interrupts
נחשוב על הפעולה הבאה, תוכנה מבצעת פעולת I/O .
למשל, אתם משתמשים בתוכנת הצייר של windows וביצעתם לחיצה על העכבר שמטרתה לצבוע אזור מסויים במסך באדום.
נבין מה קורה בעת לחיצה על העכבר.
- מידע מסויים נטען באמצעות ה device drivers לרגיסטרים המיוחדים שדיברנו עליהם שנמצאים בcontroller המטעים עבור העכבר.
- הקונטרולר בתמורה, בוחן את תוכן הרגיסטרים האלה כדי לקבוע איזה פעולה הוא צריך לעשות.
- הקונטרולר מעביר את המידע מהרגיסטרים לבאפר המקומי.
- ברגע שהמידע הזה הועבר , הקונטרולר מעדכן את הדרייבר עם interrupt שהוא סיים את הפעולה שהוא מבצע והדרייבר מעניק שליטה לחלקים אחרים במערכת ההפעלה ותוך כדי גם מעביר את המידע שהוא צריך באמצעות פוינטר או החזרת המידע עצמו (במקרה שלנו נעביר מידע על הפעולה שהעבר ביצע והמיקום שלו כנראה).
- הדרייבר מחזיר בסטטוס ביצוע עבור הפעולה שביקש לבצע , כמו flag שמסמן האם הפעולה הסתיימה , השתבשה או משהו אחר קרה.
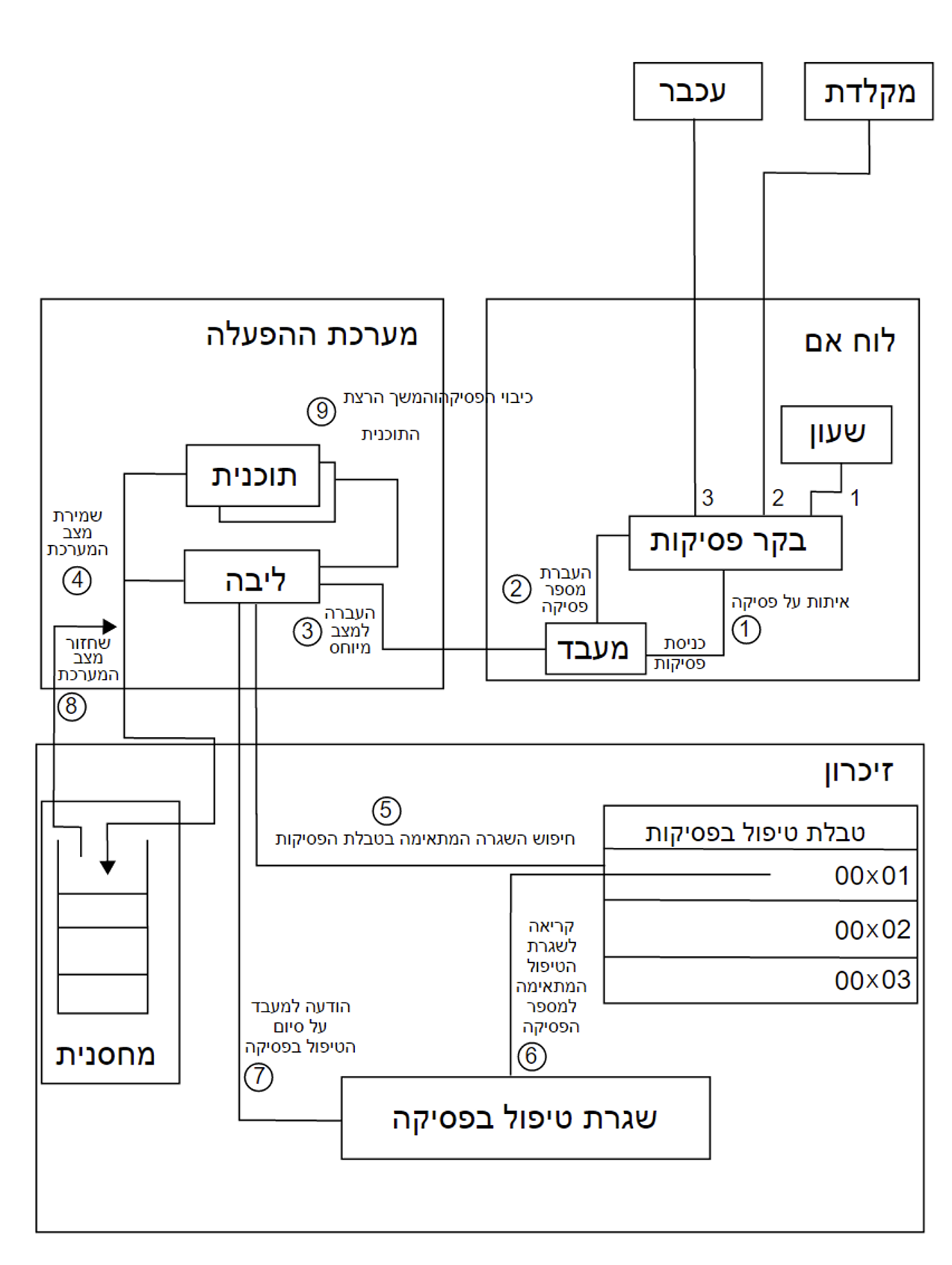
סקירה של interrupt
החומרה יכולה להפעיל פעולה זו בכל רגע נתון על ידי שליחה אות אל הCPU. בדרך כלל זה יקרה באמצעות הsystem bus . פעולה זו היא חלק אינטגרלי ממערכת ההפעלה והתממשקות עם החומרה. כאשר ה CPU מזהה ״הפרעה״ הוא מפסיק את מה שהוא עושה ומיד עובר לבצע פעולה מ מיקום קבוע בזכרון. המיקום הזה הוא בעצם נקודת התחלה של קוד מסויים שנקרא service routine. ברגע ההפרעה הרוטינה מורצת ובסיום ה CPU ממשיך את התוכנית שהוא ביצע לפני ההפרעה.
הדוגמה הבסיסית ביותר היא כאשר אנחנו מבקשים ממערכת ההפעלה להדפיס משהו למסך בתוכנית hello world שכתבנו. בעת קריאה לפונקציית printf מתבצעת הפרעה שכזו דרך הkernel באמצעות system call , ולאחר ההפרעה הרוטינה הרלוונטית מדפיסה למסך את מה שביקשנו.
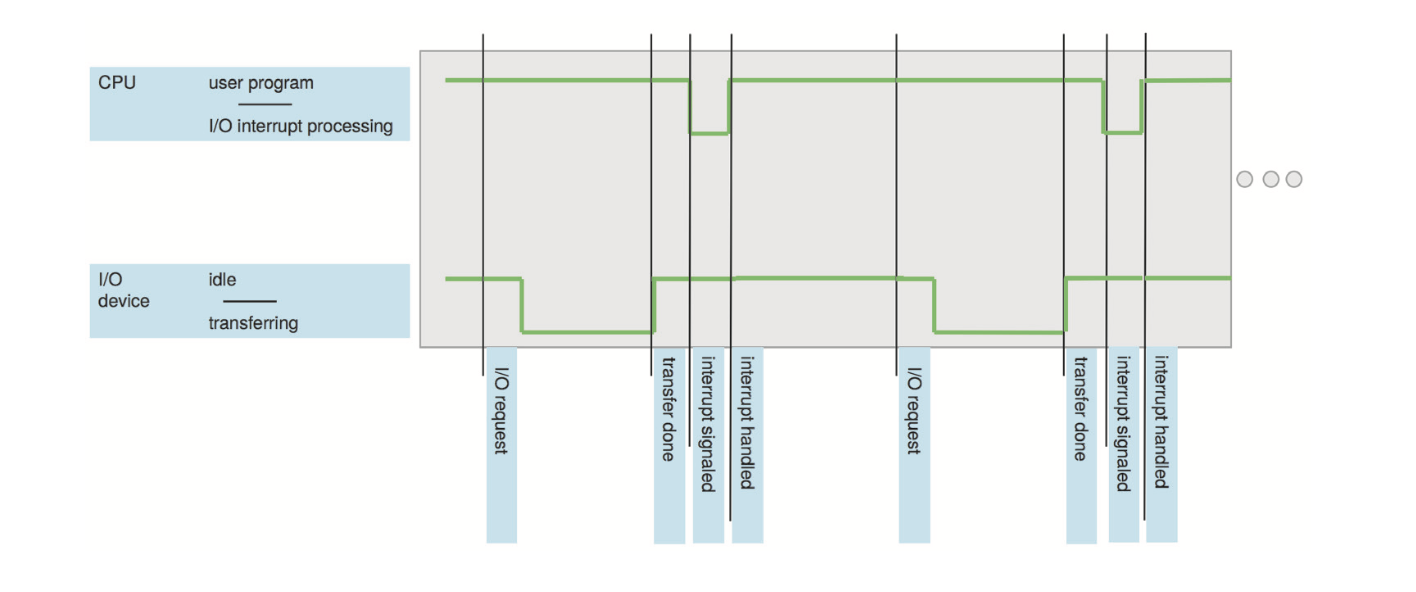
חשוב לציין שלכל ארכיטקטורת מחשב יש מכניקת הפרעות משלה אבל עם זאת גם הרבה מהפונקציונליות הן משותפות לכל מערכות המחשב.
ההפרעה חייבת להעביר את השליטה לרוטינה הרלוונטית. הגישה הכי ״נאיבית״ כדי לנהל את זה היא להגדיר רוטינה נוספת שבודקת מידע על ההפרעה וזאת בוחרת לקרוא לרוטינה הרלוונטית בהתאם למידע המתקבל. ממש כמו switch case על סוג ההפרעה. שיטה זאת נקראת polling ובגלל שזה יכול להיות איטי וחסום בבדיקה של כל האינטרפציות האפשריות, השיטה שעליה הולכים היא להחזיק מעין jump table של מצביעים ובאמצעותה ברגע ההפרעה ואיזה מניפולציה על המידע שלה נוכל להגיע ישירות לרוטינה הדרושה.
הטבלה הזאת ממוקמת מאוד נמוך בזכרון והיא נקראת גם interrupt vector של הכתובות שניתן להמיר מידע של אינטרפט לאינדקס בוקטור הזה כדי להגיע לאן שצריך. השיטה באופן כללי נקראת vectored interrupt system והיא בעצם אומרת שכאשר ישנה הפרעה היא עוברת כאות חשמלי שונה שמייצג מספר, המספר הזה יהיה ממופה לאינדקס בוקטור.
מימוש
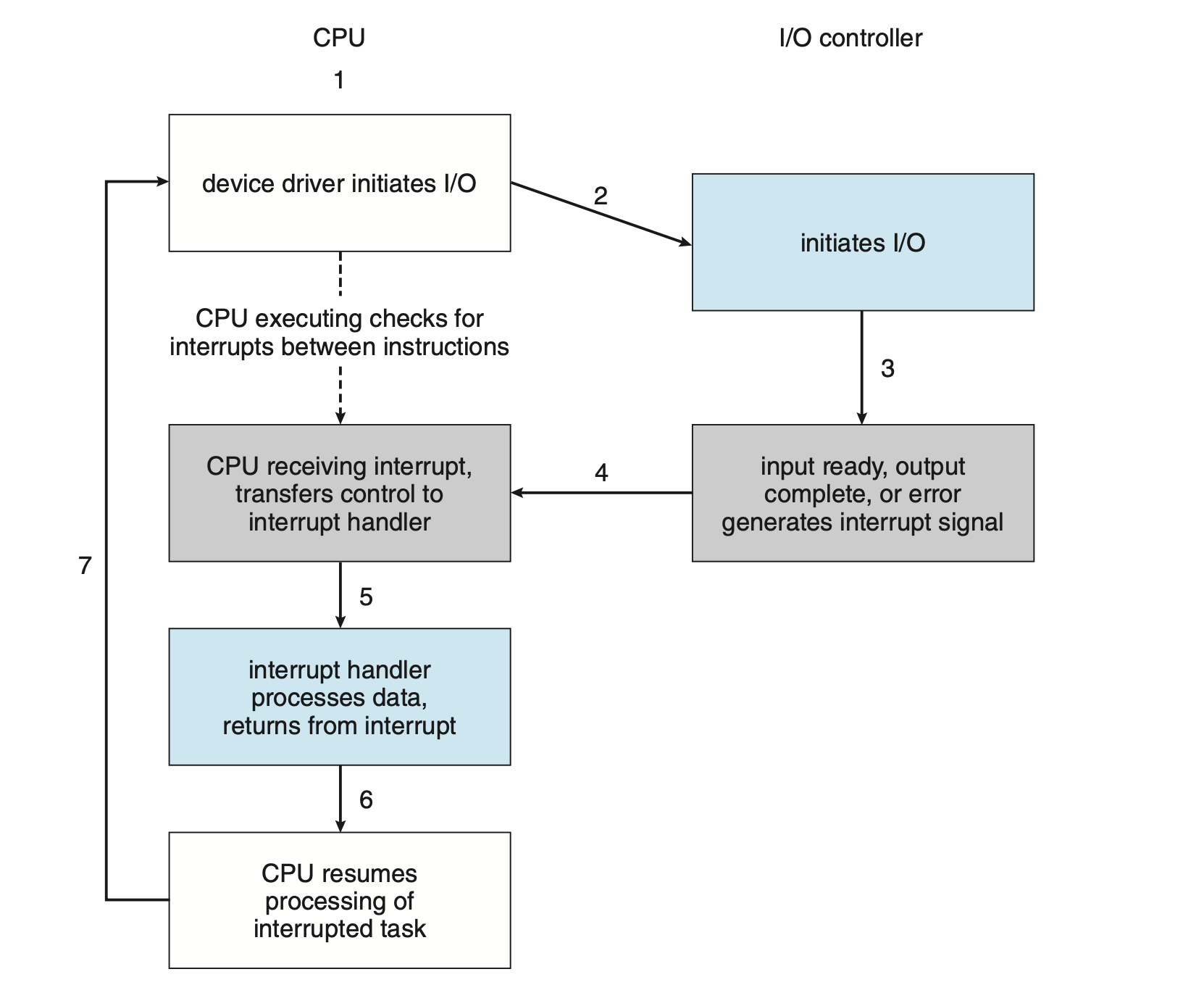
מכניקת ההפרעה עובדת באופן הבא. ה CPU מכיל חוט שנקרא interrupt request line שה CPU דוגם לאחר ביצוע כל פקודה. כאשר ה CPU מזהה שקונטרולר מסויים שלח הפרעה הוא קורא את מספר ההפרעה וקופץ לרוטינה המתאימה על ידי שימוש במספר הנ״ל כאינדקס עבור הטבלה.
לפני שהרוטינה מתחילה לבצע את המימוש של ההפרעה היא שומרת את הstate שהיה לפני כיוון שהפעולות שיבוצעו עלולות לשנות את זה ולאחר מכן משחזרת את הכל למצב הקודם. בסיום סיומת היא מריצה את פקודת return_from_interrupt שמחזירה את ה CPU למצב שהוא היה לפני ההפרעה.
נאמר שהקונטרולר מרים הפרעה על ידי שליחת אות על הקו והCPU תופס הפרעה ומבצע עליה dispatch לרוטינה המתאימה ה interrupt handler והוא לבסוף מנקה את ההפרעה.
interrupt-driven I/O cycle
מנגנון ההפרעות הבסיסי שתיארנו למעלה מאפשר ל CPU להגיב לאירועים באופן אסינכרוני בהתאם לקונטרולר המתאים. אבל במערכות הפעלה מודרניות נרצה מכניקות קצת יותר מורכבות מזה
- נרצה את היכולת לדחות interrupt כאשר יש איזשהו חישוב קריטי.
- נרצה דרך יעילה לבצע dispatch ל handler המתאים עבור מכשיר כלשהו.
- נרצה מנגנון מרובה שלבים של הפרעות כך שמערכת ההפעלה תוכל להבדיל בין הפרעות בעדיפות גבוה והפרעות עם עדיפות נמוכה ותוכל להתמדד עם כל אחד בהתאם לרמה הזאת.
במערכת מחשב מודרניות היכולות הנ״ל מוענקות על ידי ה CPU וה interrupt controller hardware.
פתרון לבעיה 1
לרוב המעבדים יש 2 interrupt request lines . האחד הוא nonmaskable interrupt שנשמר עבור אירועים כמו חריגות שלא ניתנות לטיפול.
השני נקרא maskable והוא יכול להיות מכובה על ידי המעבד לפני ביצוע פקודות קריטיות שאסור שהפרעה תפגע בהן. זה הקו שהקונטרולרים משתמשים בו על מנת לבקש שירות.
פתרון לבעיה 2
כפי שאמרנו נרצה להחזיק vector עם כתובות כדי שלא תהיה רוטינה אחת (interrupt handle) גדולה שמחפשת את מקור ההפרעה מבין כל הרכיבים. אבל במחשבים מודרנים יש המון מכשירים ולכן גם המון handleres , יותר משהם יכולים להחזיק בוקטור הכתובות. כדי לטפל בבעיה זו משתמשים ב interrupt chaining, שבה כל אלמנט בוקטור מצביע לראש של רשימה של handleres. (מזכיר קצת שרשור של רשימה מקושרת). כאשר הפרעה עולה, מגיעים לראש הרשימה הרלוונטית וקוראים את הhandleres אחד אחרי השני עד שמוצאים את הרוטינה שיכולה לטפל בהפרעה הספציפית הזאת. זאת בעצם מהווה פשרה בין קוד אחד גדול שבודק את כל ההפרעות האפשריות לבין וקטור גדול מאוד של כתובות.
פתרון לבעיה 3
על ידי הגדרת interrupt priority levels המעבד יכול לדחות את הטיפול בהפרעות בעדיפות נמוכה מבלי להגדיר שכל ההפרעות הן maskables.
בנוסף להפרעות שעוברות דרך הקו ישנן הפרעות תוכנה שנקראות trap , אלו לא בהכרח נקראות מרכיב I/O אלא משגיאה או בקשה של תוכנית כלשהי