נרצה לגעת בסוגיות נוספות שעולות כשמדברים על משתנים מקריים בין היתר
א) חישוב פונקציות הצפיפות של פונקצייה על מ״מ או כמה.
ב) חישוב סכום של משתנים מקריים בלתי תלויים
ג) כימות מידת התלות בין שני משתנים אקראיים
כשיש לנו את המטרות האלה בראש, נכיר מספר כלים שיעזרו לנו כמו טרנפוסמצייה וקונבולוצייה, כמו כן נבין יותר לעומק את המשמעות של תוחלת מותנת.
פונקציות על מ"מ
נניח ש כאשר הוא משתנה מקרי רציף נרצה לחשב את ה של בהינתן זה של . שתי השלבים הדרושים כדי לבצע את התהליך הזה:
א) חישוב ה של :
ב) חשב לפי חוק הגזירה
דוגמה 1:
יהי משתנה אחיד ב ו . יתקיים בקטע הנתון:
אין כלל צורך לחשב את האינטגרל כיוון שאנחנו יודעים ש בכל הקטע יקיים את הנ״ל ולכן אנחנו פשוט מבצעים אינטגרצייה על בקטע הזה ונקבל כמובן .
כעת לאחר גזירה נקבל
מחוץ לקטע הזה מתקיים ש עבור ועבור מתקיים : מכאן ש מחוץ לקטע.
דוגמה 2:
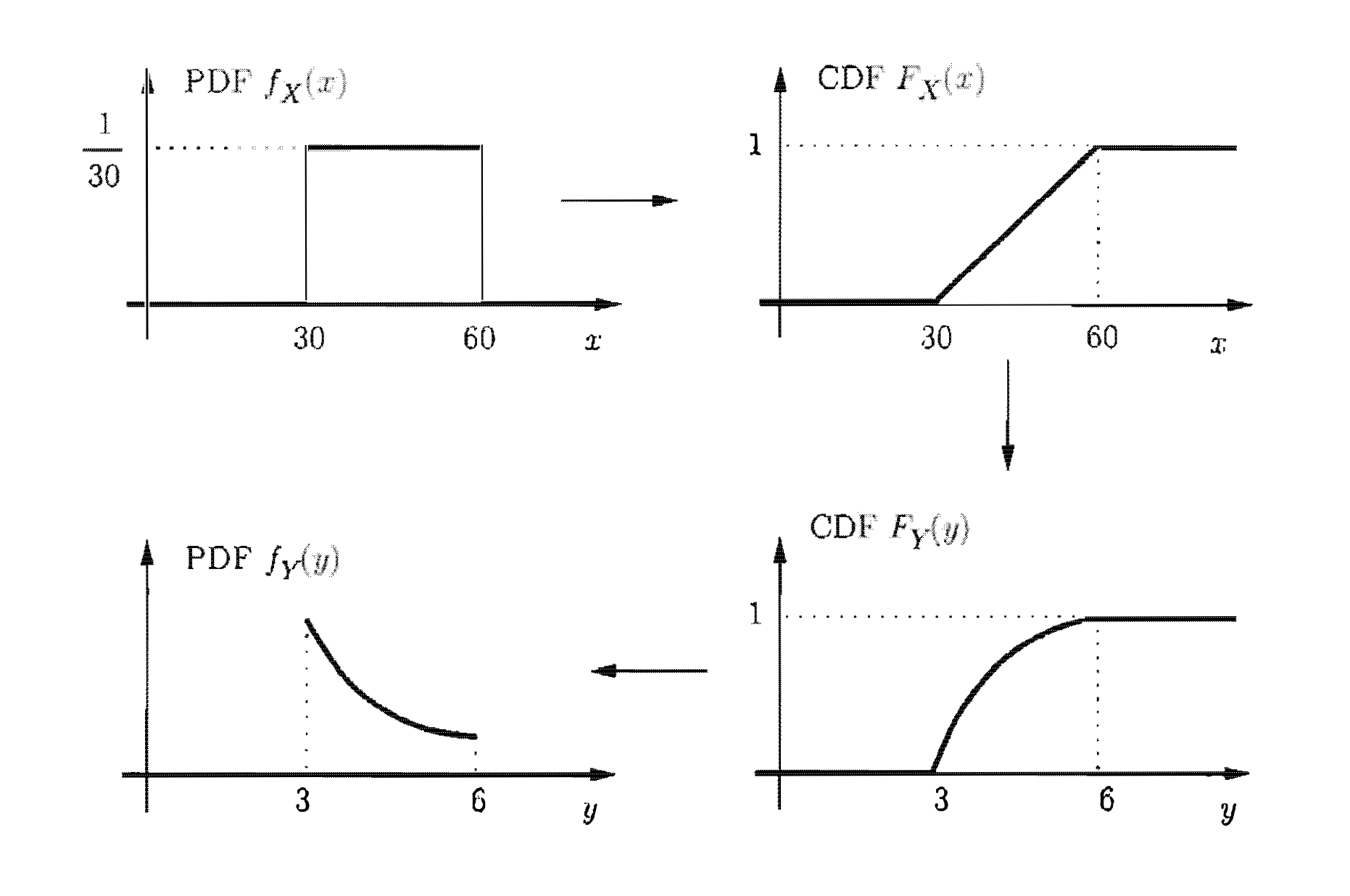
ג׳ון האיטי נוסע מבוסטון לניו יורק , מרחק של 180 קילומטר במהירות קבועה שהערך שלה מתפלג באופן אחיד בין 30 ל 60 קילומטר לשעה (כלומר יש התפלגות אחידה בין המהירות שיכולות להיות לו בטווח הזה). נרצה לחדשה את ה PDF של זמן הנסיעה.
נסמן את כמהירות ו ונסמן את כמשך הזמן של הטיול כלומר
כדי לחשב את ה של עלינו לחשב
נשים לב שאנחנו יודעים לחשב את פונקציית צפיפות ההסתברות של בקלות בגלל שהיא מתפלגת בצורה אחידה
וה של יהיה
אם כן :
נוכל להתאים את הערך לטווחים הרצויים ונקבל
האמצעי זה שקול ל ולכן אם נבצע גזירה נקבל
דוגמה 3:
נגדיר כאשר הוא עם PDF ידוע. יתקיים שלכל :
אם נבצע גזירה נקבל
פונקציות ליניאריות
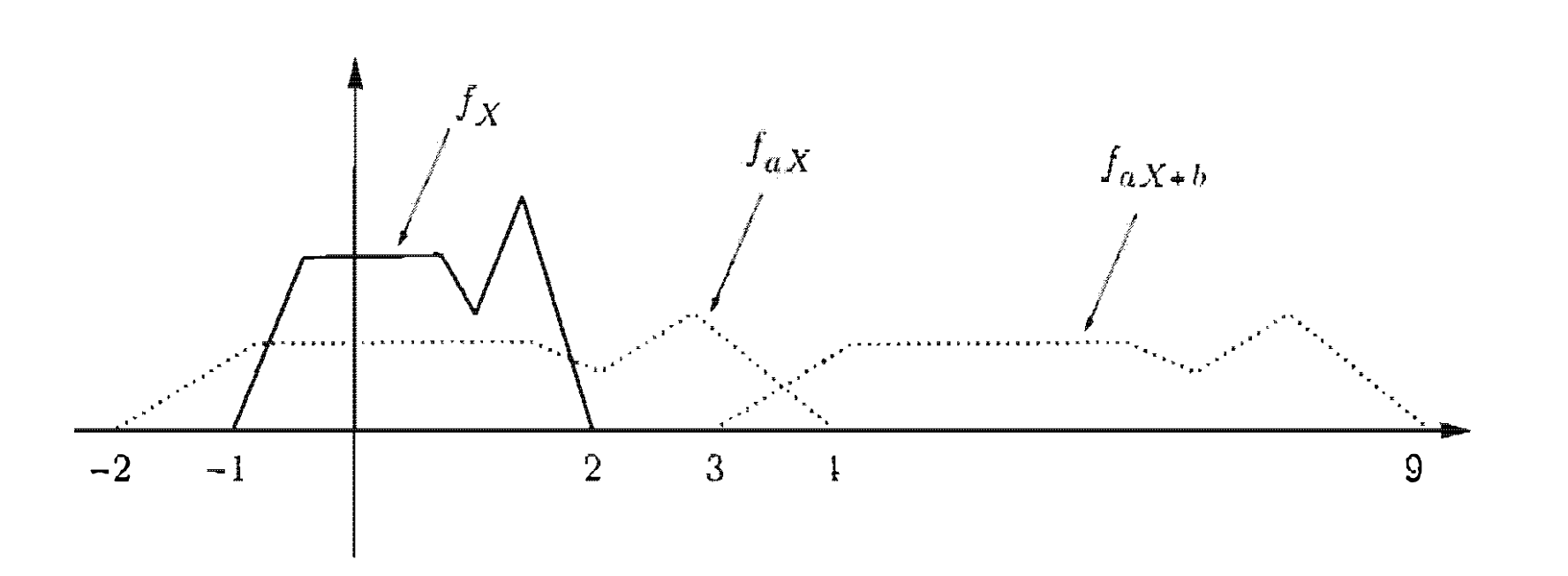
נתמקד במקרה המיוחד שבו היא פונקצייה ליניארית של
ה של במונחים של ה של . בתמונה למעלה . בשלב הראשון מוצאים את של . יתקיים כתוצאה מכפל בסקלר ש מקבל טווח ערכים רחב יותר מהטווח של בפקטור . כלומר ישנה ״מתיחה״ לאורך ציר ה אבל בגלל שצריך לשמור על תכונת הנורמליזצייה צריך לנרמל את הערכים החוזרים מהפונקצייה ולכן ה״גובה״ שלה קטן. הוספת הערף לא תשפיע על הטווח של הפונקצייה אלא רק תזיז את ערכיו לאורך ציר ה ב . בסופו של דבר יתקבל הביטוי המתמטי
בהינתן ש a שונה מ0 כמובן
הוכחה:
בלי הגבלת הכלליות נניח כאשר המקרה על דומה
על ידי גזירה נקבל
המקרה ש פשוט יוביל לכך שהסימן למעלה יתהפך ונגזיר את אבל החיסור לא ישפיע על הנגזרת (אומנם נקבל מינוס לפני התוצאה אבל בגלל ש שלילי זה יקזז את זה וכאן נכנס הערך המוחלט מלמעלה).
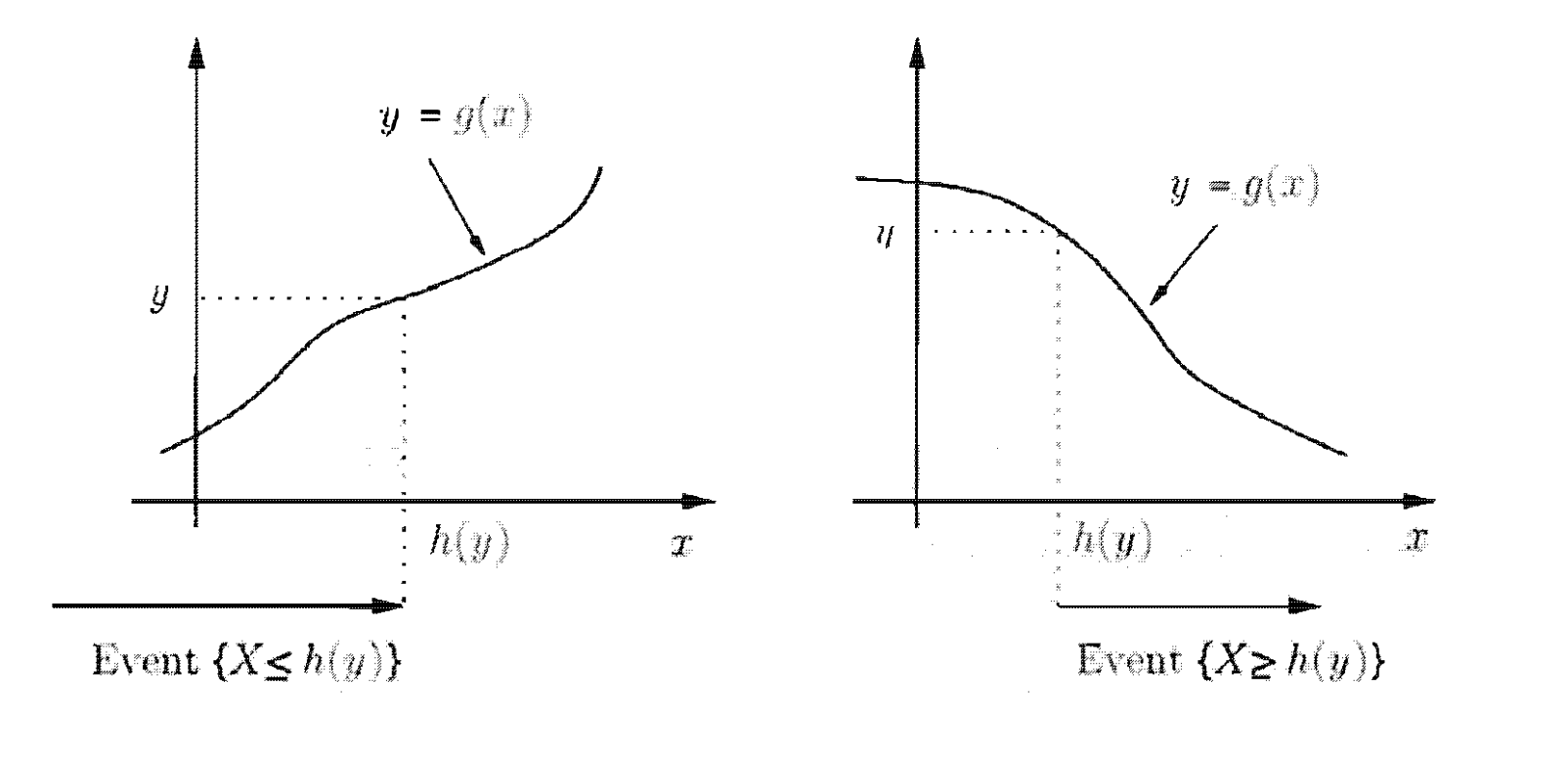
נוכל להכליל את המקרה הליניארי עבור המקרה ש היא מונוטונית. יהי משתנה מקרי רציף שתחום הערכים שלו מוכל ב אינטרוול כלשהו, כלומר .
כעת נגדיר כך ש מונוטונית ממש (עולה או יורדת) ונגדיר אותה גם כגזירה (נשים לב שהנגזרת בהכרח תהיה אי שלילית במקרה העולה ו אי חיובית במקרה היורד).
נוכל להוכיח באמצעות עוצמות שפונקציות אלה הן הפיכות תמיד כלומר קיימת פונקצייה הופכית ל כך
ו היא ההופכית.
אם היא גזירה גם כן אז ה PDF של באזור שבו תהיה
המשמעות של מה שבתוך הערך המוחלט היא שגוזרים את לפי המשתנה .
ההוכחה לכך נובעת מהעובדה ש
קל לראות בתמונה למטה למה המעבר השני נכון
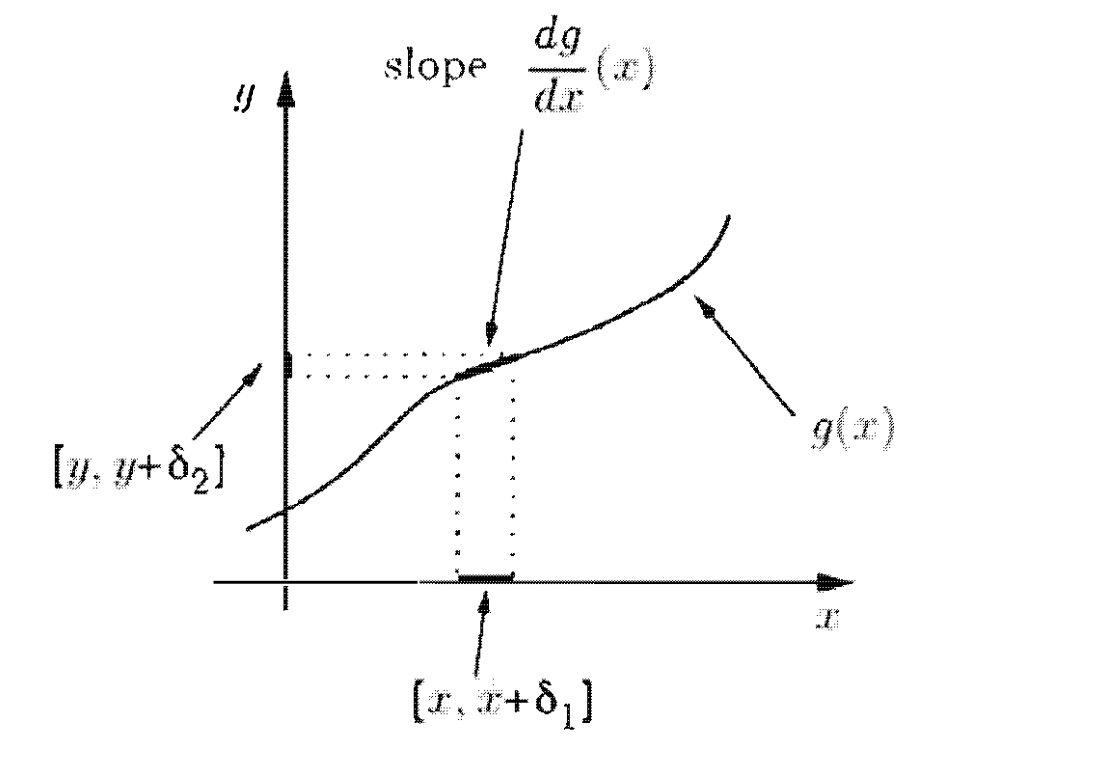
כעת אם נבצע גזירה על הנ״ל נקבל מכלל השרשרת
הסיבה לערך המוחלט היא בגלל הטיפול במקרה שבו הפונקצייה מונוטונית יורדת ולכן הנגזרת היא אי חיובית אבל זה טיפול דומה למקרה להוכחה על הפונקצייה הליניארית, פשוט עובדים עם ומבצעים על זה גזירה.
Info
אם נרצה להסתכל על PDF במונחים של הסתברויות של אינטרוולים קטנים מאוד ששואפים ל0 אז הנוסחה הנ״ל נראת כבר יותר אינטואיטיבית
קונבולוצייה
ישנם מקרים שבהם מפעילים פונקצייה על שתי משתנים מקריים , גם במצב זה התהליך של שתי השלבים שדיברנו עליו לא משתנה באופן משמעותי.
אנחנו נגע במקרה פרטי של מצב כזה שהוא הסכום של שתי משתנים מקריים בלתי תלויים . כלומר במצב שבו
עבור בלתי תלויים.
המקרה הבדיד
כדי לקבל תובנה יותר עמוקה של הסוגייה הזאת, נכנס קודם כל למקרה הבדיד כלומר נבין מה קורה ל PMF במצב הזה.
התוצאה הסופית שקיבלנו על נקראת קונבולוצייה של ה PMF של .
ההסתברות היא בעצם סכום כל הנקודות במרחב שסכומן הוא שאלה הנקודות שנמצאות למעלה. ההסתברות של נקודה כללית כזאת היא:
הקונבולוצייה מאפשרת לנו בעצם לקבל ערך בודד שמייצג את ההתפזרות של הנקודות הרצויות שלנו לכן זה גם נקרא קונבולוצייה- סוכמים את כל ההסתברויות שמקיימות נתון רצוי לכדי תוצאה בודדת שתמודל ב כערך כלשהו.
Info
דוגמה קלאסית לזה היא בעיבוד תמונה כאשר סוכמים קבוצת ערכים של פיקסלים לכדי ערך בודד שמייצג מידע מסויים על הפיקסלים שסכמנו.
המקרה הרציף
המקרה הרציף ייראה אומנם כתהליך מורכב יותר, אבל בסופו של דבר נרצה להגיע לאותה תוצאה, סכימה של נקודות שמקיימות תנאי מסויים, כלומר נרצה למצוא את ה PDF של , תיכף גם נראה שלמעשה נגיד לאותה התוצאה בידיוק פשוט בתצורה של אינטגרל ולא בתצורה של סכום.
דרך נוספת להוכיח את זה היא על ידי הנוסחה אבל לא אפרט את ההוכחה כאן שכן היא מאוד דומה לנ״ל. כמו כן מהמשפט הנ״ל משתמע שגם הפרש של משתנים מקריים מתנהג באופן דומה לחיבור שכן יקיים ש כלומר אפשר להסתכל על ולהשתמש במשפט כדי לקבל במקום את
שימו לב שזה מאוד דומה לנוסחה במקרה הבדיד פשוט מחליפים סכום באינטגרל ו PMF ב PDF . כיוון שהמשמעות היא די זהה, במקום לסכום מספר בדיד של נקודות סוכמים מספר אינסופי של נקודות שמקיים את זה.
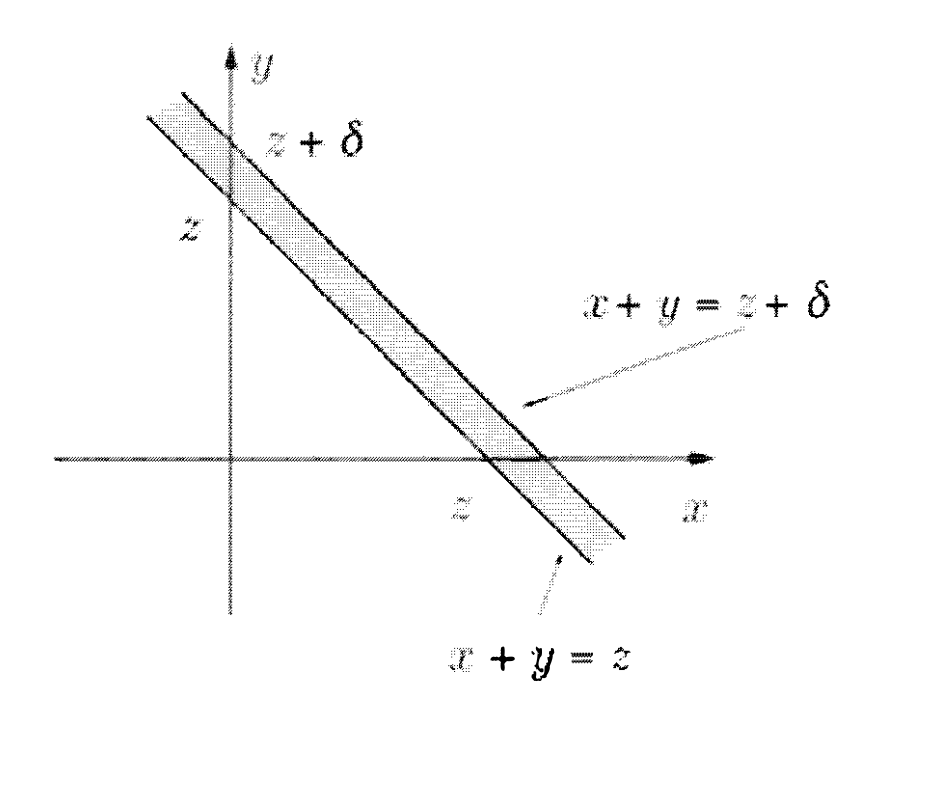
מההבנה שההסתברות של הקו הזה היא המאורע כפי שכבר ראינו בעבר שימוש בדומה במקומות אחרים. נוכל לחלץ את הנוסחה הנ״ל.
דוגמה:
עבור משתנים בלתי תלויים שמתפלגים באופן אחיד באינטרוול הסכום יהיה:
האינטגרנל הוא שונה מ ושווה ל עבור .על ידי קיבוץ של שתי אי השיוויונות האלה האינטגרנד יהיה שונה מ עבור
באמצעות המידע שיש לנו אנחנו יודעים להגיד ש כלומר זה הטווח המקסימלי של ערכי .
סך הכל יתקיים
כאשר
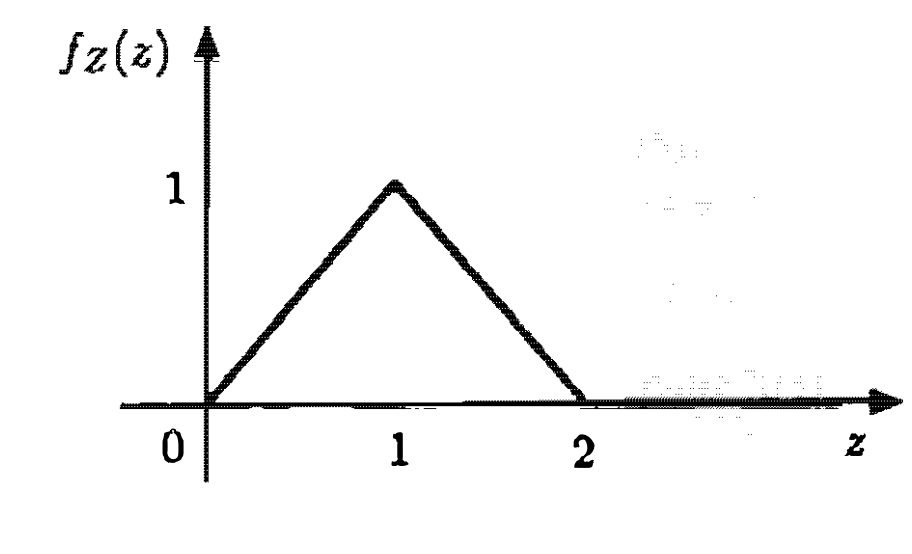
הצורה המתקבלת היא המשולש הנ״ל
הגרף הזה בעצם מתאר לנו פונקצייה שהשטח שלה הוא בידיוק ״סכימת הנקודות״ שמקיימות את הדרוש והשטח זה ההסתברות של נקודה לקיים שסכומה הוא מספר ב .
מה שחשוב לשים לב כאן היא שהתוצאה היא משתנה מתפלג נורמלית עם תוחלת ושונות . כלומר הסכום של שתי משתנים נורמלים הוא משתנה נורמלי בעצמו . מהמסקנה שהגענו עליה על הפעלת פונקצייה ליניארית על משתנה נורמלי נקבל סך הכל ש
הוא גם כן משתנה נורמלי עבור וסקלר .
חישוב גרפי של הקונבולוצייה
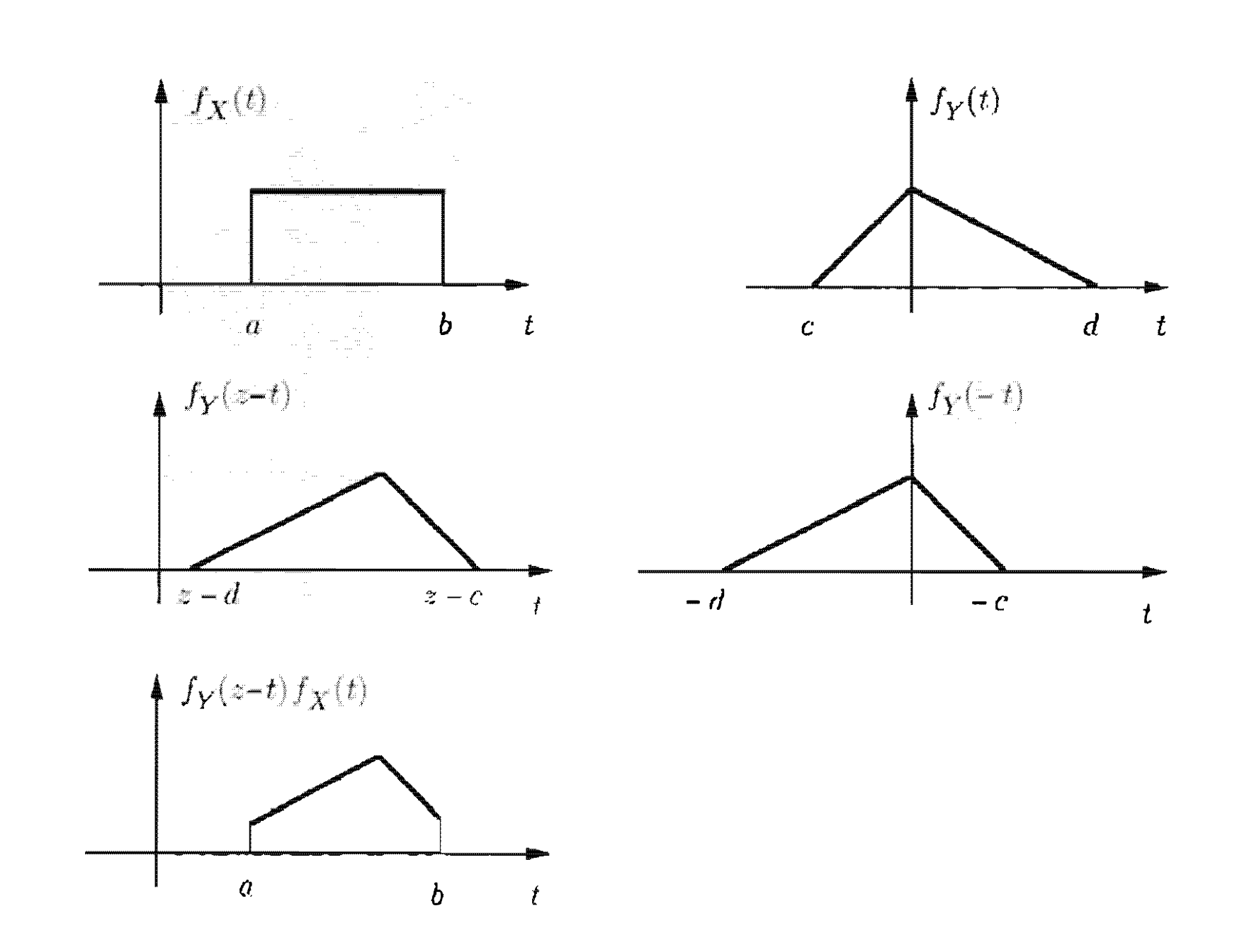
נרצה להבין באופן גרפי מה קורה ב בהינתן קלט כלשהו ביחס לגרפים שממנה היא בנויה. אם כן נשתמש במשתנה סתמי כקלט של שתי הפונקציות ונסתכל על . עבור ערך אנחנו יודעים שהערך שלה בגרף יהיה.
החישוב הגרפי יבוצע בשלבים הבאים:
א) נסתכל על כפונקצייה של ונבנה לה גרף. הצורה שלה תהיה זהה כשל חוץ מהעובדה שהיא מתהפכת בציר ה x ואז היא עוברת הזזה לפי . אם היא זזה לימין אחרת היא זזה לשמאל.
ב) נשים את הפונקצייה הנ״ל ואת אחד על השני ובונים את ההרכבה שלהם.
ג) מחשבים את הערך של על ידי חישוב האינטגרל של פונקציית ההרכבה משתי ההגרפים שבנינו.
בהינתן ערך של כלשהו השטח שנמצא בשרטוט התחתון ביותר ייתן את ערך הפונקצייה
שונות משותפת ומתאם
נרצה להשתמש בכלי מדיד שיאפשר לנו לאמוד את ה״עוצמה״ וה״כיוון״ של קשר בין שתי משתנים מקריים.
השונות המשותפת של מוגדרת להיות
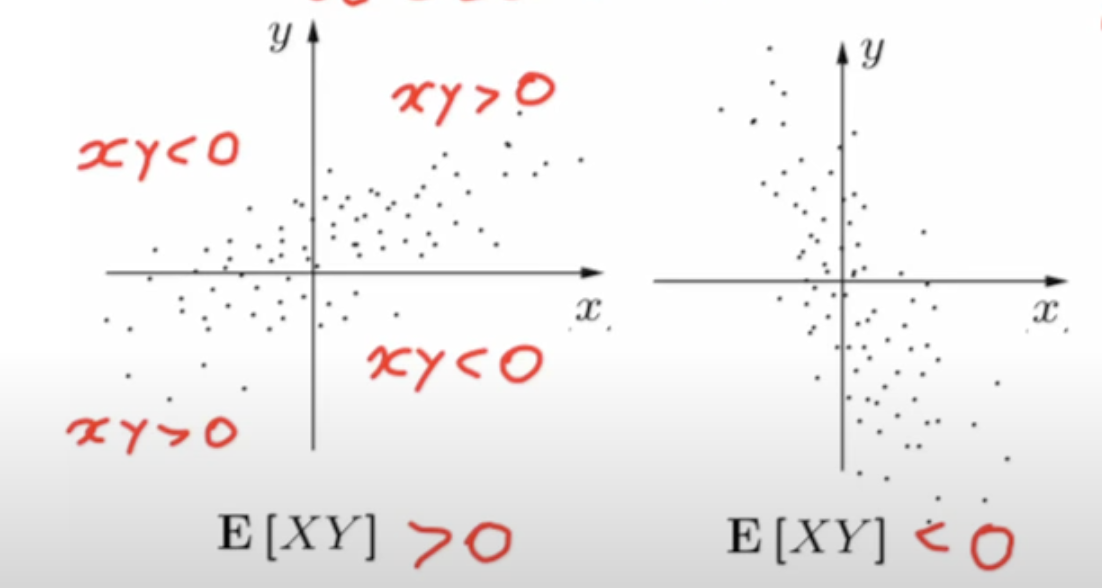
כאשר נומר ש הם בלתי משוייכים. הסימן של ה cov עונה על השאלה האם ו הם עם אותו סימן או סימן הפוך.
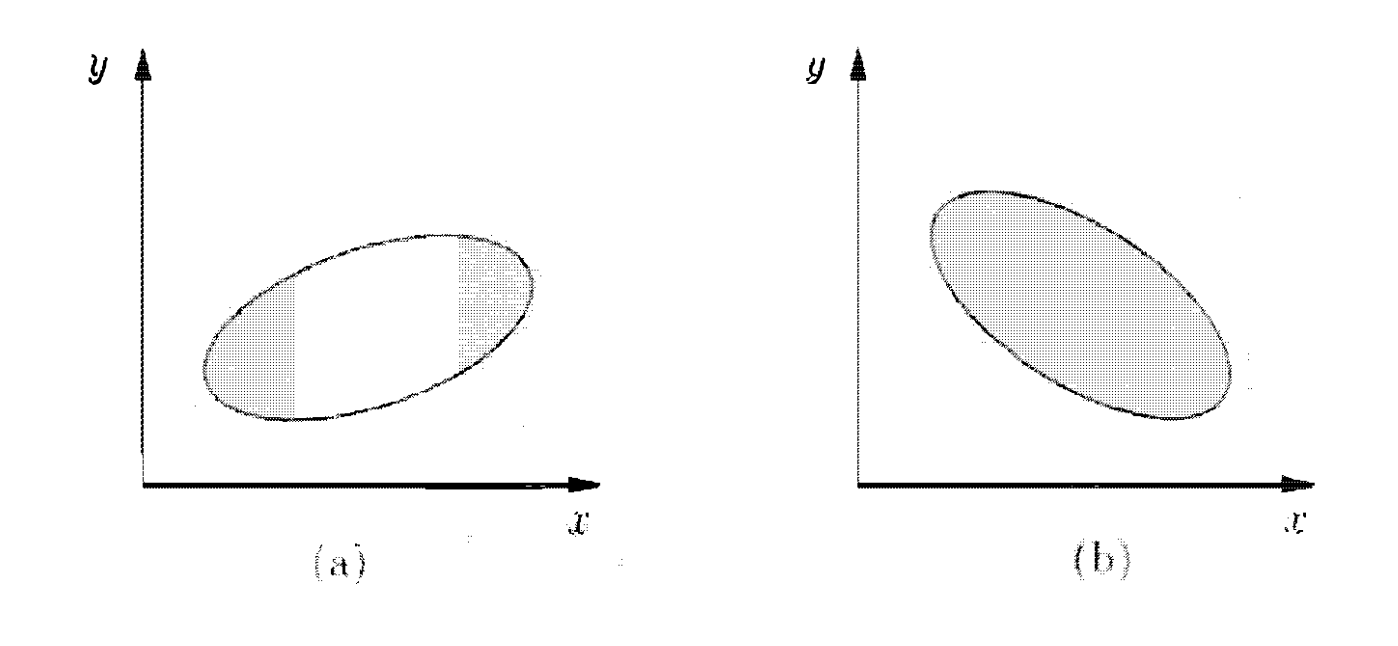
עבור כמו בתמונה, שמתפלגים באופן אחיד באליפסות הנתונות (כל אליפסה מייצגת ניסוי אחר) ניתן לראות שבתמונה השמאלית הסטייה ממרכז המסה של הם באותו כיוון כלומר ככל ש גדל מהתוחלת שלו כך גם גדל מהתוחלת שלו, במצב זה ה שונות המשותפת תהיה גדולה מ0. במצב השני בתמונה הימנית זה הפוך, ככל ש גדל ממרכז המסה שלו שלו ככה הולכים וקטנים ממרכז המסה שלהם ולכן השונות המשותפת תהיה שלילית. הסיבה שההתפזרויות הנ״ל הן שליליות או חיוביות נובע ישירות מההגדרה שמבקשת את הכפל של מרחק של משתנה מסויים מהתוחלת כפול המרחק של השני ולכן האופן שבו הנקודות מתפזרות הוא קריטי.
נוסחה שקולה תהיה
הוכחה:
כאן ניתן לראות שגם פיזור הנקודות על גבי הרבעים משפיע על שיכול להשפיע על הסימן של התוחלת הנ״ל. הדוגמה זהה בתכליתה לתמונה למעלה רק שכאן זה מצב שבו התוחלת של או של או של שניהם היא ואז מה שמשפיע על הסימן הוא הכפל בין ערכי הנקודות והפיזור שלהם לאורך הרבעים של הציר האנכי והאופקי..
תכונות השונות המשותפת
כמו כן בהינתן ש בלתי תלויים אנחנו יודעים ש ולכן יתקיים . כלומר אם בלתי תלויים הם גם בלתי משוייכים. נשים לב שההפך לא בהכרח נכון , נראה זאת בדוגמה:
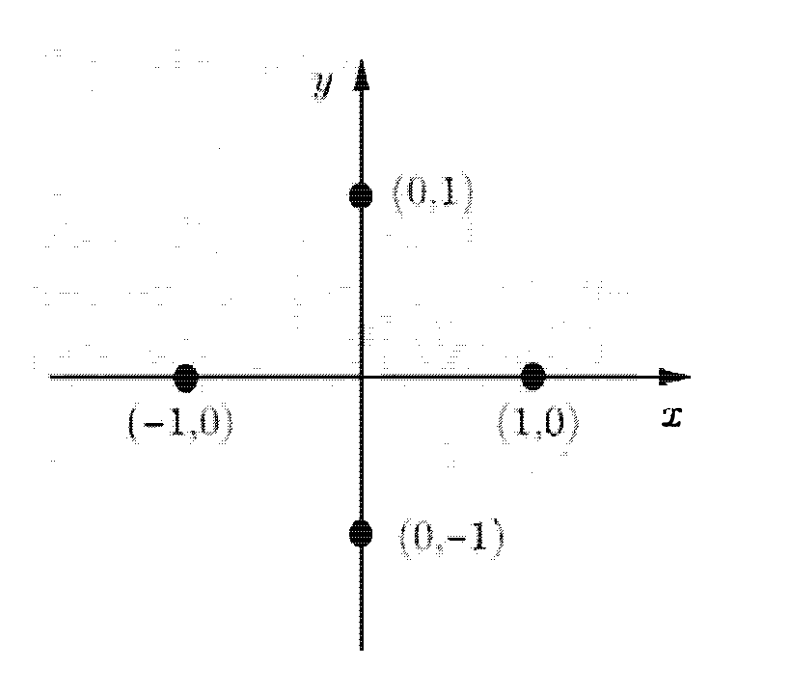
הזוג של המשתנים המקריים לוקח את הערכים . כל אחד בהסתברות .
אם כן קל לראות שה PMF השולי של סימטרי סביב ולכן התוחלת של שתי המשנים היא . כמו כן נשים לב שלכל נקודה שנבחר יתקיים ולכן , לכן
כלומר הם בלתי משוייכים. עם זאת, תלויים אחד בשני , אין סיבה כלל לבצע פה הליך חישובי כדי לראות זאת שכן
אבל
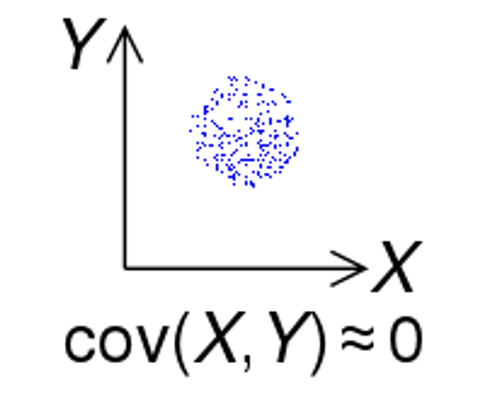
התפזרות הערכים כאשר השונות המשותפת היא 0:
מקדם המתאם של פירסון
נגדיר את מקסם המתאם של שתי משתנים מקריים עם שונות שונה מ על ידי:
זאת מעין גרסה מנורמלת של השונות המשותפת ולמעשה לא נוכיח זאת כאן אבל מקבל ערכים בין . ההתנהגות של מקדם המתאם כאשר הוא שונה מ0 זהה במשמעותה למה שהשונות המשותפת הייתה מראה לנו ההבדל הוא שהיא נותנת לנו מידע ללא תלות ביחידות מידע למשל אם נמדדים במטרים אז השונות המשותפת נמדדת ב מטר מרובע ולכן זה יכול להפריע לתהליכים חישוביים שמשלבים בין השניים, לעומת זאת מקדם המתאם אינו תלוי ביחידות מידה , הוא יישאר במטרים.
באופן דומה נשמרת התכונה שאם המשתנים בלתי תלויים אז ולכן הם בלתי משוייכים .
אם כן, הגודל מספר לנו גרסה מנורמלת של השונות המשותפת בהינתן שאין לאף אחד מהמשתנים שונות ששווה ל0 (במצב זה המשתנה המקרי שקול לקבוע ואז מקדם המתאם אינו מוגדר היטב).
משפט: אם ורק אם קיים קבוע כך ש
המקרה הכי קל יהיה
וכמו ש
(באופן דומה על )
דוגמה:
נניח שמטילים מטבע הטלות עם הסתברות ל head ששווה ל . יהי מספר ה heads וה tails בהתאמה. נחפש את השונות המשותפת של כאשר וגם (כי כל אחד מהם מתפלג גיאומטרית) .
דרך אחת להוכיח את זה:
דרך נוספת:
אם כן יתקיים מהעברת אגפים סטנדרטית :
כעת נחשב את השונות המשותפת של שניהם :
לאחר נרמול נקבל כמובן .
השונות של סכום של משתנים מקריים
נוכל להשתמש בשונות המשותפת כדי לקבל נוסחה על השונות של סכום של מספר משתנים מקריים.
נניח ש הם משתנים מקריים עם שונות סופית אזי :
הוכחה:
ויתקיים
ובאופן כללי יותר
הוכחה:
נסמן ויתקיים
דוגמה:
נניח ש אנשים זורקים את הכובכים שלהם בקופסה ומוציאים את הכובע מהקופסא באקראי. נמצא את השונות של על ידי מידול של ניסויי ברנולי
כאשר מקבל אם האדם ה הוציא את הכובע שלו בהסתברות ואחרת .