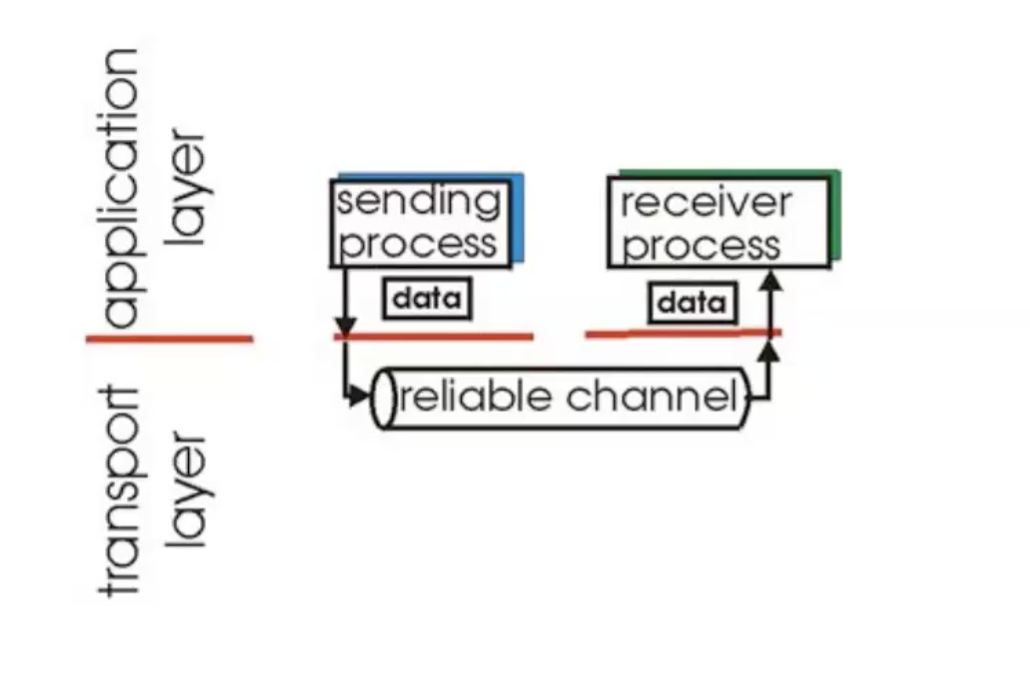
שכבת התעבורה
שכבת התעבורה אחראית להעביר מידע מProcess ל Process מרוחק. כחלק מכך, יש לה שתי מטרות עיקריות:
א) ריבוב מספר אפליקציות על אותה הend system. כלומר היכולת להשתמש בכמה שירותים של אותה מערכת קצה (כלומר עבודה מול כתובת IP בודדת) ולהשתמש בכמה שירותים שונים של הישות, כך שהיא תדע להבדיל איזה זרם שייך לאיזה שירות שהיא מספקת.
ב) העברה אמינה של מידע (אופציונלי).
אנחנו כבר יודעים איך שכבת התעבורה מאפשרת עבודה מול כמה שירותים של אותה מערכת Ports.
Port הוא מספר בטווח
פרוטוקולים מבוססי קישור ולא מבוססי קישור
בשכבת התעבורה פרוטוקולים יכולים להיות Connection Oriented או Connection Less
Connection Oriented
על מנת לתקשר עם מישהו בפרוטוקול מסוג זה, ראשית יש להקים את הקישור (בSockets עושים את זה באמצעות accept) לפני שמקבלים מידע. אפשר להקביל את זה לטלפון שבו צריך להתקשר למישהו ספציפי ואי אפשר לדבר לטלפון ושמישהו יענה. פרוטוקולים כאלה מבטיחים אמינות בשליחת המידע כלומר, שכל המידע שנשלח יגיע אל המקבל בסדר שבו הוא נשלח .
Connection Less
בפרוטוקול זה אין הבטחה שחבילה שנשלחת תגיע ליעדה והיא לא מכירה את החבילות האחרות שנשלחות בקשורות לאותו הdata. לכן גם אין הבטחה שהחבילות יגיעו בסדר הנכון. המסקנה מכך היא שאין צורך להרים ולסגור חיבור כל שצריך לעשות הוא לשלוח את החבילה.
על פניו נראה שאין שום יתרון להשתמש ב Connection Less אבל, יש יתרון פשוט. מהירות נוכל לממש התנהגות שלנו שתאבטח את UDP בשכבת האפליקצייה ולקבל חלק מההתנהגות הדרושה וכך גם לצמצם את התקורה כי אנחנו מתאימים את הפרוטוקול למוצר הספציפי שלנו. זהו עקרון שדי חוזר על עצמו בתכנות שככל שמכלילים יותר התנהגות מסוימת ככה התקורה עבורה גבוהה יותר
UDP VS TCP
הפרוטוקולים הכי נפוצים בשכבת התעבורה הם UDP ו TCP וכל מהם הוא סוג אחר של חיבור עם יתרונות וחסרונות משלו. לפני שנדבר על כל אחד בנפרד נשווה בינהם עם הפרמטרים החשובים:
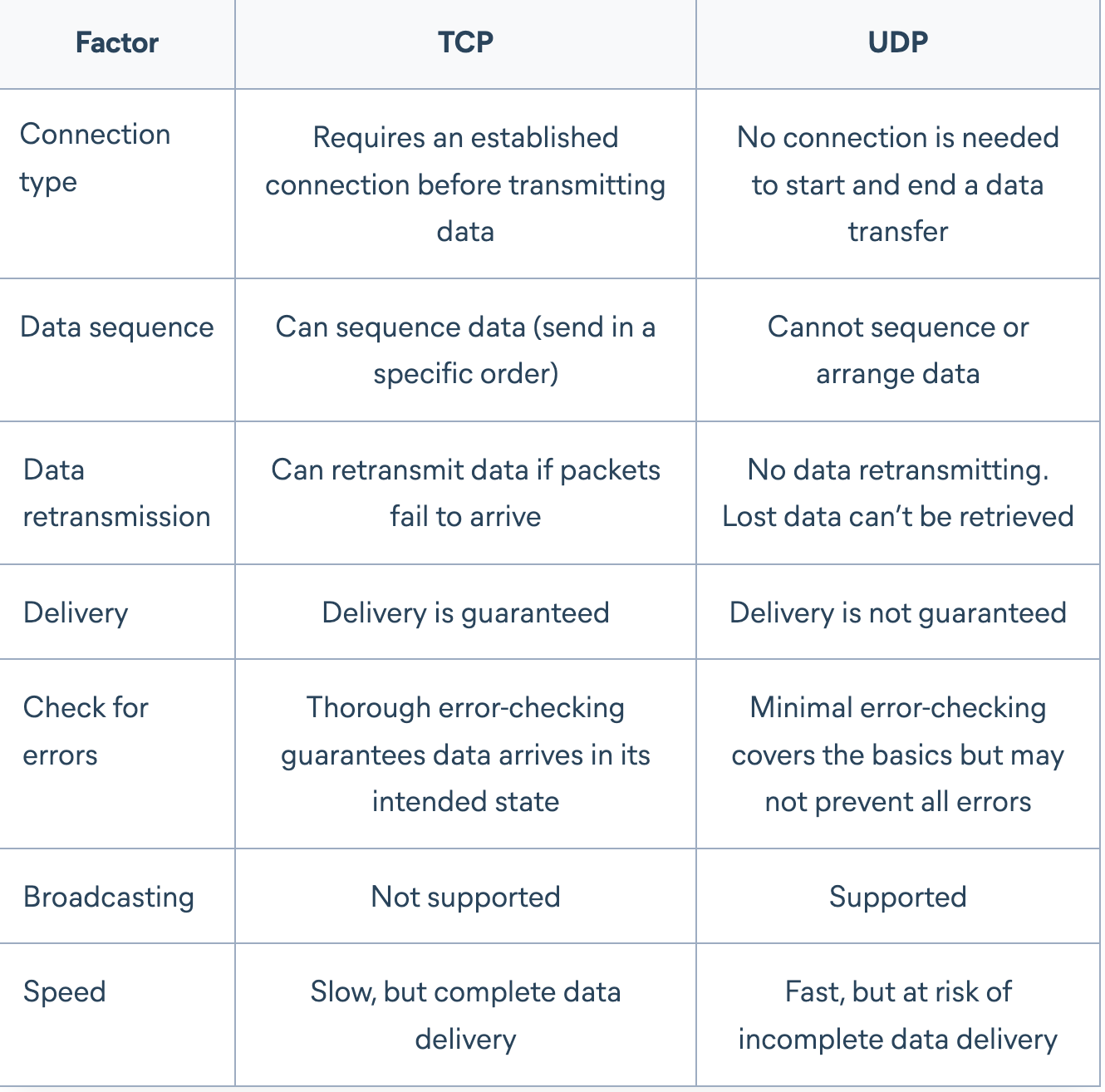
UDP
פרוטוקול שאינו מבוסס קישור. לכן הוא אינו מבטיח הגעה של המידע כלל והגעה בסדר הנכון בפרט.
ב header של פקטת UDP יש בסך הכל את השדות הבאים:
א. Source Port
ב. Destination Port
ג. Length - גודל ה header והמידע יחד בפקטה
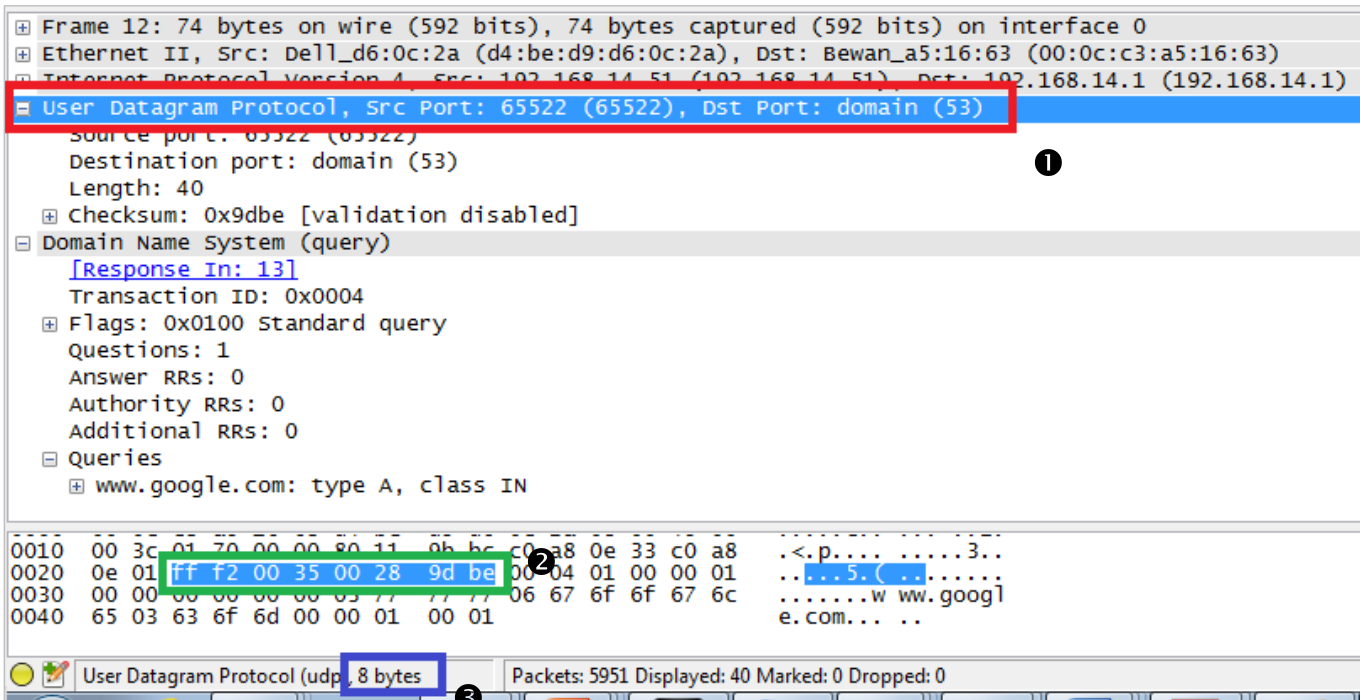
ניתן לראות בעצם שגודל הheader הוא
ד. Checksum- ציינו שבעיות ברשת יכולות לגרום לחבילות לא להגיע בכלל, או לרצף של חבילות להגיע ברצף הלא נכון. בעיות ברשת יכולות לגרום גם לשגיאות בחבילה עצמה - כלומר שהחבילה תגיע עם תוכן שונה ממה שהיא נשלחה. במצב שכזה נרצה שהשרת ידע שארעה שגיאה ולא יתייחס לפקטה התקולה.
Checksum
טכניקה שמאפשרת לקבוע את אמינות המידע המתקבל ומאפשר לזהות האם קרתה שגיאה (לא מזהה את השגיאה עצמה).
השולח משתמש באלגוריתם כדי לחשב את הChecksum של המידע. כאשר המקבל תופס את המידע, הוא מחשב את הchecksum בעצמו באותו האלגוריתם ומשווה עם הchecksum שעבר. אם יש התאמה אז אין שגיאות
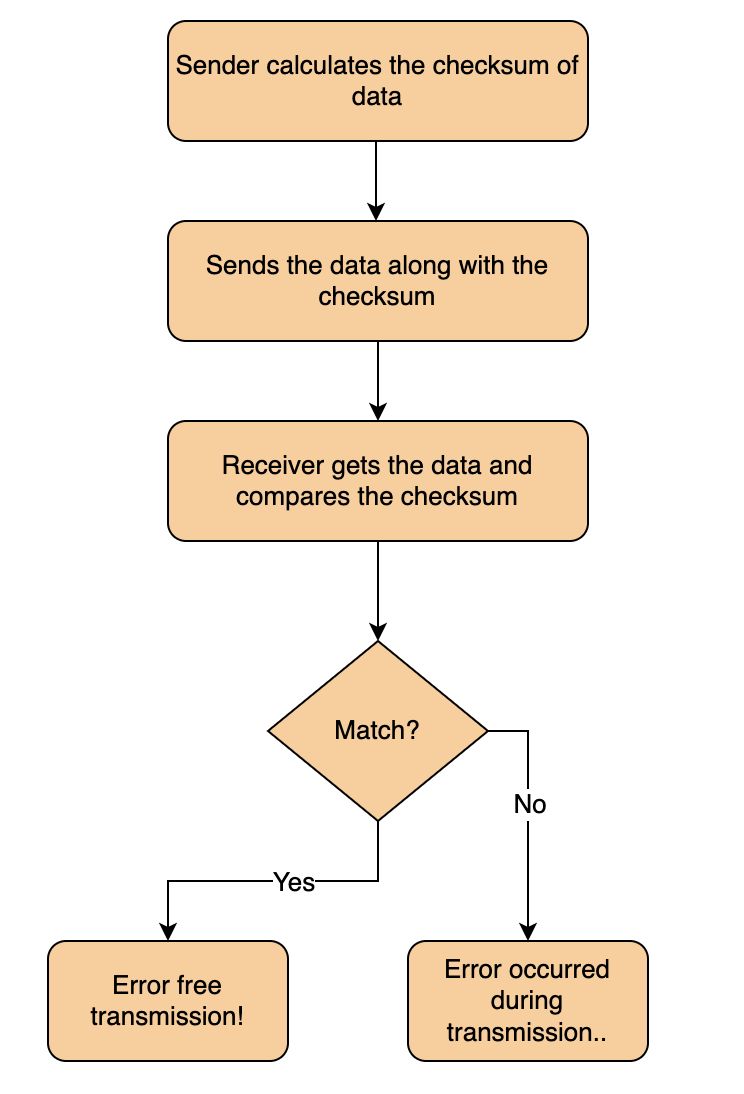
במקרה של UDP המידע מחולק לחתיכות של 16 ביט. החתיכות האלה מחוברות יחדיו, אם יש carry מוסיפים אותו ל sum. לאחר מכן מפעילים one's complement על הסכום (not על הביטים) וזה ה checksum.
למשל נסתכל על הdata הבא:
נסכום את השניים הראשונים נקבל :
לתוצאה נוסיף את 16 הביטים הנותרים :
נוצר לנו carry ולכן יש להוסיף אותו לסכום (wraparound) ונקבל
לבסוף נבצע not על התוצאה ונקבל:
בצד המקבל נעשה את אותו חישוב של הסכימה, לבסוף נסכום עם הchecksum שהעברנו ואם הסכום יוצא שכל הביטים הם
ברגע שהשגיאה היא יותר מbit אחד יש מצב שהchecksum יצא אותו דבר למרות שהייתה שגיאה. כמו כן יכול להיות שגיאה בchecksum עצמו..
TCP
פרוטוקול שכבת התעבורה הנפוץ ביותר לחיבורים מבוססי קישור.
כאשר בשכבת האפליקציה נרצה להעביר מידע באמצעות tcp, אנחנו לא יכולים פשוט לשלוח חבילה אל תוכנה מרוחקת. ראשית עלינו ליצור קישור עם התוכנה המרוחקת ועתה כל חבילה שנשלח תהיה חלק מאותו קישור.
TCP תוכנן ועוצב לרוץ מעל שכבת רשת שאינה אמינה. כלומר, הנחת הבסיס היא שבשכבת הרשת חבילות יכולות ללכת לאיבוד או להגיע בסדר לא נכון.
כיצד ניתן לוודא שהמידע מגיע אל היעד? וכיצד ניתן לוודא שהוא מגיע בסדר הנכון?
על מנת לעשות זאת, TCP מנצל את העובדה שהוא פרוטוקול מבוסס קישור. מכיוון שכל החבילות (בשכבת התעבורה segment) הן חלק מקישור, אנו יכולים לבצוע דברים רבים.
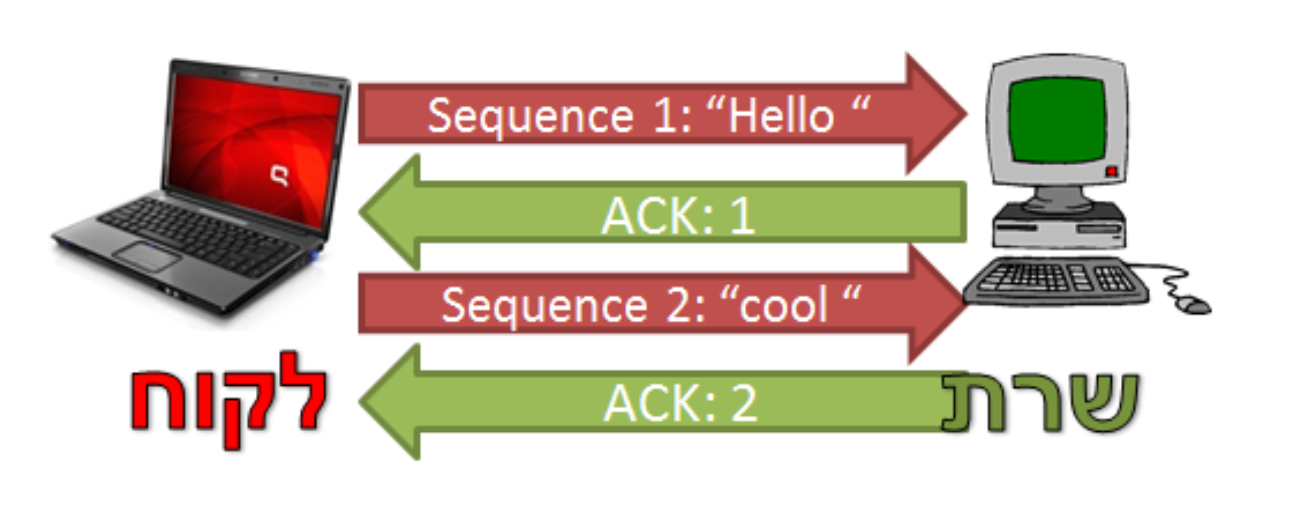
ראשית, אנו יכולים לתת מספר סידורים לחבילות שלנו. נאמר שבשכבת האפליקציה רצינו לשלוח את המידע "Hello Cool Network" והחלוקה לחבילות הוא חבילה פר מילה.
נוכל לשלוח את החבילות כשלצידן יש מספר סידורי

בצד שרת חבילות יכולות ליפות ונניח שחבילה 2 נפלה בדרך. בשיטה שלנו השרת יבין שחסרה לו חתיכה מספר 2.

ניתן להשתמש במספרי החבילות כדי לוודא שחבילה אכן הגיעה ליעדה. כך למשל, ניתן להחליט שעל כל חבילה שהגיעה, השרת שולח אישור ללקוח. חבילה כזו נקראת בדרך כלל ACK ומשמעותה ״קיבלתי את החבילה״. הלקוח יצפה לקבל ACK על כל חבילה אותה הוא שולח.
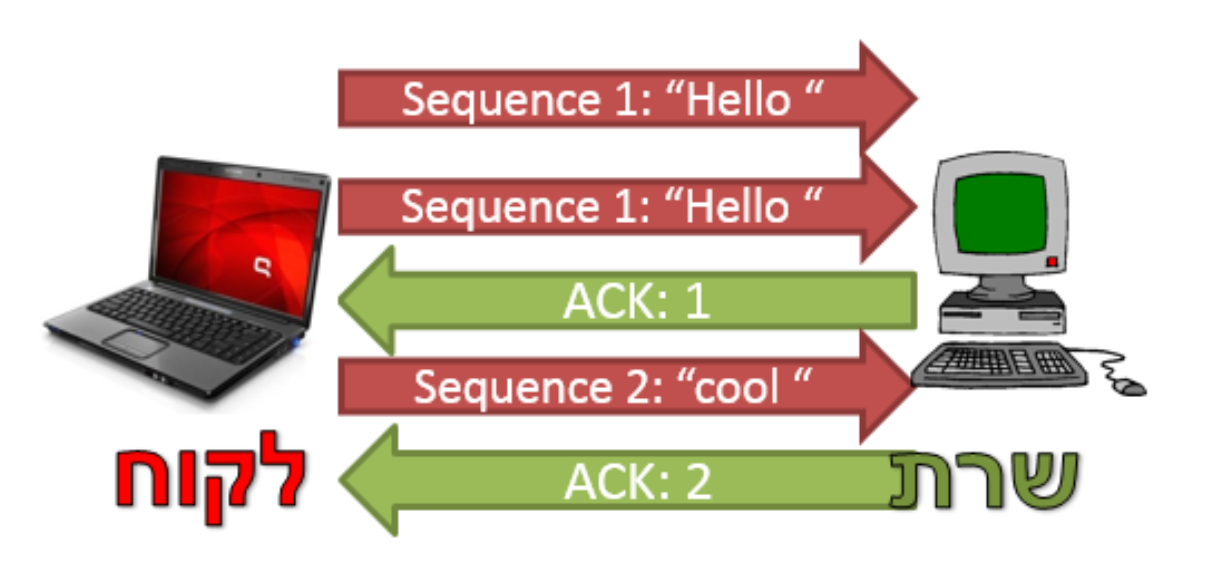
בצד לקוח, אם לא התקבלה חבילת ACK מהשרת לאחר זמן מסוים, כנראה שהחבילה שהוא שלח ״נפלה״ ובמקרה כזה היא תשלח שוב
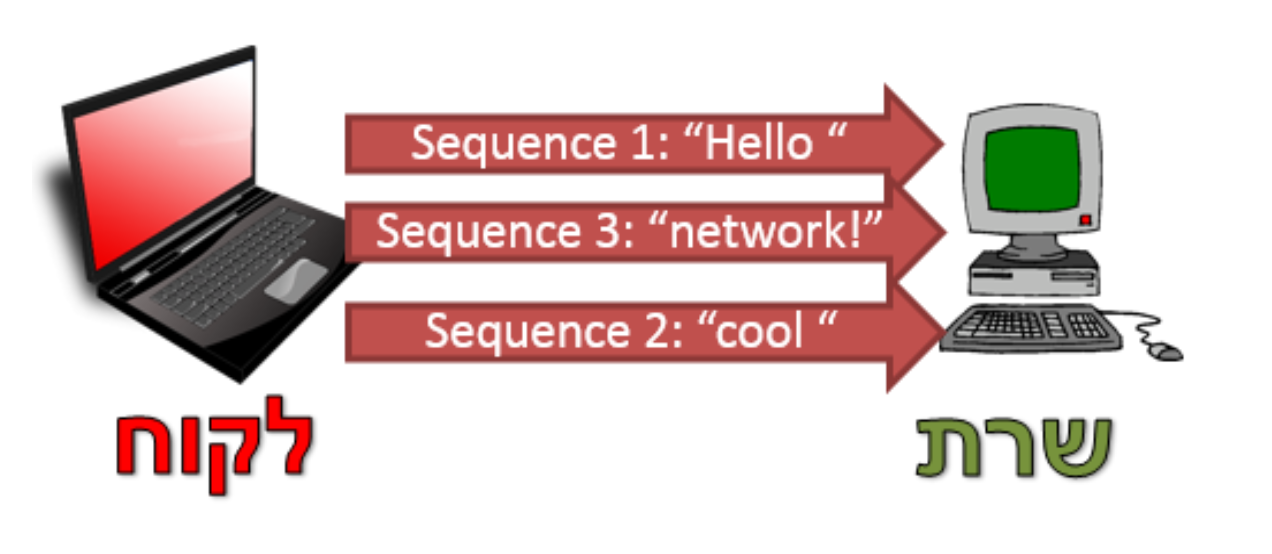
באופן הזה הצלחנו להבטיח שהחבילות אכן הגיעו ליעדן. השימוש במספר סידורי לכל חבילה מאפשר לנו להתמודד עם הבעיה של סדר הגעת החבילות.
המימוש ב TCP
ה headers ב TCP מכיל את אותם השדות של UDP ושדות נוספים, ההבדל הוא שבמקום length יש head-length שמייצג רק את הגודל של הheader.
באמצעות הchecksum אפשר לגלות שגיאות, אך אם נגלה שגיאה ב UDP הוא פשוט יזניח את הפקטה, כאן צריך להשתמש במנגנון ה ACK כדי לאשר שאכן המידע הגיע תקין או NAK כדי להודיע שהמידע הגיע לא תקין. בגלל שגם ACK/NAK יכול להשתבש בגלל שגיאות אנחנו נכניס אותו כ header TCP מלא בתשובה ונניח שהchecksum יכול לתפוס את זה. (זה במקום לשלוח פשוט ACK bit).
הפרוטוקול TCP לא נותן מספר סידורי לכל חבילה, אלא לכל byte. כזכור, אנחנו מעבירים מצד לצד רצף של בתים. לכל אחד מהבתים ברצף יש מספר סידורי משלו. בכל חבילה שנשלח, יהיה המספר הסידורי שמציין את הבית הנוכחי בחבילה.

המחרוזת
החבילה השנייה התחילה עם המספר הסידורי

נשים לב שמדובר בתקשורת בין הלקוח לשרת בדוגמה, אך באותו אופן זה יכול להיות בין שרת ללקוח.
נסתכל על דוגמה שבה הclient רוצה לשלוח שתי הודעות מופרדות הראשונה היא Hello והשנייה היא World.
ה client שולח את ההודעה הראשונה לשרת ומחכה לack . רק אחרי שהוא מקבל את הack הוא יעביר את ההודעה הבאה.
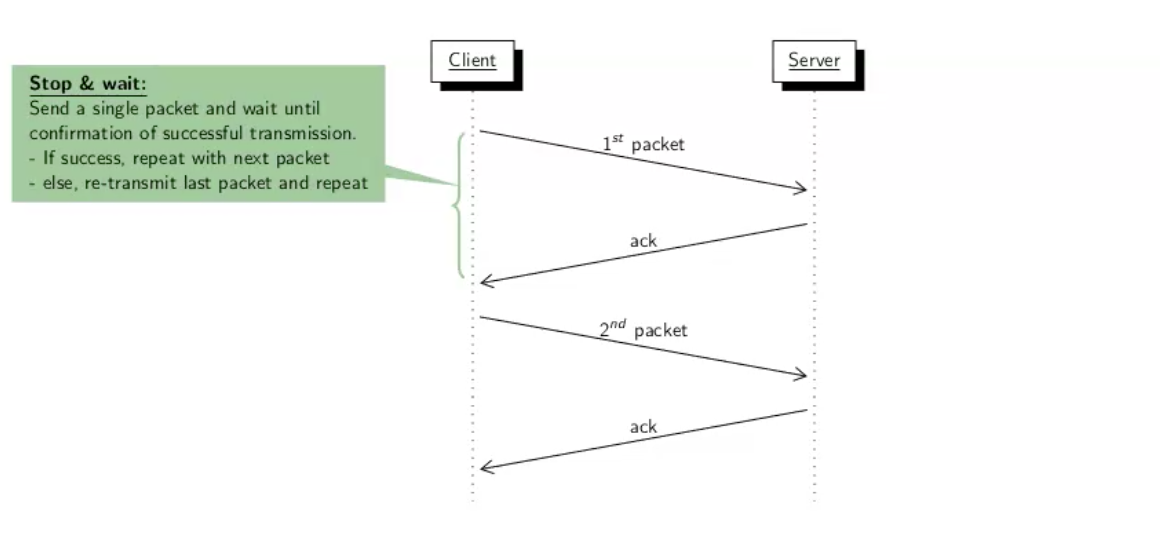
המנגנון הזה נקרא Stop & Wait כלומר אם התקבל nak נשלח שוב את הפקטה שעבורה התקבל nak.
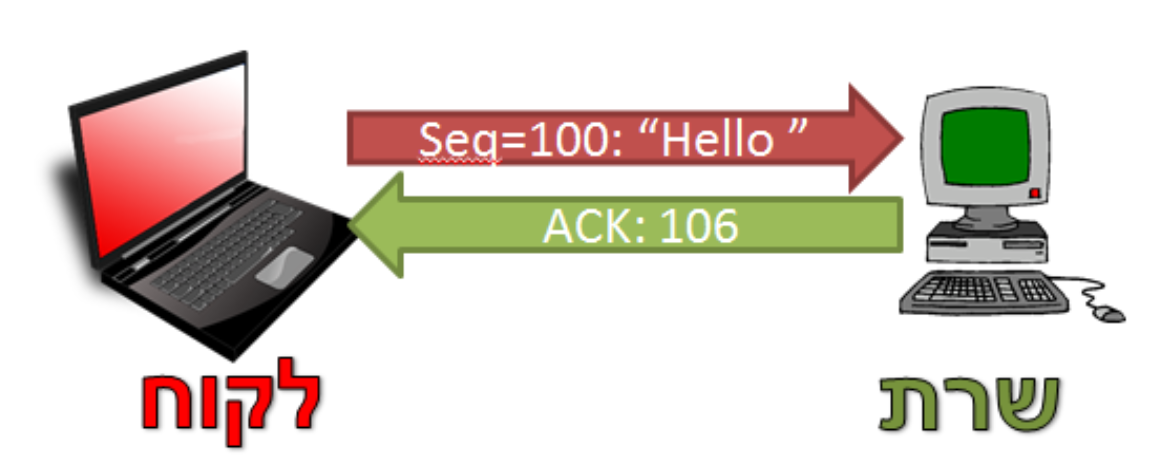
נשים לב שהשרת שולח כresponse את ה tcp header בלי data.
מכיוון שהמספרים הסידוריים של TCP מתייחסים לבתים ברצף המידע כך גם מספרי ה ACK. מספר ה ACK ב TCP מציין את המספר הסידורי של הבית הבא שמצופה לקבל. כך למשל עבור הדוגמה הקודמת
נקבל
בצורה זו קל מאוד לבצע מעקב אחרי התקשורת. מכיוון שה ACK מכיל את המספר הסידורי הבא, הרי שזה יהיה המספר הסידורי שיישלח בחבילת המידע הבאה. כך בדוגמה זו, רצף החבילות יראה כך:
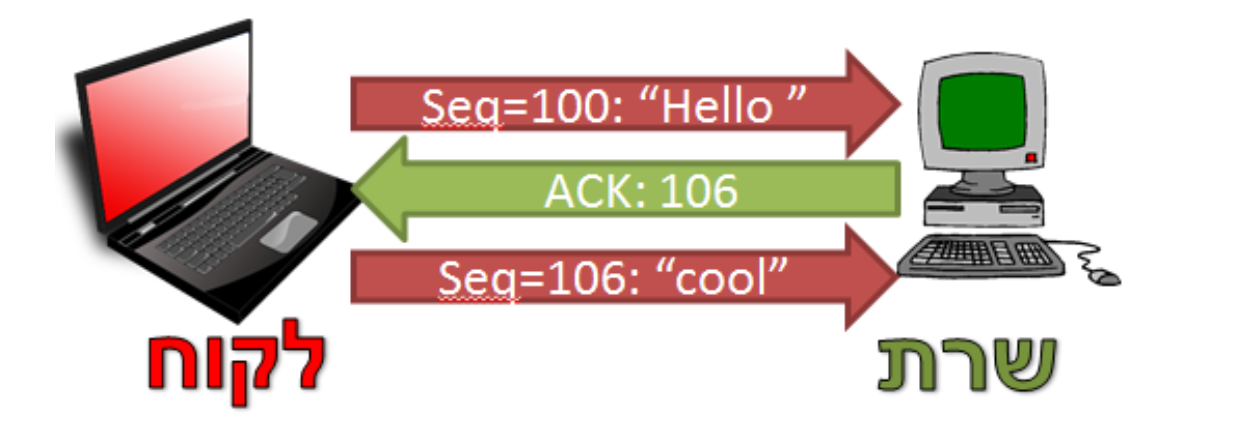
בנוסף, כאשר נשלח ACK ב TCP, הכוונה היא שכל המידע שהגיע עד לבית שמצוין ב ACK הגיע באופן תקין. כך לדוגמה, במקרה לעיל השרת יכול היה לא לשלוח ACK עבור החבילה שכללה את המידע Hello אלא רק לאחר קבלת החבילה שכללה את המידע cool. במקרה זה, ערך ה ACK צריך להיות המספר הסידורי הבא - 110.
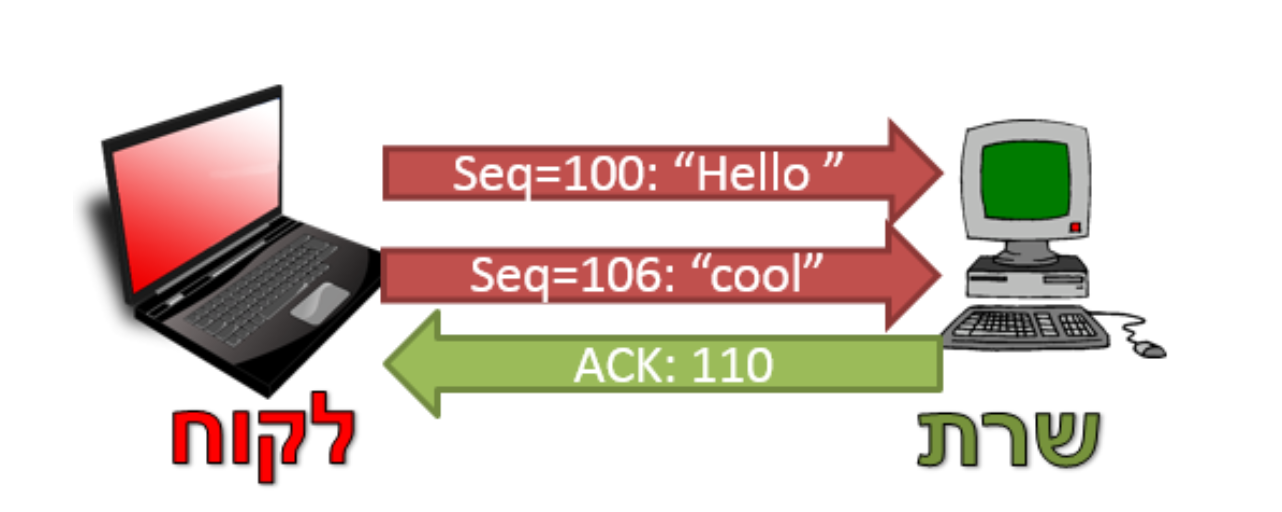
לאחר שליחת החבילות שלו, הלקוח מחכה לזמן מסוים לקבלת הACK. אם ה ACK לא הגיע עד לתום הזמן . הוא שולח אותן מחדש.
TCP Segmentation
כפי שהסברנו, TCP מחלק את המידע לפי bytes. בפועל הוא מבצע סגמנצייה שגודל של כל סגמנט הוא MSS. זה הגודל המקסימלי של מידע עבור שכבת האפליקציה שיכול להיות בתוך פקטה, כך ש כאשר מוסיפים את כל הheaders הדרושים האורך הכולל הוא לכל היותר MTU שזה אומר -maximum transmission unit, בערך
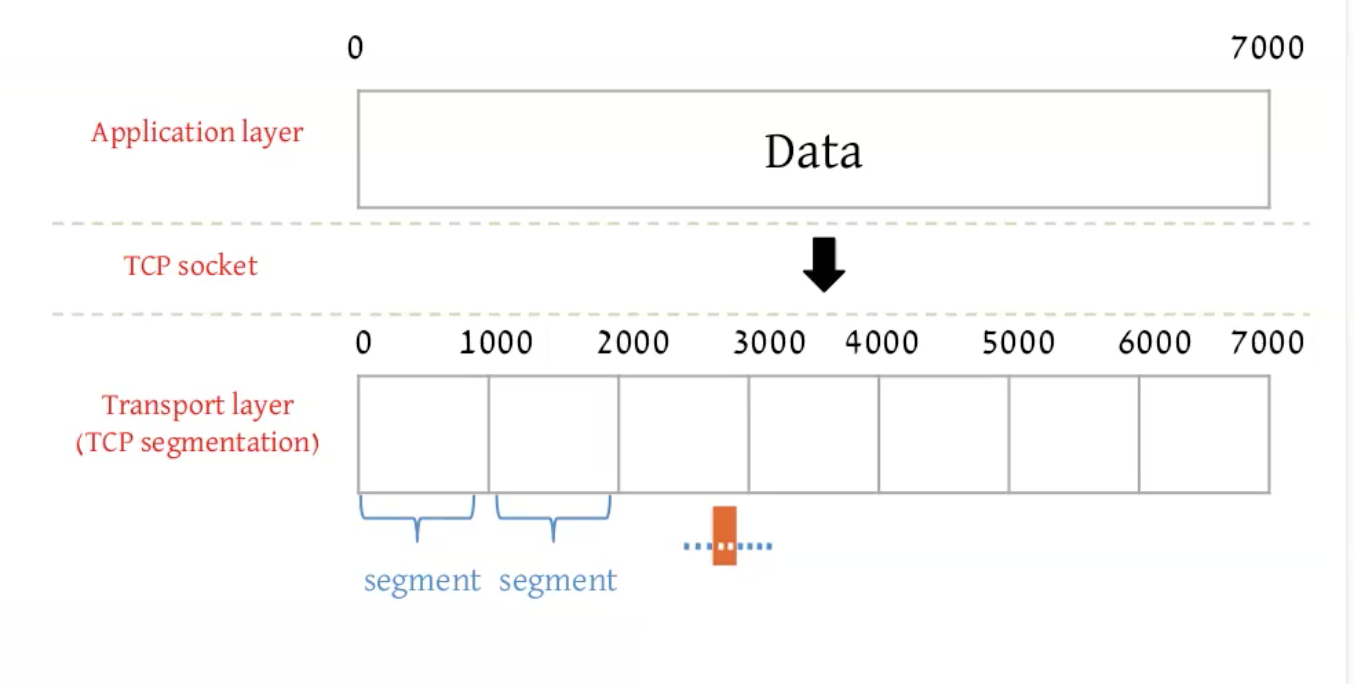
בדוגמה אפשר לראות ששלחנו בשכבת האפליקציה
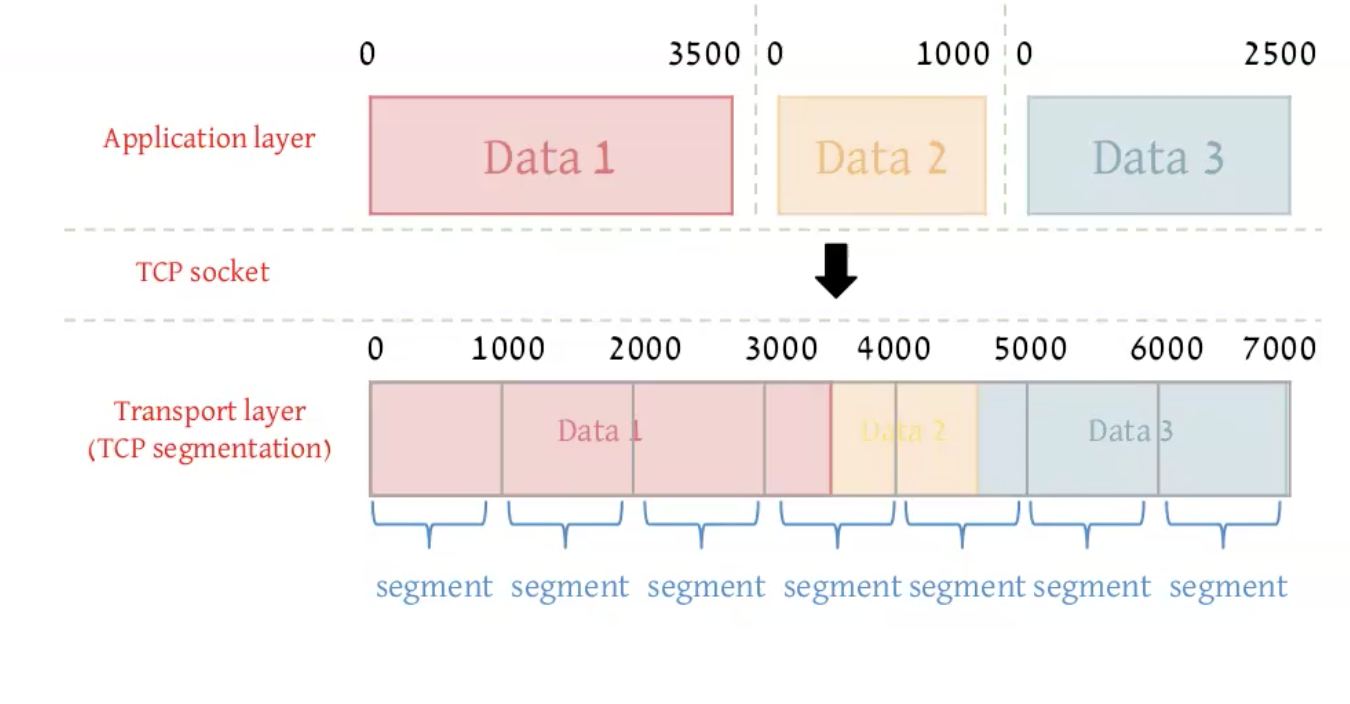
כאשר שכבת האפליקציה שולחת 3 פעמים data , הפרוטוקול TCP , משתמש באותו הבאפר כדי לחלק את הdata בבאפר הזה, יכול להיות מצב שsegment אחד מקבל חלקים משני סוגי data אחרים שנשלחו.
הרציונל הוא שהמידע נשמר בbuffer עד שמתקבל בחזרה ACK ואז אפשר לשחרר את הזכרון ולהשתמש בו למשהו אחר.
לשם כך, משתמשים בheaders שהסברנו עליהם למעלה. seq num, ack num.

נתבונן על דוגמה מפורטת יותר מההסבר הנ״ל על echo tcp server ונסביר אותה
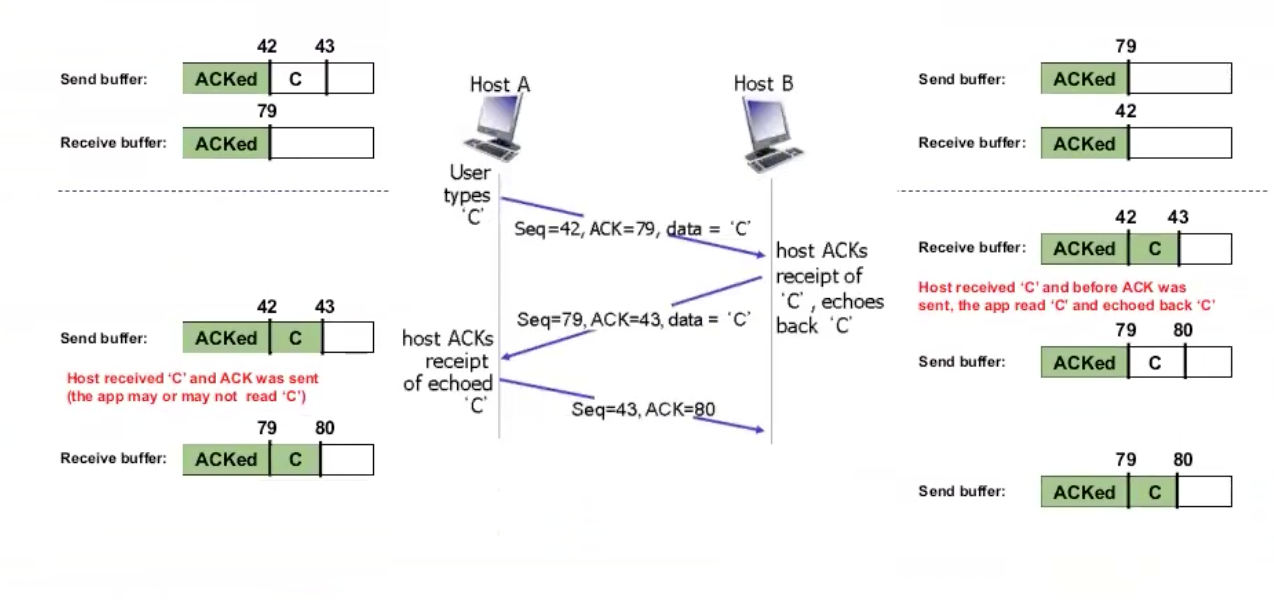
ראשית נשים לב שבפועל כל אפליקצייה שמתקשרת באמצעות TCP מחזירה Send buffer ו Receive buffer. הראשון הוא המידע שנשלח ואיזה מידע קיבל כבר ACK. השני הוא עבור מידע שהתקבל ואיזה מהם דווח עליו ACK.
כאשר C הוא מדווח גם את המספרים seq=42 וגם ack=79. הוא בעצם אומר ל
ברגע ש
ניתן בעצם להבין את הסנכרון שיש פה בין ACK לבין seq , הם בעצם נועדו לתת דיווח מהצורה
״מהו המזהה הבא של הבית הראשון שאני אמור לקבל ממך״ .
נשים לב שבסוף נשלח רק מידע של שכבת התעבורה בלי data כי אין עוד data לשלוח.
Packet timeout
כפי שאמרנו יכול להיות מצב שחבילה הלכה לאיבוד. כדי לזהות מצב כזה יש צורך במנגנון מבוסס timer כדי לקבוע שאם פקטה לא הגיעה בזמן הזה יש לשלוח אותה שוב.
לשם כך tcp רוצה לקבוע זמן שגבוה מ RTT(Round Trip Time) אבל זה זמן שמשתנה מפקטה לפקטה.
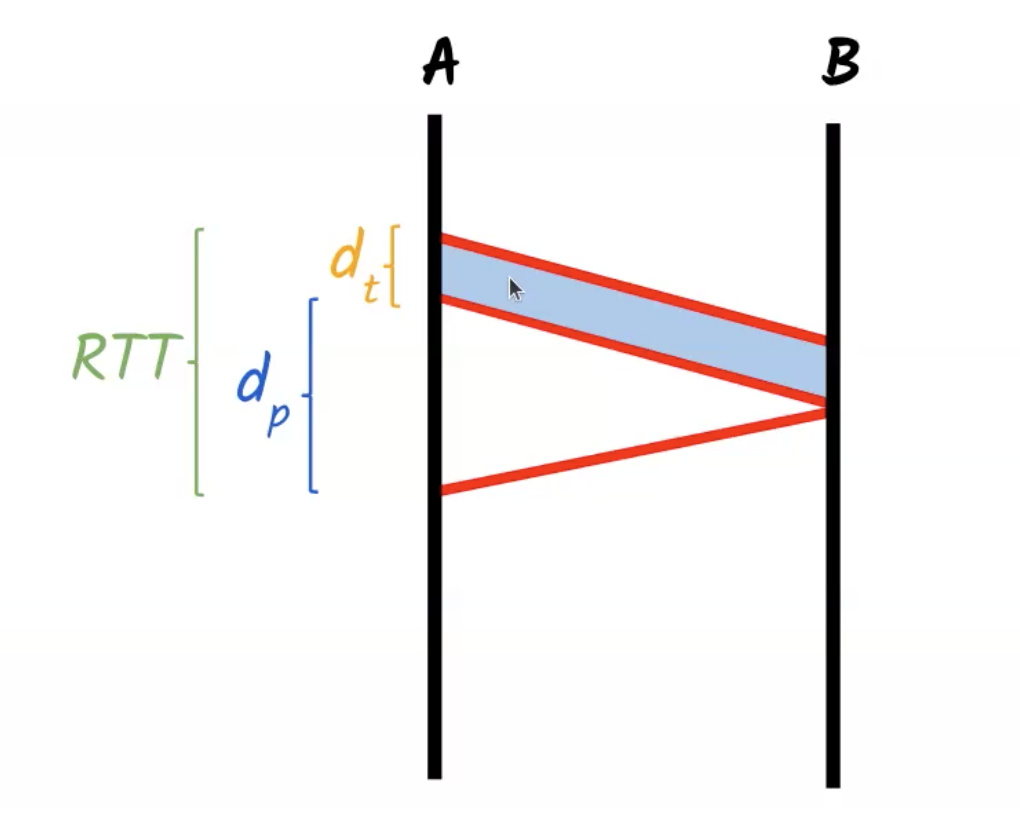
נסתכל על
א. השהיית שידור, כלומר הזמן שלוקח לשדר את הביט הראשון עד הביט האחרון בשליחת segment. יש אותו גם ב
זה מסומן כ
ב. השהיית התפשטות, כמה זמן לכל לביט בודד להתפשט על גבי הערוץ, לעבור את המרחק ממחשב א׳ למחשב ב׳. אפשר להסתכל על ביט בודד בגלל שההתפשטות נעשת בצורה מקבילית. נשים לב שהערך של השהיית ההתפשטות הוא שקול לזמן שבו לקח לביט האחרון להגיע ליעד.
זה מסומן כ
ג. השהיית השידור של הACK (בשרטוט זה בנקודה קטנה בגלל שזה זמן יחסית קטן ביחד לביטי המידע)
ד. השהיית ההתפשטות של הביט האחרון של ה ACK
סה״כ:
כאשר מתקיים ברוב המקרים ש
Store and forward:
ההסבר הנ״ל התעסק בשני מכשירים באותה הרשת. כאשר הם ברשת אחרת המצב שונה כיוון שהמידע צריך לעבור דרך הראוטר. זאת שיטה אחת שבה עובדים רכיבי תקשורות והיא פשוטה.
עד שלא מגיע הביט האחרון של החבילה, הוא לא מעביר אותה הלאה , כלומר נוצר פה רובד נוסף שמוסיף ל RDT , אם כי הנוסחה לא משתנה. באופן די אינטואיטיבי המשמעות היא שככל שיש יותר רכיבי תקשורת בדרך ליעד ככה יעלה זמן הRTT.
במילים אחרות ככל שמוסיפים לנו ראוטרים מטווחים ככה הנוסחה לחישוב RTT גדלה. אבל הרעיון הוא אותו רעיון בגלל שבstore and forward מחכים תמיד לביט האחרון של חבילה כדי לשלוח אותה הלאה.
שערוך RTT
יש צורך לבצע שערוך של הRTT כדי לדעת לאמוד את זמן ה timeout. שכן על כל פקטה צריך לבצע שערוך ל RTT הנ״ל לפני שהמידע על הRTT התקבל בפועל. נסמן
נגדיר :
בעצם מדובר פה במעין ממוצע משוקלל, שככל ש
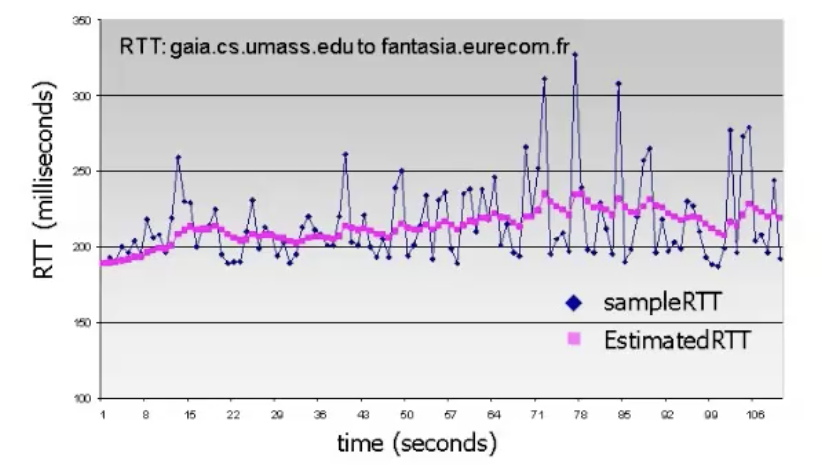 ֿ
ֿ
ההשפעה של SampleRTT יורדת מדגימה לדגימה, כלומר הנוסחה הזאת לאט לאט משפרת באופן אקספוננציאלי את ה EstimatedRTT. הרשת היא תנודתית מאוד ולכן ה smoothing הזה הוא מאוד חשוב. בגרף ניתן לראות שאין תנודתיות כזאת ב EstimatedRTT וזה טוב לנו כי זה אומר שאנחנו שומרים על הממוצע המשוקלל בערך מדגימה לדגימה.
בגלל שהסטיות האלה גדולות מאוד נרצה לצמצם את ההפרשים האלה באמצעות חישוב הסטייה/שונות של הממוצע שלנו. הנוסחה תייצג את הסטייה בין המדידה להערכה בכל פעם.
ההפרש מייצג את ההפרש הנוכחי והסטייה בנוסחה היא הסטייה הקודמת שנמדדה. ככל שהרשת יציבה יותר ככה הסטייה נמוכה יותר ואם הרשת אינה יציבה אז נשתמש בסטייה כדי לתקן את הtimeout כפי שתיכף נראה. בד״כ
סך הכל נגדיר ש
Stop and Wait Efficiency
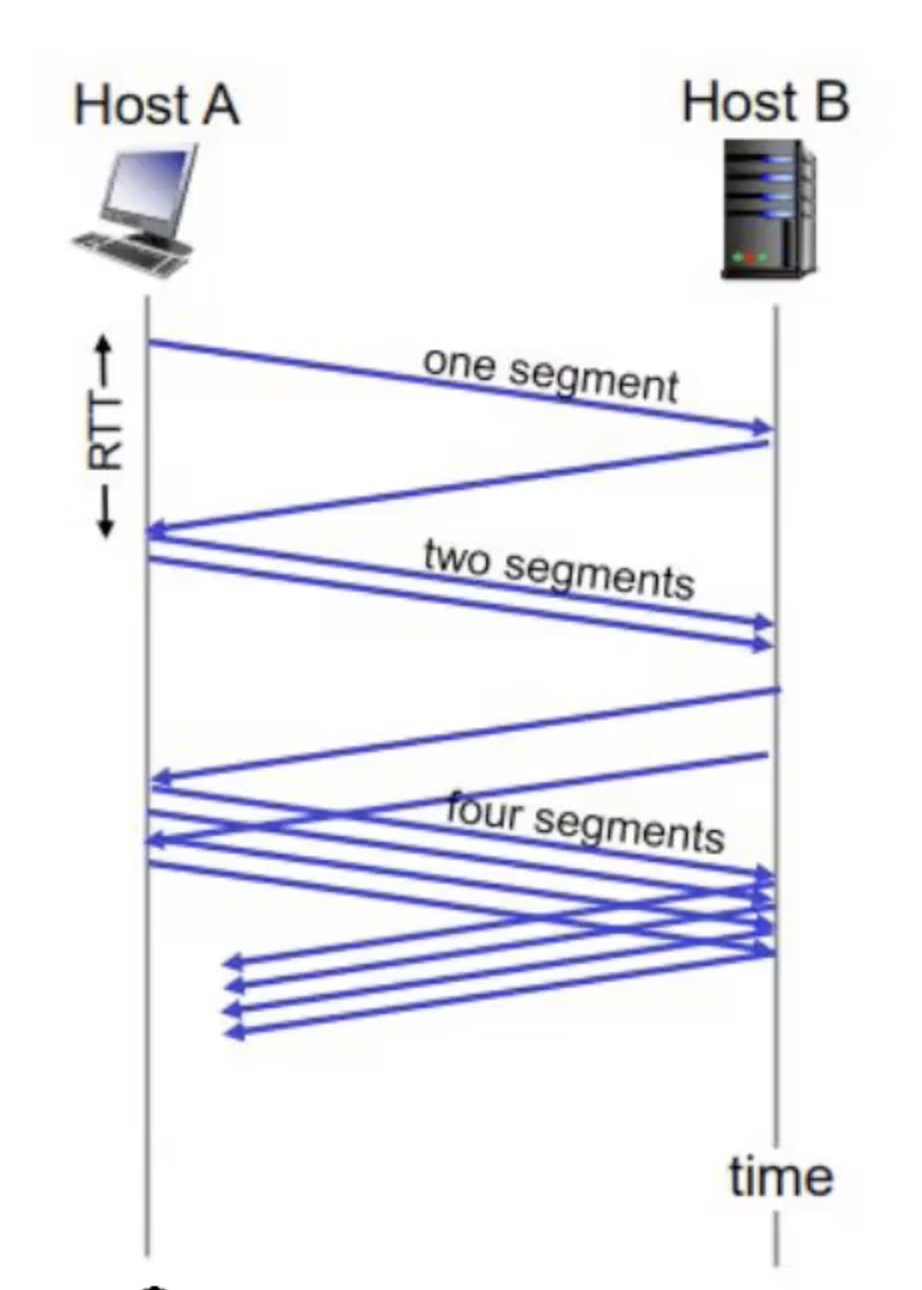
בשיטת Stop and Wait יש מצב של חוסר יעילות בגלל under utilization, אין שום סיבה שנחכה לקבל ack על חבילה כדי לשלוח את הבאה בתור. נרצה שכל צד בתקשורת יחזיר באפר מידע שקובע כמה הוא קיבל וכמה הוא שלח ובאמצעות השיטה הזאת נוכל להשתמש במנגנון pipeline, שמאפשר לנו לשלוח מספר חבילות במקביל.
Pipeline
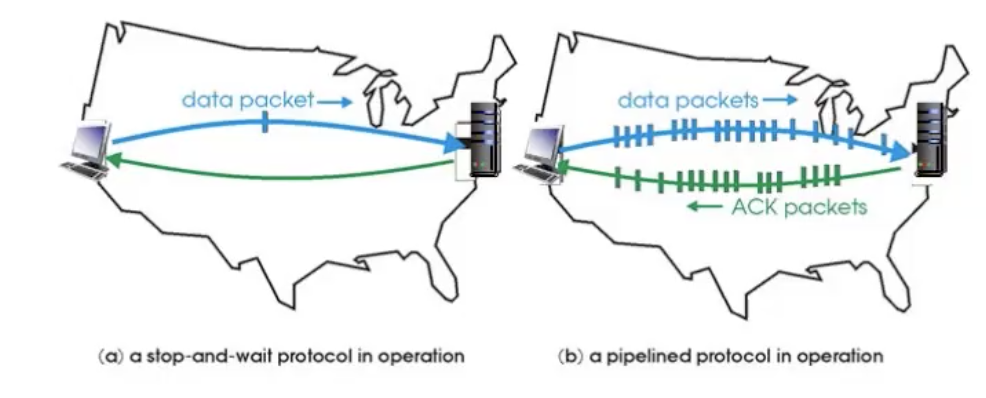
לאחר שהחבילה הראשונה הגיעה אל הראוטר, חבילות אחרות נשלחות בשני הערוצים במקביל.
המשמעות היא שלא צריך לספור את הזמן ההתפשטות והשידור בין השרת לראוטר ובין הראוטר לשרת בנפרד שכן , אלו מתרחשים במקביל בשיטת pipeline.
הרעיון בpipeline הוא לחלק את החבילה הגדולה לחבילות קטנו יותר ובכך לאפשר ״concurrency״ בזמן השידור. כעת לא צריך לשדר את כל החבילה הגדולה מהמחשב אלא אפשר לשדר חלק ממנה ובזמן שהיא מתפשטת לכיוון היעד לשדר חלק אחר.
המימוש:
נגדיר sliding window להיות מספר החבילות שאפשר לשלוח לפני שמקבלים ACK על אחת מהן. במילים אחרות, כמה חבילות ניתן לשלוח ״במכה״ אחת.
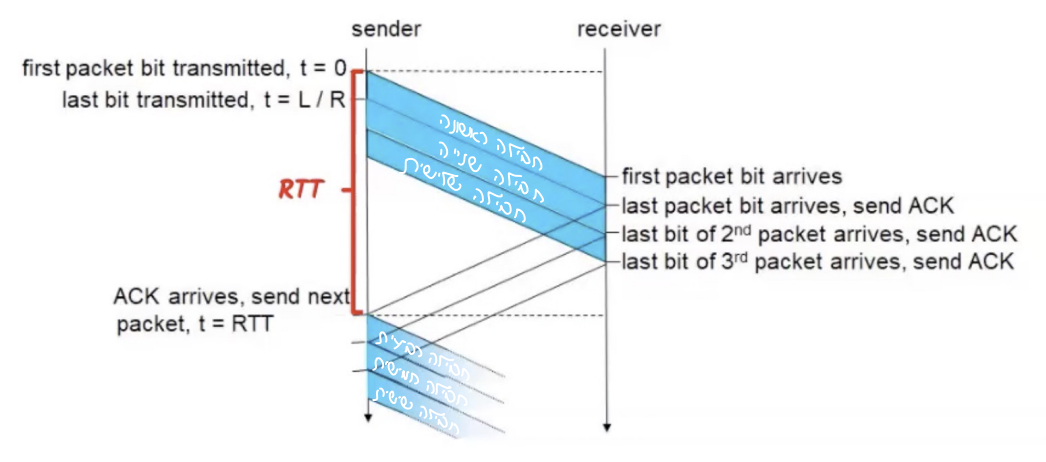
בתמונה ניתן לראות receiver שגודל החלון שלו הוא 3 ולכן ה sender שולח רק 3 חבילות במכה אחת. ברגע שהחבילה הראשונה בשלישייה שלחה ack הsender יכול לשלוח את החבילה הבאה בתור (הרביעית).
הפתרון הזה מייצר לנו בעיה חדשה, כעת אם חבילה נופלת ולא מגיעה, יש צורך גם לעדכן איזה חבילה נפלה בדרך (בניגוד ל stop and wait שתמיד ידענו איזה חבילה הלכה לאיבוד בגלל שתמיד יש אחת בתנועה ויש עליה timeout).
ננסה לפתור את הבעיה אך ראשית נבין קצת יותר טוב את מנגנון ה Slide Window:
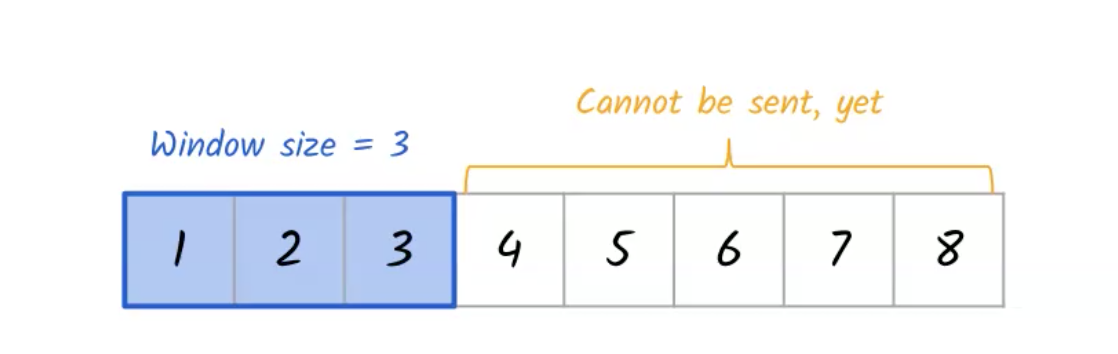
נניח ונרצה לשלוח 8 segments של מידע והחלון הוא בגודל 3.
על כל פקטה בבאפר (בין אם זה ה send buffer ובין אם זה ה receive buffer) נשמור את אחד מהstates הבאים
א. האם היא ACKed
ב. האם היא נשלחה ועדיין לא קיבלה ACK.
ג. האם היא ניתנת לשליחה
ד. לא ניתנת לשליחה כרגע.
הפרמטרים הללו נקבעים לפי ה window size והבאפרים עליהם דיברנו מקודם.
כאשר מתקבל ack על החבילה הראשונה הsliding window יזוז ימינה.
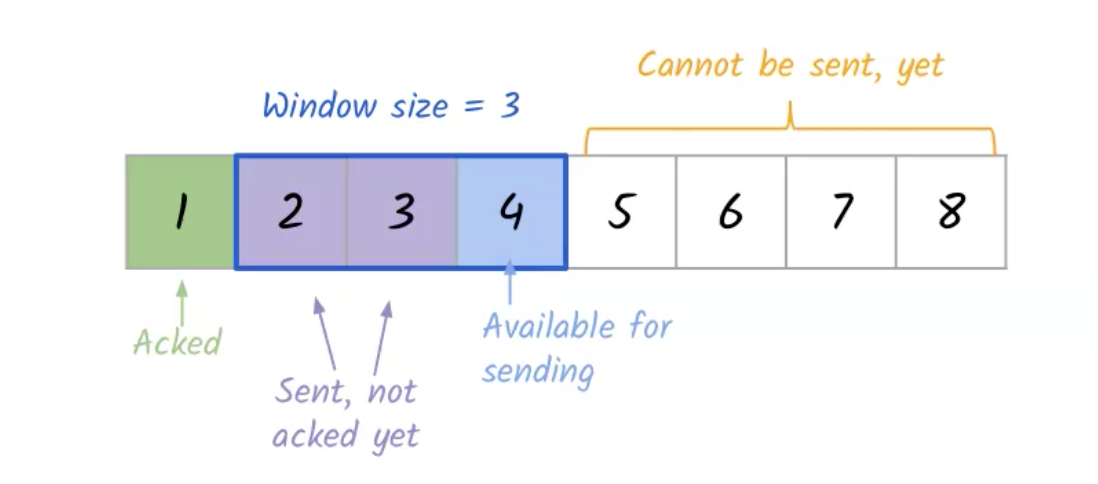
נשים לב שאם מקבל ack על חבילה 3 אבל על חבילה 2 טרם הגיע ack עדיין לא נוכל להזיז את החלון.
GBN
אחת השיטות לטיפול בבעיה, היא שיטת Go Back N. לפי השיטה:
- לשולח יכול להיות עד n חבילות שלא קיבלנו עליהן ack.
- מקבל שולח ack מצטבר בלבד. כלומר לא עושה ack לחבילה כאשר יש חור בחלון.
- לשולח יש טיימר עבור החבילה הישנה ביותר שלא עשו עליה ack. אם וכאשר הטיימר מסתיים, הוא שולח מחדש את כל החבילות שלא עשו להן ack עדיין.
נסתכל על הדוגמה הבאה:
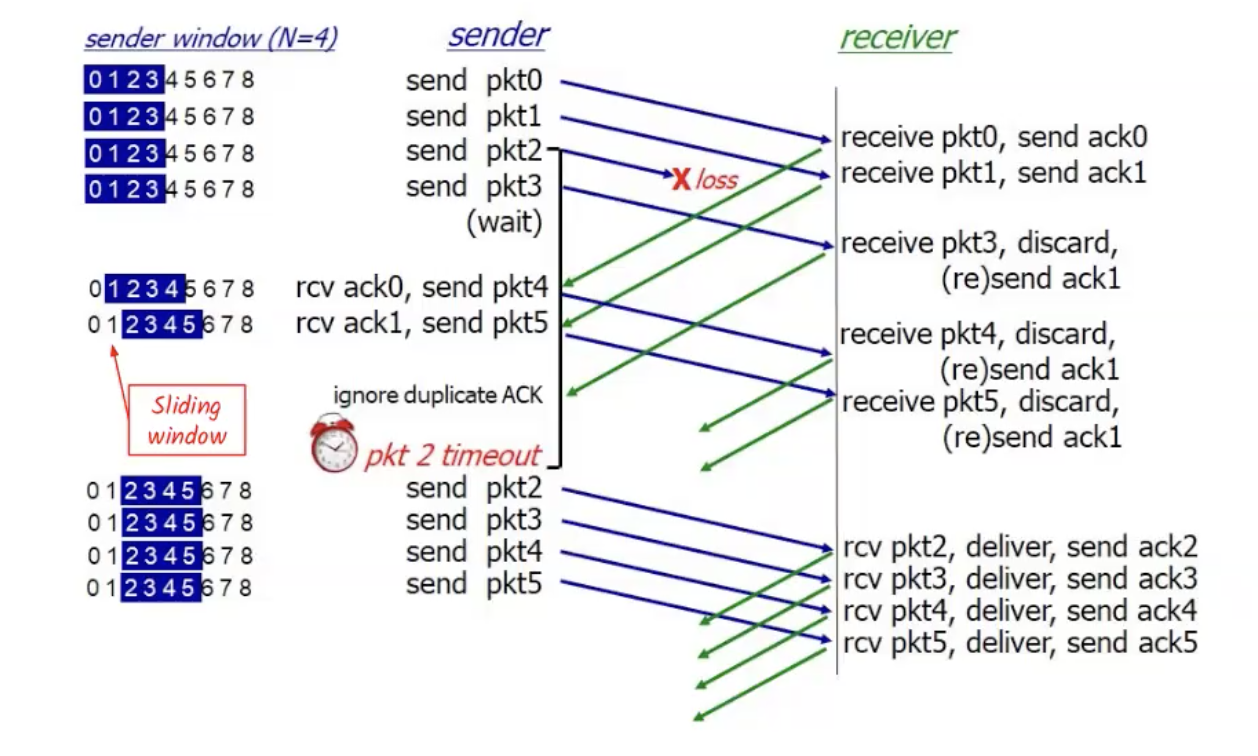
- החלון בגודל N=4
- חבילה 0 מגיעה כמו שצריך ומתקבל עליה ack. באופן דומה גם חבילה 1. מה שגורם לsliding windows לזוז ולשלוח את חבילות 4 ו 5.
- חבילה 2 הלכה לאיבוד. כל חבילה שיתקבל עליה ack כך שהמספר הסידורי שלה גדול מ2 תזרק עד שיתקבל timeout על 2.
- ברגע שהתקבל timeout על 2 כל החבילות מ2 עד end of window נשלחות מחדש.
- נשים לב שלאורך הדרך הsliding window לא זז בגלל שהיה את ה״חור״. את החור ניתן לזהות באמצעות ה sequence number.
החסרון בשיטה הזאת הוא שיכול להיות מצב שחבילה לא הלכה לאיבוד אלא פשוט הגיעה מוקדם יותר מחבילה עם מספר סידורי נמוך יותר.
Selective Repeat
שיטה נוספת לטיפול בבעיה שתיארנו.
כאשר הפקטה ה
ברגע שהפקטה ה
נסתכל על דוגמה עם חלון בגודל 4.
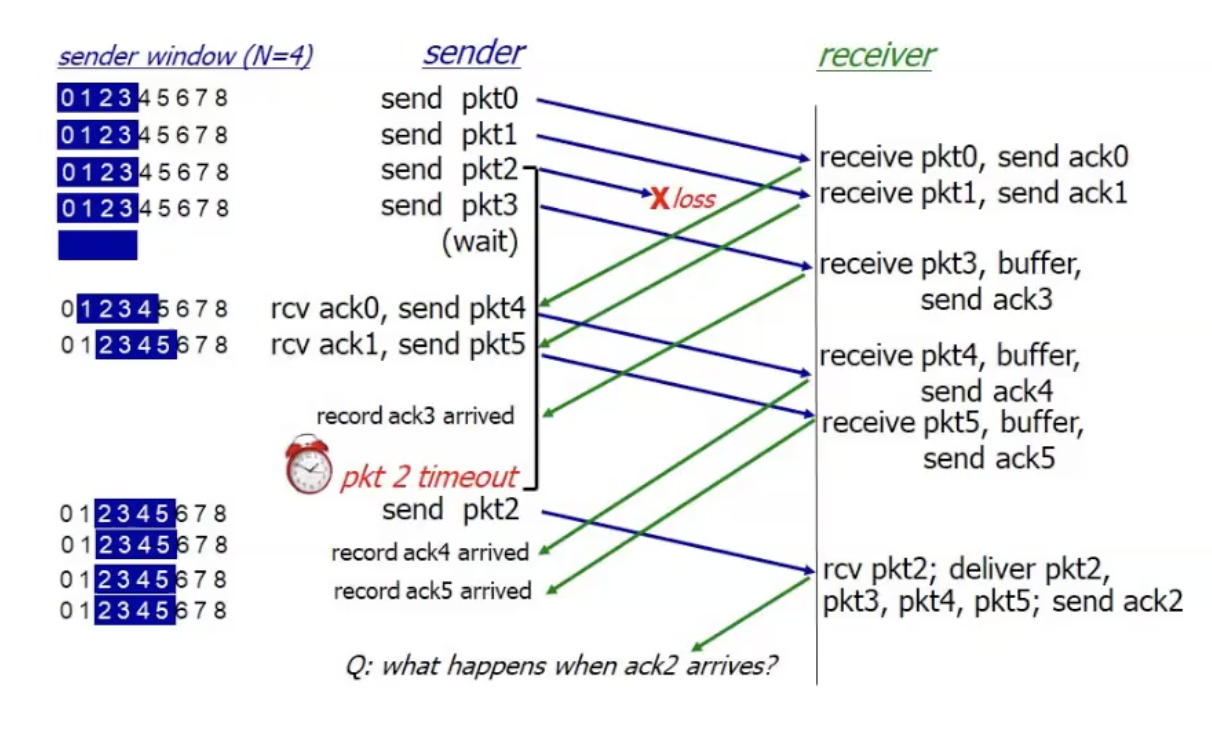
- הack של חבילות 0,1 חוזרות ולכן שולחים את חיבלות 4,5.
- חבילה 2 הלכה לאיבוד ולכן כשחבילה 3 תקבל ack לא נזניח אותה כמו מקודם אלא נשמור את ack3 במערך.
- נשים לב שכאשר חבילה 3 מגיעה לא ממשיכים לשלוח חבילות כי חבילה 2 תוקעת אותנו.
- כאשר timeout על חבילה 2 יתקבל, נשלח רק אותה שוב ונמשיך לצבור את הack על החבילות 4 ו 5.
- מה יקרה כשחבילה 2 תקבל ack? נוכל להזיז את הwindow כגודל המערך שצברנו כלומר, עבור 2,3,4,5 סך הכל נזיז את החלון 4 איברים, תחילת החלון תהיה החבילה ה6.

חשוב לשמור על יחס של קטן ממש בין ה window size ל seq numbers שכן, כיוון שה seq הוא מספר סופי וחסום בגודל של 32 בתים, אם הdata שאנחנו נרצה לשלוח גדול מזה, יהיה wrap around של ה seq number. למשל, אם
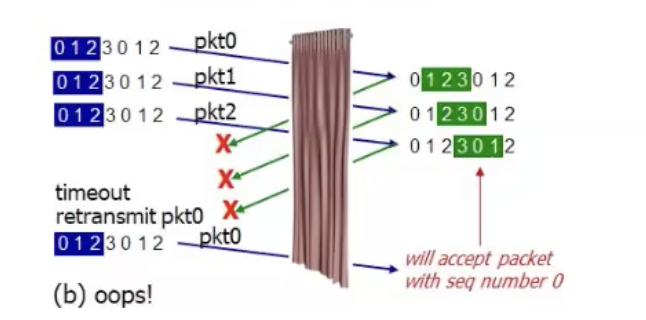
סיכום עד כאן:
- TCP הוא פרוטוקול point to point. כלומר, בניגוד ל UDP ששם המקבל יכול לקבל חבילות מהמון שולחים על אותו socket ולהגיב לכל חבילה בנפרד, ב TCP יש לנו על סוקט בודד גם שולח אחד וגם מקבל אחד.
- TCP נותן תקשורת אמינה ולפי הסדר, המידע נשלח כ stream ולא הודעות. כל דחיפה של מידע נשמרת בבאפר והסוקט מסתכל על הבאפר ובוחר כיצד לחלק את החבילות (segmentation).
- TCP משתמש ב pipeline כדי לשפר את היעילות אבל גם משתמש במנגנון בקרת עומסים שתיכף נדבר עליו כדי לוודא שלא שולחים יותר מדי או בקצב גבוה מדי למצב שהרשת או היעד לא יכולים לעמוד בעומס.
- תקשורת ב TCP הוא full duplex כלומר דו כיוונית.
- התקשורת היא מוכוונת חיבור כלומר יש צורך ב handshake.
TCP Headers
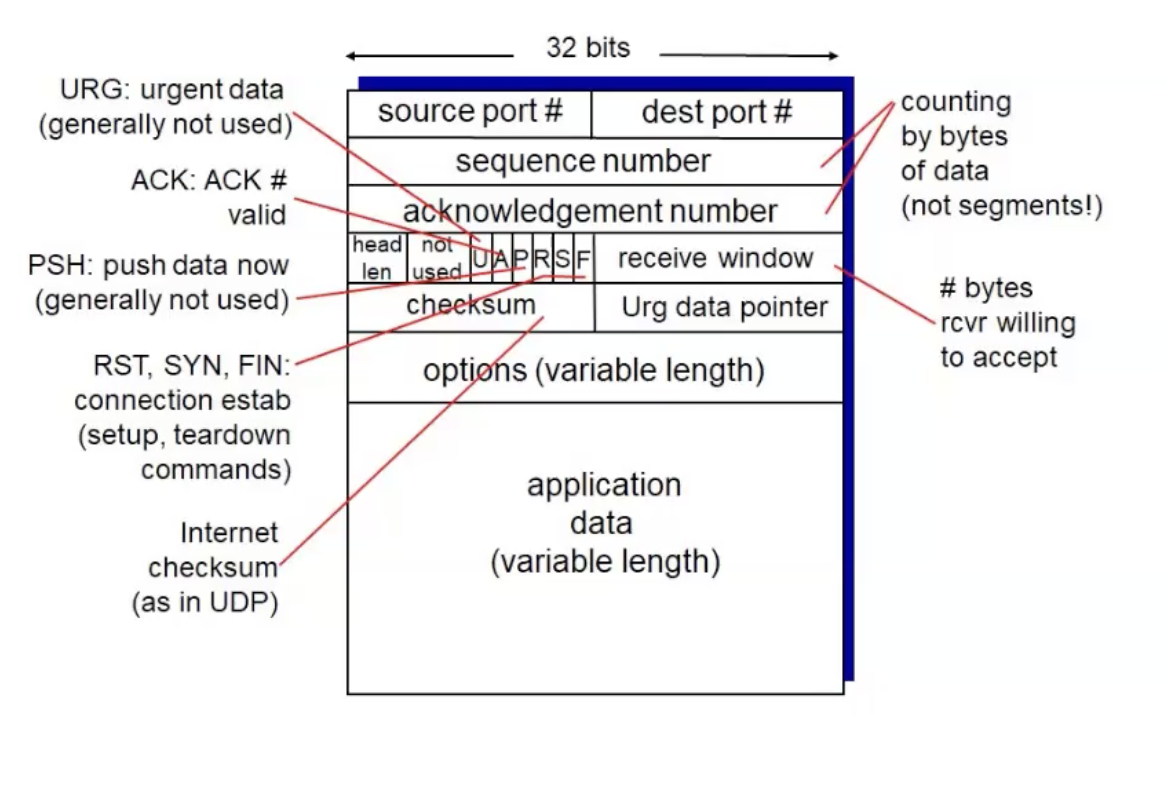
- U,A,P,R,S,F - דגלים בגודל ביט אחד
- U- מלשון urgent data.
- A - מלשון ACK, דגל שקובע האם יש להתייחס למספר ה ack.
- P- מלשון Push דגל שמאפשר למידע להקלט בלי לחכות בבאפר.
- R - מלשון reset. מודיע שצריך לעצור את החיבור ולהתחילו מחדש.
- S- מלשון synchronized. נפרט עליו בהמשך.
- F- מלשון FIN , נשלח כאשר מעוניינים לסגור את החיבור.
recieve window- כפי שניתן לראות הוא חלק מהתחיליות. נפרט בהמשך למה.
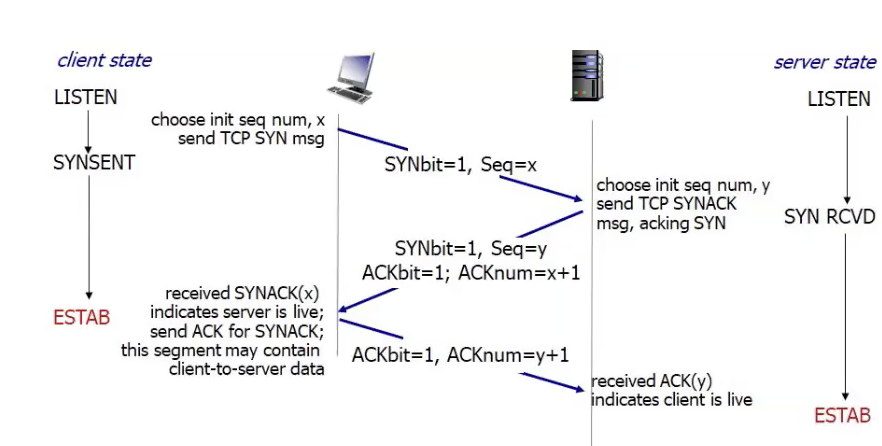
TCP 3-way Handshake
אמרנו שבפרוטוקולים מבוססי קישור, יש צורך להקים את הקישור בין הצדדים לפני שלב העברת המידע בינהם. באמצעות הקמת הקישור, אנו מודיעים לצד השני שאנו מתחילים מולו בתקשורת ושעליו להיות מוכן לכך. בנוסף, לעיתים יש לתאם פרמטרים בין שני הצדדים בכדי שהקישור יעבוד בצורה יעילה יותר.
באופן כללי, הקמת קישור ב TCP נקראת Three Way Handshake ונראת כך :

כפי שניתן לראות, במהלך הרמת הקישור נשלחות שלוש חבילות, בכל אחת מהן גם יש שימוש ב ack ו seq.
SYN
בשלב הראשון, הלקוח שולח לשרת חבילה שמטרתה להתחיל את הקמת הקישור. על ידי הדלקת הheader : SYN הלקוח מעיד על כוונתו לפתוח קישור. ה seq המצורף נקרא ISN- initial sequence number והוא נבחר באופן רנדומלי כדי למנוע התנגשויות של חיבורים, אם כל החיבורים היו מתחילים אם מזהה
כמו כן נשים לב ש ACK כבוי כי לא ניתן ACK על אף חבילה קודמת (זאת הראשונה).
SYN+ACK
בשלב זה, אם השרת הסכים לקישור הראשוני הוא עונה בחבילה בה דלוקים שני הדגלים : SYN ו ACK. הדגל SYN דלוק כי זאת חבילה שמובילה על הקמת הקישור. הדגל ACK דלוק מכיוון שהשרת מודיע ללקוח שהוא קיבל את החבילה הקודמת שהוא שלח, שהיא חבילת ה SYN.
הseq של החבילה של השרת יהיה ISN של התקשורת בינו לבין הלקוח וגם הוא ייבחר באופן אקראי. זאת כמובן שתקשורת היא דו כיוונית ונעשת בשני Streams של מידע , רצף בתים ללקוח ורצף בתים לשרת.
לסיום על השרת לציין את מספר ה ACK כדי להודיע ללקוח שהוא קיבל את החבילה שלו, כפי שהוא עושה גם במצב רגיל. כלומר הערך של ה ACK יהיה לפי הבית הבא שהשרת מצפה לקבל מהלקוח שבמקרה הזה הוא

ACK
על מנת שהחיבור יוקם בהצלחה הלקוח צריך לדווח לשרת שהחבילה SYN+ACK התקבלה בהצלחה וששני הצדדים מסונכרנים על המספרים הסידוריים הראשוניים אחד של השני.
כדי לבצע זאת, הלקוח שולח חבילה כשדגל ה ACK דולק, ומספר ה ACK מציין את הבית הבא שהוא מצפה לקבל מהשרת. כלומר המספר הסידורי + 1 (בידיוק כמו מקודם). הפעם הדגל SYN כבוי, שכן זו כבר לא החבילה הראשונה שנשלחת מהלקוח לשרת בקישור הנוכחי. כמו כן הseq של החבילה הנשלחת יהיה הערך שהיה ב ack בחבילה שהתקבלה מהשרת..

סך הכל אם נתאר את כל התהליך מהתחלה עד לסיום זה יראה כמו בדיאגרמה הבאה:
TCP Connection Termination
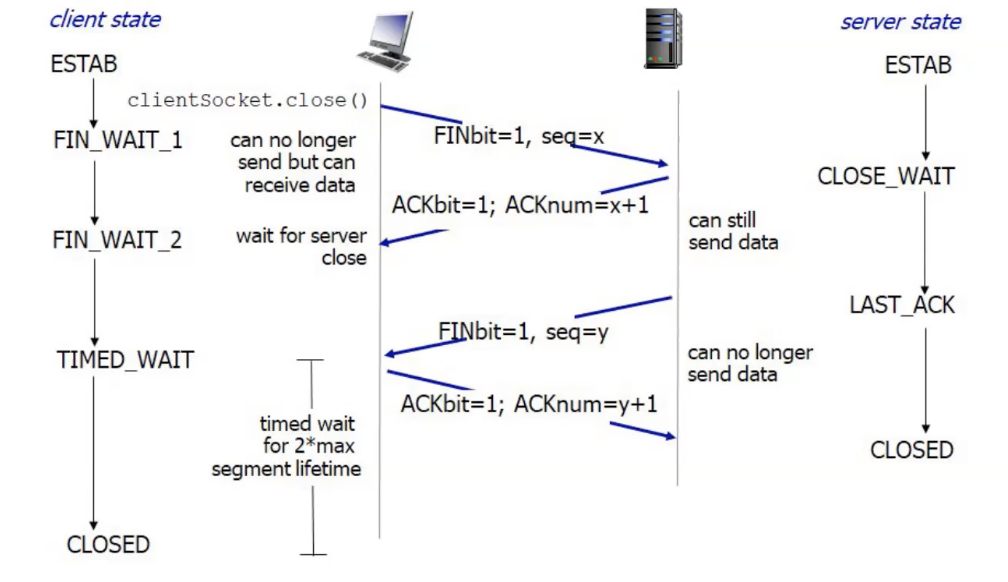
כאשר נרצה לסגור את החיבור באמצעות socket.close הדגל
הצד שמאשר את הסגירה של החיבור שולח כמובן
צד זה עדיין יכול להמשיך לשלוח מידע וברגע שהוא יסיים הוא ישלח בעצמו את הדגל
במידה ושני הצדדים מוכנים לסגור את התקשורת ניתן לסגור את החיבור בשלושה שלבים:
הלקוח שולח FIN , השרת מחזיר FIN+ACK והלקוח מחזיר ACK על ה FIN.
TCP Retransmission
ישנם כל מיני מקרי קצה ש TCP צריך להתמודד איתם כדי שיתאפשר לשלוח את המידע לפי הסדר. כך למשל יכול להיות מצב שהמידע ממחשב א׳ יגיע למחשב ב׳ אבל ה ACK עבור המידע זה יפול בדרך ונקבל Timeout. במצב זה אנחנו יודעים שמחשב א׳ שולח שוב את המידע בציפייה לקבל את הACK למרות שמחשב ב׳ כבר קיבל אותו ודיווח (כאן נכנס לתמונה ה SEQ שמאפשר לצד המקבל לדעת שהוא לא קיבל מידע חדש).
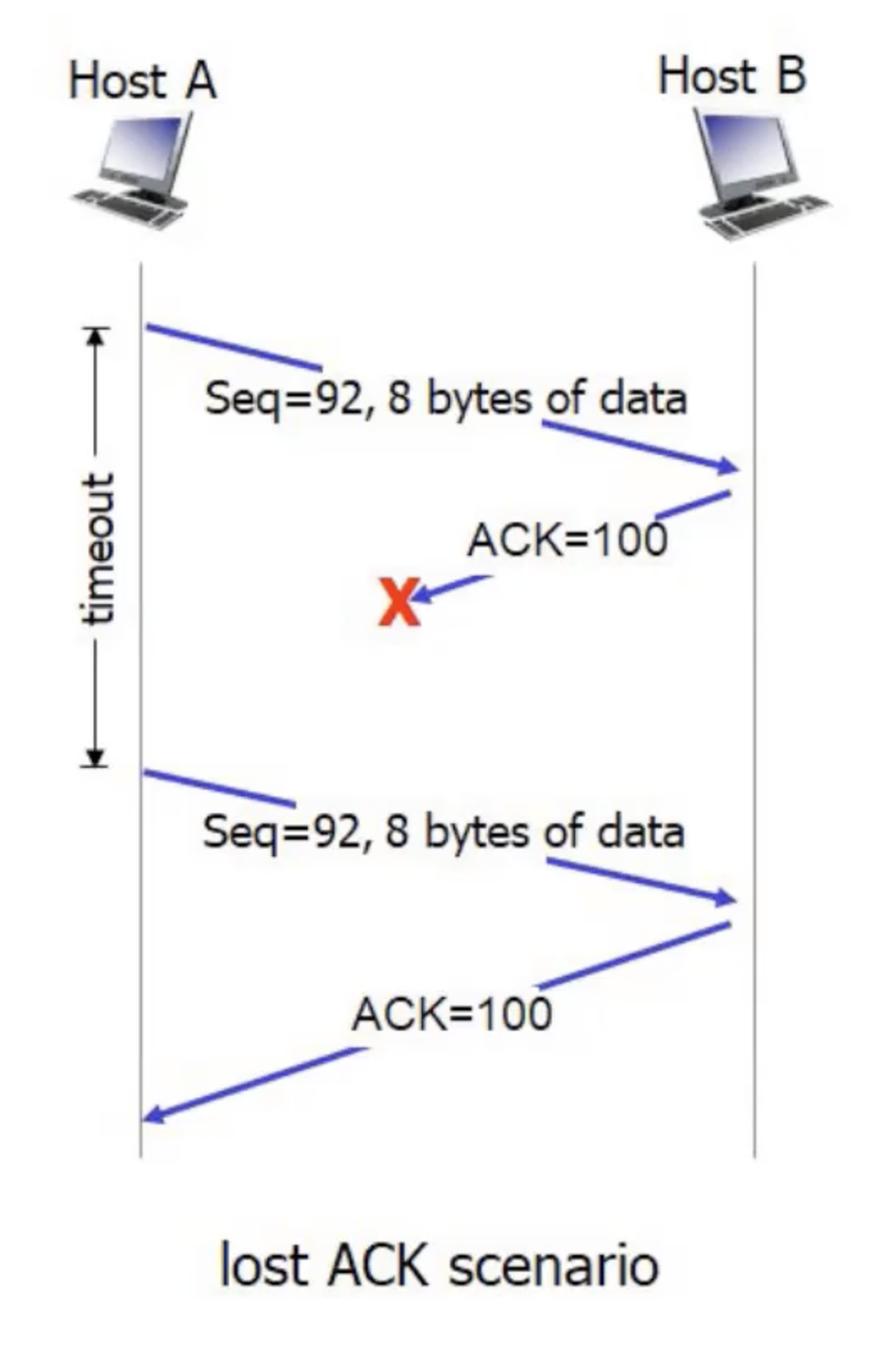
נשים לב שאם נפל ה ACK ולפני שהתקבל TIMEOUT על החבילה כבר נשלח ACK על החבילה הבאה (כי עובדים בשיטת Pipeline) אז בגלל שה ACK הוא מצטבר המחשב השולח ידע שהוא לא צריך לשלוח את החבילה שוב ויכול לשלוח את החבילה הבאה.
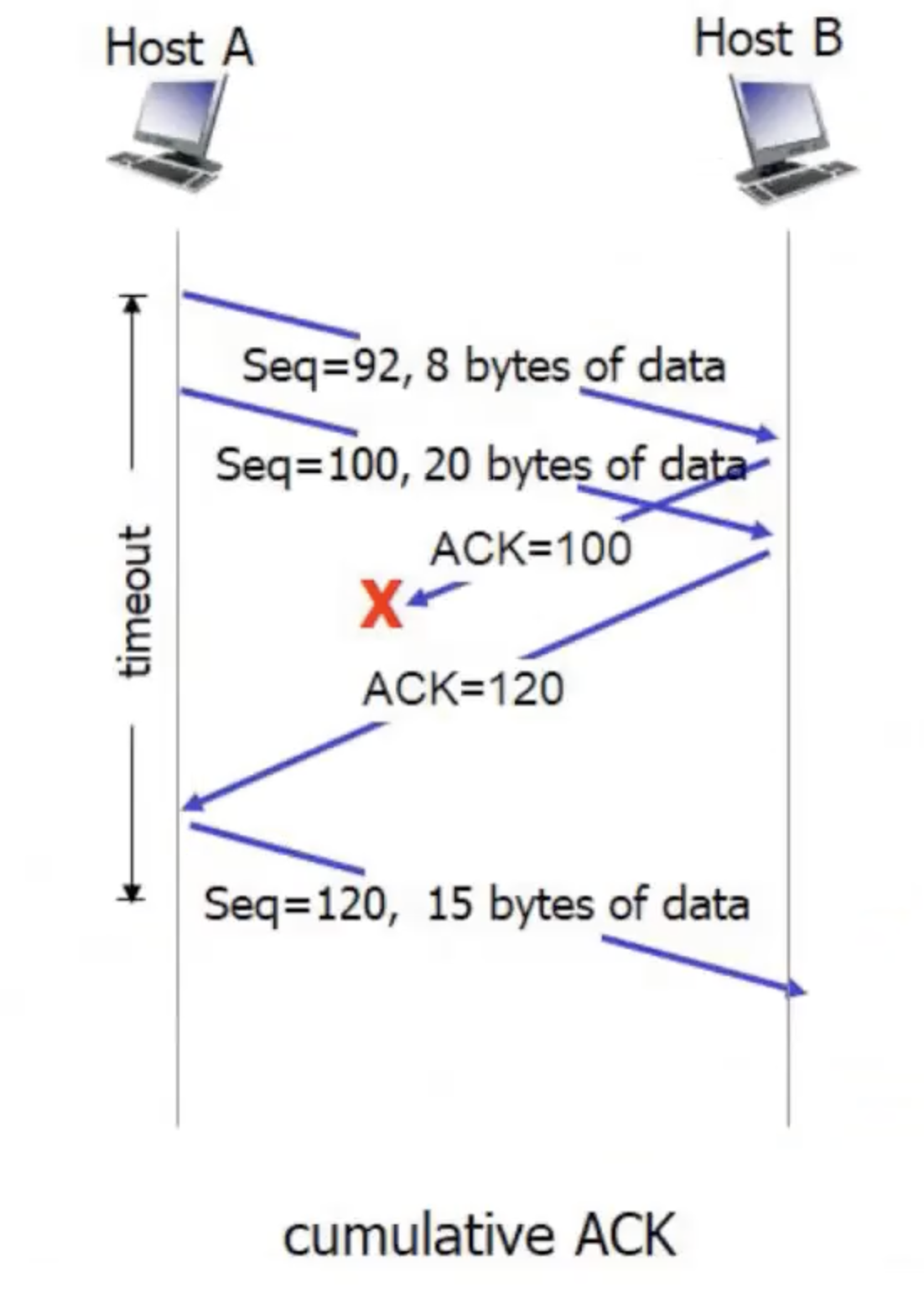
תרחיש נוסף שיכול לקרות הוא שהשערוך Timeout היה נמוך מדי ולכן יתקבל timeout על חבילה לפני שהACK עליה נשלח. במצב זה שוב פעם נשלח את החבילה פעם נוספת, אבל , בגלל שACK כפי שאמרנו הוא ערך מצטבר ולא פר חבילה אנחנו פשוט נשלח את הACK עם הערך הרלוונטי שוב.

נשים לב שהצד השולח שומר את ה ACK שהוא קיבל עד לרגע הנוכחי במשתנה SendBase.
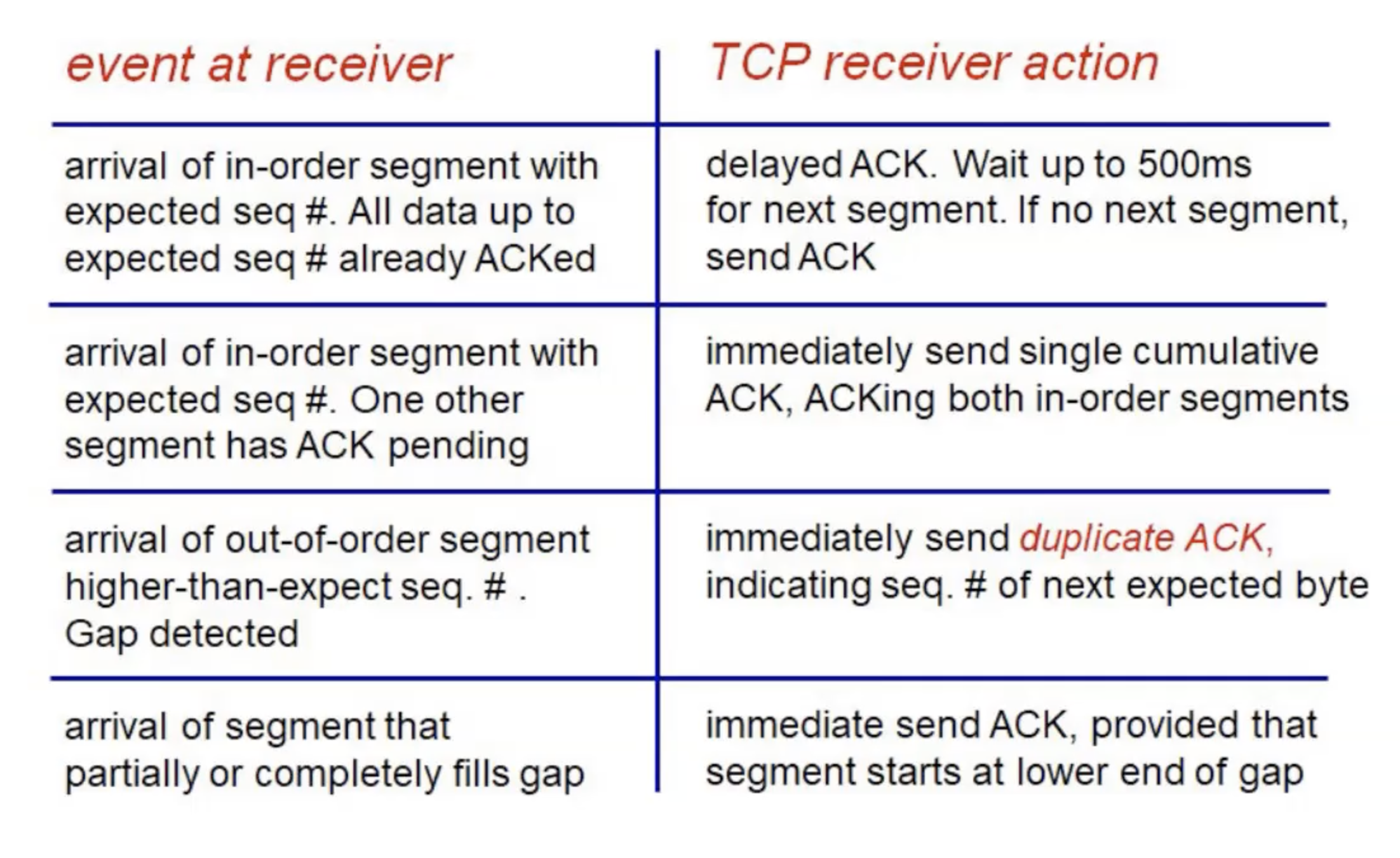
ACK Events
TCP שואף לשלוח כמה שיותר חבילות מידע ולצמצם את חבילות ה ACK . במצב זה TCP משתמש בכמה מנגנונים לפי המאורעות השונים שנמצאים בצד המקבל של המידע.
למשל:
א) אם המידע מגיע כמו שצריך לצד השולח TCP משתמש במנגנון של delay על ACK. כלומר הוא מחכה ורק אם במהלך הדיליי לא התקבל שום חבילה חדשה הוא שולח את אותו ACK.
ב) במידה והגיעה חבילה חדשה בזמן הזה הוא מגיע לאירוע 2 בטבלה למטה ושולח את ה ACK המצטבר עבור שניהם.
ג) אם יש מצב שבו מגיע מידע עם seq שלא תואם את המספר seq שהצד המקבל מצפה לו הוא ישלח ACK נוסף (לא מצטבר) עבור הפקטה הרלוונטית האחרונה שנשלחה לפי הסדר.
ד) המאורע האחרון שמצוין בטבלה הוא כאשר מגיעה חבילה שסוגרת איזשהו חור שנוצר בין הseq של החבילות השונות שהתקבלו. במצב זה שולחים ACK על המספר הכי נמוך שממנו יש חור ואם אין כזה שולחים ACK על מספר הבתים שהתקבלו עד כה.
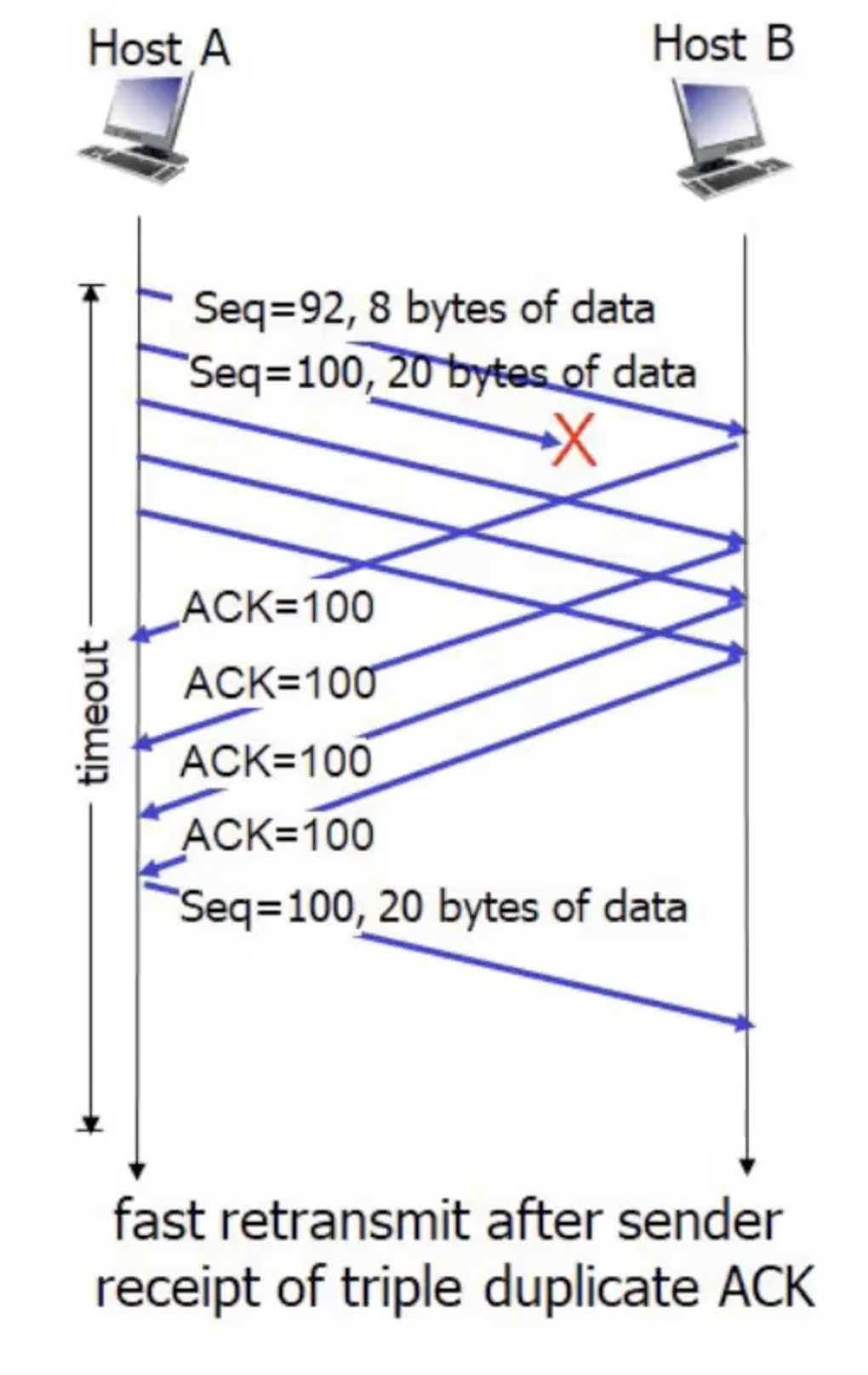
TCP Fast Retransmit
זה מנגנון שנועד להעריך שחבילה הלכה לאיבוד לפני שהתקבל עליה Timeout. המנגנון משתמש בטכניקת ה duplicate ACK שציינו מקודם. במצב שבו מגיעות יותר מ3 חבילות שהן out of order בגלל חבילה ספציפית אז TCP מיד ישלח אותה שוב ולא יחכה ל timeout. כפי שאמרנו אנחנו שולחים ack כפול ומצפים לקבל את החבילה אבל חבילות אחרות מתקבלות והיא עדיין לא מגיעה.
TCP Flow Control
עד כה התייחסנו ל window כגודל סטטי שלא יכול להשתנות.
החלונות השונים ש TCP מנהל, בפועל הם דינמיים וגודלם משתנה בהתאם לתקשורת.
החלון הראשון הוא חלון בקרת הזרימה:
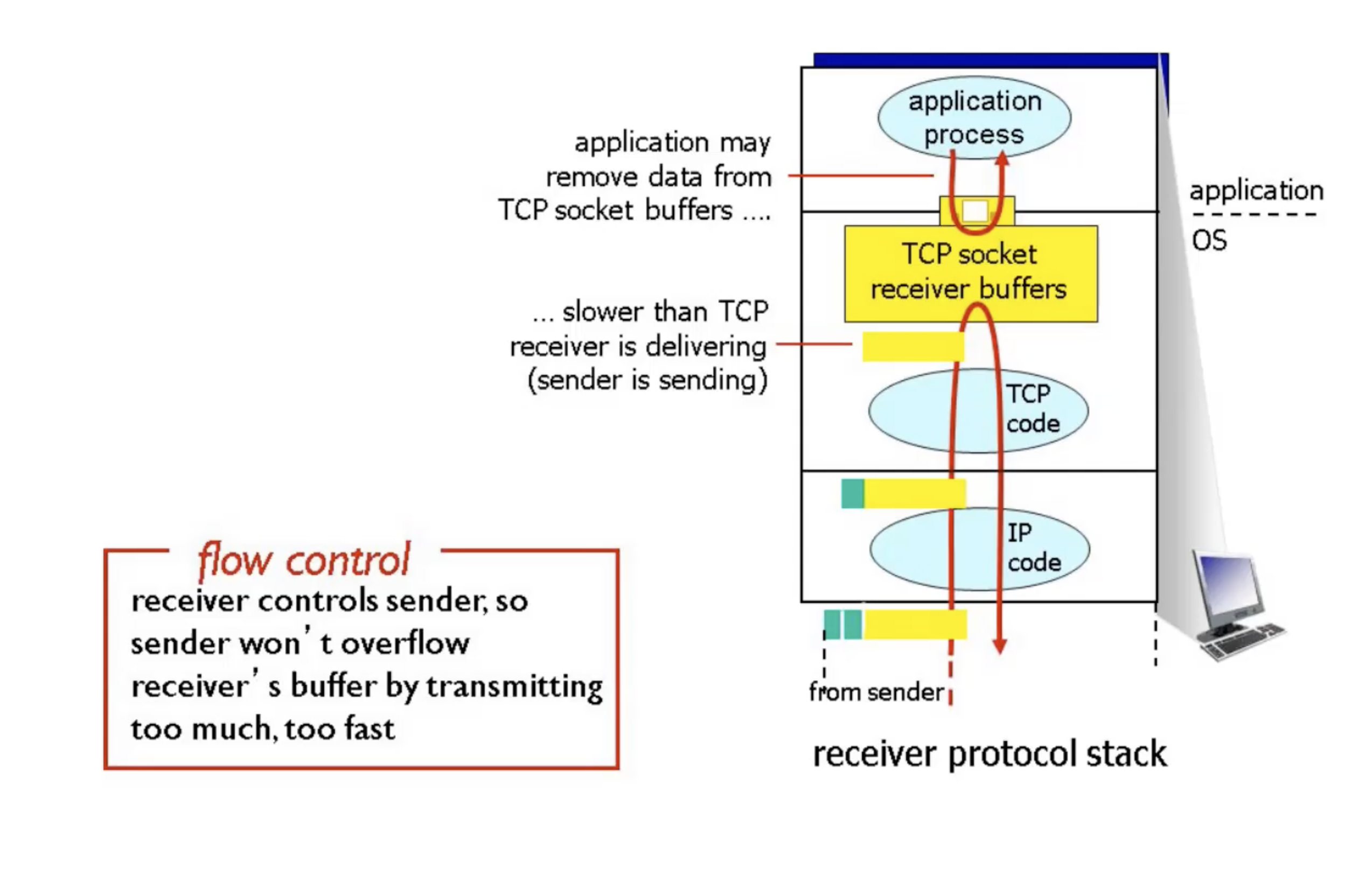
חלון זה שומר את ה data ב buffer ומחכה ששכבת האפליקצייה תשלוף אותו. כאשר אין מקום בבאפר הצד המקבל צריך לתאם את זה עם הצד השולח כדי שלא יגרום ל overflow ולנפילת חבילות בעקבות כך.
TCP עושה את זה באמצעות הheader שנקרא received window .
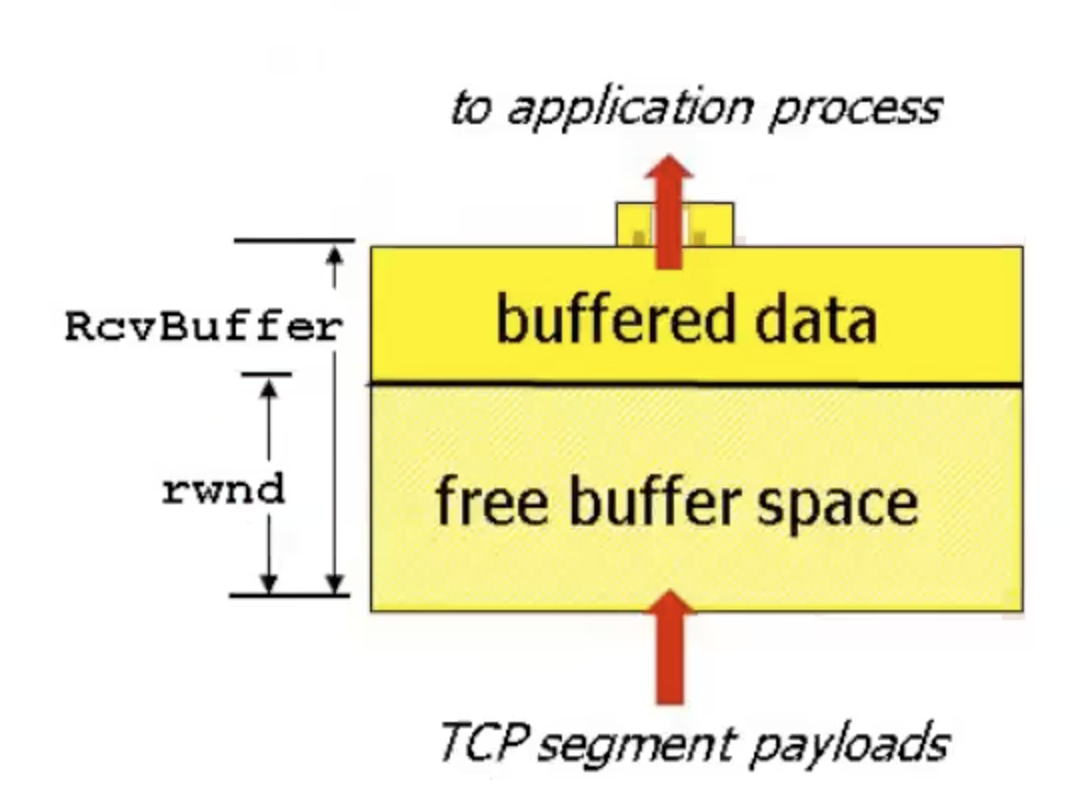
TCP ישלח את rwnd שזה הגודל הפנוי בבאפר לצד השולח וכך הוא ידע האם אפשר להמשיך להזרים עוד מידע או לא.
הניהול של זה ברמת TCP הוא יחסית פשוט.
כפי שאמרנו אם יש מידע בגודל מסויים TCP מחלק אותו לפקטות לפי ה MSS ומתחיל תהליך של three way handshake.
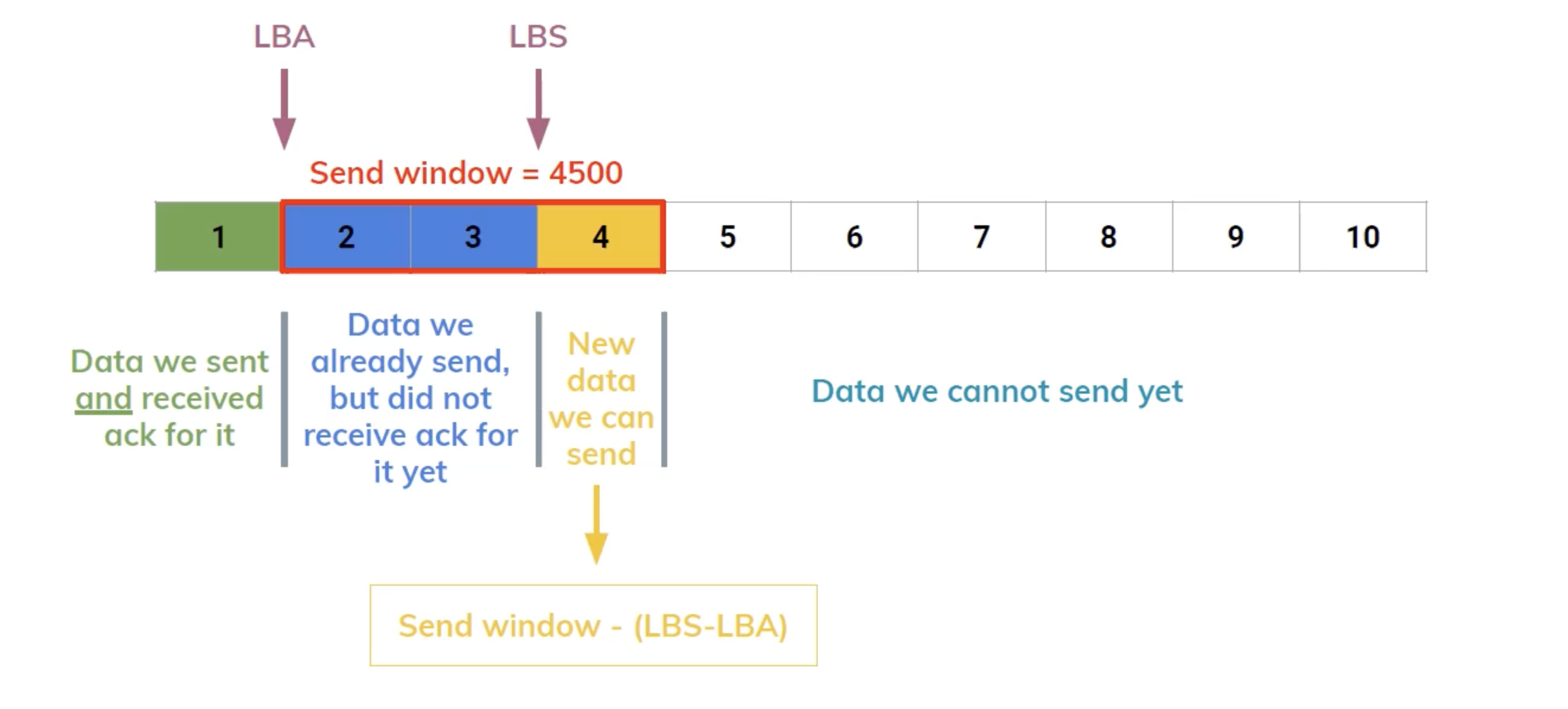
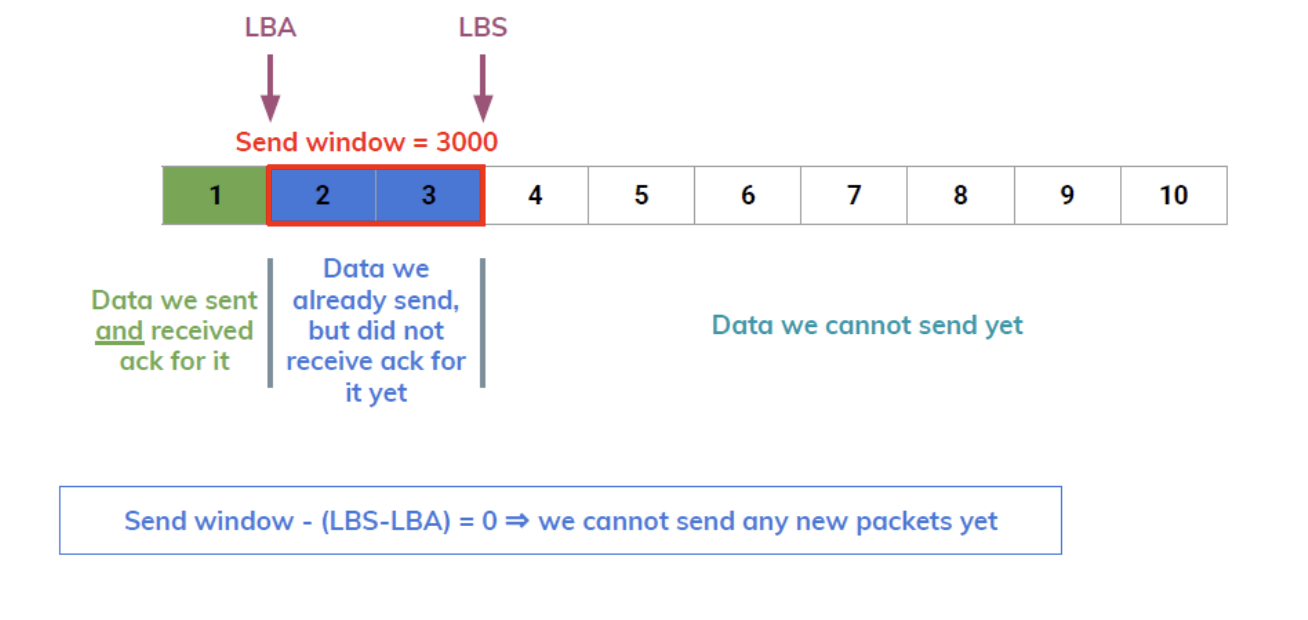
במהלך התהליך הזה הצד השולח יקבל את הגודל של הrwnd וישמור אותו בפרמטר שנקרא send window. נחזיק שני מצביעים LBA ו LBS שזה ה last byte ack ו last byte sent שכן אמרנו שה seq וה ack מתקבלים ונשלחים ברמת הבתים.
קל להבין למה הנוסחה
נסתכל על דוגמה - נניח שאנחנו רוצים לשלוח 15KB מאליב לבוב ונתון MSS=1500B וכי באפר הקבלה של בוב הוא בגודל 4500.
הצד שולח מעוניין להעביר 10 segments של מידע אבל מכיוון ש receive window יהיה 4500B אז הגודל של הwindow יהיה 3.

החבילות 1,2,3 הן החבילות שנשלח בשיטת pipeline לבוב, יהיה לנו מצביע LBA ל 0 ו LBS ל 3 (נשים לב שהמספר 3 הוא ברמת הבתים כלומר הערך בפועל יהיה 4500). ברגע ש 1 יקבל ACK וגם שכבת האפליקציה של בוב קראה את 1 מהבאפר נעשה מספר דברים:
- נזיז את LBA אבל לא את LBS
- נתאים את גודל המערך לפי ה send window החדש שהתקבל עם ה ack על הסגמנט הראשון.
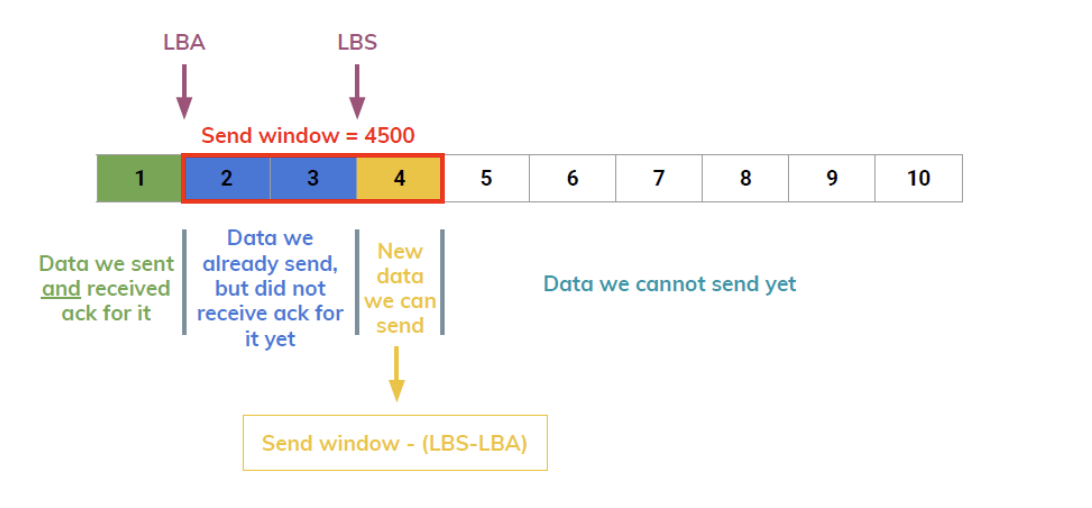
כלומר מספר הבתים החדשים שנוכל לשלוח הוא
נשים לב שאם המידע היה מגיע אבל האפליקציה לא הייתה קוראת אותו מהבאפר אז ה send window היה קטן יותר ב1500 בתים, לכן לא היינו יכולים לשלוח מידע חדש.
Congestion Control
חלון בקרת העומס נועד לטפל במצבים שבהם יש עומס על הרשת בכמות המידע ובמהירות שבו הוא נשלח. מצב כזה שלא יטופל עלול לגרום לנפילת פקטות ולזמני שהייה ארוכים כדי לצאת מהתור של הראוטר
לחלון בקרת העומס יש כמה מטרות
א) יעילות- להעביר הכי הרבה מידע שהוא יכול
ב) לא לשלוח יותר מדי מידע וליצור עומס
ג) הקצאת משאבים באופן שווה בין המקורות השונים.
ד) דינמי
ה) מנגנון טיפול במצב של עומס
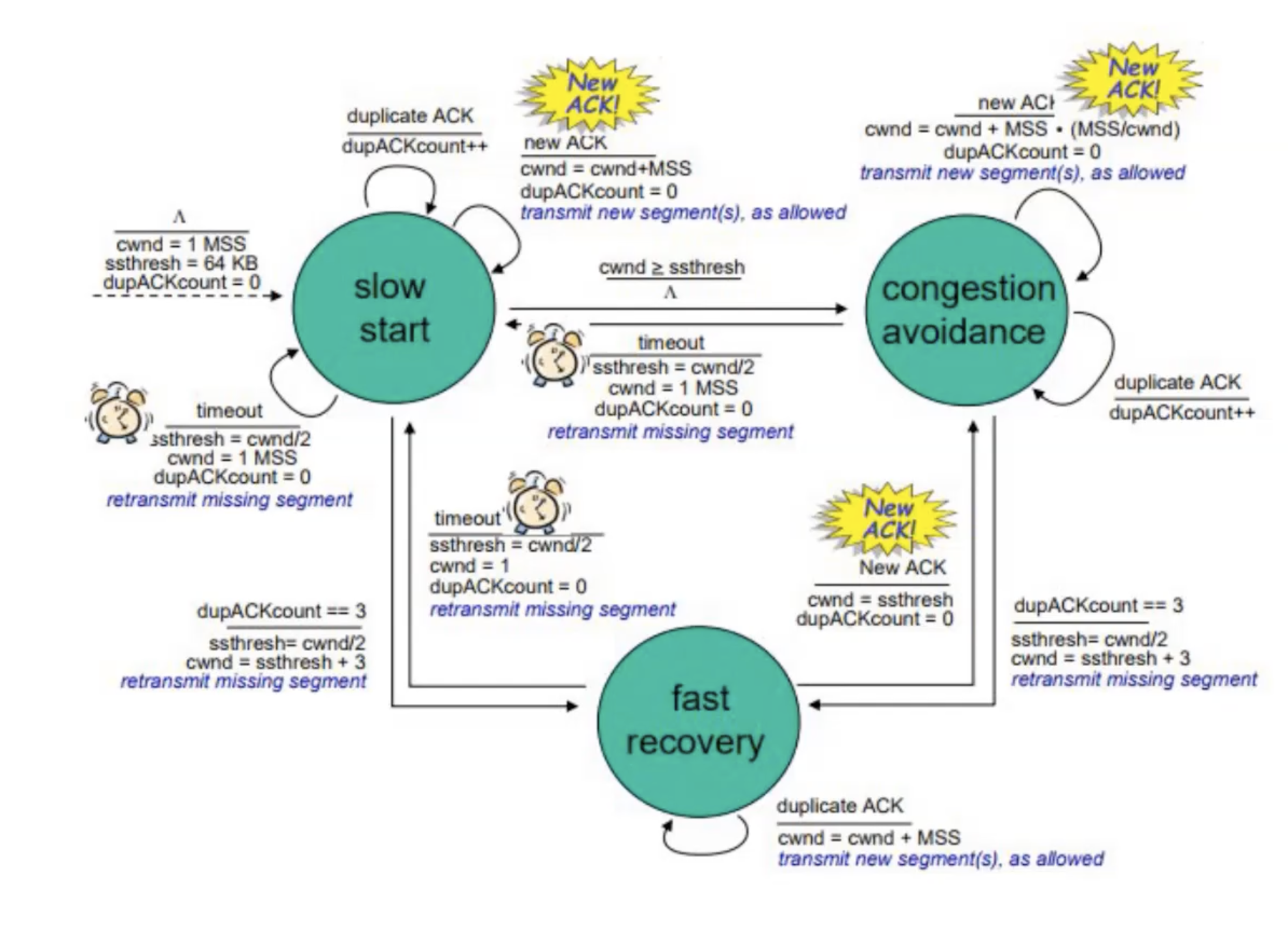
כדי להבין את TCP מטפל בזה צריך להגדיר מספר מצבים
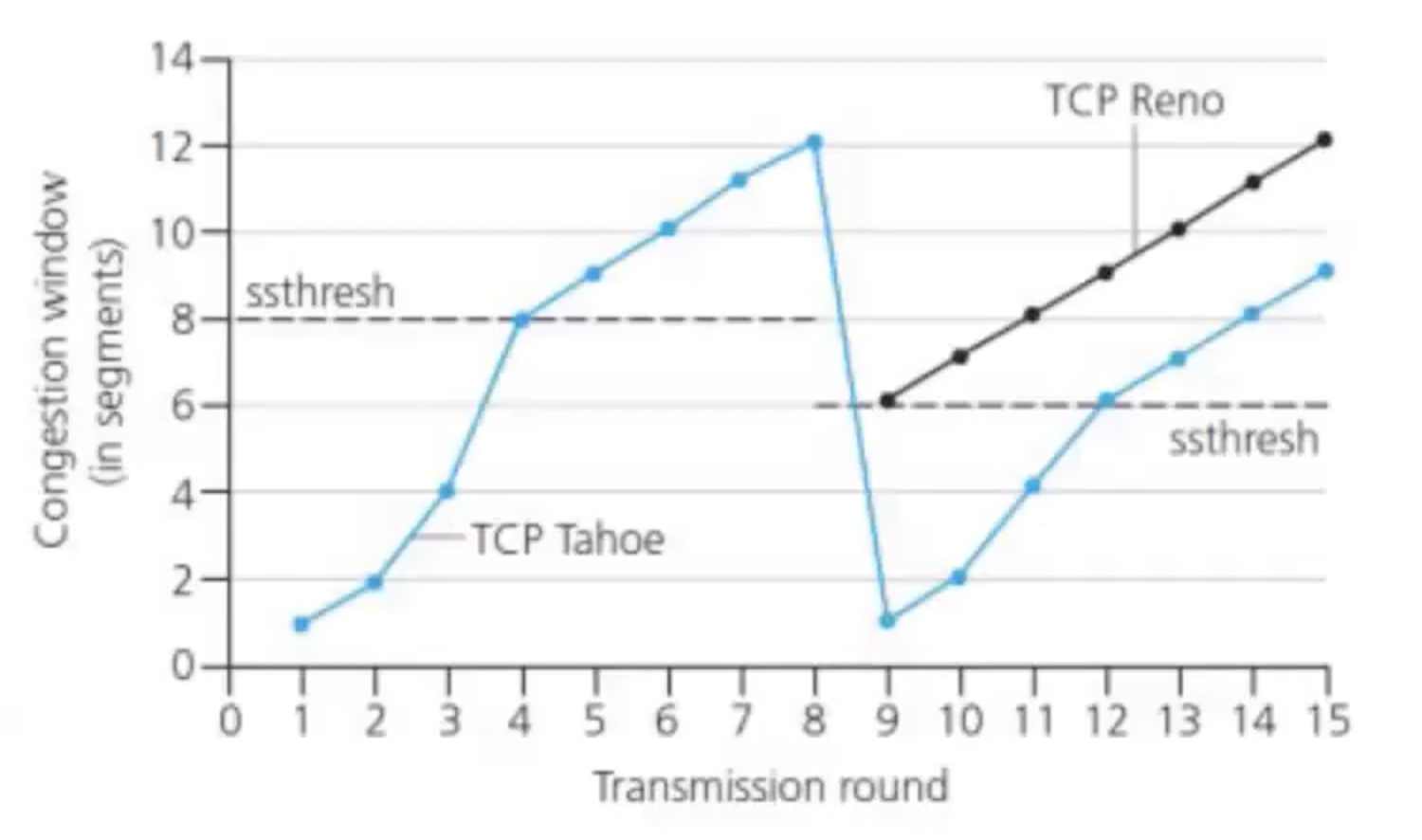
slow start
כאשר החיבור מתחיל, נגדיר באופן מעריכי את קצב שליחת הפקטות עד שנקבל מאורע של איבוד מידע.
מתחילים מזה ש ה
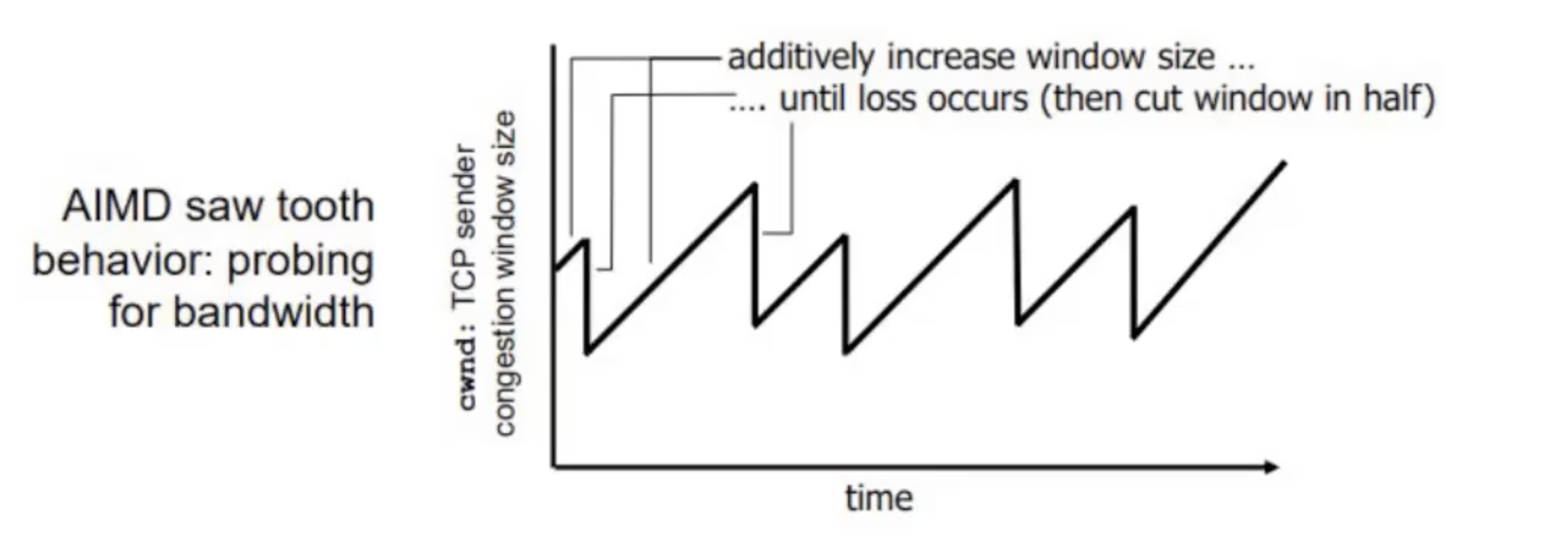
AIMD
Additive Increase Multiplicative Decrease הוא מנגנון למניעת עומס כאשר עובדים בשיטה הקודמת.
השיטה הזאת עובדת בהגדלה ליניארית של ב cwnd. כלומר במקום להגדיל ב 1 את החלון כל ACK שמתקבל מה שיגרום לכך שבכל RTT נגדיל את החלון בגודל אקספוננציאלי ביחס להגדלה הקודמת. הפעם מגדילים ב
את המנגנון הזה עושים עד שמזהים איבוד מידע. ברגע שמזהים אבדה מקטינים בחצי את ה cwnd.
המעבר בין slow start ל AIMD נעשה באמצעות פרמטר שנקרא:
SST- Slow Start Threshold. כאשר כמות הפקטות שאפשר לשלוח ברגע נתון מגיעה לערך של הSST נעבור ל AIMD.
בכל פעם שמתקבל lost יש שני דרכים לטפל:
א) מקטינים את cwnd להיות
מעיד על כך שהרשת לא בהכרח כזאת עמוסה שצריך להוריד את הcwnd ל 1 שוב.
ב) אם האובדן הוא כתוצאה מ Timeout ההתנהגות היה כמו בסעיף א. אם האובדן הוא במצב של ACK כפול אז נקטין גם את ה cwnd וגם את ה sst להיות חצי מ cwnd. וממשיכים לעבור ב AIMD. בגדרת TCP Reno עובדים בשיטה הזו.
Fast Recovery
המנגנון הזה נועד למנוע מצב שאין חבילות באוויר כי מחכים ליותר מדי ACK כפולים.
מצב זה יכול לקרות אם החבילה הראשונה מבין כל החבילות שיכלנו לשלוח בהתאם לcwnd הלכה לאיבוד. זה אומר שעל כל החבילות הבאות אנחנו אמורים לקבל ACK כפול על החבילה הזאת. כפי שאמרנו בחבילה השלישית אנחנו מקטינים את החלון בחצי וכעת צריך לחכות ל ACK המצטבר על כל החבילות כדי להמשיך לשלוח חבילות חדשות. Fast Recovery מונע את זה בשיטה פשוטה: על כל ACK כפול הוא מגדיל את ה cwnd באחד. כלומר אם התקבלו 3 ACK כפולים אנחנו נקטין את החלון בחצי כפי שאמרנו ונוסיף לו
דוגמאות
תחת ההנחה שאין fast recovery נרצה למצוא את פרקי הזמן שבהם TCP נמצא ב slow start וב congestion avoidance
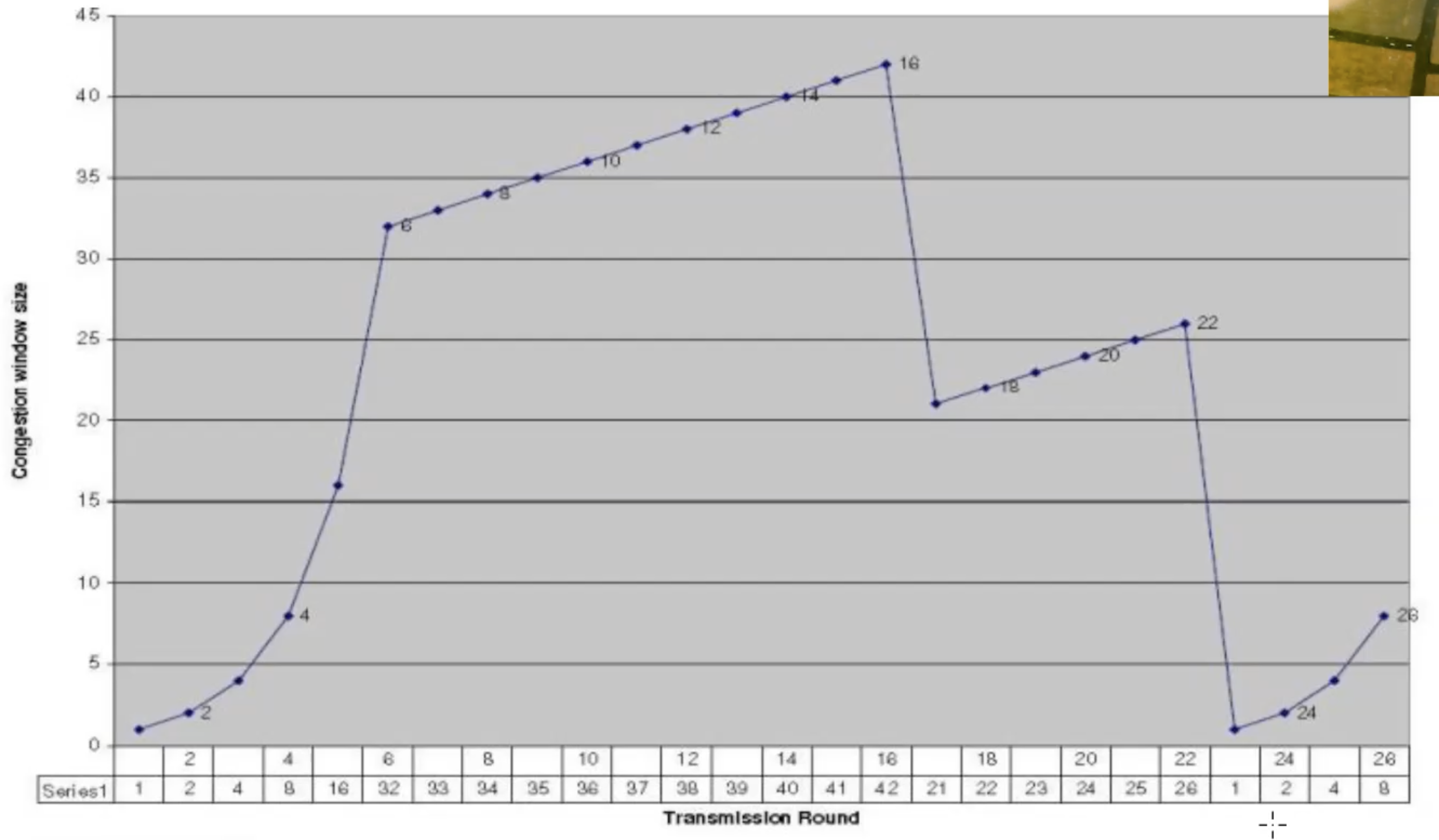
נשים לב שיש שני צירי x שאחד מהם זה הסיבובי שליחה והשני זה הcwnd size (מציג בצורה מדויקת את ציר ה y)
קל לראות זאת פשוט מחפשים היכן הגידול הוא מעריכי והיכן הגידול הוא ליניארי. לפי ציר הזמן זה בעצם מ
נתונים נוספים שאפשר להוציא מהגרף הוא שערך ה tts ההתחלתי הוא
השהיות
אחת הדרכים להשוות בין פרוטוקולים של שכבת התעבורה היא מדידה של זמנים כאשר מריצים את אותם התרחישים בשני הפרוטוקולים ומדידת הזמן שעבר בכל פרוטוקול.
לשם כך, צריך להגדיר איך מחשבים זמנים בפרוטוקול תקשורת וננסה להבין מה ״מעכב״ חבילה בדרך אל היעד.
נעזר בהגדרות שהשתמשנו בהם קודם :
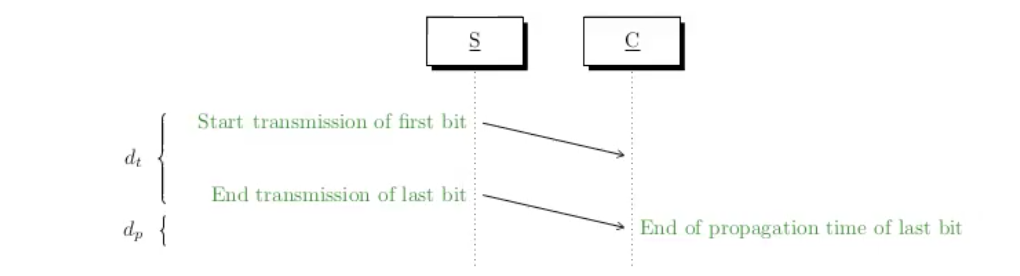
קצב שידור: כמה ביטים בשניה ניתן לשדר? (bps)
קצת התפשטות: כמה מטרים בשניה מצליח לעבור האות (mps)
נגדיר
מתקיים:
a) השהיית השידור היא
b) השהיית ההתפשטות היא
- כמה זמן לוקח לביט בודד לעבור מרחק של
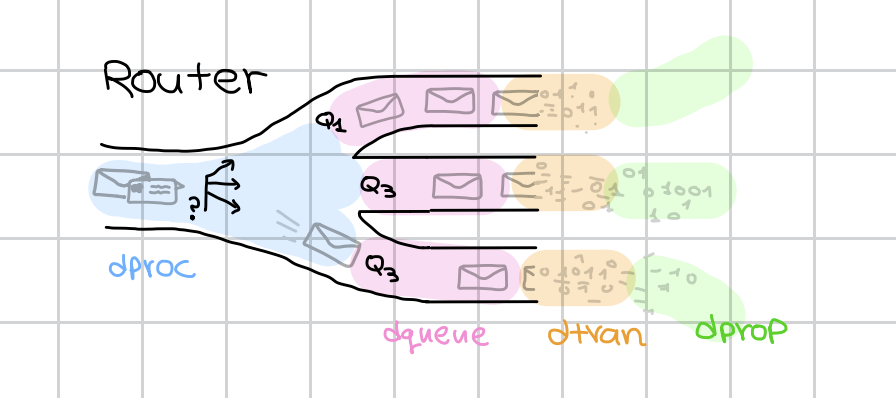
c)
- כמה זמן חבילה ממתינה בתור לפני שהיא משודרת הלאה. נשים לב שהשהייה זו היא פונקציה של קצב השידור של הנתב אל הערוץ וכמות החבילות בתור.
d)
- כמה זמן לוקח לטפל בחבילה ולהעביר אותה אל התור המתאים.
שאלה 1
לקוח הממוקם בניו יורק ניגש לשרת הממוקם בלונדון כדי להוריד קובץ. נתון שהמרחק מהלקוח לשרת הוא
כמה זמן יקח להעביר את הקובץ מהשרת ללקוח, בהנחה שאין עוד תעבורה ורשת ואין השהיית עיבוד כלומר
אם כן , מתקיים ש
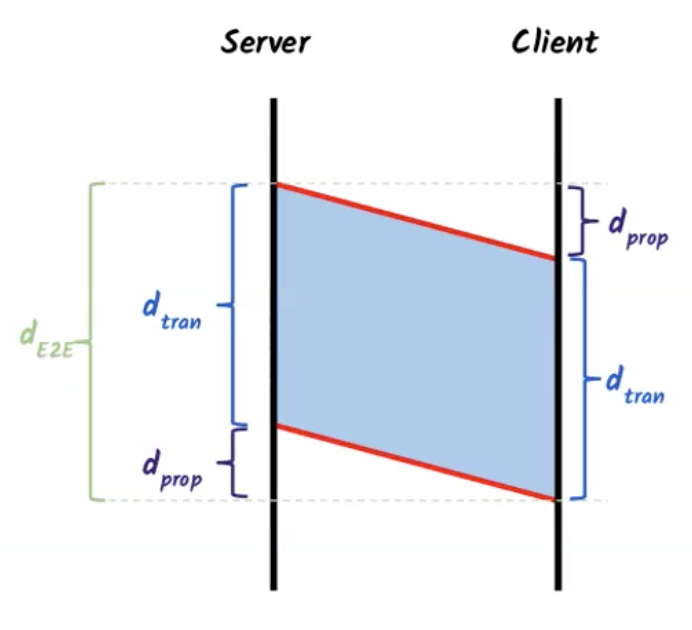
סך הכל נקבל
שאלה 2 - השהיות בשיטת store and forward

נניח כי הראוטר עובד בשיטת store and forward כלומר רק כאשר הביט האחרון מגיע לראוטר הוא שולח אותו ללקוח.
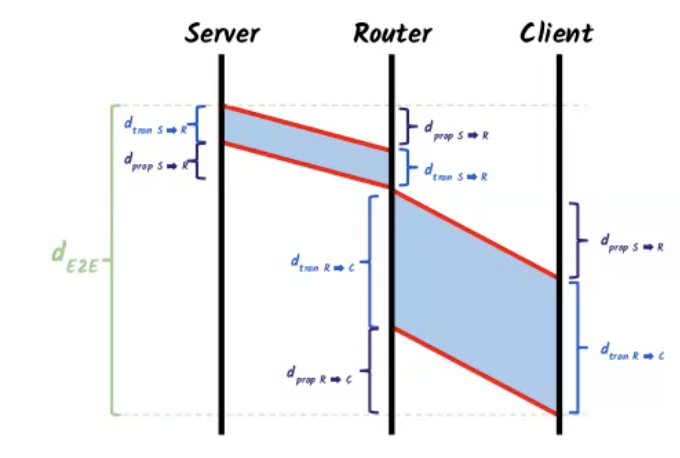
אם כן מתקיים :
ברגע שמבינים כיצד הנוסחה השתנתה העבודה היא בידיוק כמו בשאלה הקודמת, הצבה בנוסחה וחישוב
מציבים ומקבלים
השהיות בשיטת Pipeline
במצב זה מתקיים
a)
b)
c)
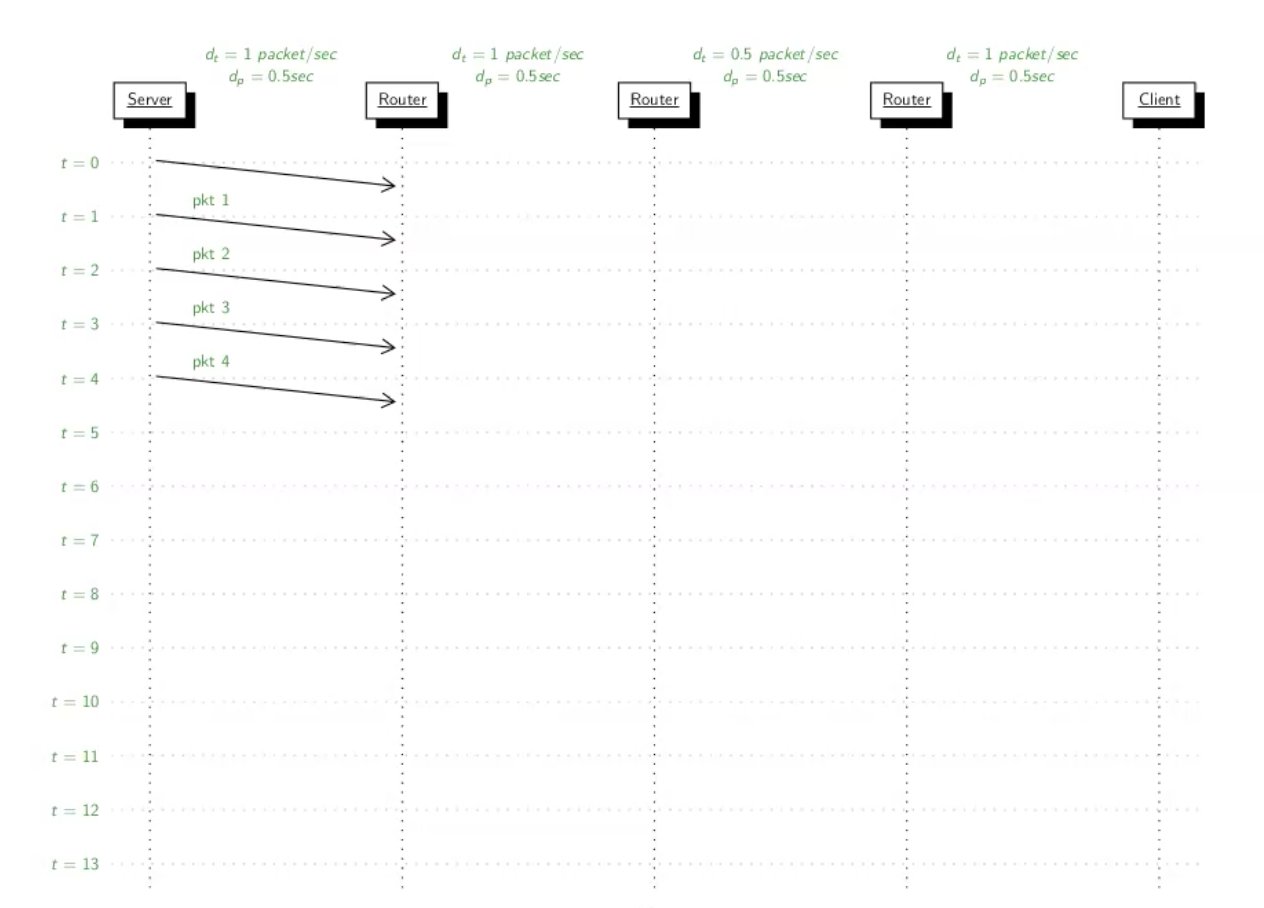
נסתכל על הדוגמה למעלה שבה רוצים להעביר פקטה בשיטת pipeline שמחלקת את הפקטות ל4 פקטות קטנות.
בשלב הראשון אפשר לראות שאנחנו שולחים את הפקטות ולכל אחת לוקח
נשים לב שבשידור השלישי יהיה לנו צוואר בקבוק שכן, זמן השידור שם איטי יותר ולכן פקטות אחרות יצטרכו לחכות ברגע שהן מגיעות עד שהן יוכלו לצאת.
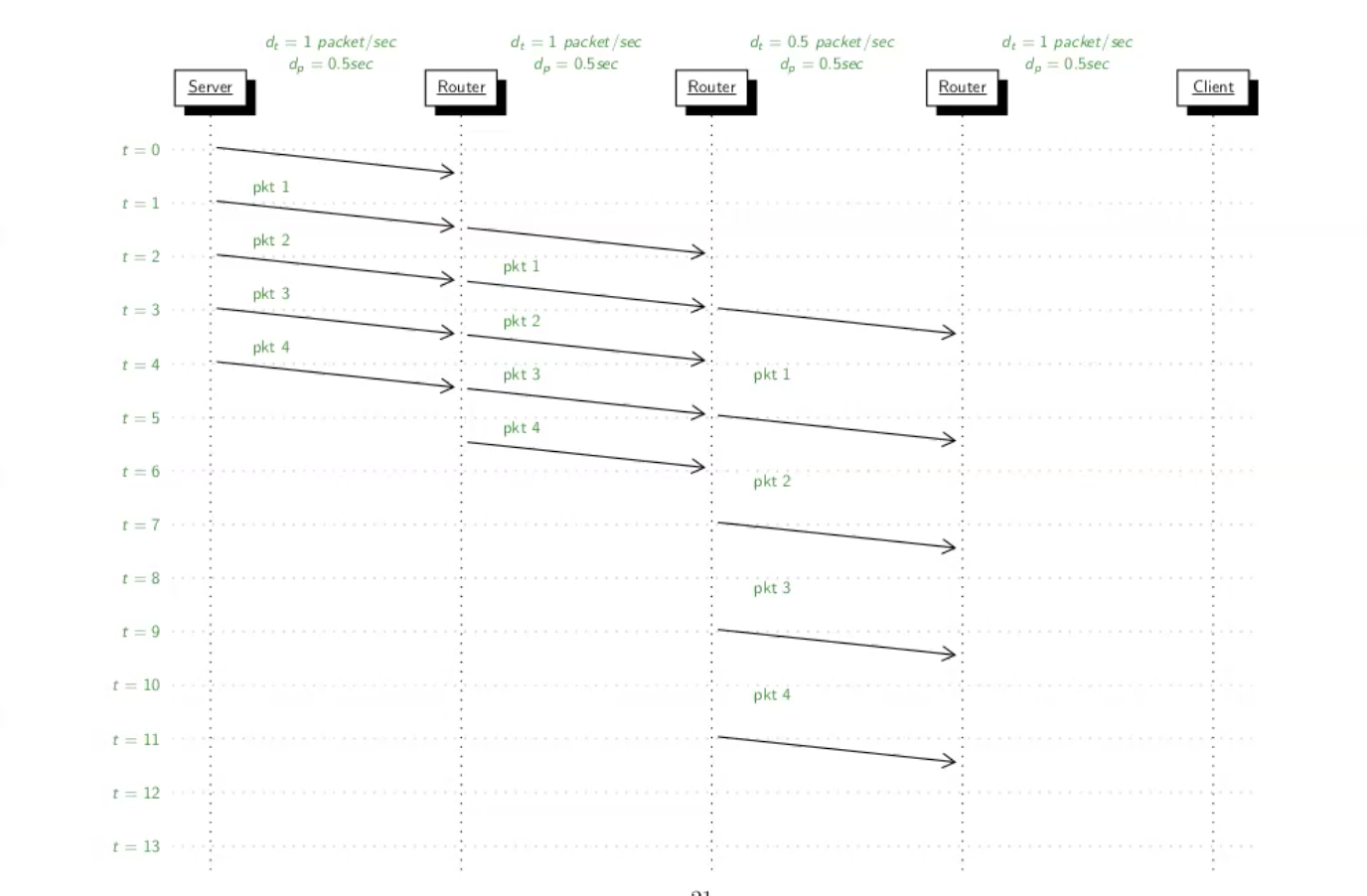
נשים לב שהיכן שהשהיית השידור איטית ביותר, הזמן של כל השידורים האחרים נכלל בתוכו
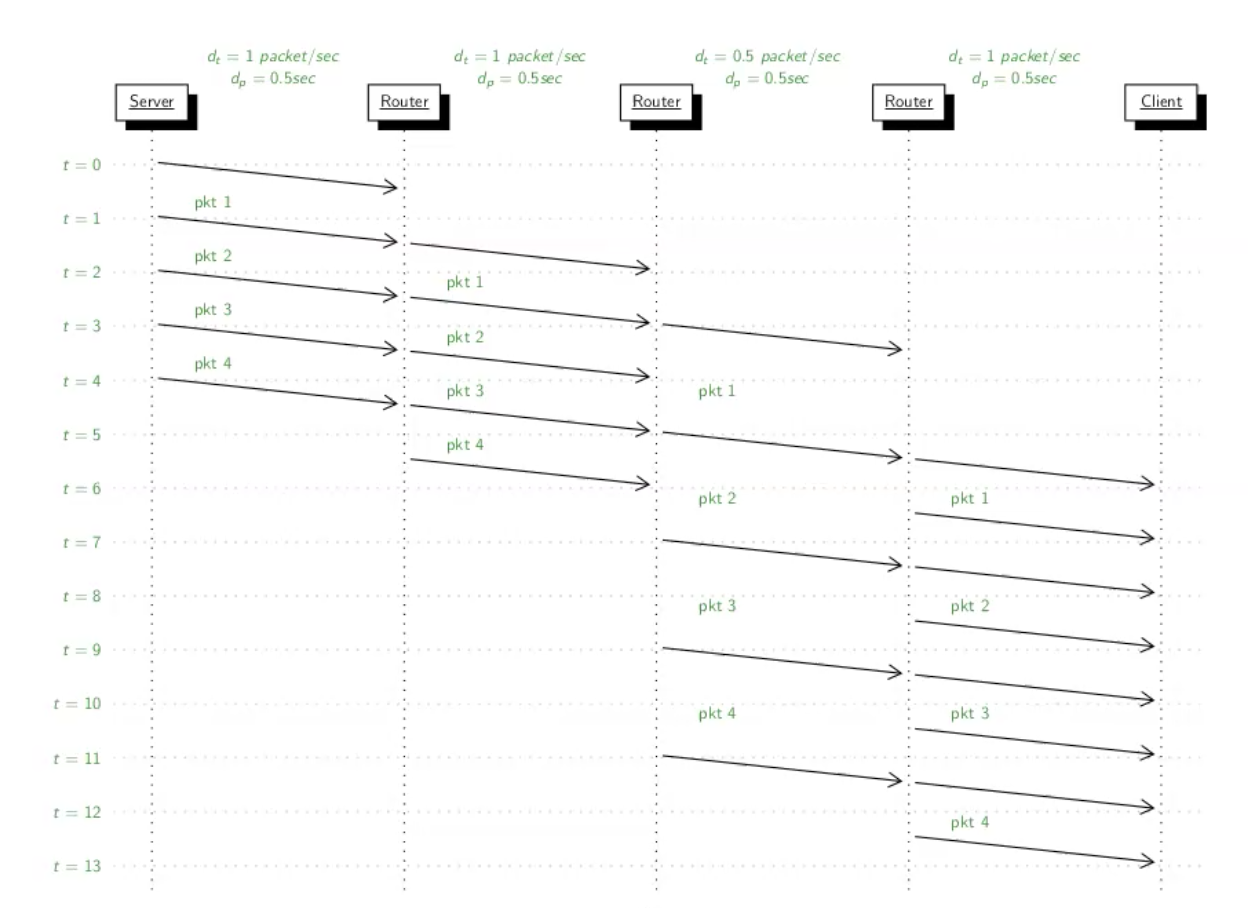
בשלב האחרון אפשר לראות שלמרות שהרמה שם מהירה יותר מהקודמת עדיין קצת השידור הוא כמו של קצב השידור האיטי ביותר. לכן ברמה האחרונה הדבר היחיד שקובע זה הזמן שלקח לפקטה האחרונה להגיע.
שאלה 3

הבחנה: הקובץ מגיע מהשרת ולכן המסלול הוא שרת->נתב->לקוח
חישוב זריז יראה שאנחנו שולחים
כעת, נמצא את הערוץ הכי איטי
- הערוץ בין הלקוח לראוטר הוא הערוץ עם קצב השידור האיטי ביותר
לכן צריך לחשב:
1. כמה זמן לוקח עד שהחבילה הראשונה מגיעה לנתב
2. כמה זמן לוקח עד שהמידע עובר בערוץ בין הנתב ללקוח
נחשב כמה זמן לקח לחבילה הראשונה עד שהגיעה לערוץ האיטי ביותר,
נקבל ש
כעת, נחשב כמה זמן לוקח לשדר את כל החבילות בערוץ הכי איטי
לסיום, נחשב את ההתפשטות של חבילה בודדת בערוץ האיטי
נסכום ונקבל
לכאורה כדאי פשוט לשלוח את המידע בחבילות בגודל של ביט בודד כי אנחנו נדרשים לחכות פחות עבור הפקטה הראשונה, כלומר ככל שיש יותר פקטות קטנות נראה כי הקנס על התעבורה עד לטווח האיטי קטנה משמעותית
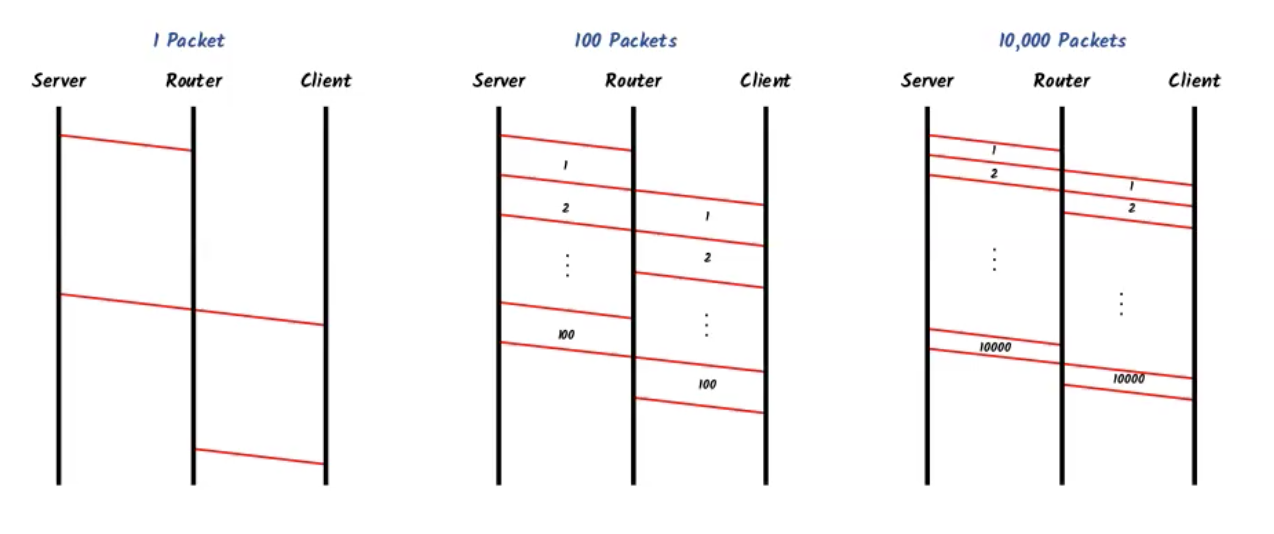
אבל זה לא באמת המצב , מהסיבה השפוטה שלכל פקטה ששולחים מתווספים headers והמחיר של זה יכול להיות כבד בהתאם לגודל ה header. למשל אם חילקנו ל
השהיית תור
נתבונן בדוגמה הבאה:
מחשבים
נוסיף גם שהתור בנתב עובד בצורת FIFO וכל החבילות הן בגודל
נרצה לחשב את השהיית התור עבור החבילה של
החבילה שהגיעה מ
כלומר אנחנו יודעים בקלות לחשב השהיית תור לפקטה מסוימת , רק צריך לחשב את זמן השידור של הפקטות שנמצאות לפניה בתור.
נסתכל על עוד דוגמה:
אם
נתון שקצב השידור הוא
נרצה להבין כמה זמן לוקח עד ששני הקבצים מגיעים וגם מהו גודל התור המינימלי כדי שלא יאבדו חבילות.
ראשית נבין מהו המספר המינימלי של חבילות שיש לשלוח:
נשים לב שמשך הזמן הכולל הוא החל מתחילת שידור החבילה הראשונה (שני המחשבים מתחילים באותו זמן) ועד שהחבילה האחרונה מגיעה ל
סך הכל אנחנו נשדר מ
כעת כדי לקבוע מהו גודל הבאפר המינימלי:
כיוון שקצב השידור בכל הערוצים שווה, בזמן ש
Packet Fragmentation
כאשר חבילה מגיעה לרכיב תקשורת והיא גדולה מדי עבור הערוץ שאנחנו צריכים להעביר אותו אליה, אנחנו מבצעים פרגמנטציה. כלומר, מחלקים את החבילה לתתי חבילות בכדי שיוכלו לעבור בערוץ הצר יותר. נשים לב, פרגמנטציה יכולה להתבצע הרבה פעמים לאורך המסלול אבל הרכבה מתבצעת אך ורק אצל הצד המקבל.
TCP מנסה להמנע מפרגמנטציה על ידי סגמנטציה. עם זאת, UDP למשל, חשוף לפרגמנטציה.
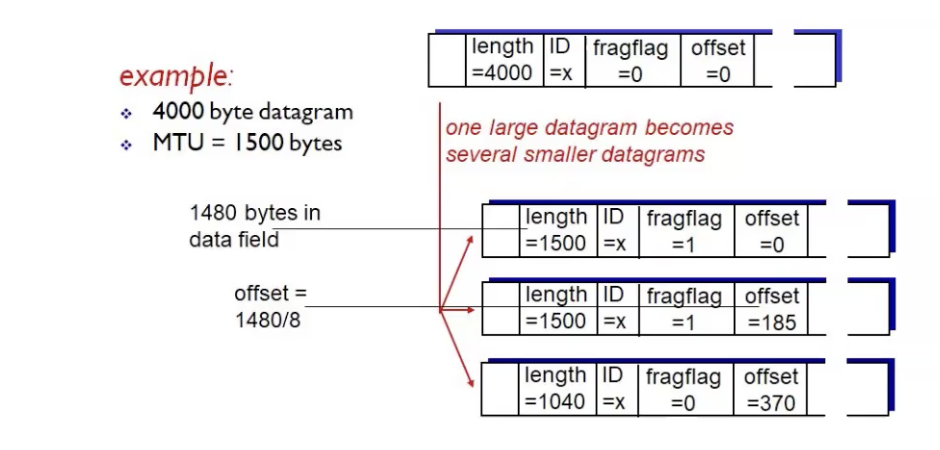
יש לנו datagram בשכבת הרשת בגודל 4000 בתים, אם נוריד את הheader זה יוצא 3980 בתים. ה MTU הוא 1500 בתים ואם נוריד את הip header זה אומר שבפרגמנטצייה נוכל להעביר כל פעם מידע בגודל 1480.
ההרכבה של הפרגמנטים נעשים לפי הoffset בשכבת הרשת במכשיר היעד הסופי, רק אם כולם הגיעו זה זה בונה את המידע ומעביר את זה לשכבת התעבורה.
נסביר את הדגלים:
fragFlag - דגל שקובע שיש עוד פרגמנטים אחריי לפי סדר החלוקה ולא סדר ההגעה.
ID- מזהה שמאפשר לדעת שכל הפרגמנטים קשורים לאותו data
offset- השדה Fragment Offset (13 בתים) משמש לציון מיקום ההתחלה של הנתונים בפרגמנט ביחס לתחילת הנתונים בחבילה המקורית. מידע זה משמש להרכבה מחדש של הנתונים מכל הפרגמנטים (בין אם הם מגיעים בסדר ובין אם לא). בפרגמנט הראשון ההיסט הוא 0 שכן הנתונים בחבילה זו מתחילים באותו מקום כמו הנתונים בחבילה המקורית (בהתחלה). בפרגמנטים הבאים, הערך הוא ההיסט של הנתונים שהפרגמנט מכיל מתחילת הנתונים בפרגמנט הראשון (היסט 0), ב-8 בתים 'בלוקים'. אם מנה המכילה 800 בתים של נתונים מפוצלת לשני מקטעים שווים הנושאים 400 בתים של נתונים, היסט הפרגמנט של הפרגמנט הראשון הוא 0, של הפרגמנט השני 50 (400/8). ערך ההיסט חייב להיות המספר של בלוקים של 8 בתים של נתונים, כלומר הנתונים בפרגמנט הקודם חייבים להיות כפולה של 8 בתים. הקטע האחרון יכול לשאת נתונים שאינם כפולה של 8 בתים מכיוון שלא יהיה קטע נוסף עם היסט שחייב לעמוד ב'כלל' זה.
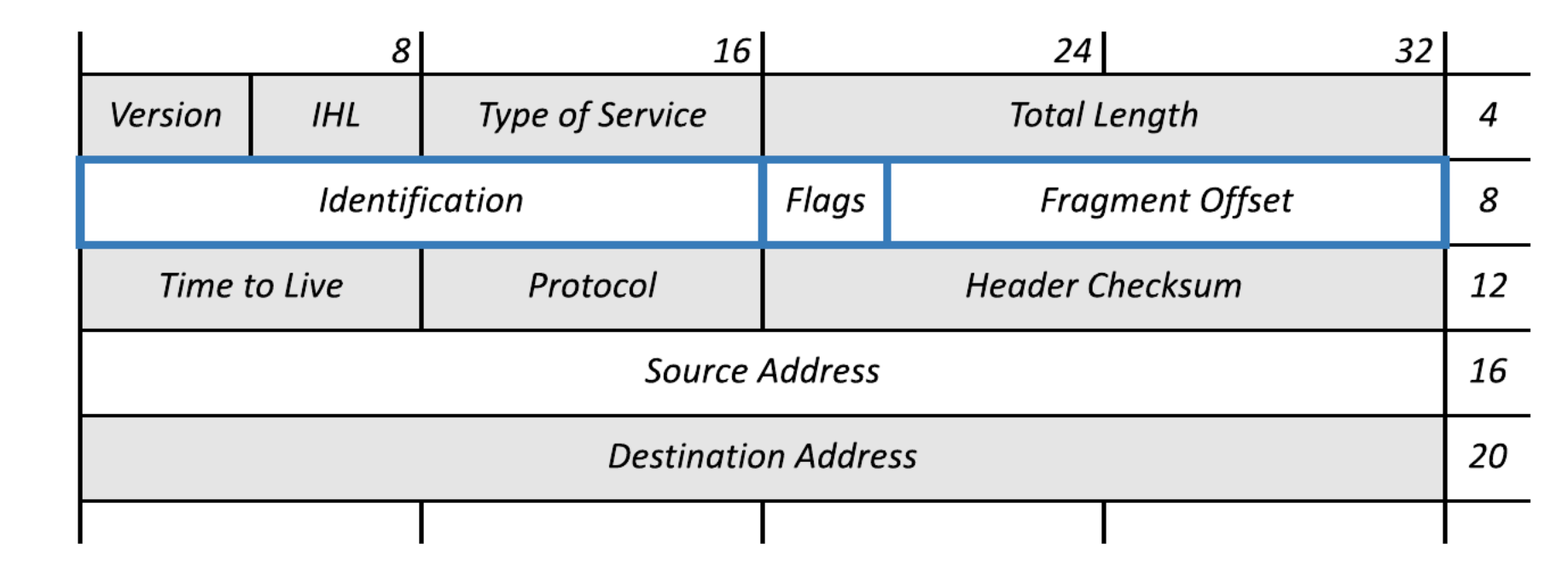
הפעולה הזאת מבוצעת בNetwork Layer, הפרגמנטציה נעשית בעקבות datagram size שגדול יותר מה MTU של הערוץ שבו המידע אמור לעבור. שכבת התעבורה מנסה לטפל בזה (לפחות אם משתמשים ב TCP), לכן חשוב להכיר את התהליך הזה כבר בשכבה הזו.
ניתן לראות בתמונה שבעצם מתבצע שכפול של כלל ה headers לתתי הפקטת. כמו כן ניתן לראות שיש payload שמתווסף לheaders כתוצאה מהחלוקה הזאת. למשל offset של המידע fragflag שקובע האם יש עוד פרגמנטים בדרך.
Path MTU Discovery
לקוחות יודעים את ה MTU של הערוץ שלהם. לקוחות שאיתם יש תקשורת יודעים לדווח על ה MTU של הערוץ שלהם. אבל, המסלול מורכב מערוצים נוספים שם ה MTU יכול להיות שונה.
TCP מנסה להמנע מפרגמנטציה לאורך המסלול באמצעות Path MTU Discovery שעובד בצורה הבאה:
א) שולחים חבילה, ע״פ מגבלות הגודל הידועות, כאשר הדגל Dont fragment דולק.
ב) כאשר החבילה תגיע לערוץ בו ה MTU קטן מהחבילה, במקום פרגמנטציה, תשלח בחזרה הודעת הודעת שגיאה בעזרת הפרוטוקול ICMP שאומרת שהחבילה גדולה מדי, ומה צריך להיות גודל החבילה המקס׳.
ג) השולח יעדכן בהתאם את גודל ה MSS וה MTU וישלח בהתאם.
ד) במידה וגודל זה עדיין גדול מדי לערוצים אחרים במסלול, חוזרים חלילה.
דוגמה:
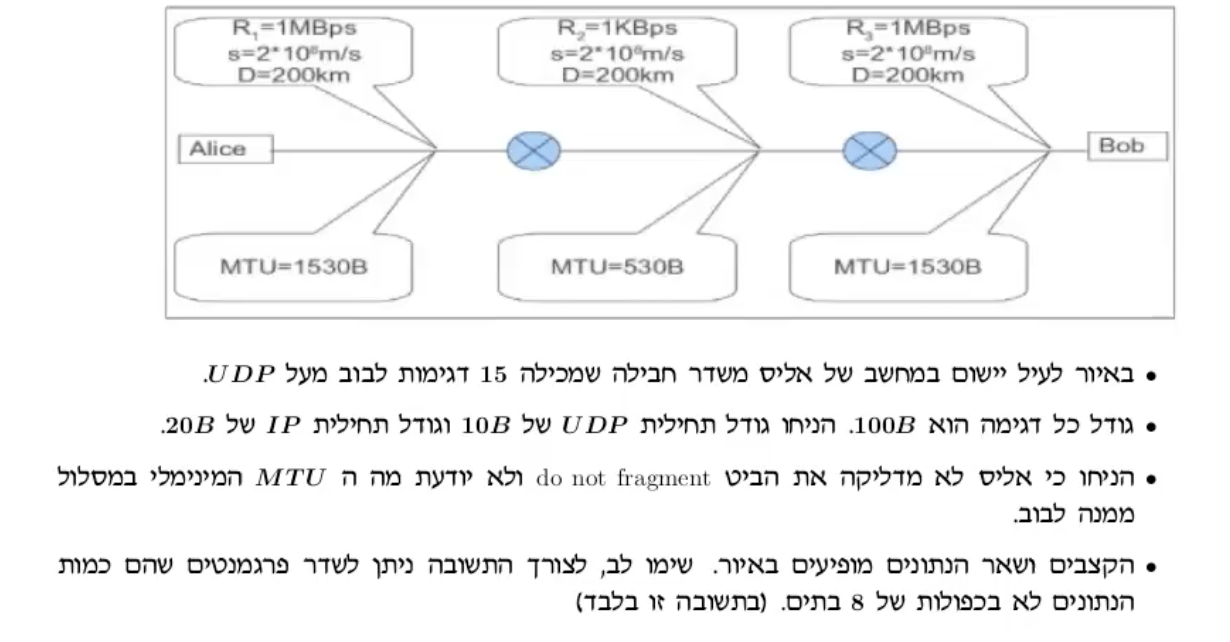

הערוץ האיטי הוא בין שני הנתבים ולכן ערוץ זה הוא זה שמכתיב את הקצב בו החבילות יתקבלו אצל המקבל.
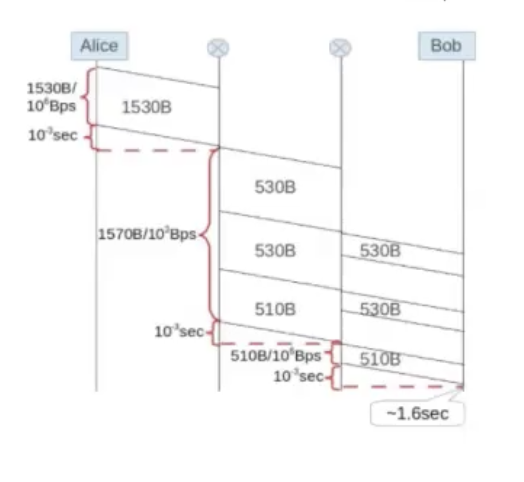
בגלל שהביט do not frag כבוי אז המידע יעבור פרגמנטייה בערוץ בין שני הנתבים. הראוטר האמצעי מקבל 1530B אבל ה MTU שלו הוא 530B.
לכן הוא לוקח את את ה1530 מחסיר מהם 20 של header IP וקיבלנו 1510. בגלל שה MTU הוא 530 נגדיר פרגמנט בגודל 510 ונוסיף לו 20 בתים של תחילית IP כדי לקבל את הפרגמנט הראשון. גם את הפרגמנט הבא נעשה באותה צורה וכעת עבור הפרגמנט האחרון נשאר לנו 490 בתים של מידע + 20 בתים של תחילים שכבת הרשת (ip) נקבל 510 בתים.
כעת לשאלה השנייה, נניח שההסתברות לכך שהנתב השני זורק כל חבילה שמגיעה היא p.
ההסתברות שהדגימה הראשונה תגיע בהצלחה ליישום של בוב היא ההסתברות שכל שלושת הפרגמנטים יגיעו לבוב ויורכבו בהצלחה בשכבת האפליקציה. כלומר אסור לאף פרגמנט ליפול בדרך ולכן ההסתברות
היחס בין גודל החלון וקצב השידור
נרצה להבין את היחס בין גודל החלון שמשדרים וקצב השידור לבין RTT כלומר:
a) אם מתקיים
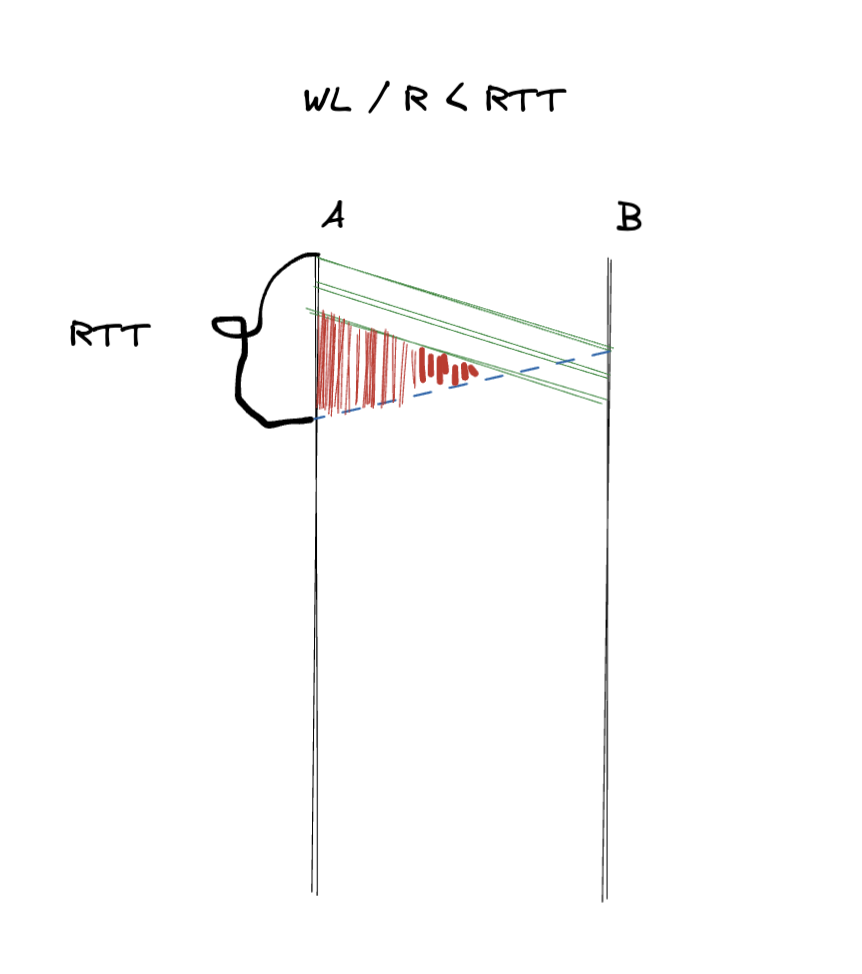
ניתן לראות שכאשר מצב זה מתקיים ישנו זמן מת (המשולש באדום) עד שניתן לשלוח את החלון הבא.
b) אם מתקיים
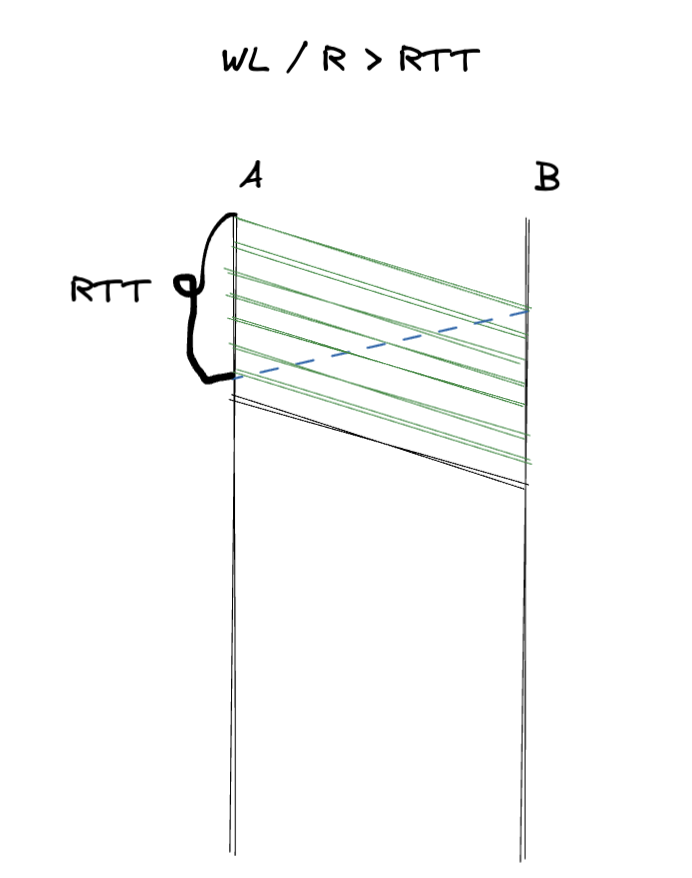
כאשר היחס גדול יותר ניתן לראות שמתקבל ack על החבילה הראשונה לפני שסיימנו לשדר.
מה קורה במספר ערוצים?
כאשר יש יותר מערוץ אחד הקצב האמיתי נקבע על ידי הערוץ האיטי ביותר, אי אפשר לשדר יותר מהר ממנו כי אם כן היינו עושים זאת אנחנו נגרום לחבילות בנתב שלו לחכות בתור , מה שיגרום ל RTT שלהם לגדול ולגדול.
כלומר, החל מאיזה חלון ה RTT כבר לא גדול יותר מזמן השידור של החלון. עם זאת, מכיוון שהRTT מכין בתוכו את זמן השידור של החבילה הראשונה, אם חיבור הTCP מתחיל מחלון בגודל חבילה אחת, בחלון הראשון תמיד ה RTT יהיה גדול יותר מזמן השידור של החלון.
החל מאיזה חלון הRTT כבר לא גדול יותר מזמן השידור של החלון?
נשים לב שכשאשר אנחנו ב Slow start אנחנו משדרים בחלון ה i כמות של
נרצה אם למצוא את ה
כאשר באי שיוויון זה הנעלם היחיד הוא
דוגמה:

נרצה לשלוח
משך הזמן שלוקח לשלוח את החבילה האחרונה הוא
משך הזמן שלוקח לשלוח ack :
סך הכל קיבלנו
ב stop and wait ייקח לנו
נשים לב שכאן ברור ש

במצב זה כבר יש לבדוק את היחס בין שידור החלון לבין הRTT
מתקיים ש
הסיבה ששמנו 11 היא בגלל שהיחס הנ״ל הוא > אז מתקיים שנשלח 10 סיבובים מלאים של 8 חבילות בנפרד ועוד סיבוב אחד של 4 חבילות (לא משפיע על ה RTT שנמדד לפי החבילה הראשונה). לאחר החישוב הזה מוסיפים את זמן השידור של כל החבילות בחלון האחרון חוץ מהחבילה הראשונה שנספרה בRTT ה 11 . החבילה האחרונה נזכיר היא קטנה יותר משאר החבילות.
Silly Window Syndrome
האפליקציה עלולה לקרוא בקצב איטי ביחס לקצב שבו המידע מגיע למחשב (אם כי, חלון בקרת הזרימה תוודא שלא ישלחו יותר מידע מגודל הזכרון בכדי שלא יזרק).
הבעיה כאן היא שעלולה להיווצר תופעה בה כמות המידע ששולחים בכל חבילה הולכת וקטנה והולכת וקטנה מה שגורם לכך שאנחנו שולחים הרבה מאוד תחיליות.
בעיה דומה יכולה להתרחש בכיוון ההפוך, כאשר האפליקציה בצד השולח, שולחת הרבה מידע אבל בחתיכות קטנות (אם TCP יחכה הוא יוכל לחבר חתיכות קטנות לחבילה אחת במקום חבילות נפרדות).
הדרכים למניעת התרחיש הן:
המקבל לא יפרסם חלון קטן מדי. למשל, גודל החלון שהוא מפרסם יהיה לפחות MSS אחד.
- אם גודל החלון קטן מכך, המקבל יפרסם חלון בגודל 0.
- השולח יקבל את החלון בגודל 0 מה שימנע שליחה של חבילות קטנות מדי.
- כאשר המקבל יפנה מקום בבאפר הוא ישלח ack עם גודל חלון עדכני מה שיאפשר לשולח להמשיך לשלוח.
- אפשר לבצע probing בצד השליחה, כלומר בצד השולח ניזום שליחה של מידע קטן אם עבר זמן מאז שקיבלנו גודל חלון עדכני ( קורה אחרי הרבה זמן שגודל החלון היה 0).
בצד השולח, נשתמש באלגוריתם Nagle
- אם אין מידע שמחכים ל ack עליו, שלח את המידע שהאפליקצייה ביקשה.
- אם יש מידע שמחכים לack עליו נעכב בקשות שליחה של האפליקציה אם הן קטנות מדי עד שנקבל את ה ack או עד שיצטבר מספיק מידע, כלומר בגודל של לפחות MSS .
נשים לב שהאלגוריתם הזה לא עובד טוב עם delayed ack algorithm.
דוגמה:

במקרה הכללי , אם הקצב שבו מגיע המידע הוא R והקצב שבו קוראת האפליקציה מהבאפר הוא O וגודל הבאפר בפועל הוא W אזי הנוסחה עבור גודל החלון ה אגרסיבי אותו ניתן לפרסם היא
נשים לב שהעיקר פה הוא השהיית ההתפשטות ולכן גם אן נתעלם משאר ההשהיות נקבל שאם השולח ישלח מידע בגודל הבאפר וימתין עד לקבלת תשובה, נקבל שקצב העברת המידע הוא
-
המקבל יכול לפרסם חלון גדול יותר מהגודל הבאפר שיש לו בפועל. פרסום שכזה יאפשר למידע להגיע מהר יותר, למרות שאין גודל בפאר לכאורה מתאים, האפליקציה מרוקנת כל הזמן את הבאפר ומפנה מקום. למשל, אם המקבל יפרסם חלון בגודל 400000 אז הקצב יגדל ל 1MBps.
-
נציב בנוסחה
. גודל חלון כזה יתן לנו קצב של .