נרצה לדון ולהבין בבעיות מרכזיות שעוסקות בחסמים של סדרות של משתנים רציפים.
עיקר הדיון יעשה סביב רצף של משתנים מקריים בלתי תלויים שמתפלגים באופן זהה עם תוחלת ושונות .
כעת, יהי
מליניאריות התוחלת אנחנו יודעים ש .
הסכום של המשתנים הראשונים. משפטי הגבול עוסקים בעיקר בתכונות של ומשתנים מקריים נוספים כאשר הוא מספר גדול מאוד. בגלל אי תלות נקבל
כלומר ככל ש גדל ההתפזרות של הערכים סביב התוחלת המשותפת גדלה ואין לה גבול שנותן לנו משמעות. הסיטואציה משתנה אם מסתכלים על הערך הממוצע
אם נחשב אנחנו נראה ש
כלומר עבור מתקיים שהשונות שלה קרבה ל ככל ש גדל כלומר התפזרות הערכים יותר שואפת ל ככל שכמות הערכים שמוסיפים גדלה. אם כן הצלחנו ליצור משתנה מקרי שמתכנס לתוחלת האמיתית באופן די מדויק.
החוקים האלה מהווים בסיס מתמטי לפרשנות של התוחלת כממוצע של מספר גדול מאוד של דגימות בלתי תלויות שנלקחות מההתפזרות של .
נסתכל גם על משתנה כמותי שמשמש כערך ביניים בין ל . ראשית נחסר מ את כדי לקבל משתנה חדש עם תוחלת : . לאחר מכן נחלק אותו ב כדי לקבל את המשתנה המקרי
אפשר לראות שמתקיים
זה משתנה שערכו לא משתנה לא משנה כמה פעמים נגדיל את . משפט הגבול המכרזי בודק ושואל על ההתפזרות של ועל האופן שבו הוא חוסם ומבטיח שזוהי תהיה התפלגות נורמלית.
משפטי הגבול עוזרים לנו במספר סיבות:
קונספטואלית, הם נותנים לנו אינטרפטצייה לתוחלת (בנוסף להסתברויות) במונחים של רצף ארוך של משתנים מקריים זהים ובלתי תלויים , למשל לשאול המון המון אנשים את הגובה שלהם יכול להביא לנו את הגובה הממוצע באזור שבו שאלנו.
הם מאפשרים לנו ניתוח מוערך של תכונות של משתנים מקריים כמו . זה בניגוד לניתוח מדויק שהיה דורש נוסחה של PMF ו PDF עבור שזו מטלה מאתגרת כאשר הוא גדול מאוד
יש להם תפקיד מרכזי בניתוחים סטטיסטיים כאשר יש מספר גדול מאוד של מידע.
לפני שנכנס לכל החוקים שדיברנו עליהם למעלה, שנקרא גם החוק החלש של המספרים הגדולים (WLLN), נרצה לפתח מספר אי שיוויונות שיעזרו לנו לנתח הסתברויות קצה. האי שיוויונות שנציג יהיו יעילים כאשר נוכל לחשב את הערכים המדוייקים או החסמים של התוחלת והשונות של משתנה מקרי אבל ההתפלגות של לא ברורה או קשה לחישוב.
אי שוויון מרקוב (Markov inequality)
האי שיוויון הראשון שנתמקד בו הוא אי שיוויון מרקוב באופן מופשט, הוא מבטיח ש אם משתנה מקרי אי שלילי הוא עם תוחלת מאוד קטנה, אז ההסתברות שיהיה לו ערך גבוה חייב להיות קטן.
יהי משתנה מקרי אי שלילי אזי :
הוכחה:
יהי נגדיר משתנה מקרי שמוגדר כך
מההגדרה מתקיים ש תמיד ולכן
מצד שני
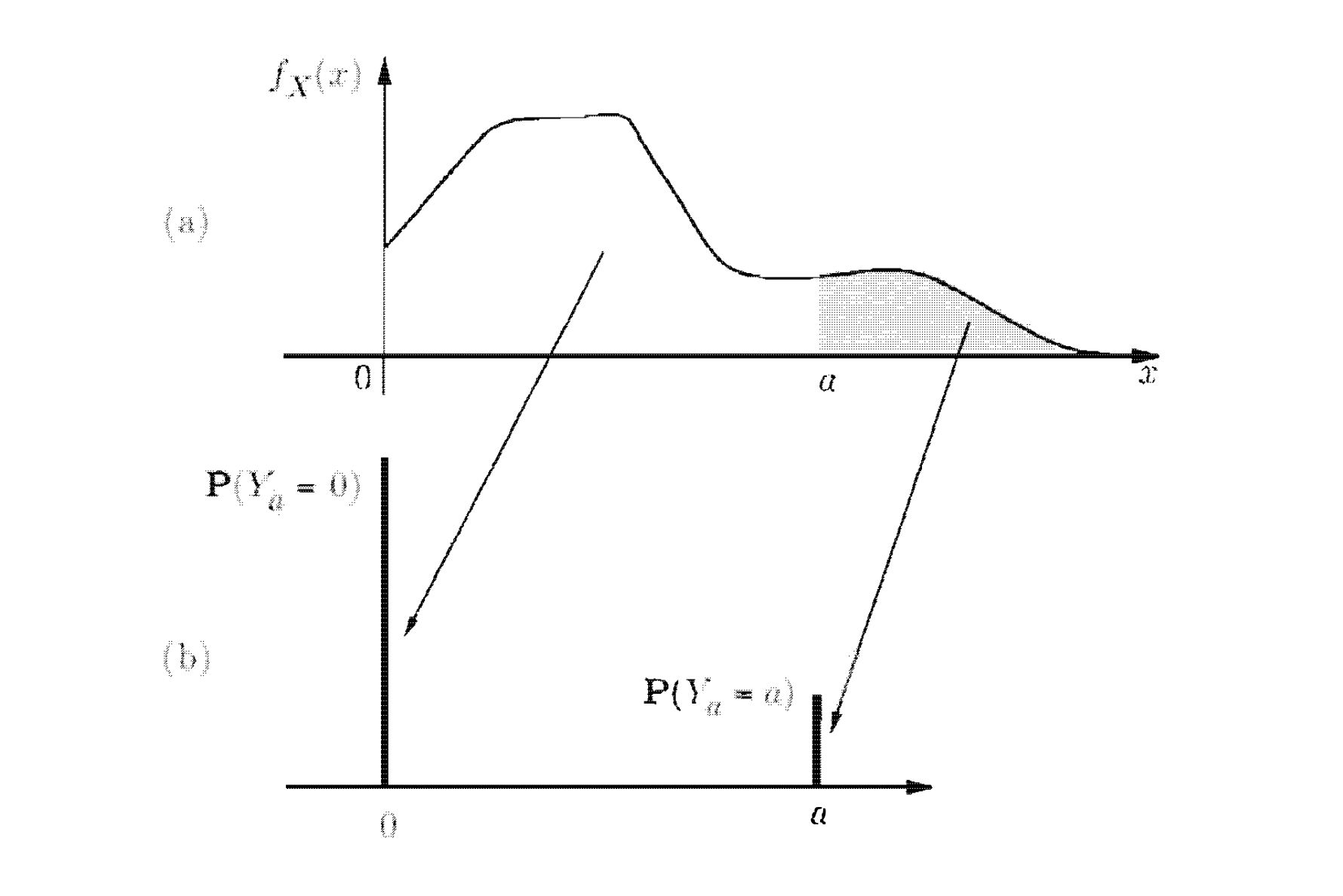
בתמונה ניתן לראות דוגמה לאי שיוויון זה. למעלה זה ה PDF של משתנה מקרי אי שלילי ולמטה ה PMF של . ההרכבה של נעשה על ידי הפרדה בין הצפיפות של ה של בין ל על ידי שיוך ל בפונקציית מסת ההסתברות, וכל מי שגדול או שווה ל בפונקציית הצפיפות משוייך ל . כלומר אנחנו מקטינים את המסה על ידי הזזה שמאלה ל או ל ולכן תמיד יתקיים
דוגמה:
יהי משתנה מתפלג אחיד באינטרוול ונניח ש . אי שיוויון מרקוב מבטיח ש
במקרה הזה אנחנו יודעים כיצד מתפלג ולכן נוכל לחשב ישירות ולאמת את האי שיווין
אם כן , האי שיווינים נכונים אבל הם יכולים להיות בטווחים גדולים מדי לעתים.
אי שוויון צבישב (Chebyshev inequality)
אי שיוויון זה, באופן מופשט, מבטיח שאם משתנה מקרי הוא עם תוחלת נמוכה, אז ההסתברות שהוא ייקח ערך שרחוק מהתוחלת שלו היא גם כן נמוכה. אי שיוויון זה לא מצריך שהמשתנה המקרי יהיה אי שלילי
יהי משתנה מקרי עם תוחלת ושונות אזי
אפשר לראות שבאופן מתמטי זה הוא מקרה פרטי של אי שיוויון מרקוב. ובמילים המשמעות היא אם השונות קטנה , אז באופן סביר לא יהיה רחוק מהתוחלת . שזה מסר קצת אחר מאי שיוויון מרקוב.
הוכחה:
נגדיר משתנה מקרי ונפעיל את אי שיוויון מרקוב על , נקבל :
האי שיוויון שקול למאורע ולכן נוכל פשוט להחליף את הנ״ל בהסתברות הדרושה.
מקרה פרטי של אי שוויון צבישב יהיה מהצורה כאשר . זה יקיים
כלומר ההסתברות שהמרחק של מהתוחלת להיות פעמים השונות שלו היא לכל היותר .
אי שיוויון צבישב נוטה להיות חזק יותר מאי שיוויון מרקוב (החסמים שהוא נותן מדוייקים יותר), בגלל שהוא משתמש במידע מהשונות של . עדיין, השונות והתוחלת של משתנה הן רק חלק קטן מהמידע שיש לנו על משתנה מקרי ולכן אין לצפות לחסמים מדוייקים למדי.
חסם עליון של אי שיוויון צבישב
כאשר נצמא בטווח ערכים נאמר ש
נוכיח את הטענה שהבאנו על החסם של , ניקח קבוע כלשהו ונשים לב שמתקיים
אם אז זה ערך מינימלי כיווון שנוכל להסתכל על הנ״ל כפונקצייה ריבועית של ונקבל
קל לראות שהמינימום של הפונקצייה הזאת מתקבל כאשר כלומר כאשר . אם כן,
אם נציב נקבל
המעבר האחרון נכון כי מהטווח ערכים של נקבל
משלים של אי שיוויון צ׳בישב
נשים לב שבעזרת אי שיוויון צ׳בישב אפשר לחשב חסם תחתון להסתברות עבור מקרי האמצע בעזרת אותה נוסחה:
הוכחה:
החוק החלש של המספרים הגדולים
החוק החלש של המספרים הגדולים מבטיח שממוצע המדגם של מספר גבוה של משתנים בלתי תלויים שמתפלגים באופן זהה הוא מאוד קרוב לתוחלת בסבירות גבוהה.
כפי שהראנו כבר בתחילת ההסבר
וגם
אם נפעיל את אי שיוויון צבישב על נקבל
נשים לב שלכל אפסילון חיובי צד ימי שואף ל ככל שמגדילים את . ההשלכה של זה, נותנת לנו את החוק החלש של המספרים הגדולים. נשים לב שהדרישה היחידה שצריך עבור זה היא ש יהיה מוגדר היטב
יהי סדרה של משתנים בלתי תלויים שמתפלגים באופן זהה עם תוחלת . אזי לכל נקבל
המשמעות של זה היא שלא משנה כמה גדול יהיה וכמה קטן יהיה ההתפלגות של מרוכזת סביב התוחלת . בעצם זה אומר שלכל אינטרוול מסביב ל , אזי יש הסתברות גבוהה ש יתפלג בתוך האינטרוול הזה וככל ש ההסתברות הזאת הולכת וקרבה ל . כמובן שאם אפסילון קטן יותר ככה נצטרך יותר ערכי כדי להגיע לתוצאה הזאת, אבל עדיין זה מובטח שזה יקרה מתישהו.
שימוש של חוק זה:
אם נבצע ניסוי שמורכב מניסויים קטנים כאשר זוהי איזשהי הפרעה עם תוחלת של כלומר . הרעיון הוא שלמרות ההפרעות האלה עדיין נקבל ש , ממוצע המדגם, ייתן בסבירות גבוהה שמרחקו יהיה קרוב ל . כלומר נוכל לעשות ניסויים חוזרים ורבים של אותו ניסוי ולמדל את ונוכל לקבל בקירוב טוב את התוחלת
הסתברויות של תדרים:
נניח מאורע שמוגדר בניסוי הסתברותי כלשהו ונסמן .
נבנה חזרות בלתי תלויות של אותו הניסוי ונגדיר להיות הממוצע של מספר הפעמים ש התרחש בסדרת הניסויים האלה , במצב זה מגדירים את להיות empirical frequency של . אם כן,
כאשר הוא משתנה אינדיקטור שמקבל כאשר קרה ו אם לא. יתקיים, . המשמעות היא שככל ש גבוה יותר ככה שואף להיות בסביבה אפסילונית של . זה אומר שיש קשר הדוק בין כמות הניסויים שנעשה לבין ההסתברות להצליח בניסוי. כלומר נוכל לפרש את ההסתברות כ״תדירות ההתרחשות של מאורע ״.
חוק החזק של המספרים הגדולים
ישנו חוק נוסף שלא אפרט עליו כאן שנקרא, החוק החזק של המספרים הגדולים שמהדק את החוק החלש על ידי כך שהוא אומר שההסתברות ש יהיה שווה ל כאשר היא שווה ל . כלומר
polling - דגימות:
יהי שמייצג את החלק של המצביעים שתומכים שמועמד מסויים לרשות המשרד. אנחנו מראיינים מצביעים ״שנבחרו באקראיות״ ובודקים את ואת החלק ממנו שתומך במועמד הנ״ל. נרצה להסתכל על כהערכה של ונרצה לחקור את תכונותיו. נשים לב ש המצביעין שבחרנו נבחרים באופן בלתי תלוי ואחיד ביחס לשאר האוכלוסייה. כלומר נוכל למדל כל בן אדם שעונה האם הוא מצביע למועמד או לא כמשתנה ברנולי בלתי תלוי עם הסתברות להצלחה של ושונות .
אי שיוויון צבישב מעיד על כך ש
אומנם אנחנו לא יודעים מיהו אבל אנחנו יודעים שלכל טווח הערכים הוא בין ל ולכן כפי שכבר אמרנו נוכל לחסום :
כלומר
כך למשל יתקיים שבהצבת ו יתקיים
כלומר עבור דגימה של 100 אנשים ההסתברות שההערכה שלנו לא נכונה ביותר מ היא לא יותר גבוהה מ . זה כבר נותן לנו מידע די אמין ומקורב להסתברות שהמועמד ייבחר , שכן בהתסברות של שההערכה שלנו כן תהיה בדיוק של סביב ההסתברות. נוכל להדק את ההסתברות להיות לפחות שהערכה שלנו תהיה נכונה בסביבה אפסילונית של סביב . אם כן
נרצה שיתקיים
אם נחשב נקבל שהדרישה היא ל . הבחירה של הזאת תספק אותנו אבל עדיין מוטלת בספק בגלל שהיא מובססת על אי שיוויון צבישב שהוא לא הדוק במיוחד..
משפט הגבול המרכזי
בתחילת ההסבר הגדרנו את
כמובן שמתקיים
נראה כי בניגוד ל , שבה השונות שואפת ל , כאן השונות
שואפת ל ביחס ל . ביצענו נורמליזצייה והזזה של המשתנה הזה כדי לקבל משתנה עם תוחלת ושונות . נזכר:
נקבל
נגדיר את משפט הגבול המרכזי באופן הבא:
יהי סדרה של משתנים בלתי תלויים וזהים בהתפלגותם עם תוחלת ושונות אזי ה של שואף ל של המשתנה הנורמלי הסטנדרטי
כלומר
המשפט הזה חזק מאוד, כי הוא כללי מאוד. חוץ מאי תלות והעובדה שהתוחלת והשונות מוגדרים היטב וסופיים, אין שום דרישות נוספות על המשתנים האלו. הם יכולים להיות בדידים, רציפים, מעורבים וכו.
למשפט זה יש חשיבות רבה ממספר סיבות , גם תיאורתית וגם פרקטית. בצד התיאורתי , זה מעיד על כך שהסכום של מספר רב של משתנים בלתי תלויים הוא בקירוב מתפלג נורמלית וניתן להשתמש בזה בכל מצב שבו יש אפקט מקרי כלשהו שהוא הסכום של מספר גבוה של גורמים בלתי תלויים. דוגמה טובה לזה היא מידוש של רעשים והפרעות במערכות מיחשוב ובעוד מגוון רחב של תרחישים נוספים. באופן כללי, הסטטיסטיקה של רעשין והפרעות הן ממודלות היטב על ידי התפלגות נורמלית בידיוק מהסיבה הזאת.
בצד הפרקטי, משפט הגבול המרכזי מוריד את הצורך במודלים הסתברותיים מפורטים ובמניפולציות מורכבות על פונקציות הצפיפות או המסה. כל שצריך לעשות הוא לגשת לטבלת ה CDF המוכרת של ההתפלגות הנורמלית.
קירובים מבוססים משפט הגבול המרכזי
משפט הגבול המרכזי מאפשר לנו לחשב הסתברויות שקשורות ל כאילו הוא היה נורמלי.
כיוון שנורמליות נשמרת תחת טרנספורמציות ליניאריות נוכל באופן שקול להסתכל על כמשתנה נורמלי עם תוחלת ושונות
משפט קירוב נורמלי מבוסס משפט הגבול המרכזי:
יהי נוכל להתייחס להסתברות בקירוב נורמלי באופן הבא:
חשב את והשונות של .
חשב את הערך המנורמל .
תשתמש בקירוב:
דוגמה 1:
טוענים למטוס 100 חבילות שמשקלם הוא משתנה מקרי בלתי תלוי שמתפלג באחידות בין 5 ל 50 קילוגרם.
מהי ההסתברות שהמשקל הכולל של החבילות יעבור את 3000 קילוגרם?
זאת לא תהיה משימה קלה לחשב אתה CDF של כל המשקלים וההסתברות הרצויה, אבל נוכל להשיג קירוב טוב על ידי משפט הגבול המרכזי. נרצה אם כן, לחשב
כאשר זה משקל של 100 חבילות. התוחלת והשונות של כל חבילה מחושבת לפי התוחלת והשונות של משתנה אחיד
כעת נחשב את הערך המנורמל
כעת נוכל להשתמש בCDF של משתנה מקרי נורמלי
וההסתברות הרצויה תהיה
דוגמה 2:
מכונה מעבדת חלקים של מידע , חלק אחד כל פרק זמן. זמן העיבוד של החלקים השוני הם בלתי תלויים שמתפלגים באיחודים ב .
נרצה לאמוד את ההסתברות שמספר החלקים המעובדים ב320 יחידות זמן יהיה לכל הפחות .
באותו אופן, נשאף לחשב את , יהיה קשה לחשב אותו כסכום של משתנים בלתי תלויים אבל נוכל להסתכל על הבעיה מזוויצ אחרת של סכימת פיסות המידע המעובד. אם כן כמו מקודם , נחשב את שזה זמן העיבוד של 100 חתיכות המידע הראשונות, ונחליף את המאורע במאורע השקול , כעת נוכל להשתמש בקירוב הנורמלי כמו מקודים כאשר התוחלת של כל היא והשונות היא . יתקיים
בגלל הסימטריה של התפלגות נורמלית סביב התוחלת אנחנו יודעים שאפשר להוריד את הערך המוחלט אם פשוט נכפיל פעמיים את ההסתברות בלי הערך המוחלט כלומר
נזכיר של יש תוחלת ושונות של . נשים לב שבמצב זה יש לנו בעיה שהשונות לא ידועה לנו כי היא תלויה ב . אם כן, ניקח חסם עליון כלשהו על באמצעות חסם העליון על התוחלת שראינו כבר ולכן הוא יהיה הסיבה בכלל שלקחנו חסם עליון היא שראינו שההסתברות הכי גדולה שהתפזרות הערכים תהיה רחוקה מהתוחלת באה לידי ביטוי כשהשונות היא הגדולה ביותר אז לקחנו את המקרה הגרוע אבל נראה שזה ייתן קירוב טוב יותר משימוש באי שיוויון צבישב. כמו כן, אם נציב בנוסחה נקבל שזה יקרה כש .
אם כן נחשב את הערך המנורמל
ובהצבה נקבל
כלומר יש לנו תלות במספר האנשים שאנחנו דוגמים. למשל אם נשאל אנשים ונרצה סביבה אפסילונית של כמו בדוגמה הקודמת אזי
זה הרבה יותר קטן ומדויק מההערכה של שקיבלנו על ידי שימוש באי שיוויון צבישב.
כמו כן נשים לב שגם חישוב הבעיה ההפוכה הופך להיות פשוט, אם נרצה לדעת מה צריך להיות כדי לקבל את בקירוב של פשוט מציבים את הגורמים הרלוונטים במשוואה ומחשבים
Warning
הקירוב הנ״ל הוא מדוייק ככל ש שואף ל אבל בפועל אנחנו תמיד עובדים עם סופי, והתשובה למהו ה הטוב ביותר שנוכל לקחת משתנה בין התפלגויות שונות ובעיקר כמה הההתפלגות הזאת קרובה להתפלגות נורמלית או שהיא סימטרית. למשל, עבור התפלגות אחידה כבר יתאים לנו וייתן קירוב מדויק מאוד לנורמלי. אבל אם הוא מעריכי נצטרך גדול בהרבה.
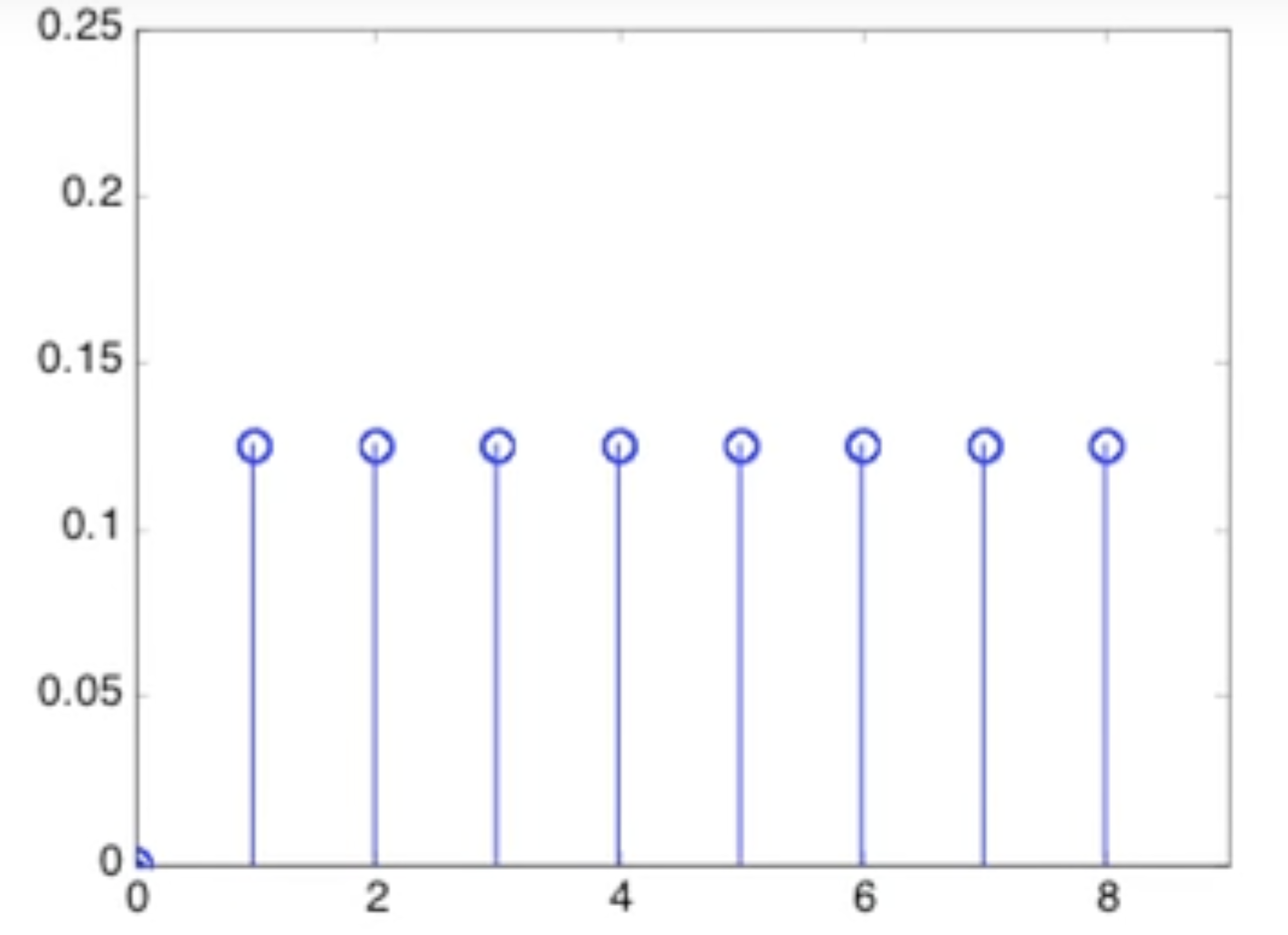
למשל עבור המשתנה הבדיד שמתפלג אחיד הבא
נקבל שעבור כלומר הקונבולוצייה עם עצמו תיתן
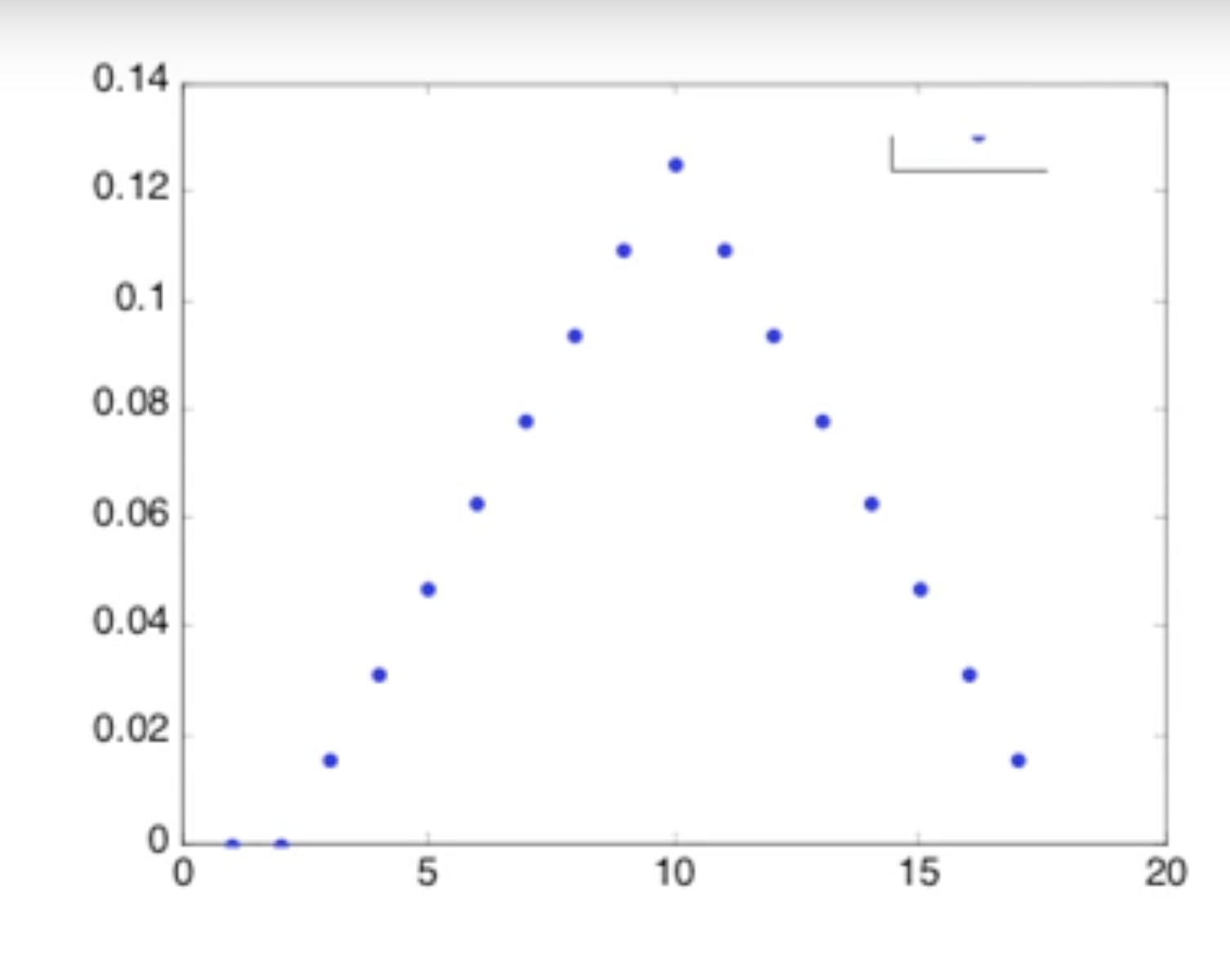
וככל שנגדיל את הקונבולוצייה תקבל צורה שיותר קרובה לגרף הפעמון המוכר מהנורמלי
קירוב נורמלי של משתנה בינומי
משתנה מקרי בינומי עם פרמטר ו הוא בעצם הסכום של משתני ברנולי בלתי תלויים עם פרמטר משותף . נזכר ש
נראה מה קורה כאשר משתמשים בקירוב שמשפט הגבול המרכזי נותן לנו כדי לספק קירוב טוב של ההסתברות למאורע , כאשר הם מספרים כלשהם. אם כן אם ננרמל כפי שעשינו עד כה
לפי משפט הגבול המרכזי נקבל ש מקורב להפלגות נורמלית ולכן
הקירוב הזה שקול ללהתייחס ל כמשתנה מתפלג נורמלית עם תוחלת ושונות
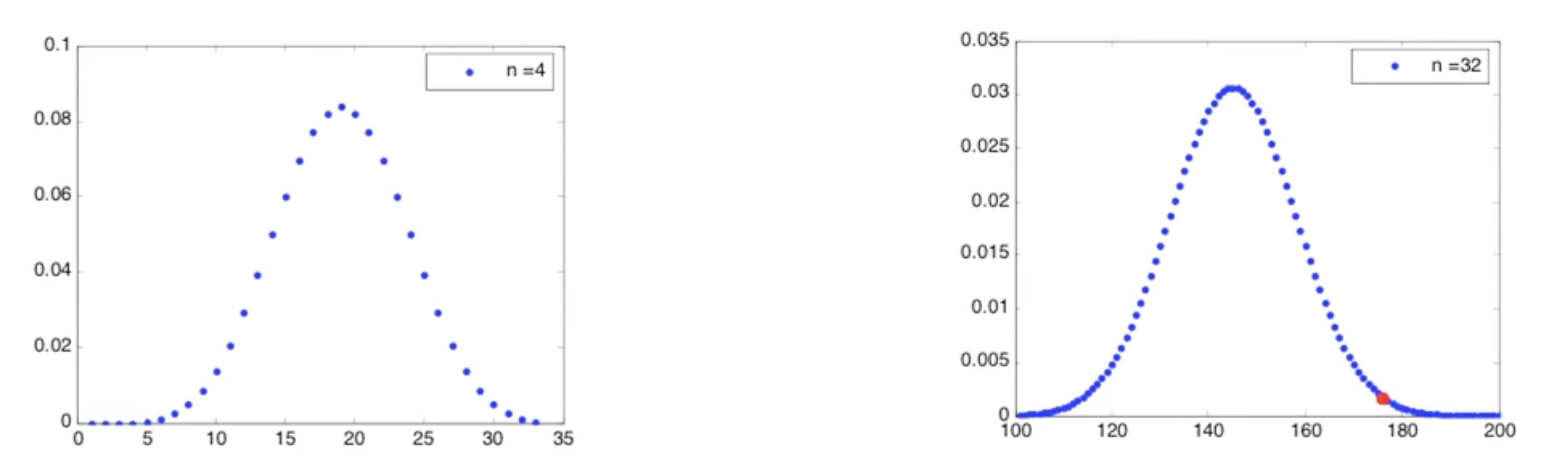
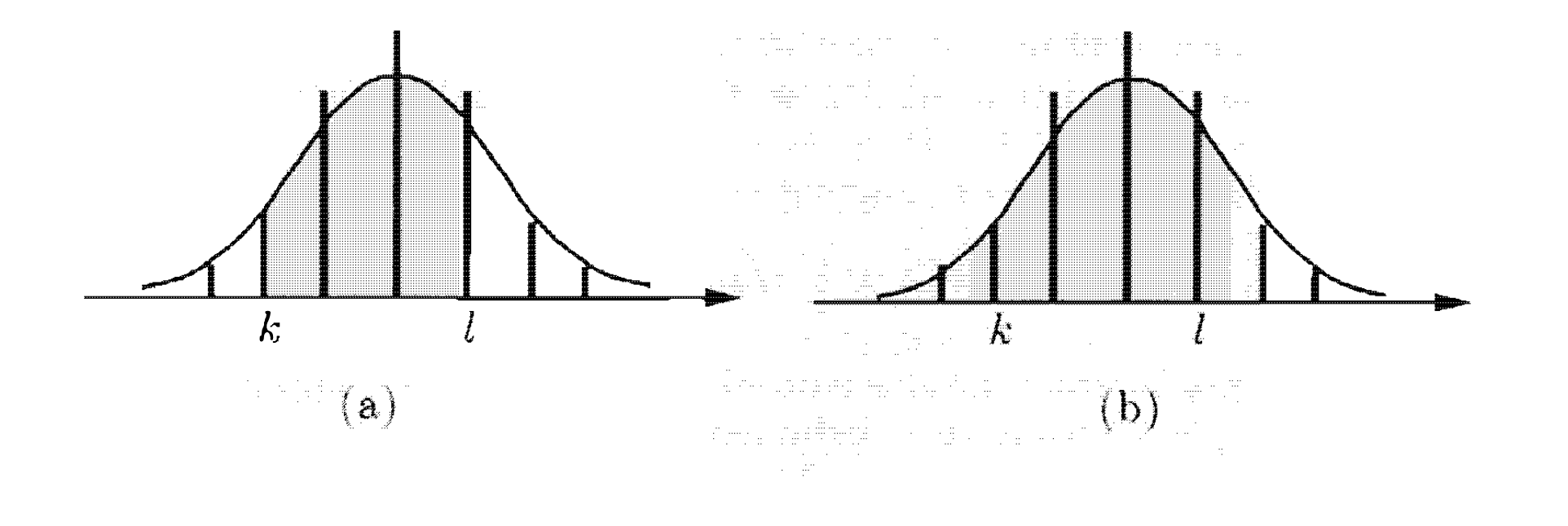
התמונה למעלה מראה לנו PMF של התפלגות בינומית עם הPDF הנורמלי. אפשר לראות שהקירוב של מציאת ההסתברות בא לידי ביטוי על ידי אינטגרצייה של השטח מתחת לPDF הנורמלי , בטווח שבין ל שזה השטח האפור בתמונה. מצב בעייתי יכול להיות במקרה זה שאם נקבל שההסתברות היא ולכן תיקון של זה יהיה להשתמש בטווח ל כדי לקבל קירוב של . בתמונה הימנית אפשר לראות הרחבה של הרעיון הזה באופן כללי שלוקח את הטווח כדי שיהיה אפשר לקבל קירוב טוב של הסתברות של כמו במקרה למעלה.
Info
הקירוב הטוב ביותר יהיה כאשר ובמצב זה ההתפלגות הבינומית הי די סימטרית, אפשר במצב זה להגיע לקירוב מצויין כאשר יהיה באזור ה עד . ככל שההסתברות מתחזקת לכיוון אחד הערכים הקיצוניים, כלומר או ככה איכות הקירוב יורדת
De Moivre-Laplace Approximation to the Binomial
אם כן אחרי שרשמנו באופן מופשט נגדיר את הקירוב הנ״ל. אם הוא משתנה המתפלג בינומית אזי
דוגמה:
יהי משתנה המתפלג בינומית עם פרמטר ו החישוב המדוייק יהיה
אם נחשב את הקירוב לפי התפלגות נורמלית נקבל
אם נחשב לפי הקירוב שאמרנו למעלה (להוריד את הטווח בחצי)
ניתן לראות שזה קירוב הרבה יותר טוב והוא גם מאפשר לנו לחשב לאמוד הסתברות לערך יחיד למשל