משתנים רנדומיים-בדיד
מהו משתנה אקראי
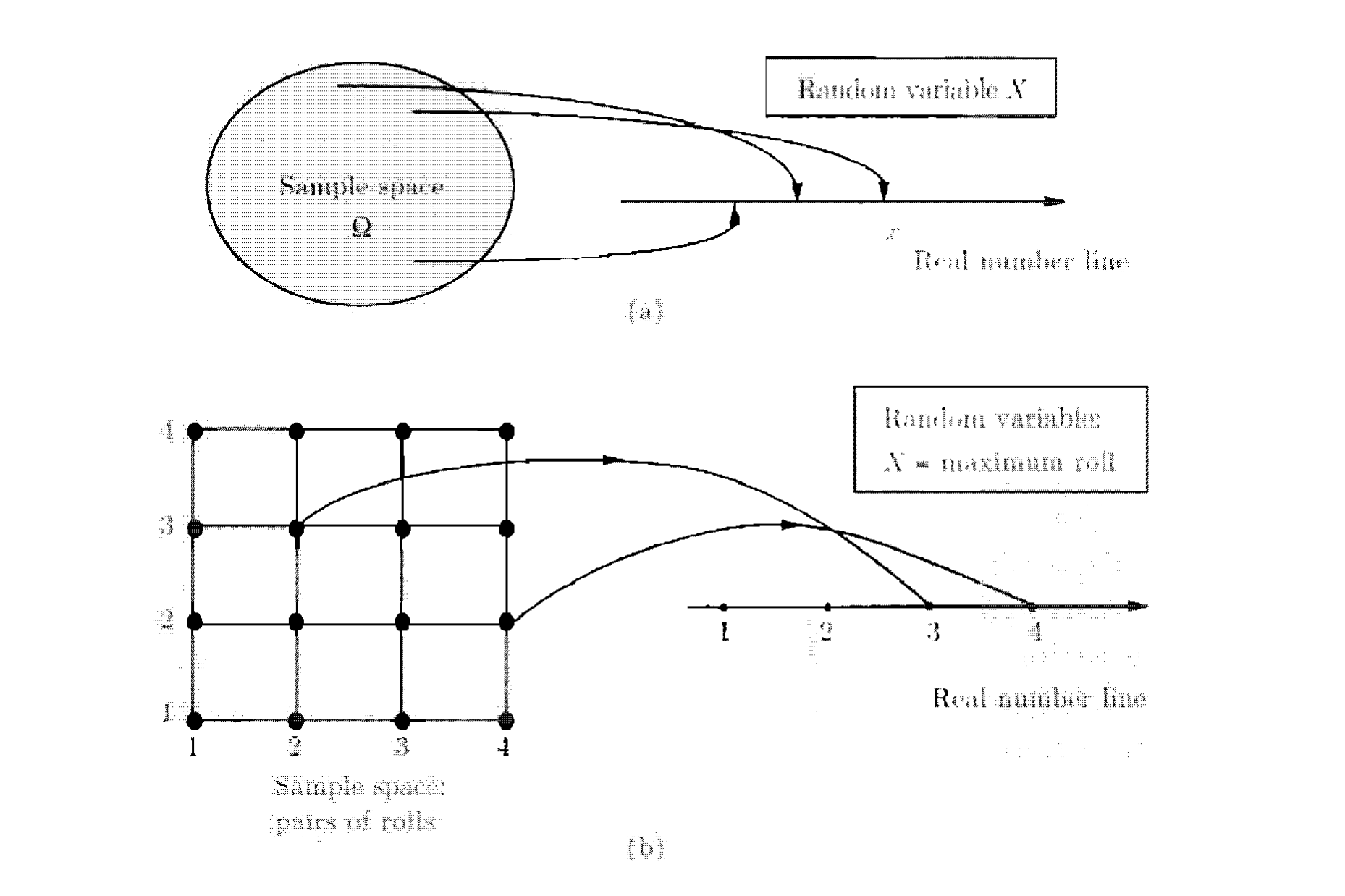
ברוב המודלים ההסתברותיים שנבנה התוצאות הדרושות יהיו ערך מספרי של ממש (כמו קריאה של מנייה). למרות זאת ישנם ניסויים, שבהם התוצאה היא לא משהו מספרי אבל נוכל לשייך את התוצאה של הניסוי לערך מספרי שמעניין אותנו. דוגמה טובה לכך תהיה אם הניסוי הוא בחירה של סטודנטים מאוכלוסייה מסויימת. אולי נרצה להתייחס לממוצע שלהם למשל. כנרצה להתייחס לערכים כאלה אנחנו נותנים להסתברויות שמייצגות מאורעות כלשהו את הערך המתאים הנ״ל. זה נעשה באמצעות משתנים רנדומיים.
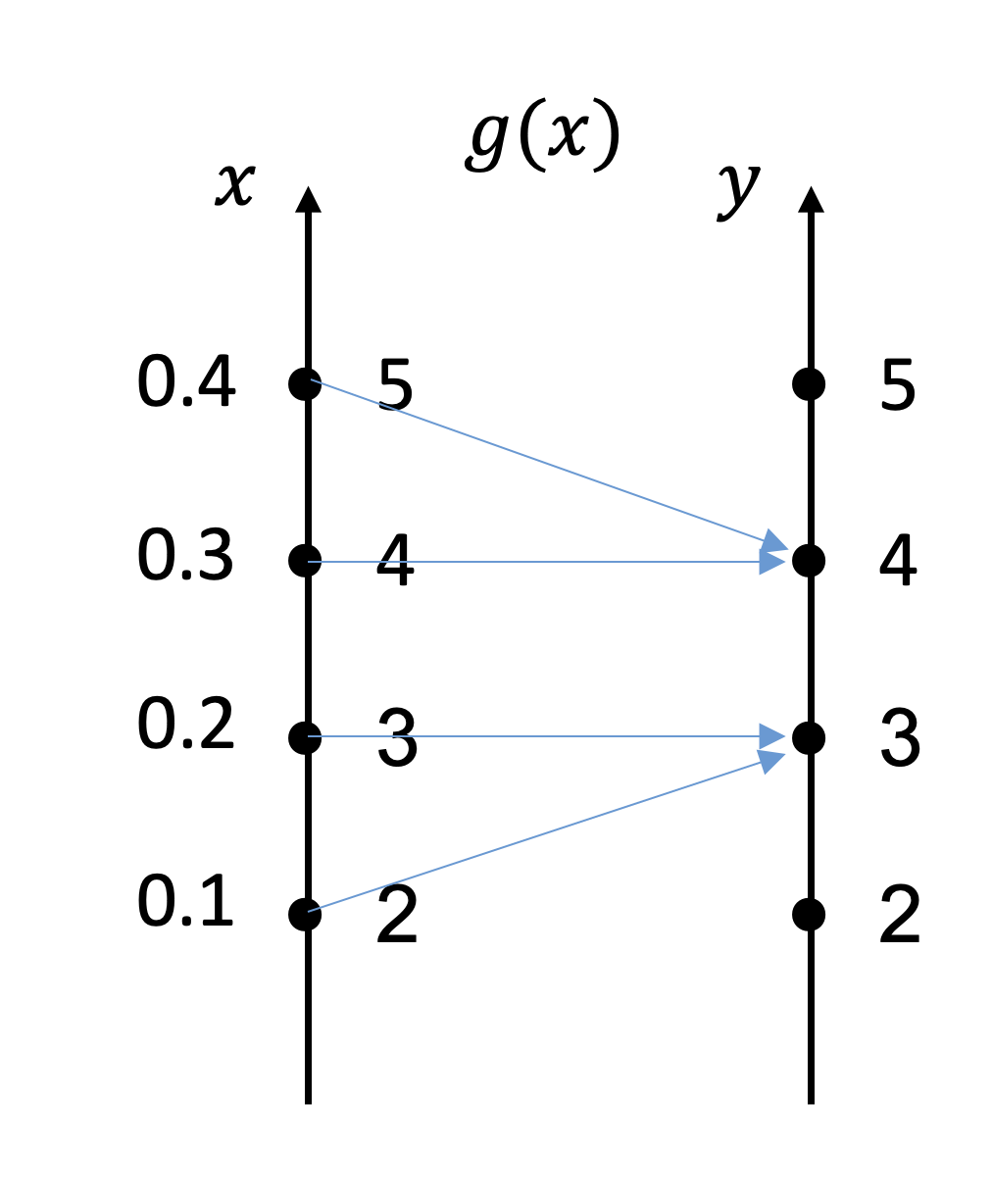
הגדרה : בהינתן ניסוי ומרחב מדגם, משתנה רנדומי משייך מספר עם תוצאה. באופן מתמטי ,
משתנה רנדומי
נשים לב שהסימון הוא
דוגמאות :
- ניסוי שיש 5 הטלות של מטבע. נוכל להגיד משתנה רנדומי שקובע את מספר הפעמים שקיבלנו ערך כלשהו .
- ניסוי שבו מטילים קובייה נוכל להגדיר משתנה רנדומי שקובע את סכום שתי ההטלות, מספר הפעמים שהיה 6 בשתי ההטלות וכו.
ישנם מספר קונספטים בסיסיים שצריך להכיר כשעבודים עם משתנים רנדומיים
- משתנים אקראיים - הוא פונקצייה ממרחב המדגם לממשיים.
- פונקציה של משתנים רנדומים היא גם משתנה רנדומי. לדוגמא, נתונים X ו-Y משתנים רנדומים אזי X+Y גם הוא משתנה רנדומי
- נוכל לשייך למשתנה רנדומי ״ממוצע״ מסויים שיעניין אותנו כמו תוחלת ו variance.
- משתנים רנדומיים יכולים להיות מותנים במאורע מסויים או משתנה רנדומי אחר.
- ישנה אפשרות ל אי תלות של משתנה רנדומי עם מאורע או עם משתנה רנדומי אחר.
משתנה רנדומי בדיד
משתנה רנדומי ייקרא בדיד אם הטווח של הפונקצייה שלו הוא סופי אם בן מנייה. למשל משתנה רנדומי שהטווח שלו הוא
ישנם מספר קונספטים חשובים בכל הקשור למשתנה רנדומי בדיד
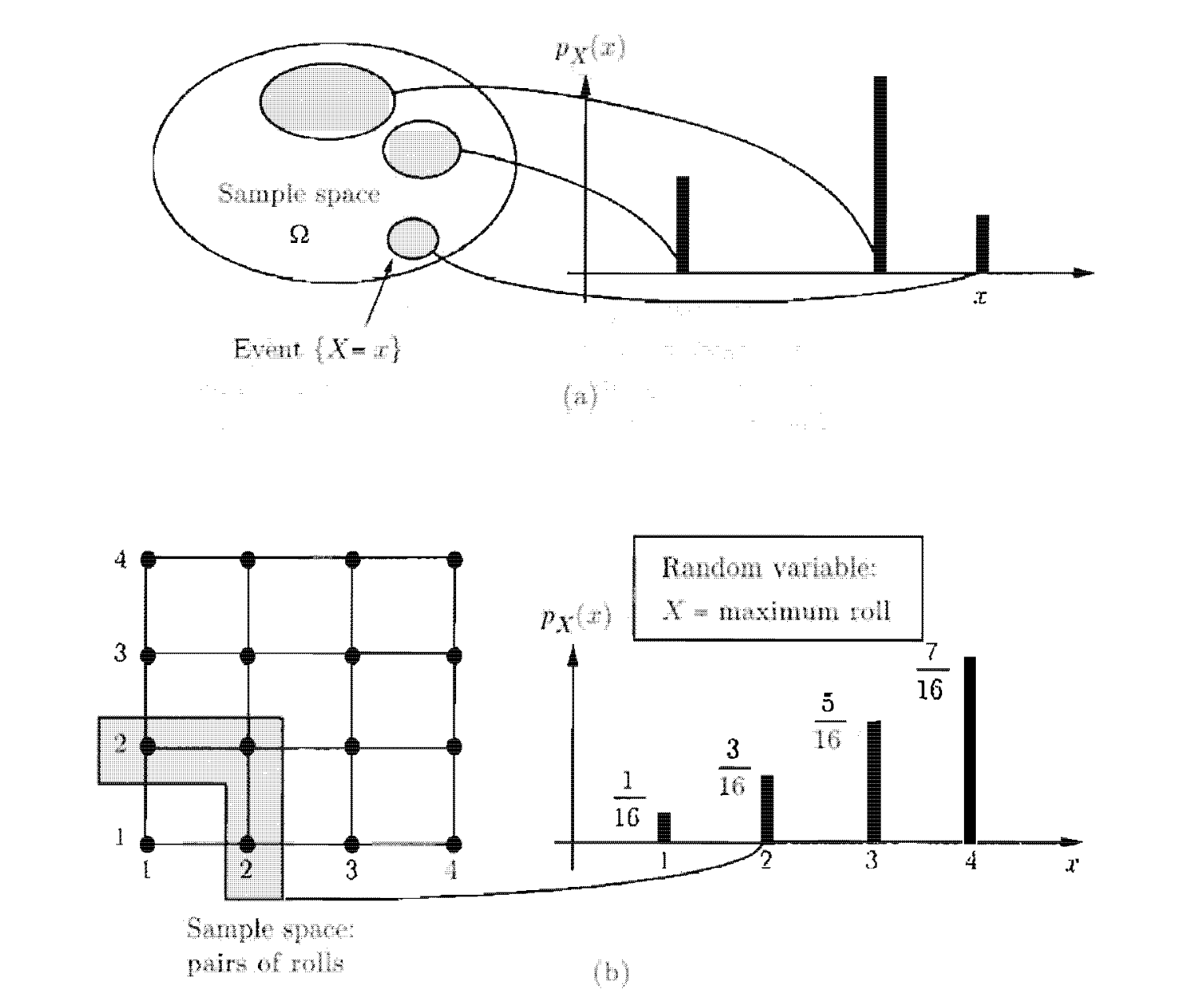
- פונקציית המסה או פונקצייה ההסתברות (PMF) נותנת להסתברות לכל ערך בתחום של המשתנה הרנדומי.
- פונקציה של משתנים רנדומים בדידים היא גם משתנה רנדומי בדיד. הPMF שלו יכול להיות מושג מה PMF של המשתנה המקורי.
PMF
הדרך הטובה ביותר לאפיין משתנה רנדומי היא דרך ההסתברויות שכל ערך מקבל. יהי משתנה רנדומי
ניתן גם לסמן
כלומר פונקציית מסת ההתסברות לערך
לדוגמה, נסתכל על ניסוי שמכיל שתי הטלות בלתי תלויות של מטבע הוגן ונגדיר את
תכונות ל PMF
זה נובע מאקסיומות ההסתברות והעובדה ש היא פונקצייה שהתמונה ההפוכה שלה היא מרחב המדגם ולכן ישנו מיפוי של כל התוצאות האפשריות והחלק היחסי שלהן מקבל הסתברות באמצעות pmf. - לכל קבוצה
של ערכים אפשריים של ערכים אפשריים של יתקיים
חשוב להסביר רגע את הסימון, הוא מייצג את ההסתברות ש
למשל אם נסתכל על ניסוי מהדוגמה למעלה, ההסתברות שיהיה לפחות head אחד הוא :
חישוב PMF של משתנה רנדומי X
לכל ערך x ששייך ל X נעשה את הדבר הבא
- נאסוף את כל התוצאות האפשריות לניסוי שמקיימות את המאורע
. - נסכום את ההסברויות שלהם כדי לקבל
סוגים של משתנים רנדומים בדידים
משתנה ברנולי
נניח שמטילים מטבע שבהסתברות p ייתן לנו head וב
ה pmf שלו זה
המשתנה הזה אומנם פשוט אבל הוא חשוב מאוד. בפרקטיקה, משתמשים בו למידול תרחישים הסתברותיים גנרים עם שתי תוצאות בלבד. למשל:
- המצב של טלפון בכל רגע נתון יכול להיות פנוי או תפוס.
- בן אדם יכול להיות חולה או לא חולה במחלה מסויימת.
יתרה מכך, שילוב של מספר משתני ברנולי מאפשר בנייה של משתנה רנדומי מורכב יותר למשל משתנה בינומי.
משתנה אינדיקטור
משתנה מקרי אינדיקטור הוא מקרה פרטי של ברנולי , אפשר להגיד שהוא גם משתנה שעוזר לתאר התפלגות ברנולי. הוא מוגדר על מאורע
באמצעות משפטים שקשורים לתוחלת עליה נדבר בהמשך נוכל להוכיח שעבור מאורעות תלויים, אם נוכל להפריד אותם לרצף של אינדיקטורים, אזי נוכל לחשב כל מיני סוגים של מידע על המאורעות באמצעות תכונות של אינדיקטורים.
משתנה/התפלגות בינומי
זורקים מטבע
מתייחסים ל
כאשר k מייצג את המספר אותו נרצה למצוא. נשים לב שהתכונה שרצינו מתקיימת שהסכום של כל הקלטים האפשריים בפונקציית הpmf תיתן 1 (הוכחנו את זה על הנוסחה הזאת).
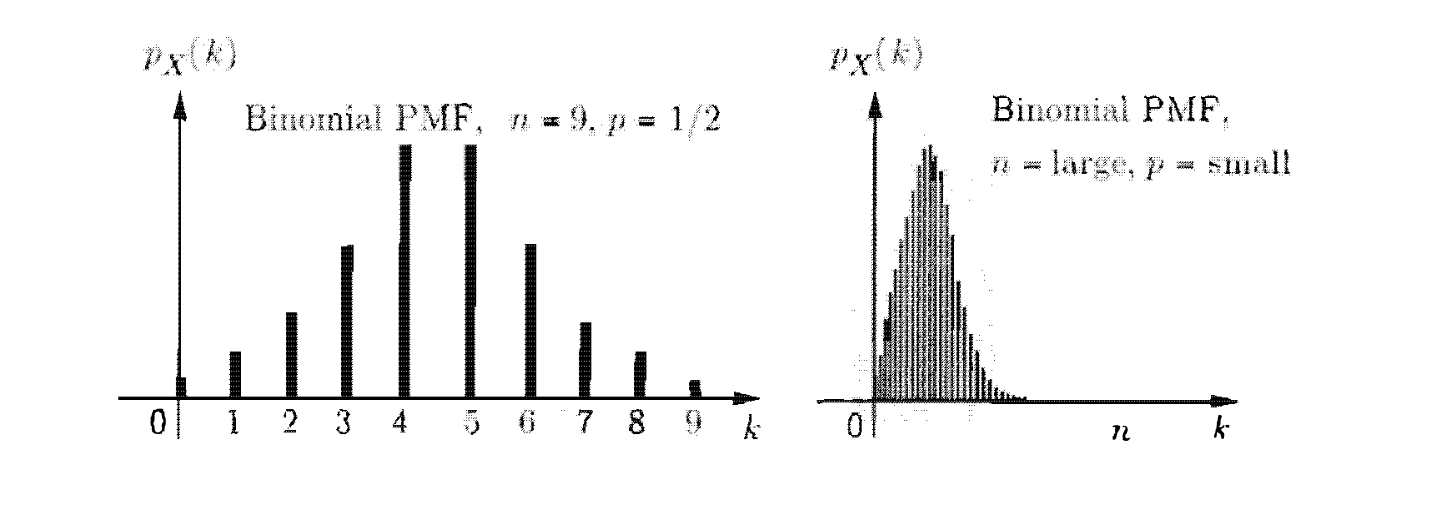
כאן ניתן לראות שתי מצבים מעניינים של pmf . הראשון הוא כאשר p=0.5 שבו ניתן לראות שההתפלגות של הערכים היא סימטרית ביחס ל
הסיבה שפונקציית מסת ההסתברות ממודלת ככה היא הגיונית למדי, שכן אם נדמיין את הדוגמה של הטלת המטבע כמודל הסתברותי סדרתי (למשל עץ) אנחנו נראה שתמיד שלקראת הערכים באמצע של
משתנה גיאומטרי
נניח שיש לנו באופן חוזר ובלתי תלוי הטלת מטבע באופן בלתי תלוי, עם הסתברות לקבל head שהיא p כאשר אנחנו יודעים בוודאות ש
הנוסחה הזאת מאוד הגיונית כי היא מתארת רצף של הטלות בלתי תלויות כאשר
המעבר האחרון נובע בגלל שנתון ש p מספר קטן בין 0 ל 1 ולכן
השתמשנו בדוגמה של הטלת מטבע כי היא מתארת את המשתנה הזה באופן די טבעי. באופן כללי, נוכל לפרש משתנה גיאומטרי במונחים של חזרה בלתי תלויה של ״מבחנים״ עד ל״הצלחה״ ראשונה. כל מבחן יהיה עם הסתברות להצלחה
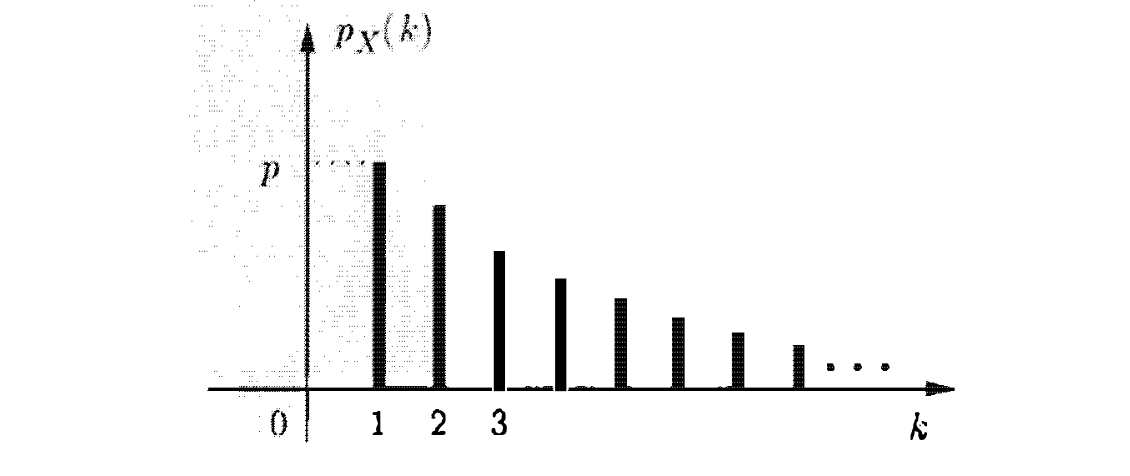
ככל ש
משתנה פואסון
למשתנה פואסון יש PMF שמיוצג על ידי
כאשר
נשים לב ש
זה משתנה PMF לגיטימי בגלל ש
זה נובע מ טורי טיילור ידועים (הטור של הפונקצייה
פונקציית מסת ההסתברות עבור קלט
כדי לקבל אינטואיציה למשתנה פואסון. נחשוב על משתנה בינומי עם מספר
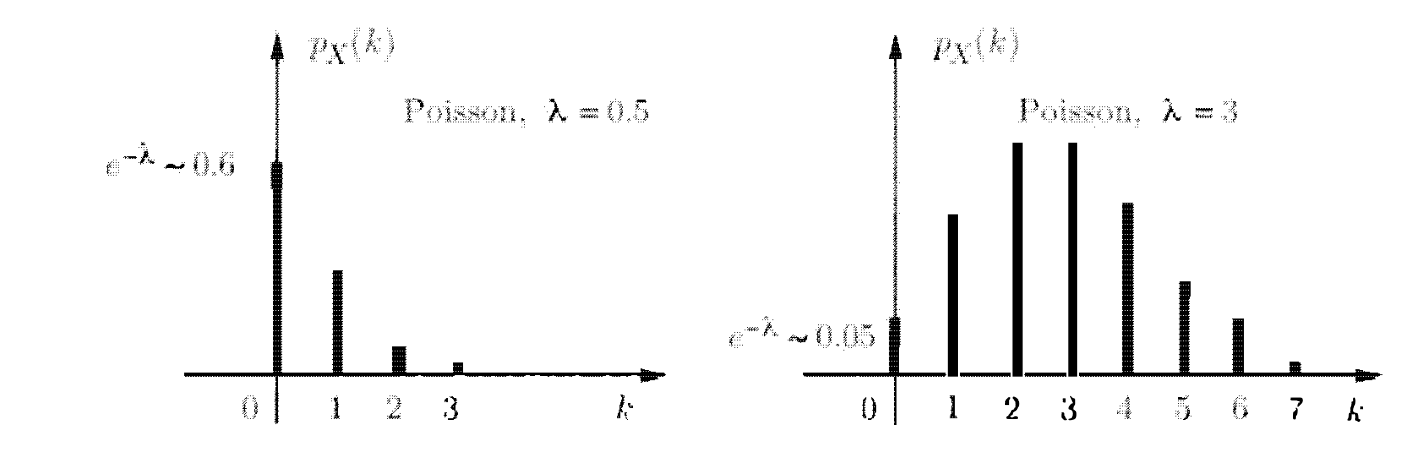
נשים לב,
מאוד מעצבן לחשב, אבל על ידי שימוש במשתנה פואסון עם
הקשר בין פואסון לבינומי
בדומה:
- המאורעות בלתי תלויים - התרחשות של מאורע אחד באינטרוול כלשהו לא משפיע על כך שהוא יקרה מאוחר יותר.
- בשתיהם יש מידול של סיכוי להצלחה והסתברות לכשלון
- גם במקרה הזה אנחנו מעוניינים בהסתברות למספר הצלחות כלשהו.
בשונה:
- מספר הניסויים במשתנה פואסון לא מוגדר
- ההסתברות להתרחשות של מאורע בודד אינה ידועה אך ברוב המקרים בקטנה מאוד.
משתמשים במשתנה פואסון במצבים בהם מאורע יכול לקרות בכל רגע ולכן אין לנו הסתברות על המאורע. אם האירועים מתרחשים באופן בלתי תלוי ובקצב (ממוצע) קבוע
דוגמה לכך היא מספר השיחות המתקבלות במרכזיית טלפונים במשך דקה.
ניתן לראות את התפלגות פואסון בתור גבול של סדרת התפלגויות בינומיות שבה מספר הניסויים שואף לאינסוף, ותוחלת מספר ההצלחות נשארת קבועה.
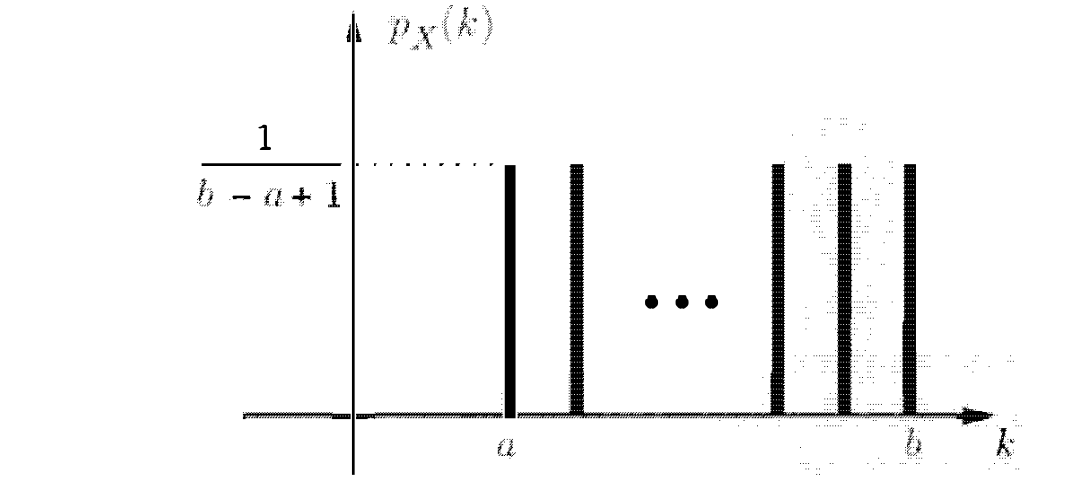
משתנה בדיד אחיד uniform
משתנה רדנומי X הוא משתנה אחיד עם פרמטרים a ו-b כאשר a ≤ b אם ערכו של המשתנה הוא מספר מ a,a+1,…,b כאשר לכל מספר ההסתברות זהה.
כלומר מרחב המדגם הוא
נשים לב ההסתברות למאורע שהתוצאה תהיה
כלומר מרחב המדגם הוא מרחב שווה הסתברות.
פונקציות של משתנים רנדומיים בדידים
בהינתם משתנה רנדומי
לדוגמה, בהינתן משתנה רנדומי
כאשר
כמו כן נוכל להגדיר את
כלומר, עבור קלט
דוגמה : עבור
נקבל את
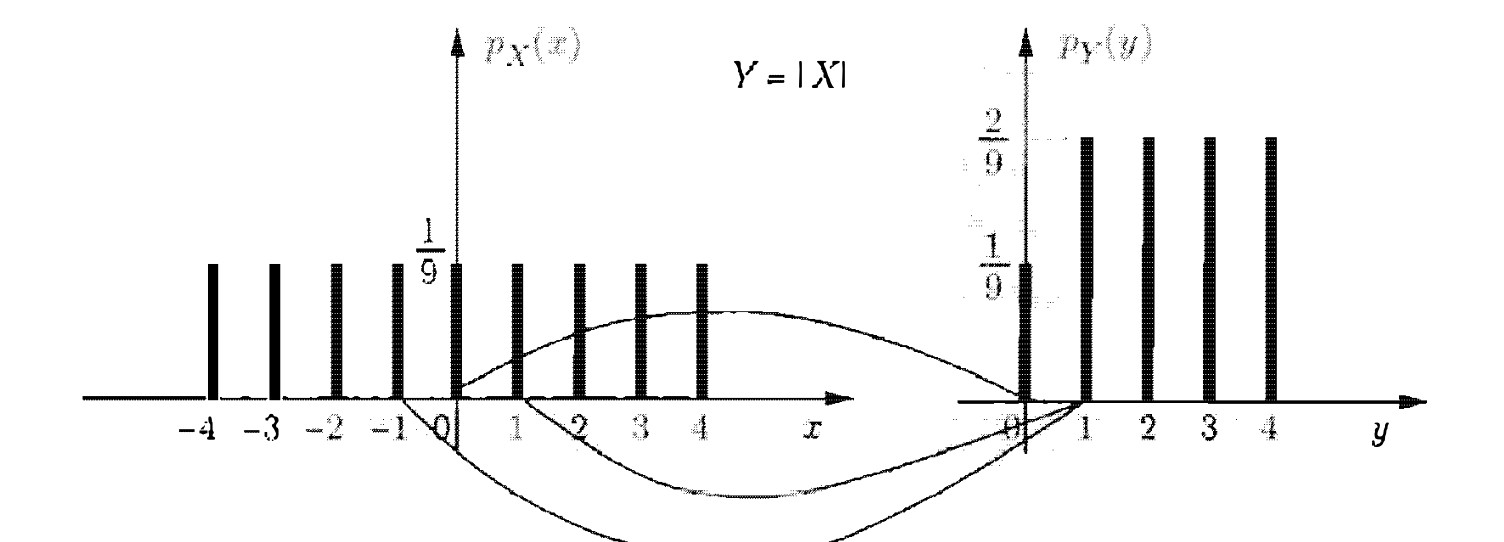
בגלל שלכל שתי ערכים ב
תוחלת ו variance (שונות)
תוחלת
פונקציית מסת ההסתברות ששל משתנה רנדומי X נותנת לנו את ההסתברויות של כל הערכים של X . הרבה פעמים נרצה את זה, אבל נרצה לעתים לכמת את המידע הזה למספר יחיד. המספר הזה הנקרא התוחלת של
כדי לקבל אינטואיצייה נניח שאנחנו מסובבים גלגל מזל מספר רב של פעמים. על כל מספר שמתקבל
נרצה לדעת מה כמות הכסף שאני מצפה להשיג עבור סיבוב. ״מצפה״ ו״עבור סיבוב״ הם קצת מונחים עם מספר משמעויות אבל פרשנות סבירה להן תהיה:
אם נסובב את את הגלגל
אם
לפיכך, כמות הכסף פר סיבוב שאני מצפה להשיג היא
ומכאן נוכל להגדיר באופן ברור יותר את ה תוחלת : נגדיר את התוחלת של משתנה רנדומי
אינטואיטיבית זה עוזר להסתכל על התוחלת של
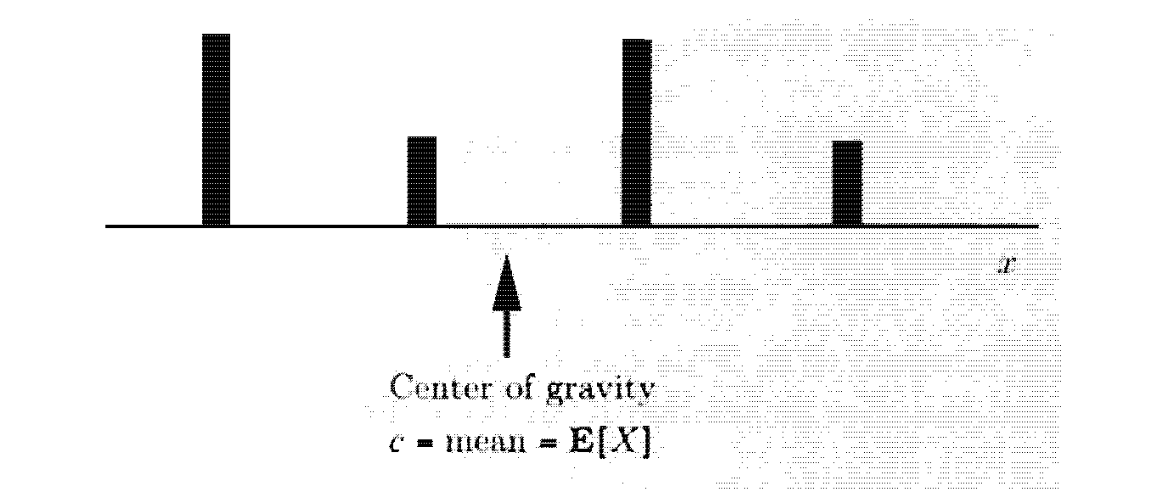
הגרף מראה מה המשמעות של מרכז כוח המשיכה. נניח שהגרף למעלה מתאר לכל נקודה
אם נפתח את זה נקבל
כלומר כדי שההפרש יהיה 0 נרצה ש
מומנט
חוץ מהתוחלת ישנם תכונות נוספות שנרצה לשייך את פונקציית מסת ההסתברות אליהם. לדוגמה מגדירים את המומנט ה2 של משתנה רנדומי
variance- שונות
התכונה החשובה ביותר של משתנה רנדומי
כלומר היא מוגדרת להיות התוחלת של המשתנה הרנדומי
השונות מספקת דרך למדוד את ההתפזרות של
נשים לב שבאופן אינטואיטיבי , השונות מייצגת את ממוצע המרחקים של כל הערכים מהמשתנה הרדנומי למרכז הכבידה שלו
דרך אחת לחשב את השונות היא לפי ההגדרה של תוחלת של משתנה רנדומי. זאת בהינתן שכבר יש לנו את פונקציית מסת ההסתברות של
מחלצים את פונקציית מסת ההסתברות של
נסתכל על הדוגמה הבאה כדי להתחיל לענות על השאלה הזאת
עבור המשתנה הרדנומי
נשים לב שיתקיים במקרה הזה שהתוחלת היא
כעת אם נחשב לפי הגדרה נקבל
מסתבר, שיש דרך קלה יותר לחשב את ה שונות של
כדי להוכיח את זה נשים לב שמתקיים עבור
כלומר לוקחים את כל האיברים ב
סך הכל יתקיים
לפיכך אם נציב את הנ״ל בשונות של
באופן דומה ה מומנט ה
וכך אין צורך לחשב את פונקציית מסת ההסתברות של
אז כמו שניתן לראות , השונות היא תמיד אי שלילית, נשאלת השאלה מתי היא
תכונות חשובות של תוחלת ושונות
- ליניאריות התוחלת: נשתמש בחוק התוחלת של פונקציה שהוכחנו למעלה כדי לפתח כמה תכונות חשובות מאוד של התוחלת והשונות. נתחיל ממשתנה רנדומי
שמוגדר באופן הבא
כאשר
- מסקנה מליניאריות התוחלת על השונות
אם כן נקבל שתי מסקנות חשובות
- נסתכל על דרך נוספת לחישוב השונות של משתנה רנדומי
ההוכחה לכך פשוטה:
המעבר השלישי נובע מהוצאת סקלר של הסכום
נשים לב שאם פונקצייה
-
- עבור
קבוע יתקיים
תוחלת ושונות של משתנים רנדומים נפוצים
תוחלת ושונות של ברנולי
נזכיר שפונקציית מסת ההסתברות של ברנולי נראת כך
כלומר יתקיים ש
כמו כן
ולכן
תוחלת ושונות של משתנה אחיד
נדגים את זה על הטלה של קובייה הוגנת. ה
פונקציית מסת ההתסתברות סימטרית סביב
סך הכל באופן כללי
ִ
ה
נשים לב שפונקציית מסת ההסתברות תיראה ככה
תוחלת ושונות של משתנה פואסון
נזכיר שפונקציית מסת ההסתברות של פואסון היא
עבור התוחלת נקבל
המעבר האחרון נובע בגלל ש
זאת תכונת הנרמלות של פונקציית מסת ההסתברות. חישוב דומה יראה שגם השונות של משתנה פואסון היא
תוחלת ושונות של משתנה בינומי
התוחלת של משתנה בינומי
השונות של משתנה בינומי
תוחלת ושונות של משתנה גיאומטרי
תוחלת ושונות של משתנה גיאומטרי
קבלת החלטות על ידי שימוש בתוחלת
נסתכל על בעיה הסתברותית בשם the quiz problem . בהינתן משחק חידות שבו בן אדם מקבל שתי שאלות וחייב להחליט לאיזה שאלה הוא יענה ראשון. (הבחירה היא לא מקרית).
שאלה 1 תיענה נכונה בהסתברות של
שאלה 2 תיענה נכונה בהסתברות
אם השאלה הראשונה שנבחר נענית לא נכונה , המתמודד לא יכול להמשיך לשאלה השנייה. אם השאלה הראשונה נענתה נכונה, המתמודד יכול ללכת לשאלה השנייה.
השאלה המתבקשת היא, איזה מהשאלות עלינו לענות ראשונה על מנת למקסם את הרווח שלנו.
השאלה לא כל כך אינטואיטיבית בגלל ההשלכות של בחירת השאלה , במידה ואטעה לא אוכל להמשיך.
כדי לענות על השאלה ששאלנו, נסמן את הפרס הכולל שנזכה בו כשמשתנה רנדומי
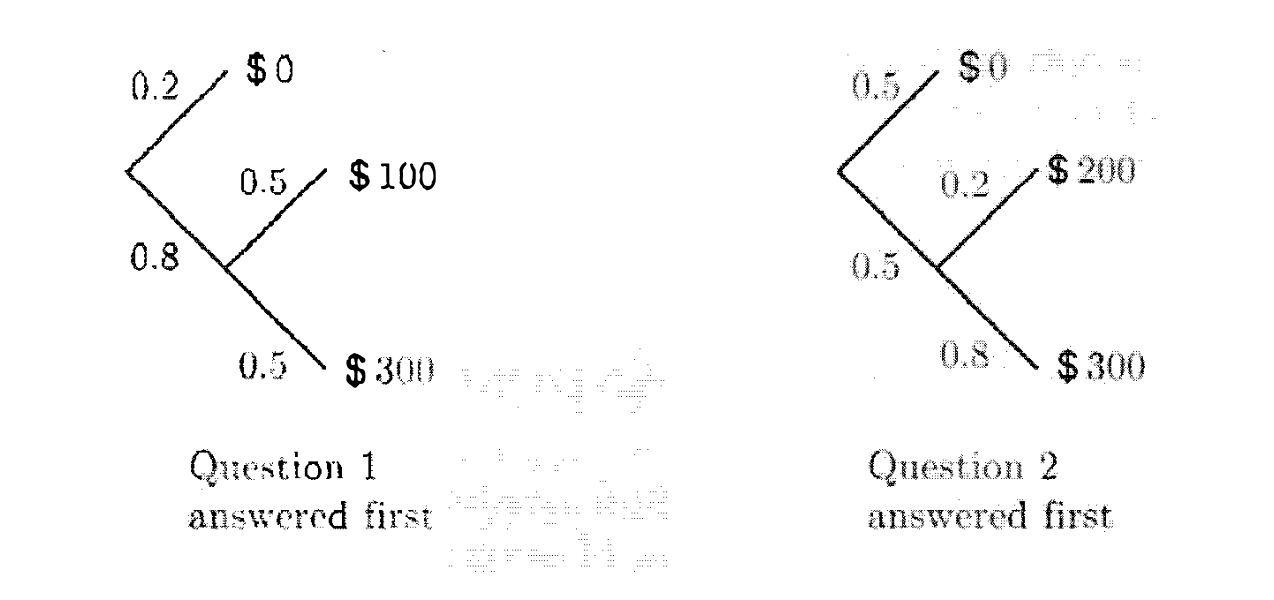
א) נענה על שאלה אחת קודם, במצב זה ה PMF של X יהיה
במצב זה התוחלת תצא
ב) נענה על שאלה שתיים קודם, במצב זה ה PMF של X יהיה
ובמצב זה התוחלת תהיה
אם כן, נראה כי בחירה של השאלה הראשונה עדיפה שכן התוחלת או מרכז המסה של הסכומים שבהם נזכה יהיה יותר גדול.
נוכל להכליל את המסקנות מהתרגיל הזה באופן הבא:
בהנתן
אם שאלה אחת נענית קודם נקבל
אם השאלה השנייה נענית ראשונה נקבל
כלומר נקבל סך הכל שבחירה של שאלה אחת היא אופטימלית אם ורק אם
כלומר הבחירה האופטימלית היא סידור השאלות בסדר יורד של הביטוי הזה. (ניתן להכליל את זה אף יותר למקרה של