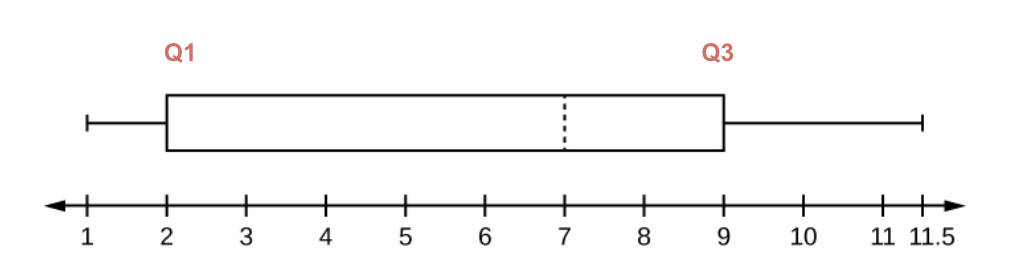
כאשר הקו המקווקו זה החציון. והקצוות זה המינימום והמקסימום של המדידות.
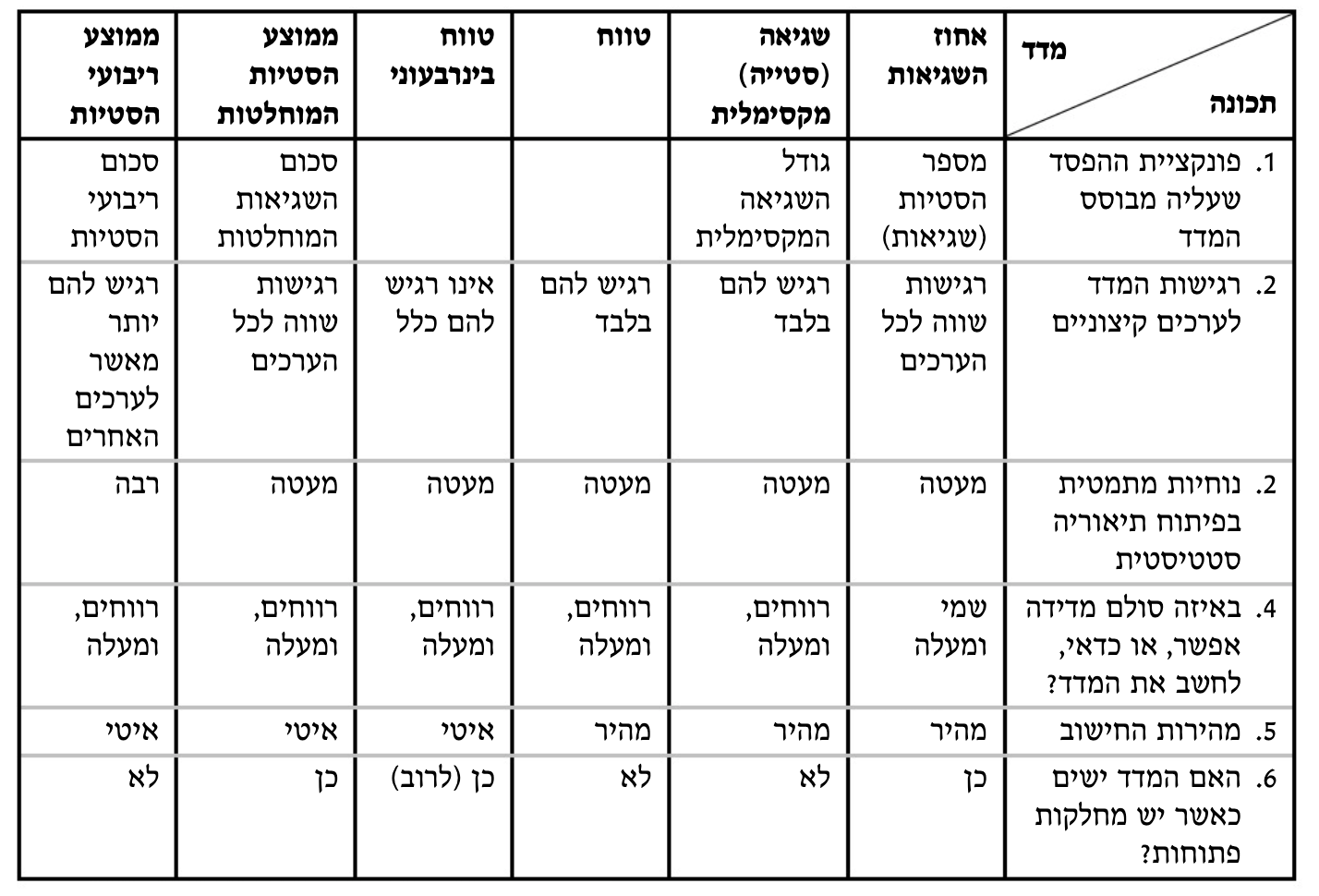
ממוצע הסטיות המוחלטות
המדדים שהצגנו לעיל, התחשבו או בקצוות או רק בחלק מהתצפיות. נרצה מדדי פיזור שלוקחים בחשבון את כל התצפיות אך יהיה מסוכן לקחת לדוגמה את סכום מרחקי השגיאות ממדד מיקום מרכזי שכן מרחקים שליליים ומרחקים חיוביים יתקזזו.
לכן, נוכל לסכום בערך מוחלט וכדי לאפשר השוואה של פיזור בהתפלגויות בעלות מספר תצפיות שונה נשתמש בממוצע הסטיות כלומר
כאמור, מדד זה מינימלי כאשר
ממוצע ריבועי הסטיות
באותו אופן נוכל לעבוד עם
מדד זה מבוסס על פונקציית ההפס שהיא סכום ריבועי השגיאות והוא מינימלי כאשר
לסיכום מדדי השגיאות
שונות וסטיית תקן
ממוצע ריבועי הסטיות מהממוצע מכונה variance
השונות במדגם בהתפלגות שכיחויות מסומנת
שונות של מדגם מוגדרת להיות
במילים, השונות היא ממוצע הריבעוים פחות ריבוע הממוצע.
בגלל ההעלאה בריבוע יחידות המידה של התצפיות מתעוותות לנו ולכן נגדיר גם סטיית תקן שהיא השורש של השונות.
כאשר אין שכיחויות:
סכום כל ערכי התצפיות שווה לממוצע כפול מספר התצפיות
טרנספורמצייה ליניארית על משתנה
ממוצע משוקלל ושונות מצורפת
לעתים מידע נאסף ממקורות רבים, הדיווח על ממוצע ועל שונות של משתנה מסוים מגיע לעתים קרובות מכל מקוד בנפרד. למשל מנהל בית ספר מקבל את ממוצע הציונים במתמטיקה ועל שונותם בכל אחת מכיתות י״א שבבית ספרו.
סביר להניח שהמנהל ירצה גם את ממוצע הציונים של כל התלמידים בשכבה זו בלי ההבחנה בין הכתות.
לשם כך ישנם כלים שעוזרים לנו לחשב כאשר ישנה החשיבות של גודל כל קבוצה ביחס לכלל הקבוצות.
נסמן:
ממוצע משוקלל
חישוב הממוצע המשוקלל יהיה פשוט סכימה של הציונים במתמטיקה של כל תלמידי הכתות ואת התוצאה נחלק במספר התלמידים הכולל. כלומר
אנחנו יודעים ש
אם כל גדלי הקבוצות שווים כלומר
שונות מצורפת
חישוב השונות של ציוני כל התלמידים יהיה
נוכל לפשט ולקבל
כלומר החיבור בין ממוצע משוקלל של השונויות לבין פיזור הממוצעים של הכתות שונות לפי מרחק ריבועי.
אם הממוצעים שווים בכל הכתות אז השונות המצרופת בין הכתות קטנה יותר ומושפעת רק על ידי הממוצע המשוקלל של השונויות. שכן המחובר השני מתבטל לגמרי
מדדי מיקום יחסי
נרצה לבטא את ערכי ההתפלגות כערכים יחסיים (ביחס להתפלגות) וטהורים (שאינם תלויים ביחידות מידה) כאשר נרצה להשוות התפלגויות שונות.
נגדיר מדדי מיקום יחסיים מאון ו ציון תקן.
מאון
המאון ה
ראינו שמתקיים ש
כעת נראה כיצד לחשב את
הסימון
נוכל לחלץ את
ציון תקן
ציון תקן של
במצב זה נוכל להשוות כל ערך של משתנה בהתפלגות כלשהו לערך של משתנה בהתפלגות אחרת ולקבוע את היחס בינהם בהתאם ליחידות של סטיית תקן.
ממוצע התפלגות ציוני התקן
שונות התפלגות ציוני התקן
מדדי קשר
נרצה דרך לחשב את עוצמת הקשר בין נתונים. כלומר באיזה מידע ערך של משתנה
נדון במדדי קשר מבוססים סכום ריבועי השגיאות, כל פונקציית הפסד כזאת או אחרת הייתה יכולה לעזור לנו אך נתמקד בפונקציית ההפסד הנ״ל.
כלומר, אם לכל ערך
ונרצה שככל שהערך גדול יותר ככה הקשר חלש יותר.
נתמקד במדד המתאים למשתנים
הדרך לניבוי היא חישוב
מדד זה נקרא מקדם המתאם של פירסון ונסמנו
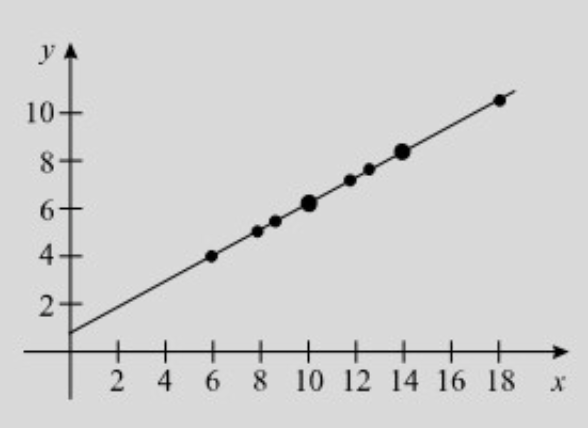
נסתכל על גרף המתאר את ערכי
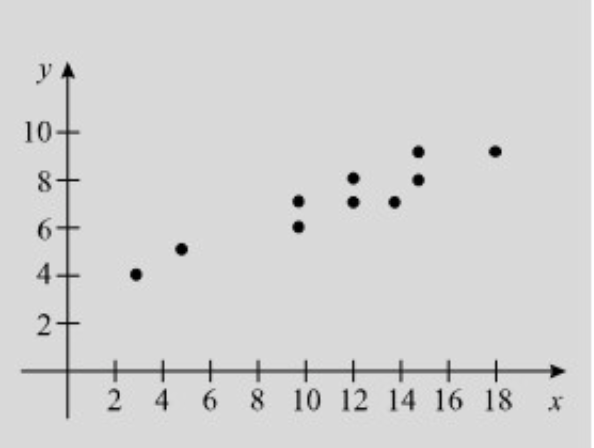
ניתן לראות שישנו קשר ליניארי קווי לא מושלם בין
כאשר הקו הוא ישר לגמרי הקשר נקרא ליניארי מושלם
דוגמאות לקשרים:
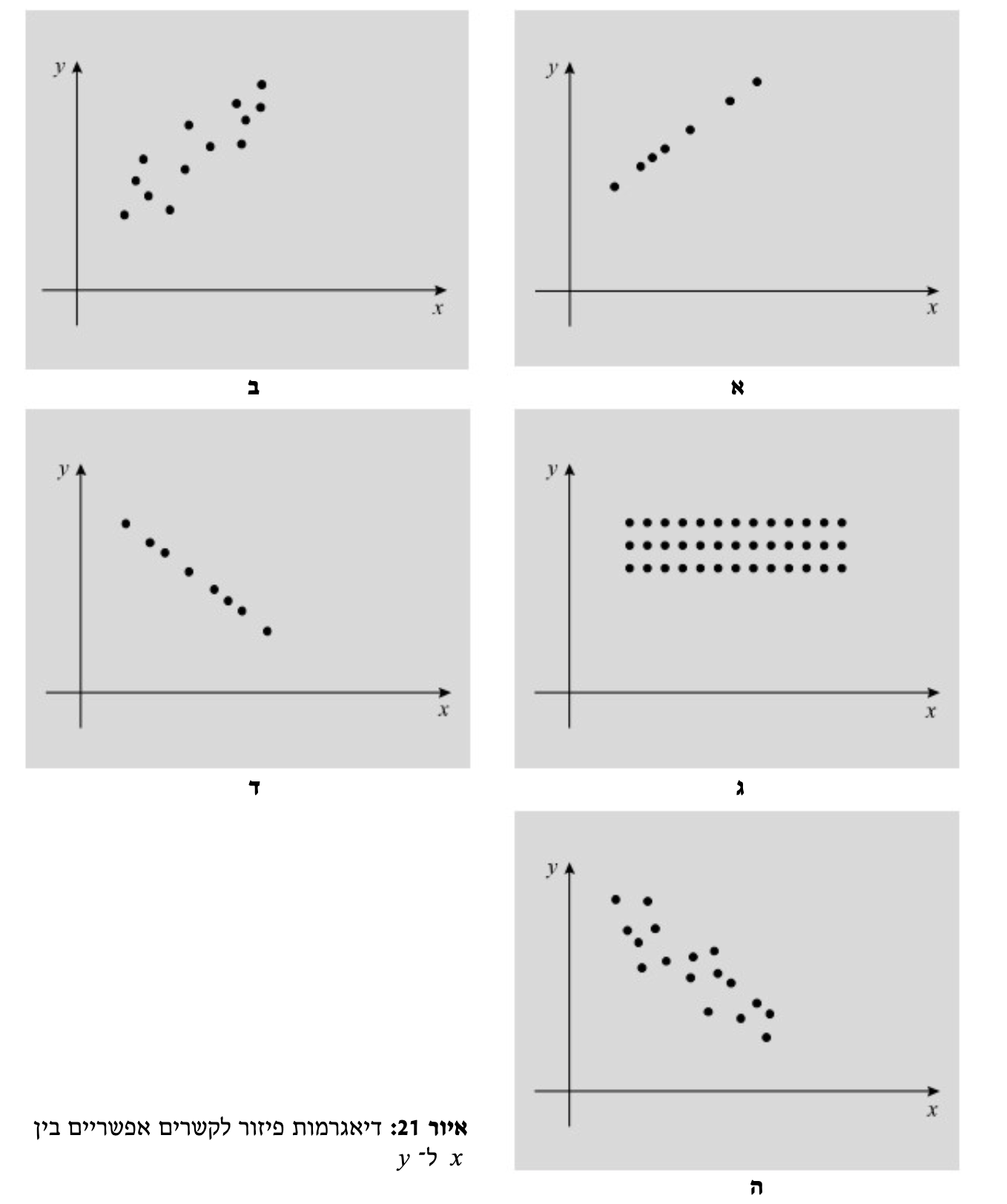
אומנם באופן ויזואלי קל לראות מתי הקשר שלילי (ה) חלקי או חיובי חלקי (ב) או בכלל חזק לגמרי(א,ד) או שבכלל אין קשר (ג)
אבל נרצה לבטא זאת באופן מתמטי כך
מקדם המתאם של פירסון נע בין
השונות המשותפת
השונות המשותפת של שני משתנים מוגדרת על ידי
השם נובע מכך שאיברי הסכום הם מכפלות הסטייה של
ולכן
אפשר לפתח את השונות המשותפת ולקבל ביטוי קצת יותר נוח:
שזה בעצם ממוצע המכפלות פחות מכפלת הממוצעים.
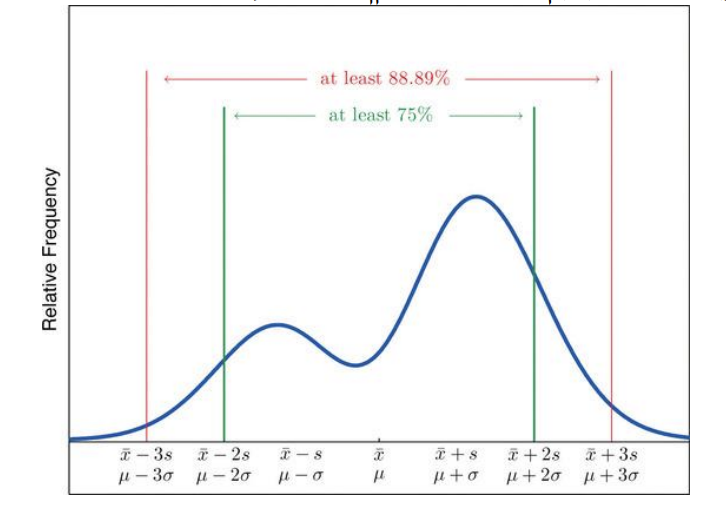
תאוריית צבישב והחוק האמפיקי
עבור עקומת פעמון
- *
מהערכים הם במרחק של עד סטיית תקן אחת מהממוצע. מהערכים הם במרחק של עד 2 סטיות תקן מהממוצע
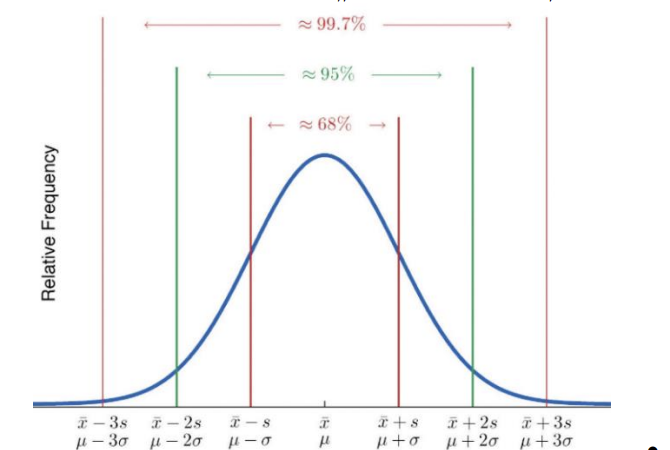
באופן כללי
מהערכים הם במרחק של עד 2 סטיות תקן מהממוצע מהערכים הם במרחק של עד סטיות תקן מהממוצע