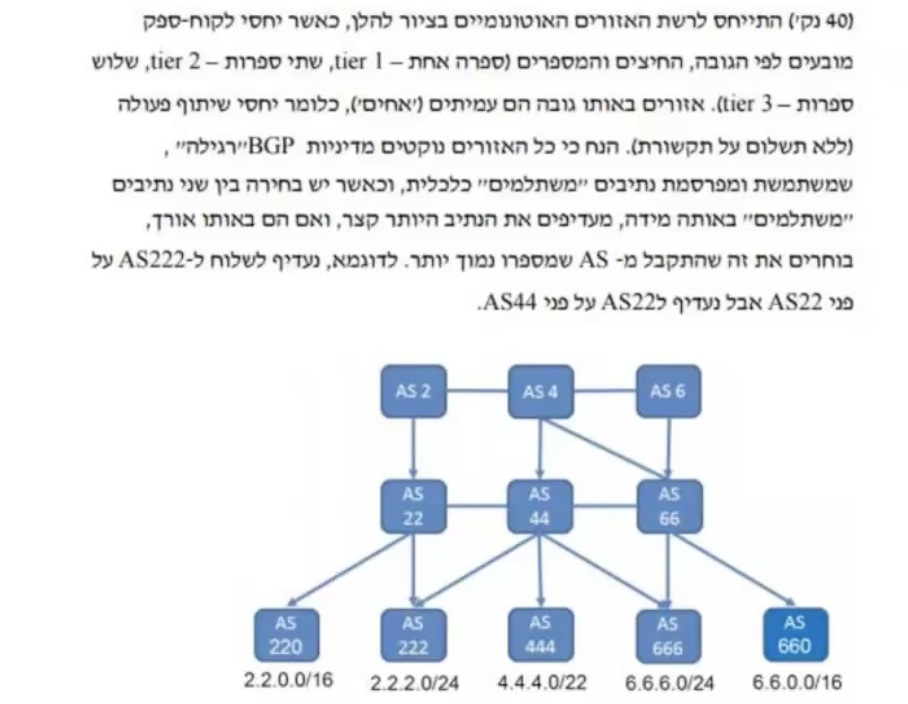
שכבת הרשת
תפקיד שכבת הרשת הוא לשנע segment מהרכיב השולח לרכיב המקבל.
השולח - מייצר datagram מה segment ומעביר ל link layer.
המקבל - מעביר את הsegment לTransport Layer .
התפקיד של שכבת הרשת הוא לא בידיוק להעביר למחשב המקבל אלא לרשת שבה נמצא המחשב המקבל , Link Layer אחרי להעביר את המידע למחשב המתאים ברשת המקומית.
לראוטר יש תפקיד מרכזי בשכבה זו:
* הוא בודק את כל שדות ה headers בכל ה IP datagrams.
* משנע datagrams מ input ports ל output ports כדי שיוכל להעביר אותם את כל הדרך עד לרשת המתאימה
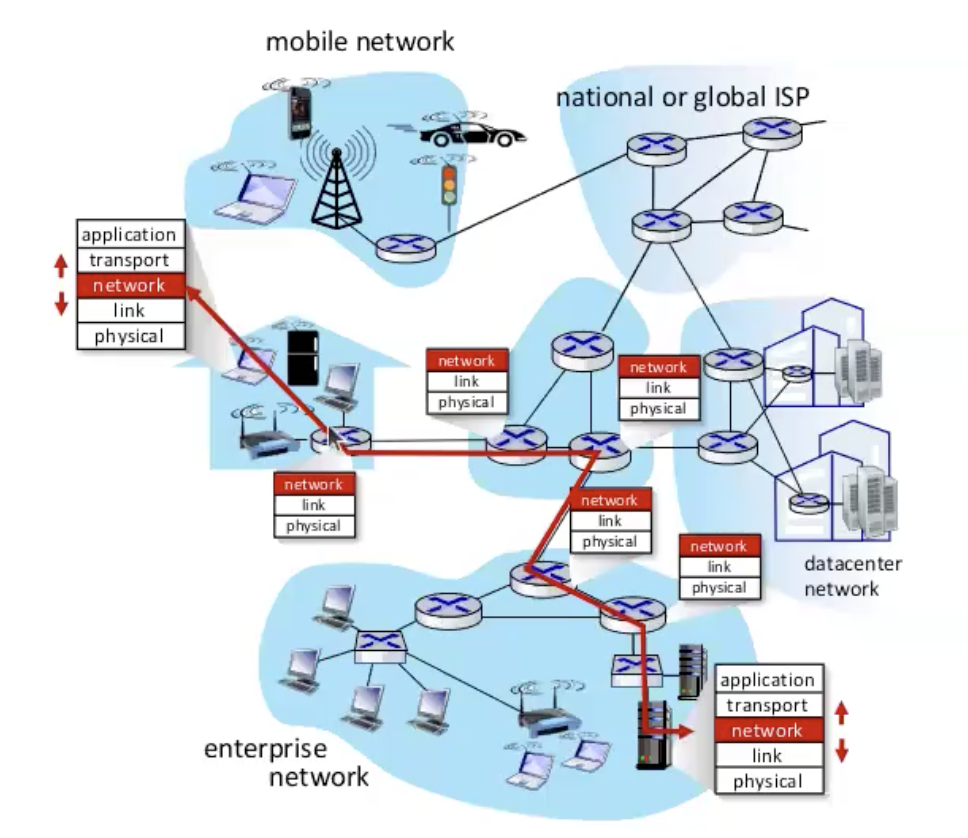
ישנן שתי פונקציות עיקריות של שכבת הרשת
forwarding- שינוע פקטות מראוטר אחד לראוטר הבא בתור.
routing - קביעת המסלול מהשולח ליעד.
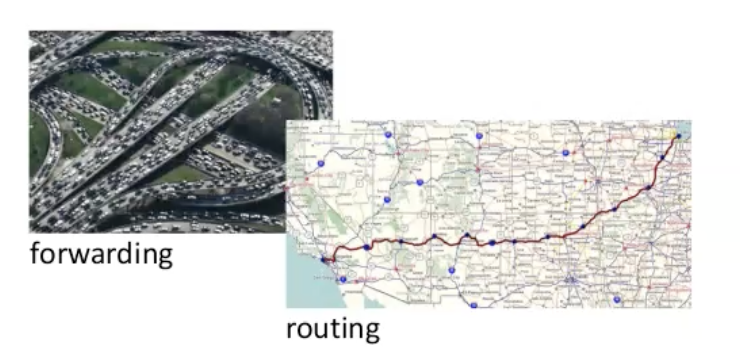
על שכבת הרשת נסתכל בשני מישורים עיקריים
Data plane - כאשר הראוטר מקבל חבילה הוא קובע כיצד ה datagram המתקבל מinput כלשהו יעבור ל output port של הראוטר הבא.
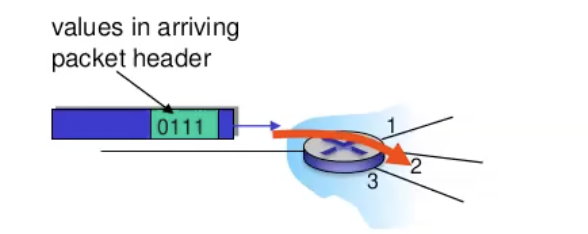
Control plane - קובע כיצד datagram מנותב בין ראוטרים מקצה לקצה עד הגעה ליעד. כלומר איך הראוטרים מחליטים בינהם לאן הפקטה תלך
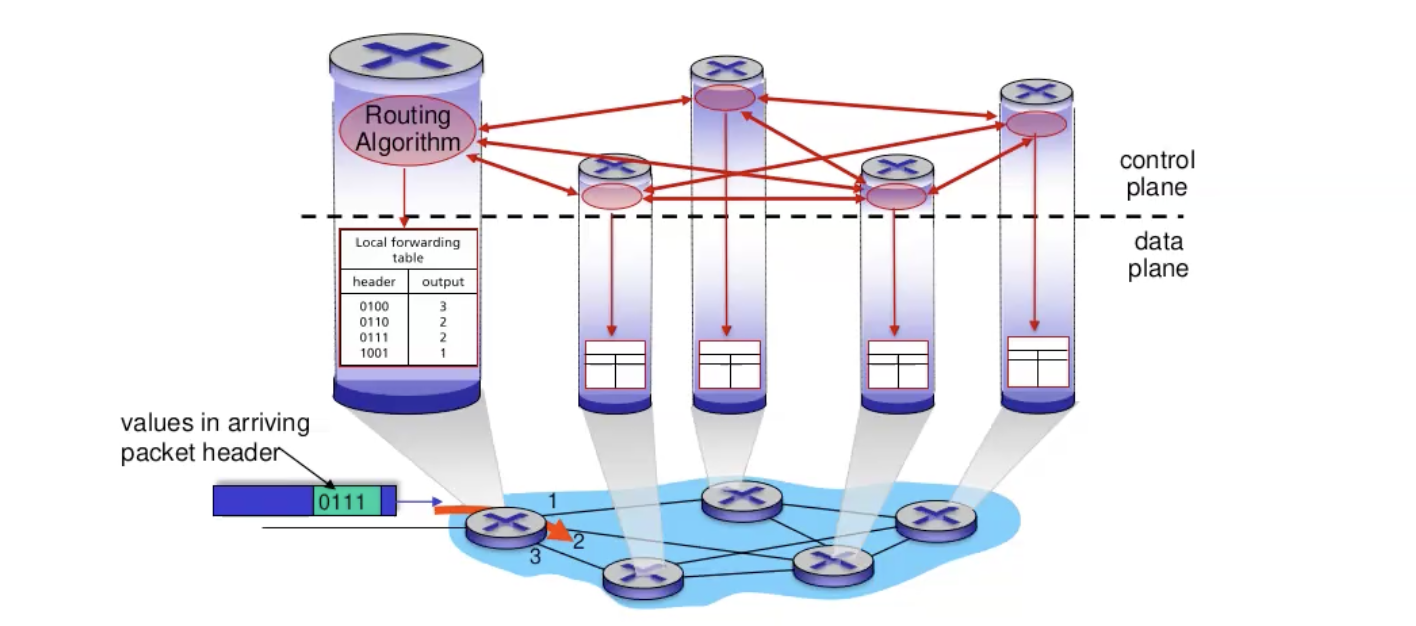
לכל ראוטר יהיה רכיב שמהווה את אלגוריתם הניתוב והוא מתממשק עם מישור הבקרה.
Service model של שכבת הרשת:

עובד בשיטת best effort כלומר לא מבטיח הגעה של הdatagram ותזמון בסדר ההגעה.
פקטה של שכבת הרשת נראת מהצורה:

IP
כתובת IP מהווה אמצעי זיהוי של כל שרת באינטרנט ושל כל ציוד קצה שמחובר לאינטרנט.
כתובת IP היא ייחודית ומוקצית בד״כ באופן אוטומי. בכל בקשה שנשלח לשרת, כתובת ה IP מוצמדת לכל בקשה שתשלח כדי שהשרת ידע לאן להחזיר תשובה. באופן דומה הדפדפן במחשב זקוק לכתובת ה IP של השרת כדי לדעת לאן לשלוח את הבקשה.
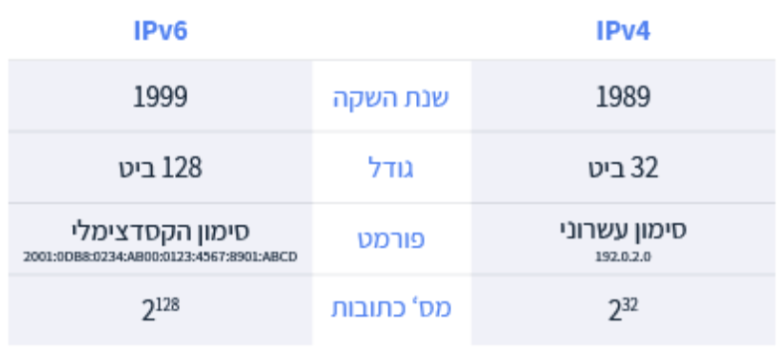
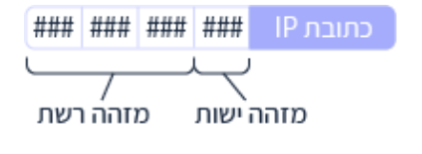
מבנה כתובת ה IP
כל כתובת IP , מורכבת מרצף של ארבעה מספרים ובינהם נקודות. כל מספר נמצא בטווח
אנשים רגילים לא יכולים לדעת איפה אנחנו גרים על סמך כתובת הIP שלנו, אך בחוזה ההתקשרות שאנו חתומים עם ספק האינטרנט, רשומה כתובת הבית שלנו וזאת מקושרת לכתובת ה IP של המחשב שלנו.
ping IP היא פקודה שמאפשרת לנו לבדוק אם שני מחשבים מקושרים זה לזה. הפקודה שולחת הודעות אל כתובת ה IP של היעד שאנחנו בוחרים. אם ההודעות מגיעות ליעד ואם היעד מוכן לענות לנו, נקבל על כל הודעה תשובה ובה משך הזמן שלקח להודעה לעבור בין שני המחשבים.
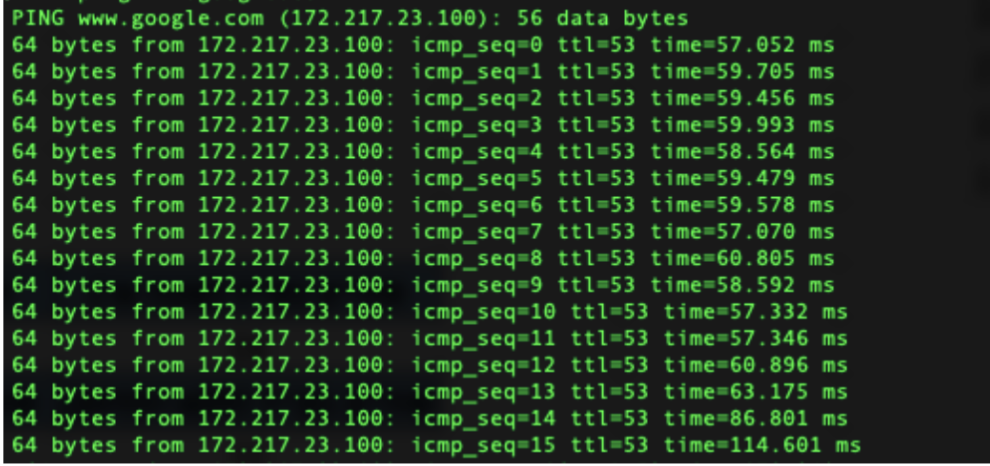
נשים לב שהפרוטוקול שping משתמש בו הוא ICMP שזה פרוטוקול שמיועד לשליחת הודעות שגיאה או metadata כאשר מעבירים מידע
מזהה רשת, מזהה יישות
בכתובות IP מסתתר מידע נוסף שחשוב לפעילות של שכבת הרשת.
כל כתובת IP מכילה את המידע הבא:
א) מזהה רשת- Network ID: לאיזו תת רשת שייכת כתובת ה IP?
ב) מזהה ישות - Entity ID: לאיזה כרטיס רשת, חומרת המחשב המאפשרת למכשיר להתחבר לרשת מחשבים או לרשת האינטרנט (NIC- Network Interface Controller) שייכת הכתובת?
Class Based Addressing in IP
ב IP הזכרנו ש32 הביטים שמרכיבים IP/4 מורכבים ממזהה רשת ומזהה יישות. נשאלת השאלה כיצד מחלקים את הביטים האלה בין מזהה הרשת למזהה היישות בתוך הרשת. אחת הדרכים היא ב CBA.
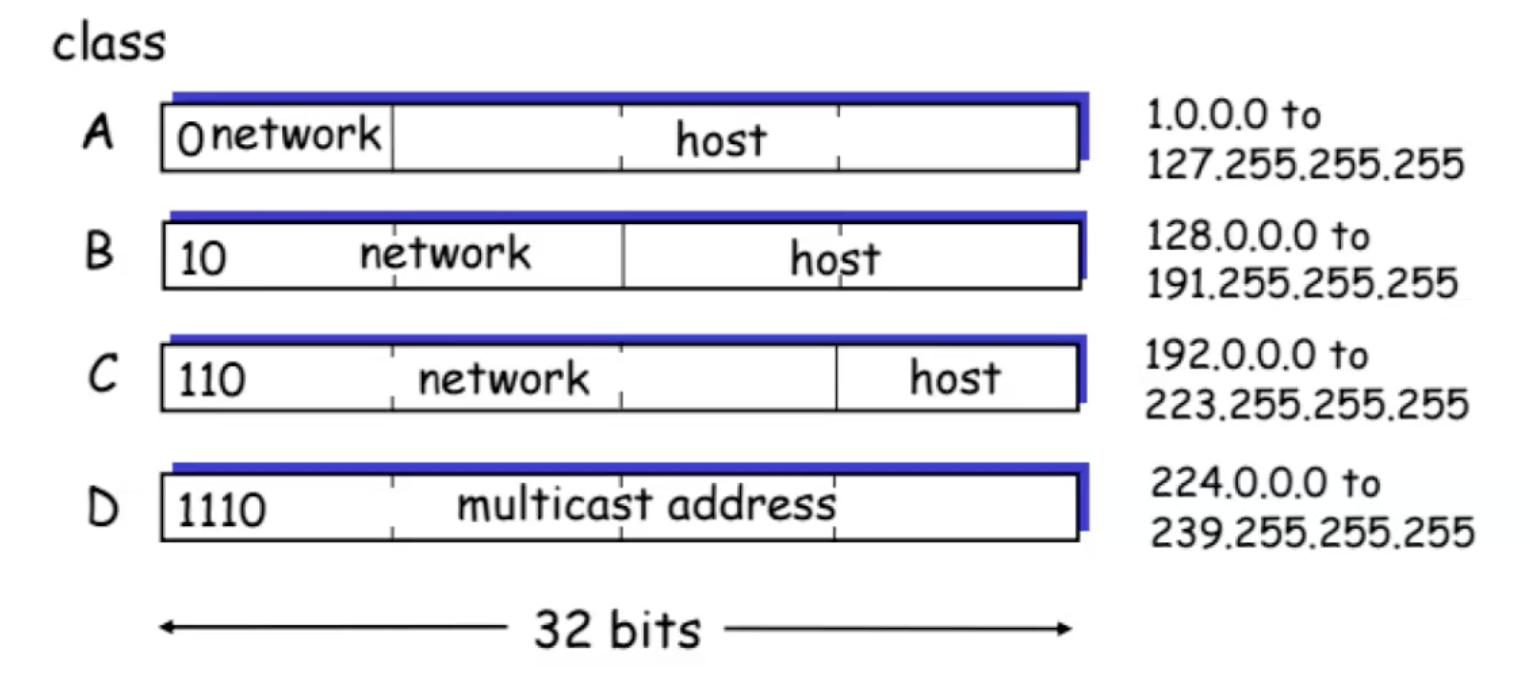
אם ה MSB הוא 0 אז הclass של ה IP הוא A , במצב זה 8 הביטים השמאליים הם מייצגים את מזהה הרשת. אם הביט הוא 1 אז היא שייכת לאחת המחלקות האחרות. במצב שבו השייכות היא ל A יש
ככל שעולים ב Class ככה מתווספים עוד 8 ביטים לרשתות אבל גם מאבדים עוד MSB במספר המחלקה.
היתרון של שיטה זאת הוא בכתובת ip אני יכול לקבל במחיר די קטן את החלוקה של הכתובת ל מזהה רשת ויישות.
החסרון של שיטה זאת הוא שמעבר בין מחלקות מקפיץ את כמות הכתובות מעריכית ולכן יש לזה עלות ״כלכלית״ גבוהה.
כפי שאמרנו לכתובת IPv4 יש
Classless Inter-Domain Routing and Subnetting
לכל כתובת IP נצמיד subnet mask שזה כמות הביטים משמאל שמזהים את הרשת. שאר הביטים יזהו את המחשב בתוך הרשת. הפורמט הוא a.b.c.d/x כאשר x הוא הsm.

השיטה הזו פחות בזבזנית כי היא מאפשרת קפיצות ברמת ביט בודד ולא בית כמו בשיטה המחלקות. כלומר אומנם אנחנו עדיין מוגבלים ברמת הקפיצות בין כמות המחשבים שאפשר לייצג באותה רשת ברמת הקפיצות בין ביט לביט אבל כעת אלו יותר קטנות.
הsubnet mask הוא בעצם מספר בינארי באורך 32 ביטים שכל ביט אצלו מייצג האם הביט בip שייך למזהה רשת או מזהה היישות (ביט דולק משמעותו שייך למזהה היישות אחרת למזהה הרשת). לאחר מכן נתן לחלץ את המידע מהmask על ידי ביצוע bitwise & .
כתובות IP שמורות
שומרים בדרך כלל את הכתובת הראשונה עבור הרשת עצמה והכתובת האחרונה היא עבור broadcast של הרשת.
יש גם מספר טווחים שהוקצו לprivate networks כלומר כתובות של רשתות פנימיות.
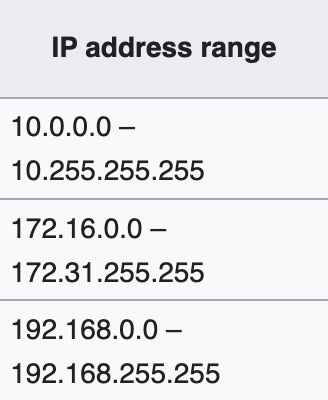
יש גם כתובות מיוחדות כמו 127.0.0.1 שאנחנו מכירים כ loopback.
Destination-base forwarding
בהינתן פקטה, נרצה לדעת כיצד הראוטר מחליט לאיזה ממשק להעביר את הפקטה כדי שתמשיך להתקדם עד להגיעה ליעד.
לשם כך הראוטר יחזיק בתוכו forwarding table עם שתי עמודות. הראשונה תהיה ה Link Interface והשנייה תהיה Destination Address Range שתכיל בתוכו את טווח הכתובות ה IP שמיועדות לעבור לממשק שבעמודה הראשונה. נזכיר שפקטה של שכבת הרשת מכילה כתובת IP של הsource וכתובת IP של הdestination ב תחיליות שלה.

נשים לב שייצוג של טווח בטבלה הוא על ידי סימון ב * את הביטים שברצוננו לאפשר להיות להיות במצב ״חופשי״ כלומר גם כבויים וגם דלוקים. טווח בשורה מסוימת יכול להיות ״ספציפי״ יותר מאחר או להכיל טווח בשורה אחרת. כאשר הראוטר רוצה לקבוע לאן פקטה צריכה ללכת הוא מחפש את האחד שטווח הכתובות המכיל אותו הוא הקטן ביותר (יכול להיות כמה אבל בהכרח יהיה טווח קטן יותר מהשני)
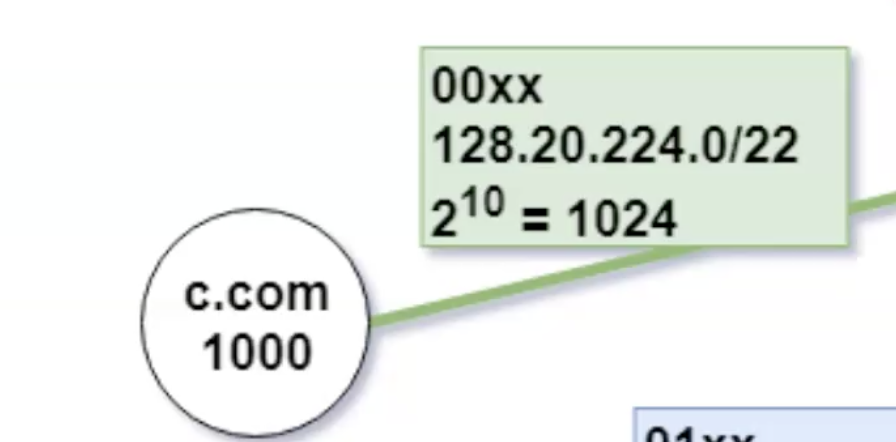
נסתכל על ה ip הבא
בעצם מחפשים את הprefix הארוך ביותר שמתאים לשורה כלשהי בטבלה. אם נסתכל על הכתובת הדוגמה, נראה שעבור שלושת השורות, הבית הראשון מתאים וגם הבית השני. לעומת זאת, הבית השלישי מתאים רק לשורה הראשונה בטבלה כי הוא היחיד שהבית ה5 משמאל הוא 0 ולכן השורה הראשונה מכילה את הprefix הארוך ביותר.
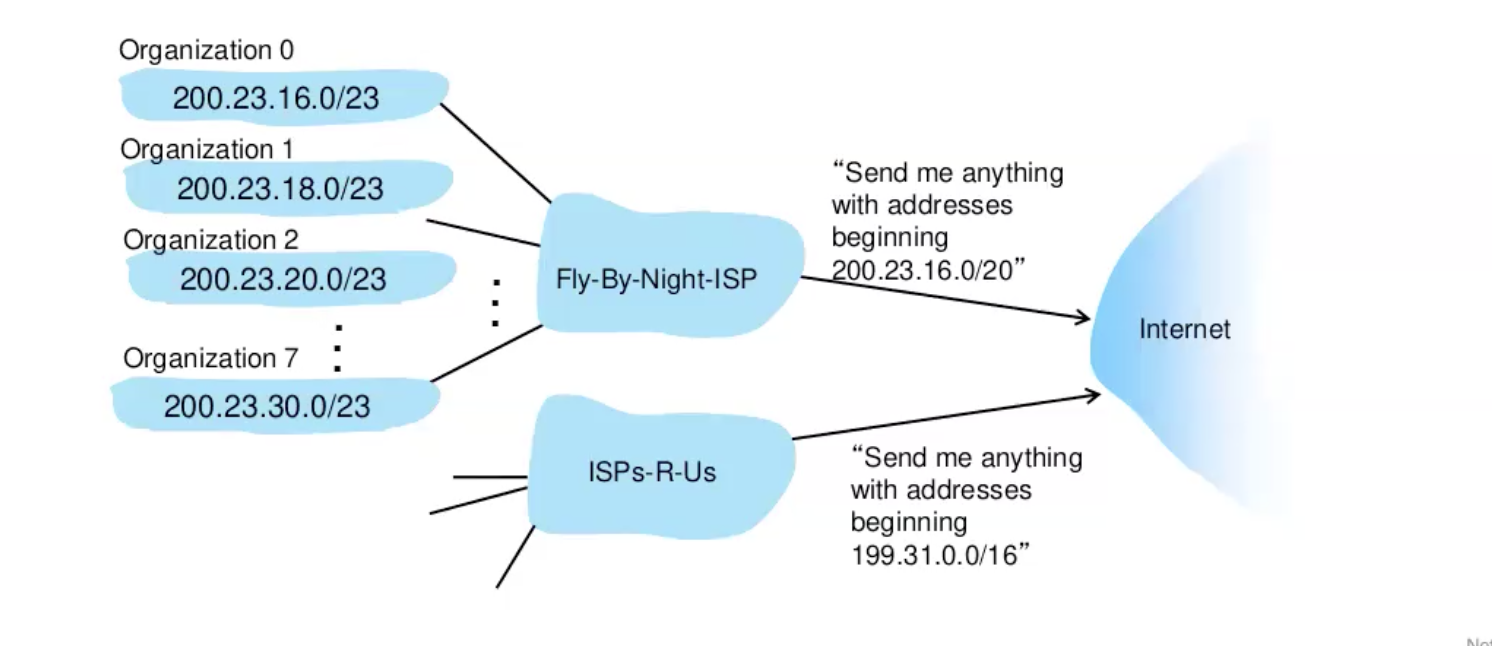
באמצעות הטבלה הזאת ספקי אינטרנט יכולים להשתמש בראוטרים שלהם כדי להעביר מידע לפי הארגונים שנמצאים תחתם ברשת. הקונספט הזה נקרא hierarchical addressing והוא בעצם מאפשר להקצות עוד ביטים למזהה רשת דרך ה mask ואלו יהוו מזהים לארגונים.

״האינטרנט״ בתמונה למעלה מהווה ראוטרים אחרים שמקבלים מידע מספקי אינטרנט על טווחי הכתובות שהם מעוניינים שאותם ראוטרים יעבירו אליהם את המידע. לפי הממשק שממנו באה הבקשה הראוטרים יודעים לבנות את הforward table שלהם.
IP Datagram Format
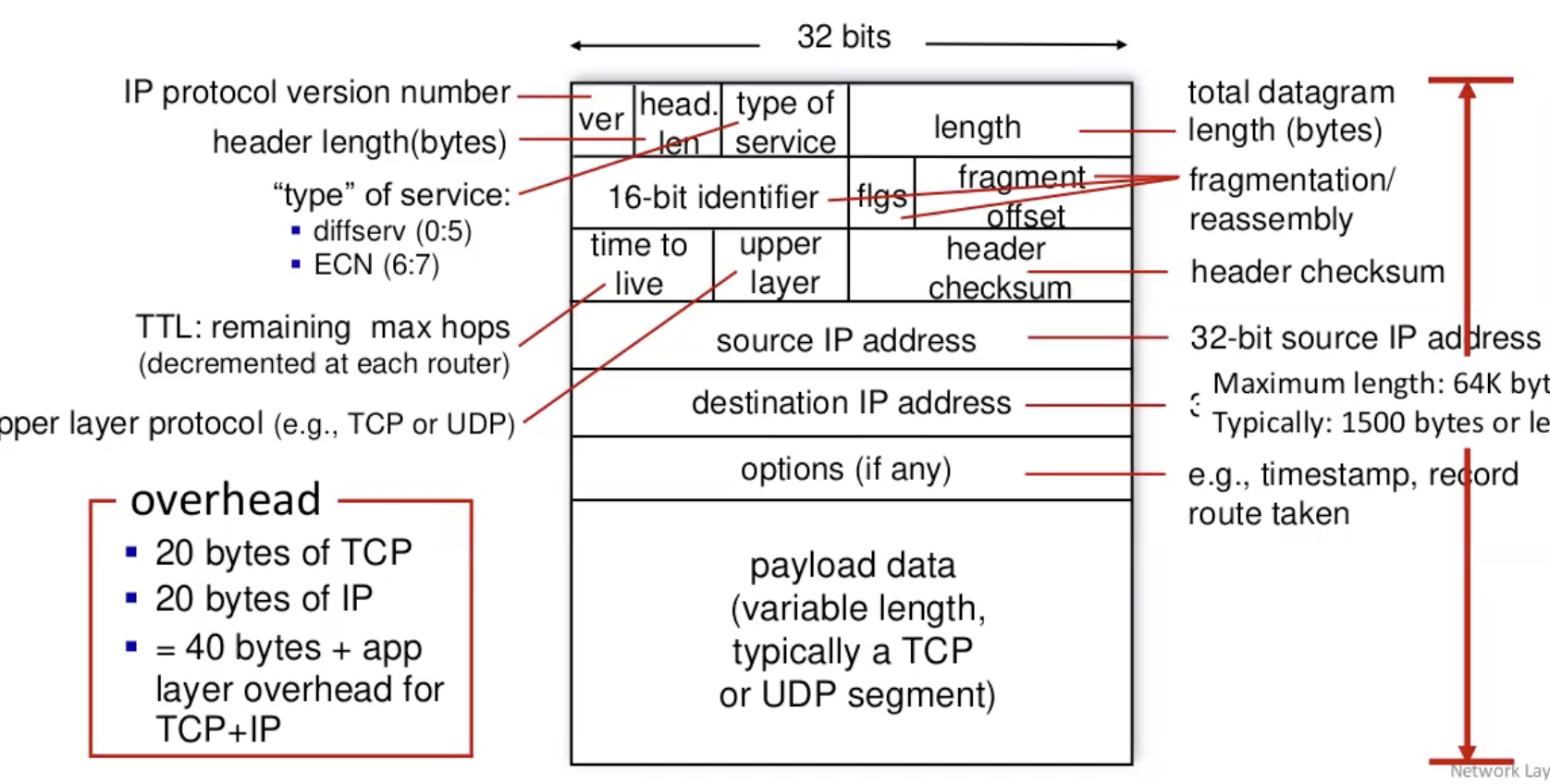
נשים לב שבשכבה זאת נשמר ה offset של הפרגמנטצייה שפרוטוקול TCP מנסה להמנע ממנו.
פרמטר חשוב נוסף הוא ttl שזה נועד למנוע מצב של תנודה אינסופית של פקטה בין הראוטרים.
IP Calculations
שאלה 1
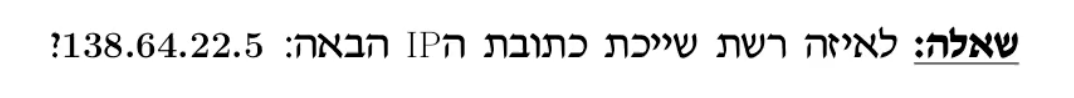
מכיוון שלא ניתן subnet mask אזי מדובר בשיטה המבוססת מחלקות.
הביט השמאלי הוא 1 ומימינו מכובה ולכן הכתובת שייכת למחלקה B. לכן המזהה רשת הוא 138.64 .
שאלה 2

ה subnet mask הוא 23 (כמות הביטים הדלוקים היא 23 מתוך 32). נבצע & בין כתובת ה IP ל subnet mask בבינארית ונקבל
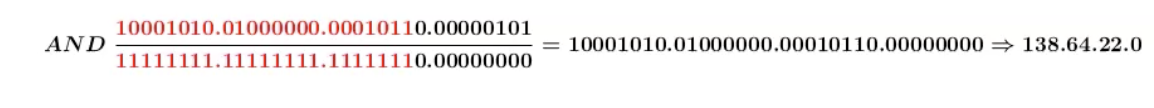
שאלה 3

ראשית נזהה כמה כתובות יש ברשת הזאת לכל היותר
מכיוון שה subnet mask הוא 26 יש 6 ביטים שמייצגים מחשבים בתוך הרשת ולכן יש
101.101.101.65 - 101.101.101.126 מתאימה לנו.
שאלה 4

ברשת שלנו יש 64 כתובות אפשריות. נשים לב, שהספק מעוניין לדעת לכל כתובת לאיזה לקוח היא שייכת. מכיוון שיש 4 לקוחות, הספק מקריב את 2 הביטים הכי שמאליים מהחלק של הכתובת ולא מהחלק של מזהה הרשת, בכדי לזהות את הלקוח. הסיבה ל 2 ביטים היא שאפשר בעזרתם לייצג 4 לקוחות. בלוקי הכתובות ייראו מהצורה
- 101.101.101.64/28
- 101.101.101.80/28
- 101.101.101.96/28
- 101.101.101.101.112/28
נשים לב, שכאשר ספק האינטרנט מפרסם לעולם את הכתובות שהוא מעוניין שישלחו אליו, הוא מפרסם רק את הכתובת הראשונה. כאשר חבילה המיועדת לכתובת ip כלשהי בטווח הזה תגיע לראוטר של ספק האינטרנט, הראוטר יסתכל על 2 הביטים הבאים ולפי זה ידע לאיזה לקוח יש להעביר את החבילה. התהליך שבו ״איחדנו״ מספר תתי רשתות תחת רשת אחת נקרא route aggregation.
שאלה 5

בשלב הראשון ספק האינטרנט יעביר שכל הפקטות עם הdst ip כפי שמצויין בתמונה, יש להעביר את הכתובות האלה אליו.

נשים לב שזה ממשק אחד מבין ה4 כי הנתב חייב להתחבר לאינטרנט. נשארנו עם 3 ממשקים.
אם כן נוכל להקדיש 2 ביטים עבור ניתוב לכל אחד מ3 הממשקים כאשר הממשק השלישי (עם ביט שמאלי מבין ה2 שערכו יהיה 1) יקבל פי 2 יותר כתובות פנימיות, את החצי השני של מרחב הכתובות הפנימיות.
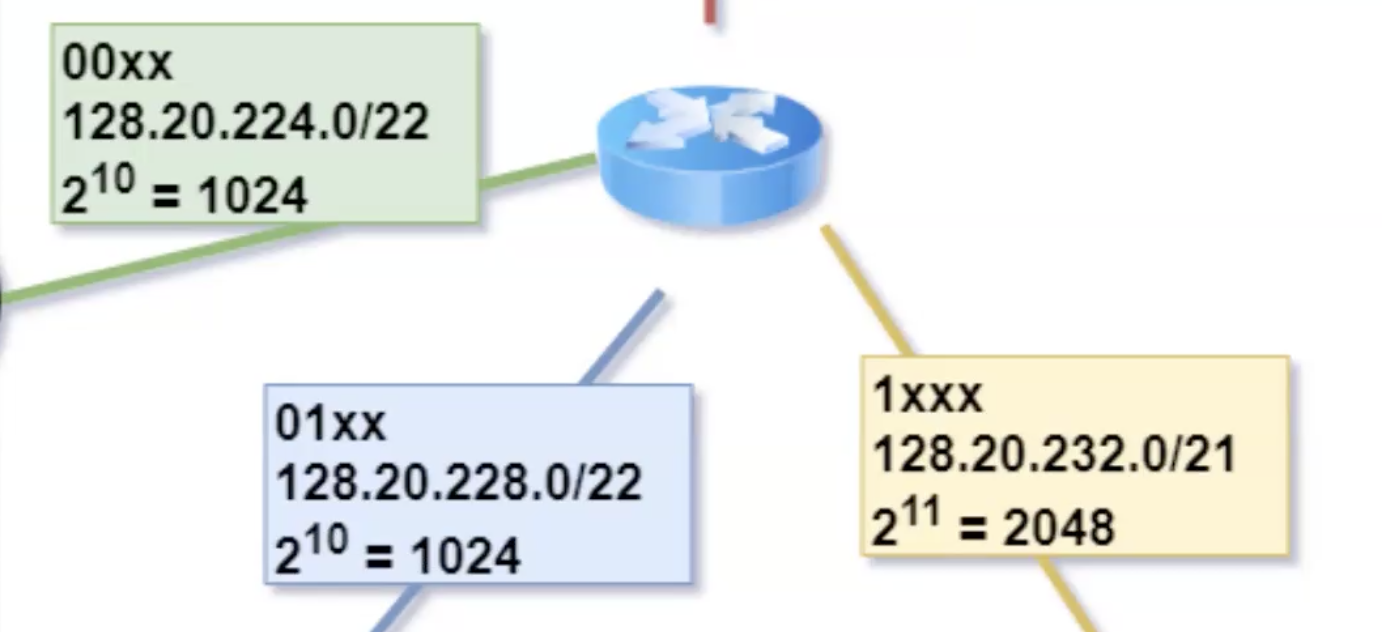
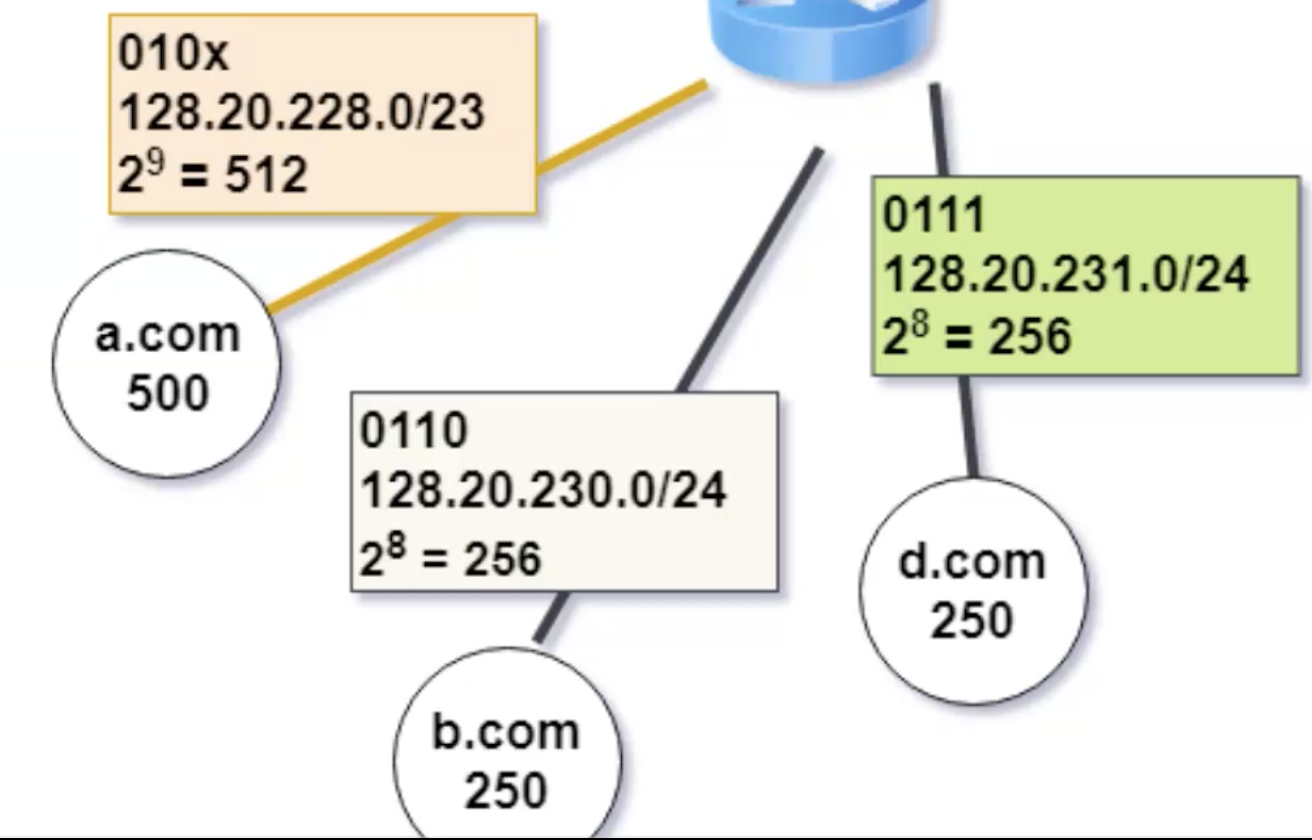
כעת נתחיל להתאים לקוחות לנתבים:
בגלל שיש לנו לקוחות שרוצים פחות מ 100 כתובות נוכל להשתמש בנתב האמצעי (התכלת) ולחבר אותו לנתב נוסף שיהיו לו 3 ממשקים פנויים ולכל אחד מהממשקים נצמיד לקוח
באותו אופן גם לראוטר עם 2048 כתובות
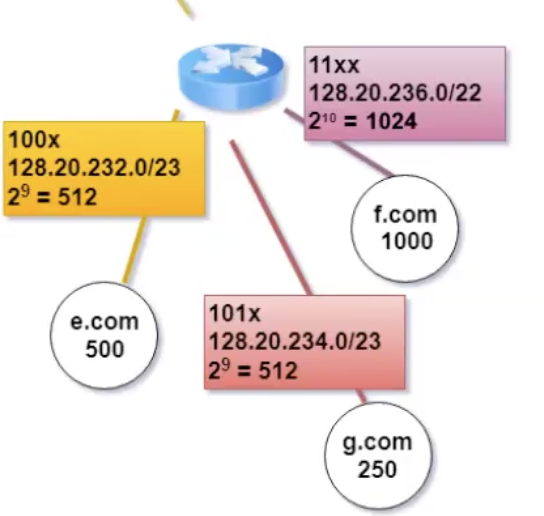
וסה״כ
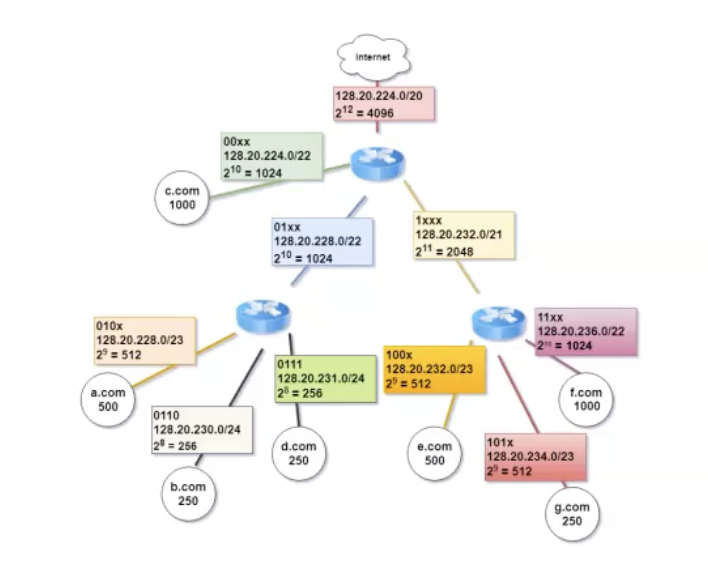

נשים לב שמכיוון שכל כתובת היא מבוססת בינארית צריך לבדוק כמה ביטים צריך עבור לפחות 50 כתובות.
- במקרה שלנו מדובר ב
כתובות כלומר ב 6 ביטים. - לא ניתן פחות, כי הקפיצות הן בינאריות
- לכן, נוכל לחלק את הכתובות ל 4 תתי רשתות.
ICMP
פרוטוקול של שכבת הרשת שמאפשר להעביר errors, pings ו network diagnostics. הודעות ICMP נבנות בשכבת ה־IP, בדרך כלל מחבילת IP רגילה, אשר יצרה תגובת ICMP. IP עוטף את הודעת ה ICMP המתאימה בכותרת IP חדשה, כדי לשולחה חזרה למכונה ששלחה את ההודעה המקורית, ולהעביר את החבילה הנוצרת באופן הרגיל.
Traceroute
באמצעות הפקודה הזאת ניתן לאתר את הנתבים שהמידע עובר בהם כדי להגיע ליעד.

הרעיון הוא כל פעם לשלוח פקטת UDP עם ttl שערכו הוא i כאשר i מייצג את מספר הפקטה ששלחנו.
הפקטה הראשונה תקבל ttl=1 השנייה ttl=2 וכן הלאה. ttl הוא פרמטר שמתעדכן בכל פעם שהפקטה מגיעה לראוטר. הראוטר מוריד ערך זה ב 1 , אם הערך הוא 0 הוא זורק את הפקטה ומחזיר הודעת שגיאה עם פרוטוקול ICMP. לכן עבור הפקטה הi הראוטר ה i יחזיר שגיאה מסוג 11 עם קוד 0 (ttl expired)
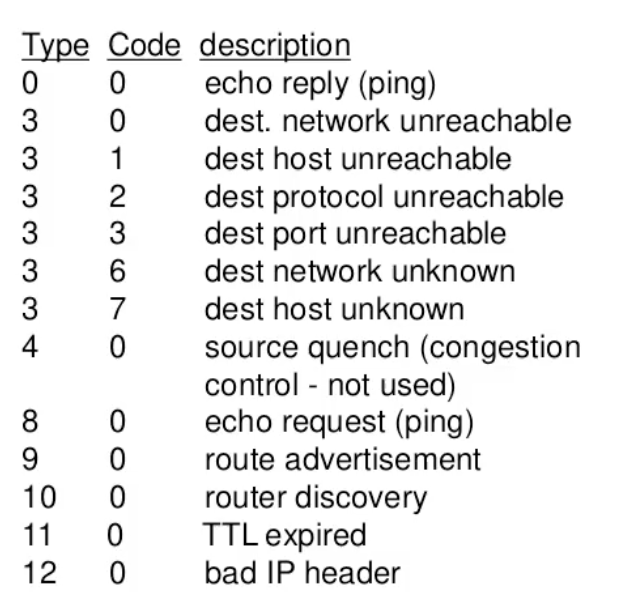
הודעות השגיאה הללו מכילות את שם הראוטר וה ip שלו.
תנאי העצירה הוא הגעה ליעל אבל בגלל שאין port מוגדר שוב יוחזר שגיאת ICMP מסוג port unreachable (type 3, code 3) והפקודה תפסיק לרוץ.
בטרמינל של windows :
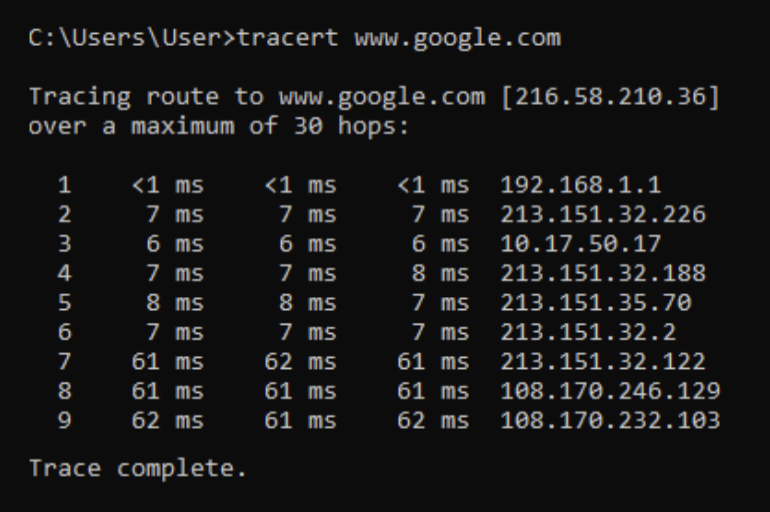
בטרמינל של לינוקס :
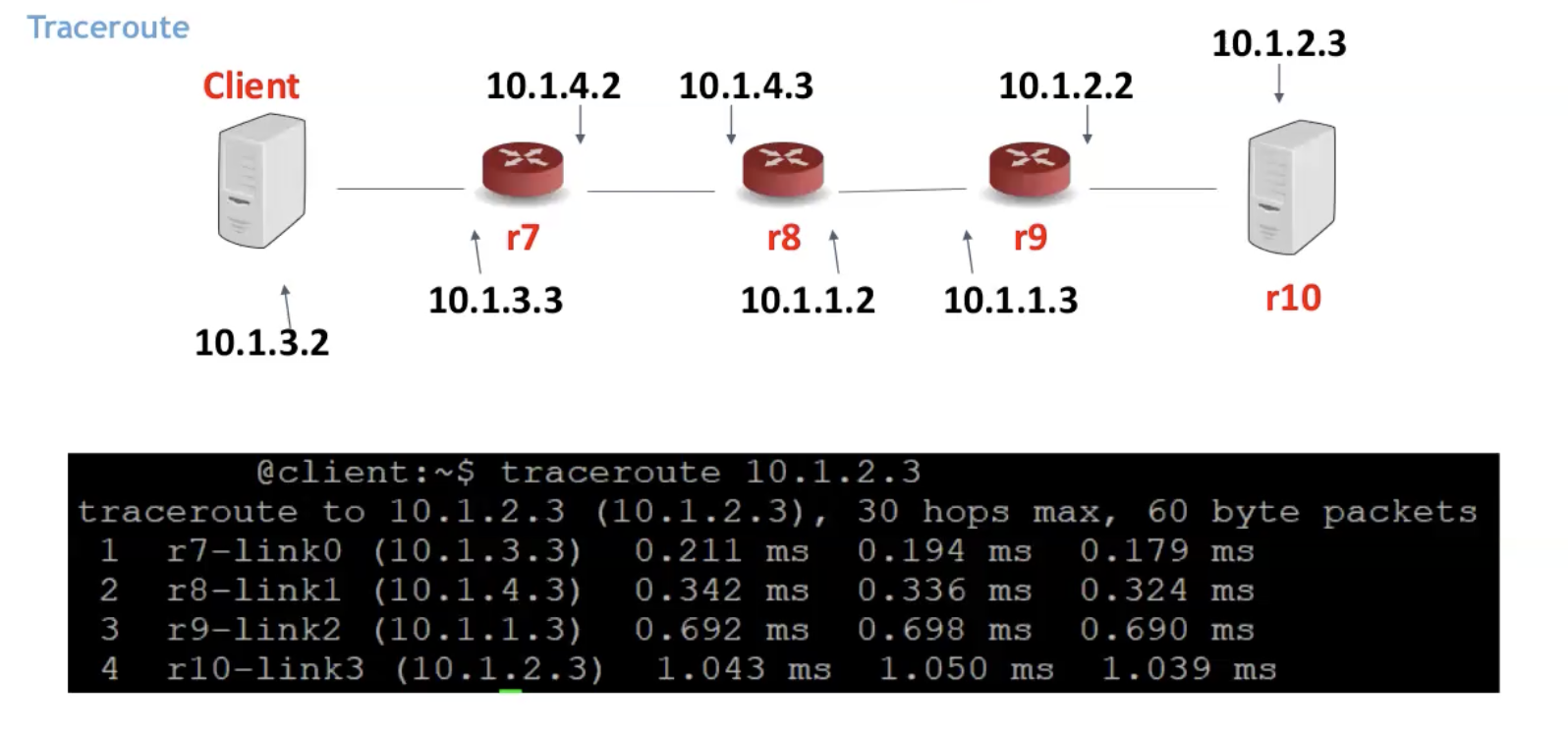
נשים לב שהפקודה גם שומרת את ה RTT.
כמו כן, בלינוקס השגיאה מחזירה גם את מספר הלינק שממנו הגענו (לכן גם בתמונה לכל ראוטר יש 2 כתובות לפי הלינק).
NAT
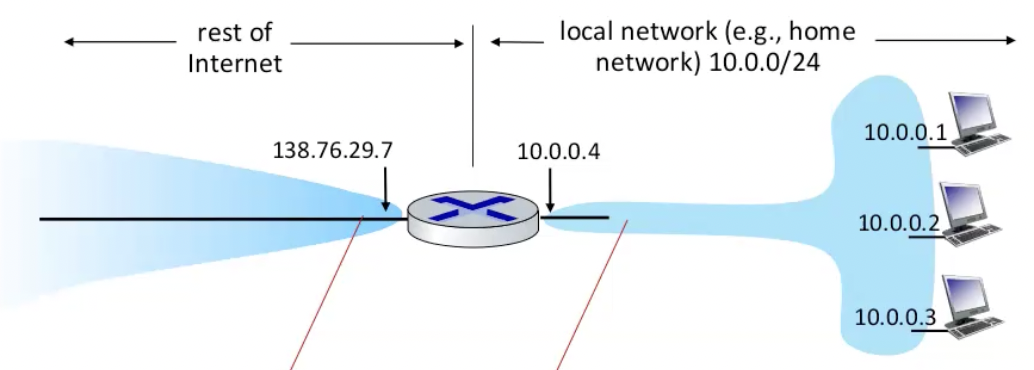
network address translation - בפועל יש הרבה יותר מחשבים מכתובות ipv4 וגם הטכנולוגייה לא תומכת בהעברה מידית ומלאה ל ipv6. לשם כך, משתמשים ב NAT, טכניקת ניתוב שמאפשרת למספר מכשירים ברשת מקומית לחלוק רק כתובת IP אחת ברחבי האינטרנט.
-
דיברנו על כך ש DHCP הוא פרוטוקול שמספק כתובת IP לhost שמתחבר לרשת פעם ראשונה. חשוב להבחין שפרוטוקול זה מספק את כתובות הרשת הפנימיות (מצד ימין בתמונה) בעוד שבאינטרנט הכתובת של כל הרשת הזאת הוא הכתובת 138.76.29.7 (וזה החלק ששכבת הרשת ביחד עם NAT אחראית עליו).
-
כאשר datagram עוזבים את הlocal network , כתובת ה ip שנמצאת ב header היא הכתובת 138.76.29.7. אבל כאשר הdatagram נשארות ברשת המקומית הכתובות ip שלהם ב header רשומות לפי הכתובת הפנימית שלהם.
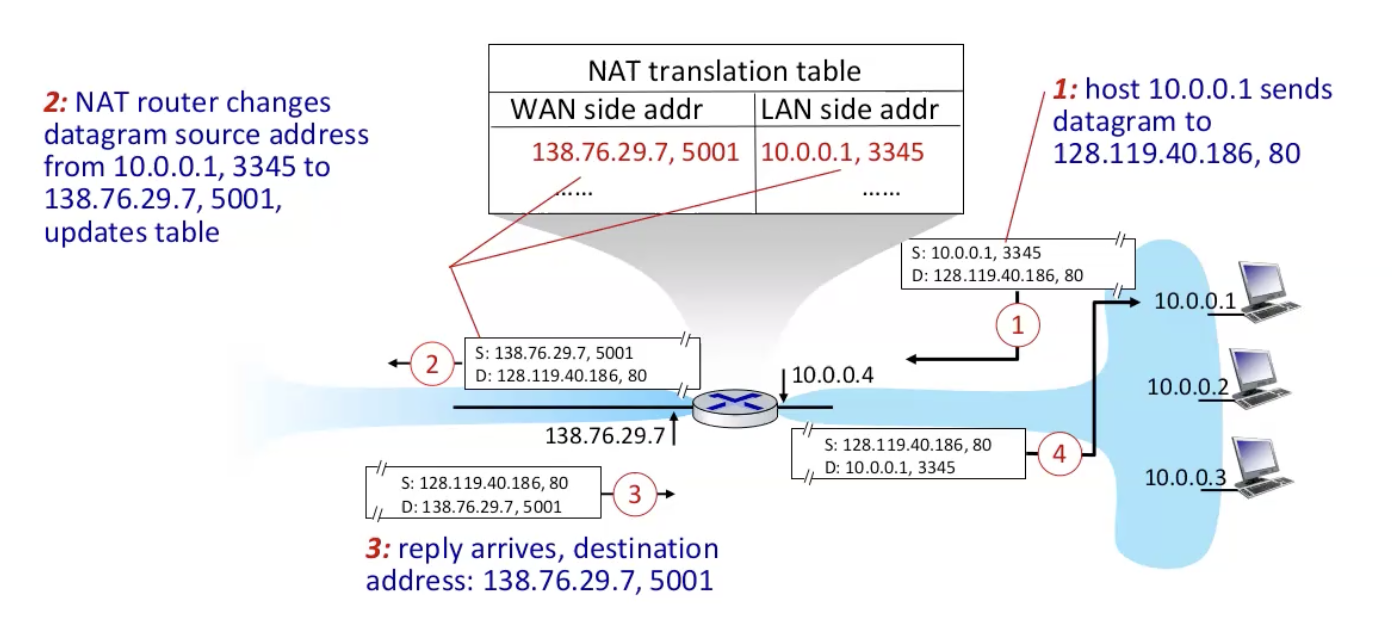
איך תהליך התרגום עובד?
- נניח שאפליקצייה במחשב עם source ip של 10.0.0.1 רצה על port של 3345 ורוצה לשלות datagram לכתובת 128.119.40.186 על גבי פורט 80.
- בheaders של שכבת הרשת רשום ב source ו destination את הכתובות הנ״ל.
- באמצעות subnet mask (השוואת 24 הביטים של הכתובת שלו עם הכתובת של היעד) המחשב הגיע למסקנה שהרשת destination היא לא ברשת המקומית ולכן הוא מעביר את הבקשה לdefault gateway, הוא מגלה את הMAC של ה default gateway עם ARP ומעביר את הבקשה לראוטר בכתובת 10.0.0.4.
- הראוטר, שכבר יודע דרך איזה ממשק להוציא את החבילה באמצעות forward table הולך ל NAT translation table, וממפה בין הכתובת ip והפורט הפנימיים של הרשת המקומית וממפה את זה לכתובת הip הגלובלית שהרשת מכירה ולport שבה הראוטר עצמו מאזין לבקשה. נניח שהכתובת היא 138.76.29.7 על פורט 5001, משנה את הheader ושולחת את הבקשה.
- כאשר מתקבלת תשובה עבור הבקשה זו הראוטר חוזר לטבלה רואה מי הכתובת המקומית שצריכה לקבל את הבקשה ומעביר אליה.
התהליך הזה שקוף לחלוטין לאפליקציה במחשב ששלח את הבקשה
NAT הוא לא פרוטוקול של שכבת הרשת! הוא מעין hack שמאפשר לפתור את הבעיה של מחסור כתובת מסוג IPv4 (שאמורה להפתר עם מעבר ל IPv6 אבל הטכנולוגיה לא מאפשרת מעבר שכזה) ולכן שיטה זאת קצת שנויה במחלוקת שכן היא משנה headers של שכבת הרשת ונותנת לראוטר אחריות נוספת. כמו כן בגלל ההכמסה של NAT נפגעת היכולת לעשות חיבור ישיר (end to end) בין מחשב אחד לאחר ברשת החיצונית כמו בTCP , על ה NAT router לפתור בעיות אלו בעצמו מה שגם מערבב בין השכבות.
NAT Variations
כפי שניתן לראות ב RFC 38489 ישנם מספר סוגים של NAT routers:
(מסמכי בקשה להערות הם סדרה של מזכרים בתחום טכנולוגיות אינטרנט שונות. לרוב, המזכרים מתארים מחקר חדש, חדשנות טכנולוגית או מתודולוגיה המרחיבים באופן כלשהו את טכנולוגיות האינטרנט הקיימות).
- Full Cone - המיפוי הוא קבוע, כל בקשה שתשלח מהip והפורט הפנימיים ימופו לאותו כתובת ip ו פורט חיצוניים. כמו כן כל מחשב אחר ששולח פקטה ל ip והפורט החיצוני שממופים לכתובת פנימיות יגיעו לכתובות האלו (גם אם המחשב ברשת הפנימית לא שלח בקשה).
- Restricted Cone - כמו ה Full, המיפוי קבוע אבל מחשב חיצוני עם כתובת X כלשהי יכול לשלוח פקטה למחשב פנימי רק אם המחשב הפנימי שלח בעבר פקטה למחשב החיצוני בכתובת X. כלומר מניחים שהמחשבים שנמצאים תחת NAT הם מחשבי Clients שלא אמורים לקבל פקטות בלי לבקש זאת מראש. נשים לב שההגבלה היא רק על כתובת IP ולא פורט.
- Port Restricted - כמו Restricted רק שההגבלה ספציפית יותר גם למספרי פורט. כלומר רק אם המחשב הפנימי שלח בקשה לכתובת X בפורט P אז כתובת זאת והפורט הזה יכולים לשלוח בחזרה פקטות. ישנה בעיה שעולה מידית, מה קורה כששני מחשבים נמצאים מאחורי NAT מסוג Port Restricted , איך הם יתקשרו אחד עם השני? שכן, הפורטים שאנחנו נשלח אליהם יהיו שונים בגלל המיפוי.
- j - כל הבקשות מאותו ip ו פורט פנימיים ליעד כלשהו ימופו לאותו ip ופורט חיצוניים. אם המחשב הפנימי ישלח לכתובת אחרת המיפוי יהיה אחר. כמו כן, רק מחשבים חיצוניים שקיבלו פקטה יכולים לשלוח פקטת UDP בחזרה ל internal host.
(לא אעמיק כאן בחשיבות של זה, אבל בגדול זה קשור לנושאים כמו firewall ואבטחה, איך אפשר לדעת שחבילת UDP נשלחת במסגרת חיבור שבוצע בעבר).
Architectures
השיטות NAT הנ״ל יכולות להעלות מספר סימני שאלה כאשר מבינים שברשת יש מספר ארכיטקטורות
- Client/Server - השיטה הקלאסית שאנחנו מכירים, שרת תמיד ער עם IP קבוע בעוד שהלקוחות משתנים.
- Peer 2 Peer - כל מחשב בתקשורת זאת הוא גם שרת וגם לקוח כאשר המערכות קצה הן שרירותיות וה IP של כולם הוא דינמי.
- Hybrid - הלקוח משתף שרת בתוכן שלו והשרת מאפשר ללקוח להתחבר ללקוחות אחרים.
הבעייתיות מתחילה כאשר חלק מהמכשירים מדברים אחד עם השני מבלי שפנו אליהם קודם אבל הם יושבים מאחורי NAT. במצבים מסוימים בקשות שיגיעו פשוט יחסמו בגלל המגבלות של שיטה זאת.
NAT Traversal Problem
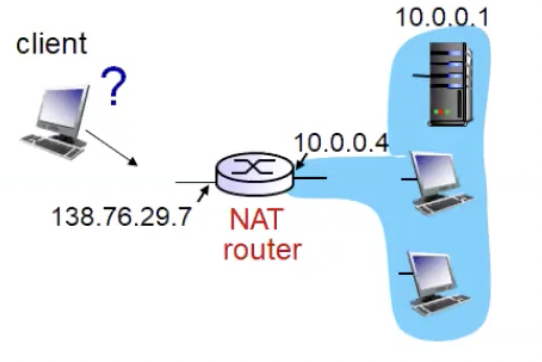
איך פותרים את הבעיות שעולות מהארכיטקטורות הנ״ל? למשל נסתכל על לקוח שרוצה לדבר עם הכתובת 10.0.0.1 שממופת לכתובת חיצונית 138.76.29.7. ב Full Cone היינו מצליחים אבל בכל שיטה אחרת נחסם.
פתרון 1 - השרת שנמצאת מאחורי הNAT יוסיף רשומה סטטית לטבלת ה NAT שבאופן אוטומטי מעבירה בקשות מפורט וכתובת מסויימת למחשב מקומי שנרצה.
פתרון 2 - שימוש בשרת מתווך. מחשבים שמשתמשים באפליקציה מסוימת שולחים בקשה לשרת מה שיגרום למיפוי בnat table ולקוחות שרוצים לדבר עם המחשבים הנ״ל ישלחו בקשות לשרת המתווך והוא יעביר אותם למחשבים וככה לא יחסם.
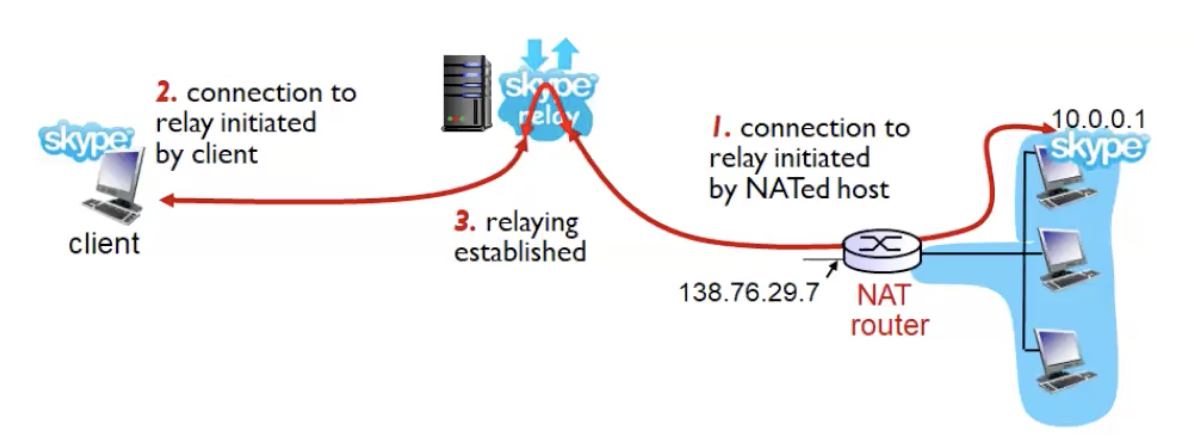
נשים לב שכדי שזה יעבוד השרת עצמו לא צריך לשבת מאחורי NAT. כמובן גם שיש חסרון של איטיות ופרטיות, השרת המתווך לא יכול להבטיח הצפנה של המידע וכו׳.
פתרון 3- Hole Punching
איך מחשבים שלא רוצים תקשורת דרך שרת אבל עדיין יושבים מאחורי NAT יוכלו לדבר אחד עם השני?
אליס ובוב רוצים לתקשר אחד עם השני ללא מתווך, בהתחלה נחזיק שרת Dir שהמטרה שלו היא לייצר חורים ב NAT וגם להחזיק מיפוי בין לקוחות שרוצים לדבר אחד עם השני.
אליס יעביר את הפרטים שלו ל Dir וככה יווצר 'חור' ב NAT (רשומה בטבלה) שלא חוסמת בקשות מDir. אליס מאוחר יותר תרצה להקים חיבור עם בוב ותבקש משרת ה Dir את הפרטים של המחשב של בוב וככה נוצר 'חור' גם בטבלה של המחשב שלה.
הDir יעשה ״היכרות״ בין אליס ובוב על ידי כך שישלח בקשה לשניהם עם הפרטים של השני. כעת אליס יכולה לפנות לבוב, תשמור רשומה שלו בטבלה שלה, אבל החבילה תזרק אצל בוב, למרות זאת במקביל, בוב שולח בקשה לאליס שומר את הרשומה אצלו בטבלה אבל החבילה תגיע הפעם לאליס כי היא שמרה את בוב בטבלה, כעת הם יכולים לתקשר בינהם.
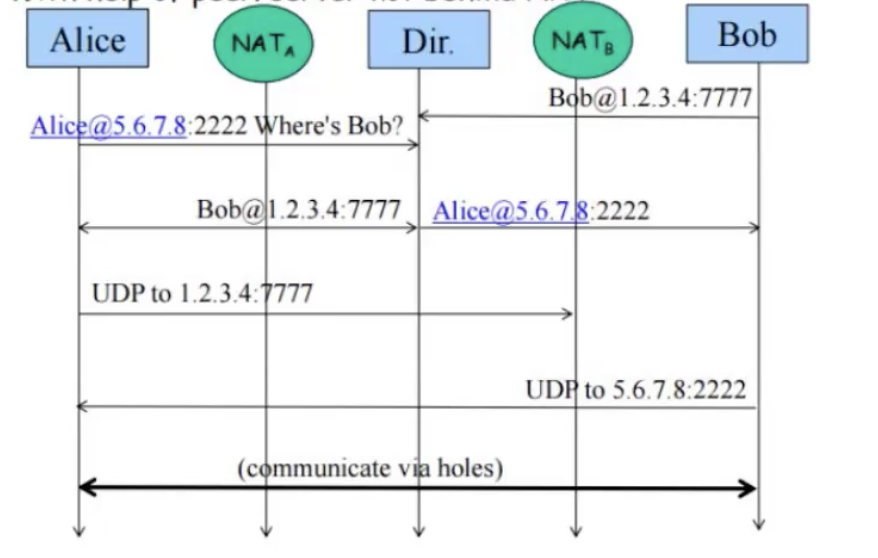
הטכניקה הנ״ל נקראת hole punching.
בעיית הניתוב
כיצד ראוטר שרוצה להעביר בקשה למחשב יעד יודע מה המסלול הכי טוב על גבי הרשת שפקטה צריכה לעבור? זאת אחת הבעיות ששכבת הרשת פותרת. שכבת הרשת ממדלת את הבעיה הזאת באמצעות גרף.
הקודקוד הם ראוטרים והקשתות הם חיבורים בין ראוטרים קרובים (לפי הforward table).
OSPF routing
Open Shortest Path First- פרוטוקול ניתוב שמשתמש באלגוריתם Shortest Path First ונמצא תחת קטגוריית אלגוריתמים מסוג link-state, כלומר כל כל ראוטר צריך להציף את מצב הערוצים לכל הראוטרים ששייכים לאותו AS. ברגע שיש את המידע הזה ניתן לקבוע את העלות לפי מספר פרמטרים כמו bandwidth ו delay אבל החלק המרכזי כאן הוא שניתן לבצע דייקסטרה בגלל שלכל מחשב יש את כל טופולוגיית הרשת שלו ובאמצעות דייקסטרה אפשר לבנות את ה forward table.
הסיבוכיות של אלגוריתמים כאלה לעתים לא מאפשרת לנו להריץ אותם כל פעם בכל ראוטר כי זה כמו גדולה של זכרון וזמן, כמו כן הקשרים בין ראוטרים הם מאוד דינמיים. לכן מחלקים את האינטרנט לAutonomous System, אזור אוטונומי, ובכל אזור ניתן לקבוע באיזה אלגוריתם ניתוב להשתמש. כאשר רוצים לדבר עם נתב מחוץ לאזור האוטונומי שלך צריך להשתמש בפרוטוקול BGP עליו נדבר בהמשך.
Dijkstra's link-state routing algorithms
דייקסטרה הוא אלגוריתם שפותר את בעית המסלולים הקצרים ביותר על גרף ממושקל ופרוטוקול OSPF מבוסס עליו.
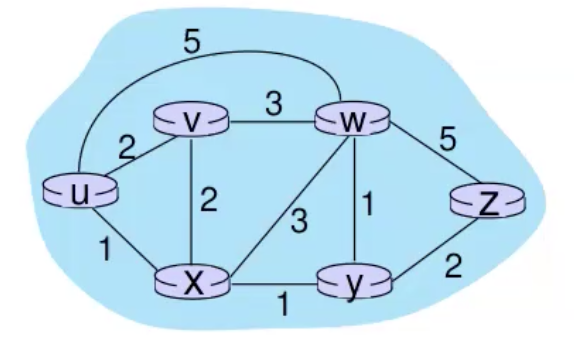
נסתכל על דוגמה-
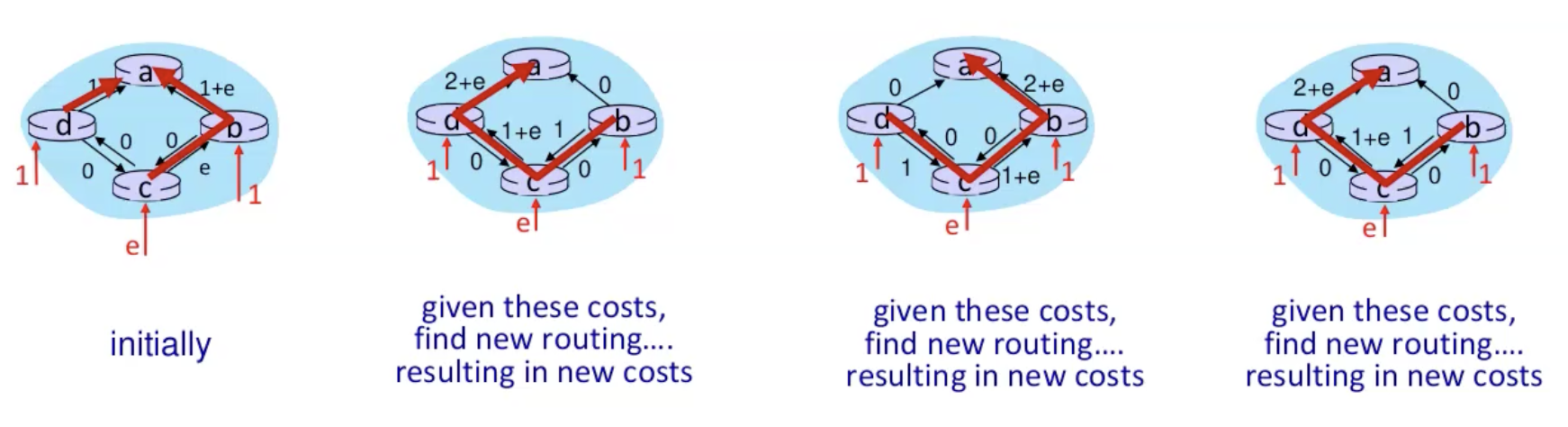
- מתחילים מקודקוד מקור, u ובודקים את השכנים שלו והעלות להגיע אליהן, מעדכנים בטבלה אם העלות להגיע אליהן כעת קטנה ממה שחישבנו קודם לכן(בשלב הראשון הכל
) ולוקחים את המינימלי מבינהם, במקרה הזה העלות של 3 לקודקוד w. - מבצעים כיווץ קודקודים של u ו w וכעת בודקים את השכנים של שניהם. ניתן לראות שהעלות להגיע לx יקרה יותר ולכן אם עושים זאת דרך w ולכן לא מעדכנים אבל להגיע ל v כן קצר יותר כי העלות היא 6 ולכן מעדכנים בטבלה.
- ממשיכים כך עד שמכסים את כל הקודקודים.
- נשים לב שגם שומרים בטבלה מי הקודקוד שממנו הגענו כדי שנוכל לבנות מסלול.
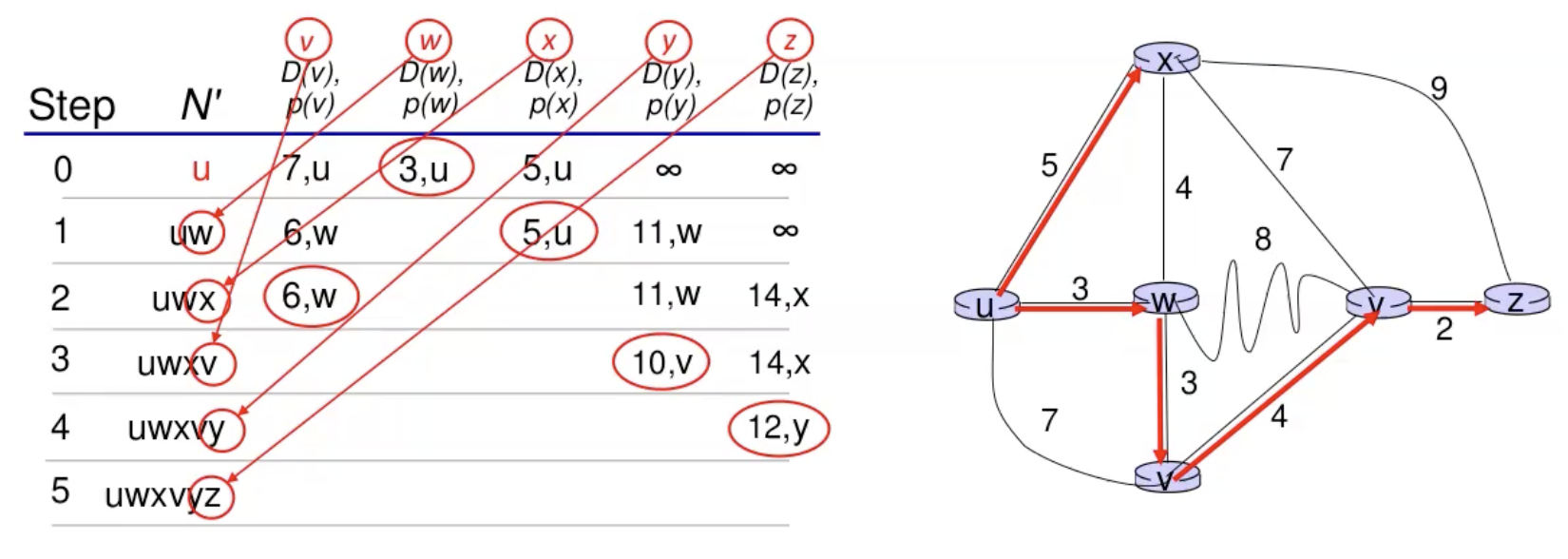
נסתכל על דוגמה נוספת-
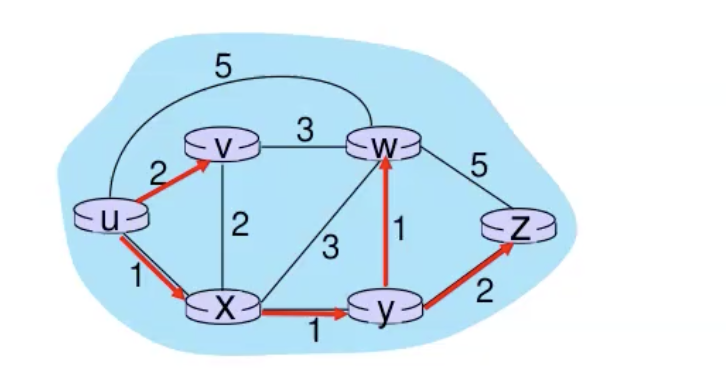
ביצענו את האלגוריתם וקיבלנו את המסלולים הנ״ל, אם נפשט את זה נקבל
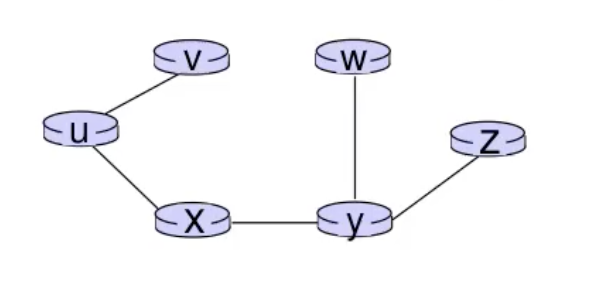
כעת עם הגרף הזה ניתן לבנות את הforward table. בהתאם ליעד, נוסיף את הממשק (השכן) שהכי קצר להגיע ממנו ליעד הסופי. למשל עבור הגרף הנ״ל הטבלה תיראה ככה
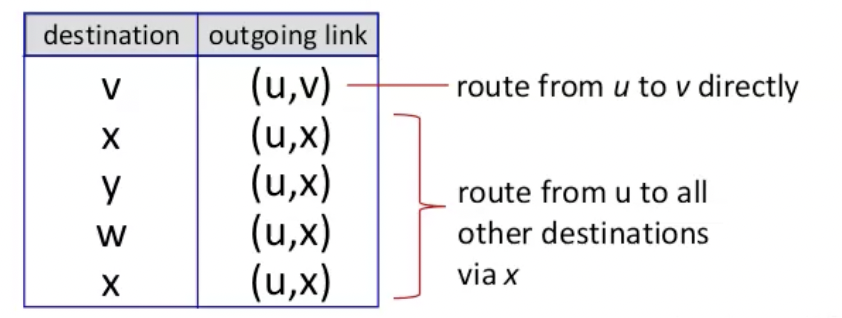
- ל v - הכי קצר להגיע דרכו ישירות.
- ל x,y,w,z - הכי קצר להגיע דרך x ולכן הם ימופו לאותו הלינק.
מה שהראנו עד כה זה לא הפרוטוקול ניתוב אלא רק חלק ממנו שמשתמש בדיקסטרה. נשים לב שכל נתב צריך להריץ דייקסטרה בעצמו וגם בעיות נוספת שעולות:
- איך ראוטר יודע איזה ראוטרים הם שכנים שלו בכלל?
- העלות יכולה להשתנות לפי traffic volume, כלומר אם המשקלים תלוים בעלות התעבורה שעברה בערוץ בזמן הרצת דייקסטרה. המצב הזה יכול לגרום לכך שכל הפקטות עוברות באותו מסלול מה שגורם בכל ריצה לכיוון של המסלול להתחלף
Routing Information protocol
RIP הוא פרוטוקול שמשתמש באלגוריתמים שמבוססים על וקטורי מידע (במקרה הזה distance vector כפי שמיד נראה) כדי לחשב את המסלול בין הראוטרים.
Distance vector algorithm
משתמש במשוואת בלמן פורד ולא מצריך את כל מצב הערוצים בגרף אלא כל ראוטר יעביר לשכניו את וקטור המרחקים שלו. וקטור המרחקים הוא וקטור שמראה לאן הם יודעים להגיע ובאיזה עלות. נזכיר שמשוואת בלמן פורד אומרת
כלומר העלות המינימלית מ x ל y היא המינימום מבין העלות של x להגיע לשכן שלו v + עלות ההגעה מ v ל y.
נסתכל על דוגמה שבה כל הקודקוד x,v,w מדווחיםל u את העלות המינימלית שלהם לz
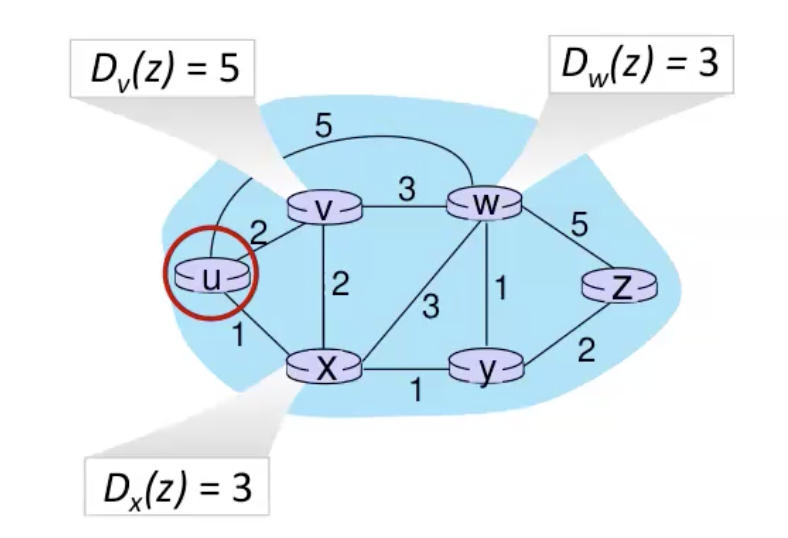
מתקיים
- נשים לב שבשיטה הזאת נוכל להגיע למצב של מעגלים כי אין לנו מידע על כל הגרף.
- כמו כן, גם כאן אם המידע משתנה קודקודים צריכים לעדכן את שכניהם בוקטור המעודכן אבל זה דורש פחות עדכונים מאשר להריץ דייקסטרה מחדש.
נסתכל על דוגמה נוספת-
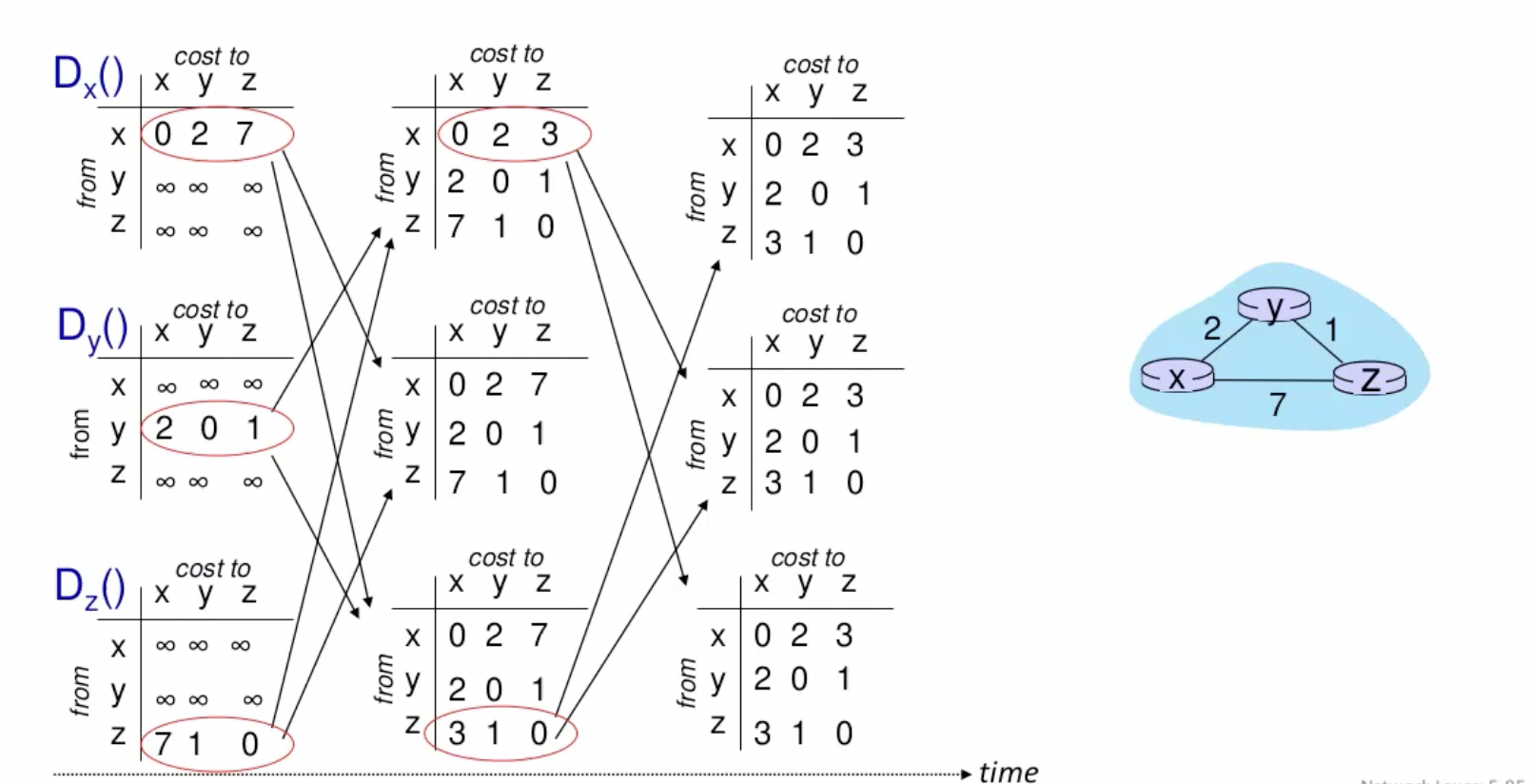
- ניתן לראות שוקטור המרחקים של x, y, z מכיל רק את המרחקים לשכנים שלהם בהתחלה ובכל האחרים שם
. - בשלב הראשונים כל אחד מדווח את וקטור המרחקים שלו לשני שכניו. הם מריצים את משוואת בלמן פורד וניתן לראות שכתוצאה מהרצת המשוואה וקטור המרחקים של x השתנה וגם של z.
- כתוצאה מהעדכון שניהם שולחים את וקטור השכנים המעודכן לשכנים שלהם (x, y עבור z ו z, y עבור x) , y לא שולח מחדש כי הוא לא עדכן.
- כעת כל מי שקיבל את וקטור המשתנים המעודכן, מריץ בדיקה ורואה ששום דבר לא השתנה והאלגוריתם נעצר.
link cost changes:
כפי שאמרנו קודקודים שעלותם משתנה מעדכנים את השכנים שלהם והם צריכים לחשב את הוקטור שלהם מחדש. נשים לב לתופעה מעניינת ״חדשות טובות מתפשטות מהר״. נדגים למשל עם הגרף הבא:
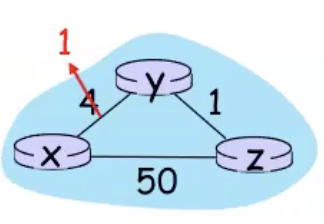
- בהתחלה y מזהה את השינוי ומעדכן את הוקטור שלו.
- לאחר מכן , y מתריע על כך ל z שמשנה גם הוא את העלות שלו ל x ושולח הודעה לשכנים.
- y מקבל את המידע והעלות שלא לא משתנה אז הוא מפסיק להפיץ.
אבל כמו שחדשות טובות מתפשטות מהר ככה גם ״חדשות רעות מתפשטות לאט״:
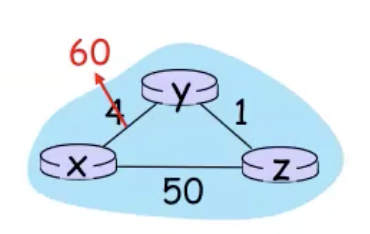
- y רואה את השינוי אבל רואה שz מגיע ל x בעלות 5. מסיבה זאת y מודיע לz שהעלות החדשה שלו לx תהיה 6 דרך z.
- z מזהה שהעלות לx דרך y עולה 6 אז z מחשב מחדש שהעלות שלו היא 1 לy + העלות מ y ל x שזה 6 כלומר סך הכל 7.
- y מזהה את העלות החדשה מ z ל x כלומר 7 ומחשב מחדש עלות של 8.
- התהליך הזה חוזר שוב ושוב עד שהעלות עולה על 50 , רק בשלב הזה z ו y יבינו שהמסלול בכלל ל x הוא מצד השני.
התופעה הזאת נקראת count to infinity
אז איך RIP משתמש באלגוריתם הזה?
- המשקלים בין הקשתות הם תמיד 1.
- כל 30 שניות שולחים לשכנים את וקטור המרחקים גם אם הוא לא השתנה.
- אם אחרי 180 לא התקבל עדכון משכן, מבחינת אותו ראוטר הקשת כבר לא קיימת ומעדכנים את הטבלה כאילו הוא לא קיים.
- כדי להמנע ממצב של count to infinity משתמשים בשיטה שנקראת poison reverse, בשיטה זאת מגדירים שהמרחק הכי רחוק למסלול הוא 16. כלומר מגבילים את אורך המסלול הארוך ביותר להיות 16 וככה גם יודעים שזה הcount to infinity הארוך ביותר האפשרי.
חישובים בבעיות הניתוב
נסתכל על הגרף הבא-
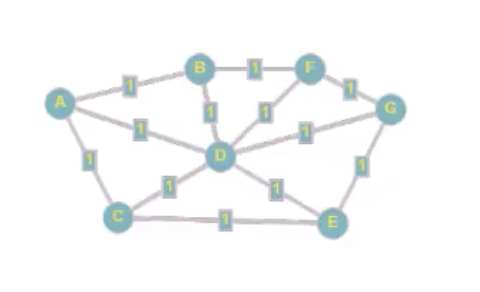
הגרף מכיל את הנתונים הבאים:

- A רוצה להוריד קובץ בגודל 5KB מ G ב HTTP1.1. מה הנתיב שיעברו בין החבילות בעזרת RIP?
- A רוצה להוריד 2 קבצים מ G בגודל 3KB כל אחד באזרת OSPF ב HTTP1.1.
- אותו הדבר אבל הפעם D הוא פרוקסי.
נבין כיצד ניגשים לבעיה הזאת. ראשית, מכיוון ש RIP הוא פרוטוקול מסוג Distance Vector (DV) אזי כל נתב לומד את המרחקים לכל היעדים דרך שכניו. בRIP אנחנו מעדיפים את המסלול הקצר ביותר מבחינת מספר הקפיצות. לאחרמ ספר סיבובים תחנה A תלמד מתחנה D שהיא יכולה להגיע דרכה ל G במסלול הקצר ביותר.
נזכיר שבמהלך השידוך היחס בין גודל החלון וקצב השידור מתהפכים בהתאם לנוסחה
אם נציב לפי הנתונים שקיבלנו יתקיים
- המכפלות פי 2 זה בגלל שעוברים שתי ראוטרים עד שמגיעים ליעד ובחזרה. A ל G דרך D ובחזרה.
- כלומר, כאשר גודל החלון גדול יותר מ4 חבילות. אבל, יש לנו סך הכל 5 חבילות לשדר (כי הקובץ הוא 5 וה mss הוא 1) כך שלא נגיע לזה.
- סך הכל שידרנו 3 חלונות ולכן הזמן כולו היה
כעת לסעיף השני, משתמשים כעת ב OSPF כלומר צריך לחשב את משקלי הקשתות, השהיית ההתפשטות לכל קשת. נקבל:
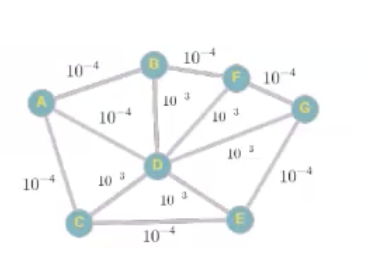
כעת המסלול הקצר ביותר הוא
נשים לב, שהורדת המשאב הראשון תהיה בעזרת החלון החילון והשני בחיבור ואילו הורדת המשאב השלישי תהיה בעזרת החלון השלישי בלבד.
לגבי הסעיף האחרון, כעת יש פרוקסי, אזי A יפתח חיבור TCP מול הפרוקסי ויבקש את המשאב ממנו. D יפתח חיבור נפרד מול G ויבקש את המשאב. יוריד את המשאב ואז יעביר אותו ל A.
BGP
Border Gateway protocol הוא פרוטוקול ניתוב בין AS.
- בתוך כל AS יהיה BGP Router. ראוטרים מסוג זה שיהיו שכנים יחליפו בינהם הודעות בחיבור TCP שהוא semi permanent.
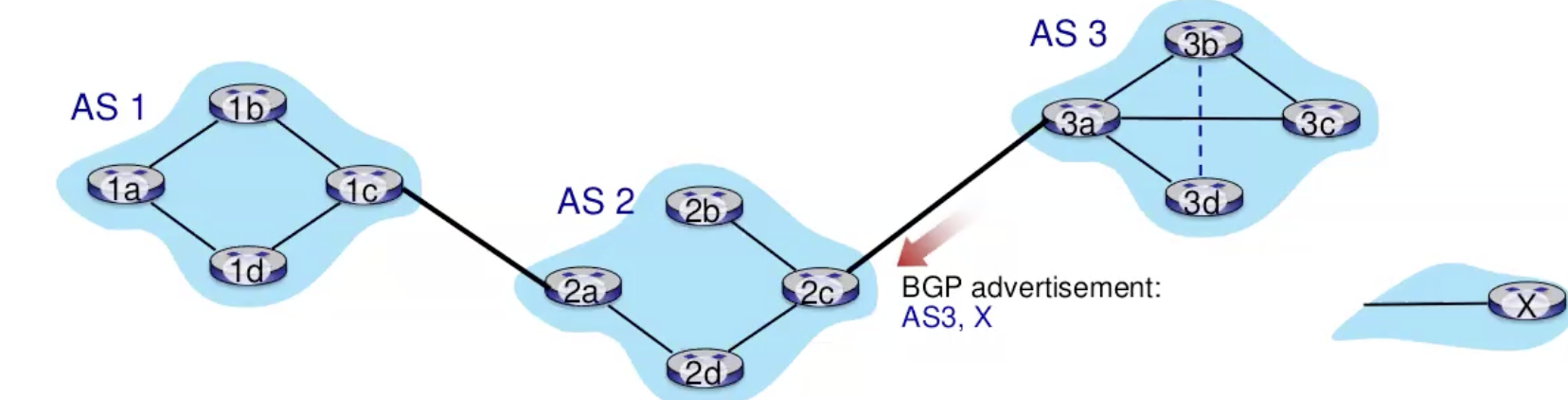
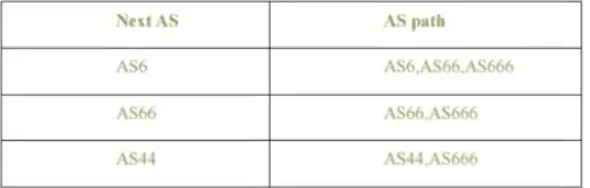
- AS3 מפרסם דרך 3a שהוא ה Border gateway לשכן שלו AS2 שכדי להגיע לראוטר x עליו להגיע ל 3a ומשם זה יגיע ליעד.
- במילים אחרות, AS3 מבטיח ל AS2 שדרכו המידע יגיע לx.
- 2c שהוא הborder gateway של AS2 צריך לקבל את המידע ולדווח אותו לכל הראוטרים בAS2 (זה נקבע מראש ב policy של AS2). כמו כן בpolicy נקבע שראוטר גבול נוסף של AS2 שהוא 2a צריך לפרסם את המסלול (AS2,AS3,x) ל AS1.
- אין צורך לפרסם אם אני מופיע בתוך המסלול.
- באותו אופן ש AS2 פרסם ל AS1 את המסלול גם AS3 יכול לפרסם את המסלול ל AS1 לפי המדיניות.
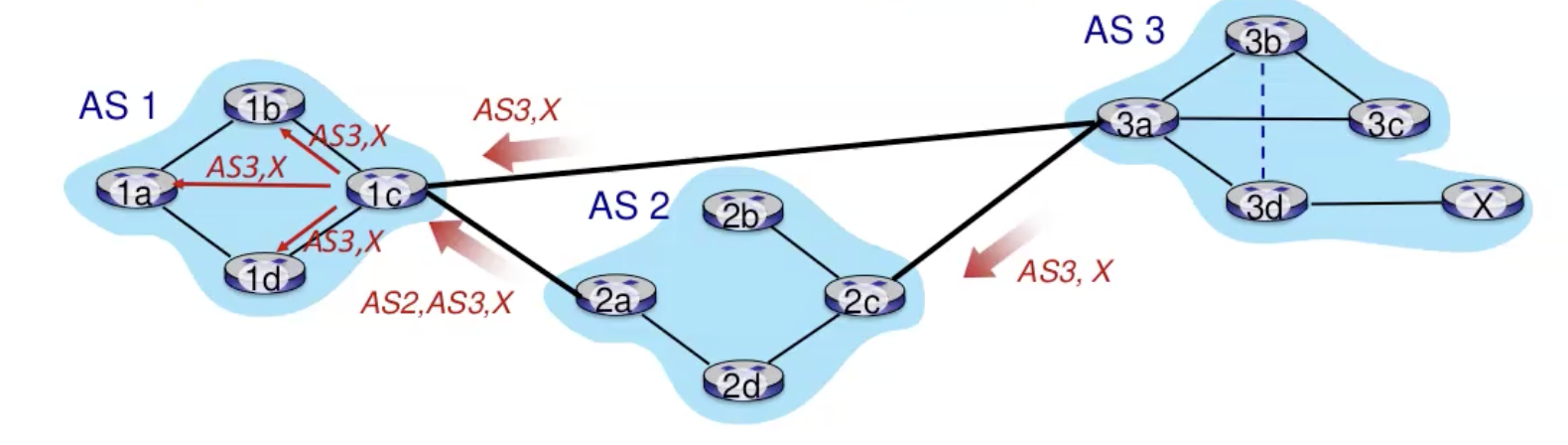
- במצב זה AS1 בוחר את המסלול שמתאים ל policy שלו (לאו דווקא הקצר ביותר) ואת מה שבחר יפרסם הלאה, במקרה הזה בחר את AS3,x.
גם את הAS עצמם נוכל לחלק לתתי קטגוריות
- provider network
- customer network
אלו מקיימים בינהם יחסי גומלין:
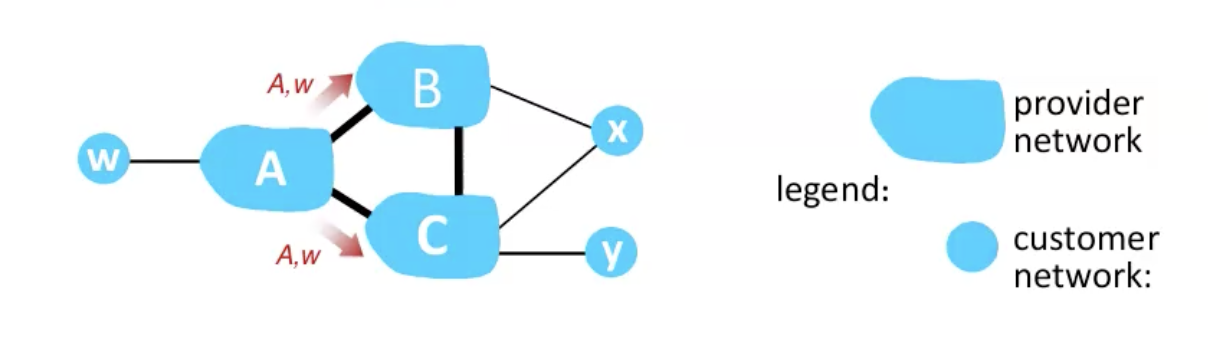
על בסיס היחסי גומלין האלה רשתות יחליטו האם לפרסם מסלולים או לא. למשל כאן B לא יפרסם ל C שניתן להגיע ל w דרכו ו x לא יפרסם לאף אחד כי הוא ״לקוח״ של C.
- A,B,C הם providers
- x,w,y הם customer
- ל x יש שני providers.
חוקי publish של BGP:
- customers משלמים לProvider
- בין Peers אין תשלום.
- אם הsource (מי שפרסם אליי) הוא לקוח - נפרסם.
- אם הsource הוא peer/provider: נפרסם רק ל customers.
אין ולידציה על advertisements מה שיכול לגרום לאנשים לפרסם שהם מחזיקים בכתובות שהם לא באמת מחזיקים.
דוגמה: