Encryption
הצפנת המידע היא טכניקה המאפשרת סודיות של המידע העובר ברשת והגנה עליו מפני גורמים שמנסים לדלות את המידע הזה ברשת.
נשים לב שהצפנה מטרתה סודיות אבל היא לא מבטיחה יושרה של המידע כלומר לא בטוח שמי שהצפין את המידע זה הצד השולח, את זה אין איך לדעת.
Keyless Encryption Scheme
הגדרה: הצפנה היא פונקציה Enc שמקבלת
הגדרה: פונקציית הפענוח (decryption) היא פונקציה Dec שמקבלת
סכמת ההצפנה: מכילה שני אלגוריתמים
הצפנת קיסר היא שיטה הסטורית של הצפנה שכבר לא נפוצה היום והיא סך הכל ביצעה shift לתווים לפי מספר מסויים. למשל, אם ערך הshift הוא 3 והתו במחרוזת הוא a אז במחרוזת המוצפנה הוא יהיה

אם נסתכל על סכמת ההצפנה נקבל

קונבנציה
- Alice , Bob , Charlie, Carol - קונבנצייה לצדדים בתקשורת שהם ״תמימים״
- אויב מסוג off path ייקרא Oscar.
- אויב מסוג מאזין ייקרא Eve
- Man in the Middle ייקרא Mallory
כאשר מתעסקים בהצפנה חשוב גם להבין מהי חשיבות ההצפנה ועם איזה בעיות נצטרך להתמודד ללא הצפנה:
- Off-path - מאזין לתקשורת בין Alice ו Bob ומדמה את הצד השולח.
- Eavesdropper - מאזין לתקשורת ומקבל עותק של המידע שנשלח בתקשורת.
- Man in the Middle - לא רק מקבל עותק של המידע אלא המידע עובר דרכו (!) והוא יכול להחליט האם להעביר את המידע שהתקבל או להעביר מידע חדש לחלוטין וכו׳. אפשר להסתכל על זה כמו מעין proxy זדוני...
Kerckhoffs' principle
העקרון הזה יוצא מהנחה שתמיד ניתן לדעת את סכמת ההצפנה ולפיכך תמיד ניתן לשבור אותה.
העקרון של קרקהוף- סכמת הצפנה תהיה בטוחה כל עוד המפתחות של ההצפנה נשארים סודיים (גם אם האלגוריתם של ההצפנה ידוע).
אם הולכים על ההצפנה הזאת אז ההגדרה ממקודם אינה הצפנה שניתן להשתמש בה.
Symmetric Encryption
סכמת הצפנה סימטרית מוגדרת על ידי (Enc, Dec) כמו מקודם רק שהפעם הקלט לפונקציות יכלול בתוכו מפתח k. לכן ההצפנה נקראת סימטרית כי ערך המפתח k הוא זהה גם בצד המצפין וגם בצד המפרש. כלומר Enc(k, p) = c וגם
באופן פורמלי נגדיר את סכמת ההצפנה הסימטרית כ
אם ניקח את הסכמה הזאת ונפעיל אותה על הצפנת קיסר נקבל

האם שיפרנו את הצפנת קיסר על ידי הוספת המפתח? לא, בגלל שהתוצאה חסומה בערך קבוע 26 עדיין ניתן לפענח את ההצפנה. מרחב הערכים שkey יכול לקבל במקרה הזה הוא קטן.
צופן החלפה
Monoalphabetic substitution cipher הוא ההכללה של הצפנת קיסר שקבענו מקודם והיא מחליפה בין תווים לאו דווקא על ידי פונקצית shift אלא על ידי פונקצייה שלמה אחרת.
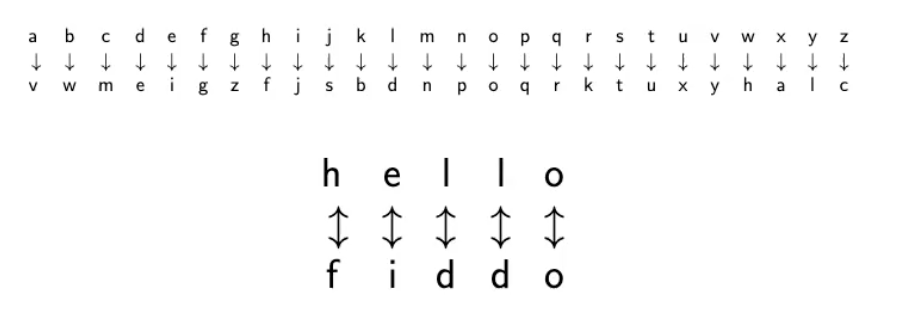
במקרה הזה אנחנו משפרים מאוד את מרחב הערכים של k ביחס להצפנת קיסר. כעת מרחב הערכים של מפתח ההצפנה (שהוא טבלת המיפוי) יהיה
הצפנת ויגר
נבחן הצפנה נוספת ונבחן האם טווח המפתחות שלה טוב.
Vigenere cipher הולך כך:
- בחירת מפתח אקראי - רצף תווים אקראי
- שרשור המפתח לעצמו
- להמשיך לשרשר עד שהאורך של המפתח זהה לאורך של המחרוזת (תוך התעלמות מתווים שקופים)
- לבצע shift על התו ה i במחרוזת לפי הערך של התו ה i במפתח.

כאן ניתן לראות שהמילה הראשונית הייתה lemon. כדי לחשב למשל את הערך החדש של האות t מבצעים סכימה עם הערך של l (האינדקס בabc, כלומר 11) כשמחברים ומבצעים %26 מקבלים 4 שזה התו e.
על פניו נשמע מבטיח, אבל נשים לב שהעובדה שהרצף חוזר על עצמו באיזשהו שלב מאפשרת לנו לקבל מספרים שאורך המפתח המקורי יהווה מחלק שלהם

התוקף מצא שתי מילים זהות בטקסט המוצפן (עדיפות שיהיו באורך ראשוני כמו 3) במקרה זה,

נשים לב שהעובדה שהתווים האלה זהים בהצפנה היא בגלל שגם המילים ב p היו זהות אבל גם המפתח חזר על עצמו בקפיצות של האורך שלו ולכן קיבלנו רצף זהה. כלומר אפשר לחשוד שאורך המחרוזת המקורית הוא מחלק משותף של 50 ו 10 כלומר או 2 או 5 או 10.
השיטה הזאת נקראת Kasiski method. כעת אם גילינו שהמפתח הוא באורך 5 נוכל לבצע בנייה של שכיחויות לפי קפיצות של אורך המחרוזת.

e מופיע הכי הרבה פעמים במקרה הזה. כיוון שאפשר להניח שהתפלגות התווים ידועה בתווים של הטקסט המקורי נוכל לבצע התאמה בין התו e לתו שמופיע הכי הרבה פעמים בטקסט המקורי.