שכבת האפליקציה
שכבת היישום (באנגלית: Application) נקראת גם: שכבת התוכנה או שכבת האפליקציה. היא השכבה השביעית והעליונה של מודל ה-OSI והחמישית במודל TCP/IP. היא ממונה על אספקת שירותי הרשת לתוכנות בהן משתמש משתמש הקצה. שכבת היישום משתמשת בשירותיה של שכבת הייצוג של מודל ה-OSI ואינה מספקת שירותים לאף שכבה אחרת במודל ה-OSI.
שכבת היישום היא זו הקובעת את סוג התקשורת בין מחשבים. למשל, היא קובעת האם מדובר בתקשורת "שרת–לקוח" (client-server) שבה מחשב אחד (השרת) מספק נתונים לאחר (הלקוח) - כמו בגלישה באינטרנט, או שמדובר בתקשורת "קצה לקצה" (peer to peer), שבה כל אחד מהמחשבים הוא גם שרת וגם לקוח - כמו ברשתות שיתוף קבצים.
DHCP
Dynamic Host Configuration Protocol (DHCP) הוא פרוטוקול client/server שמספק באופן אוטומטי ודינמי, את הכתובת IP של host כאשר הוא מתחבר לרשת בפעם הראשונה.
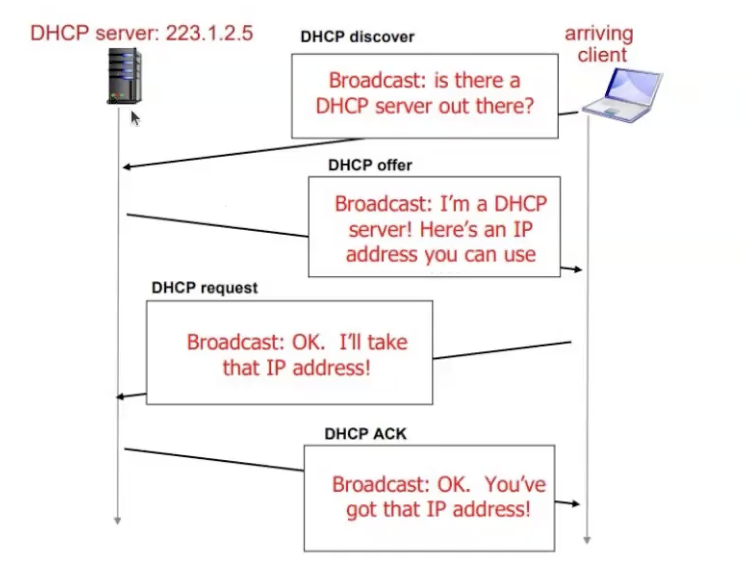
באופן כללי הפרוטוקול עובד באופן הבא:
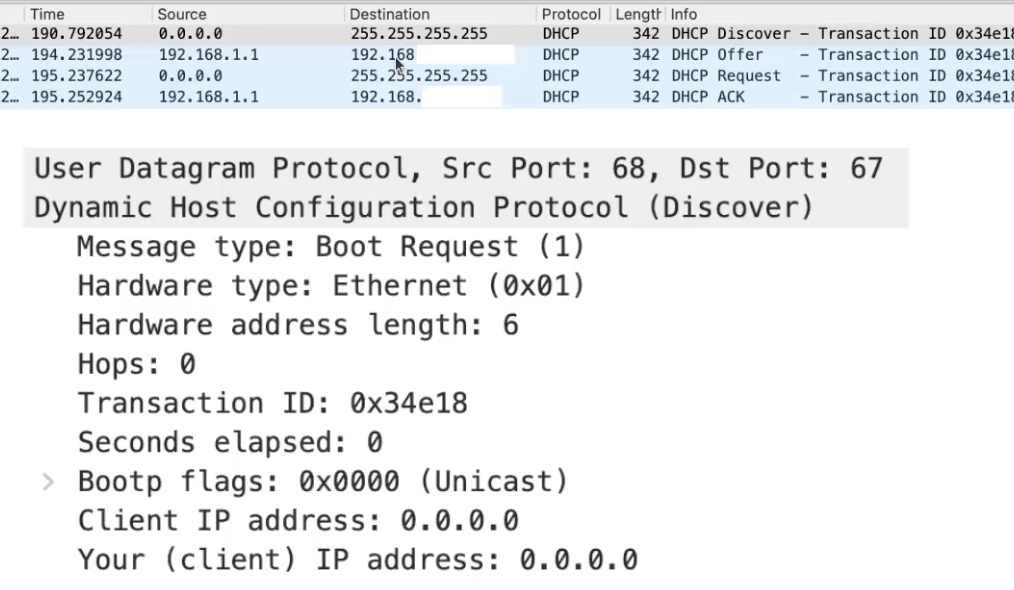
א) שליחת broadcast מסוג DHCP discover
ב) שרת ה DHCP מגיב עם DHCP offer
ג) הhost מבקש כתוב IP עם DHCP request
ד) השרת שולח את הכתובת ו DHCP ack
שרת ה DHCP מביא מידע קונפיגורטיבי נוסף חוץ מה IP שמוקצה לרשת החדשה.
א. הכתובת של הראוטר הראשון שקופצים אליו מחוץ לרשת המקומית במידה וצריך.
ב. שם וכתובת של שרת הDNS
ג. network mask שגם עליה נדבר בהמשך.
DHCP עובד בפרוטוקול UDP ולכן הוא connectionless לכן צריך להצמיד מזהה להודעה כדי שמי שמקבל את ההודעה ידע שהיא רלוונטית אליו בשכבת האפליקצייה.
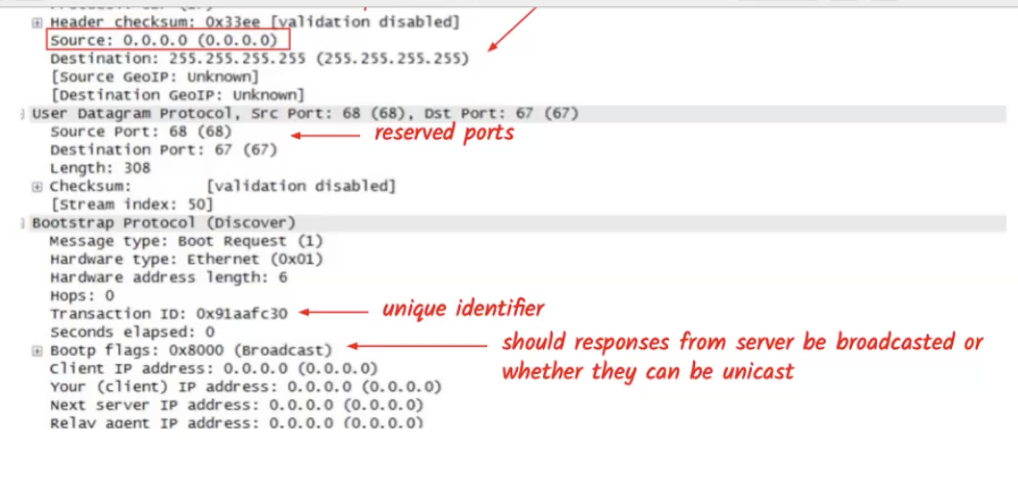
ניתן לראות שבשליחת ברשה ראשונית ה source IP הוא עדיין

השרת שולח תגובת Offer ב Broadcast עם המזהה הספציפי שדיברנו עליו מקודם והכתובת IP המוקצת.
ברגע שהhost מחליט להסכים לקבל את ה IP הוא מבקש גם מידע נוסף
ההודעת Offer בדוגמה למעלה הייתה ב broadcast אבל היא גם יכולה להשלח בבקשת Unicast . במצב זה השרת שולח בקשה ל IP שהוא עוד לא הקצה למחשב החדש שהתחבר
אם קיימים שרתי DHCP ברשת המקומית בעלי כתובת פנויה לחלוקה, הלקוח יקבל חבילת offer עם כתובת IP מכל אחד מהם (בהנחה שאין חסימה של מעבר חבילות DHCP בין השרת ללקוח, למשל על ידי חומת אש).
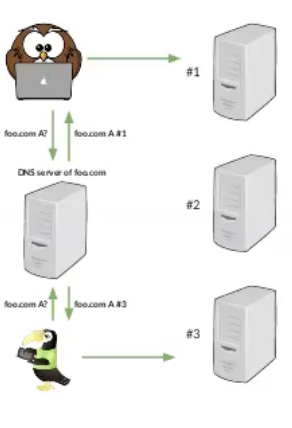
DNS
מחשבים מתקשרים זה עם זה באמצעות IP אך רוב הגולשים לא מודעים לקיומן בכלל.
כדי להפוך את הגלישה לנוחה, לכל אתר מוצמד שם דומיין שהוא שם מילולי ומייצג את הכתובת. לשם כך הוגדר הפרוטוקול DNS שרץ על UDP. הפרוטוקול מהווה מעין ״ספר טלפונים״. הדפדפן מאחורי הקלעים על כל דומיין פונה לשרת ה DNS כדי לקבל את הכתובת ה IP.

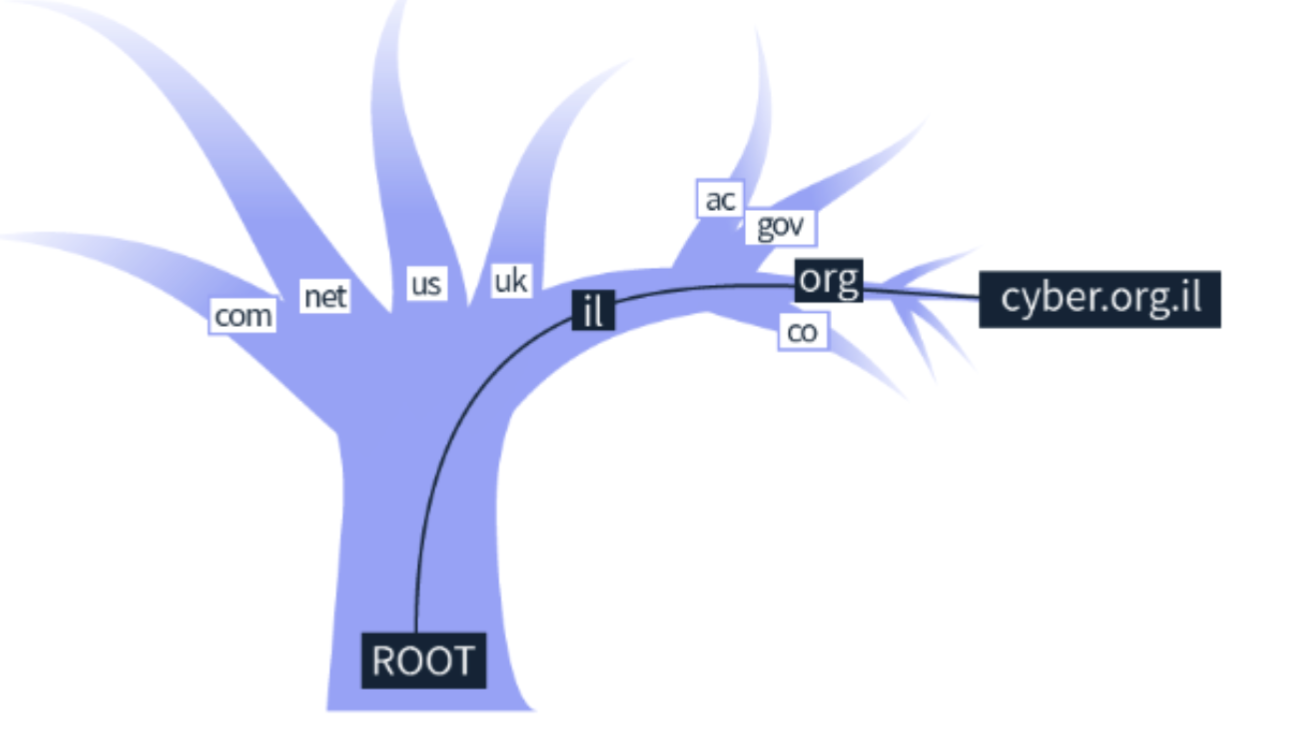
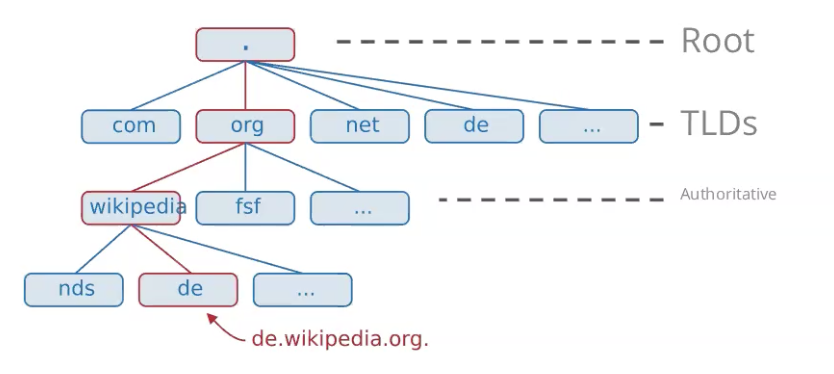
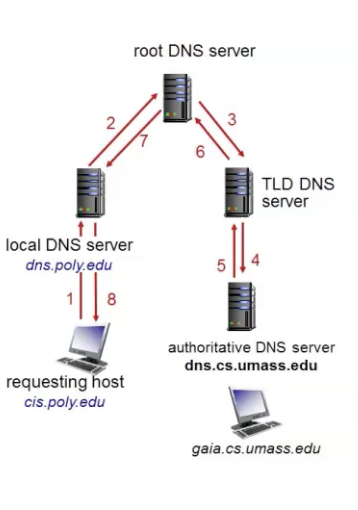
מבנה של שמות דומיין מזכיר עץ , הסיומות בשם הדומיין מייצגות את סדר הפניה לשרתי DNS מהסוף להתחלה. נדגים על cyber.org.il :
א) בגזע של שמות הdomain נמצא שרת DNS בשם Root- הוא שומר את כתובת ה IP המשמשים רק ב top level domains למשל סיומות של מדינות
ב) בשלב הבא מתבצעת הפנייה אל שרת ה DNS האחראי על סיומות
ג) בשלב האחרון מתבצעת פנייה לשרת DNS שהשורש שלו הוא
שרתי ה Root:
יש כ 13 שרתי root לוגיים (של חברות רשת מסויימות שהשרתי root הפיזיים שלהם מפוזרים בכל מיני מקומות).
בהגדרות הרשת של המחשב מוגדר לנו לאיזה שרת DNS לפנות כאשר אנחנו רוצים לקבל כתובת של דומיין מסוים. אלו הגדרות שמוזנות באופן אוטומטי דרך הראוטר אבל נתנות לשינוי או להגדיר באופן ידני את כתובת ה IP של השרת DNS שנרצה לפנות אליו
DNS Resolver
הresolver היא התוכנה שפותרת שאילתות DNS.
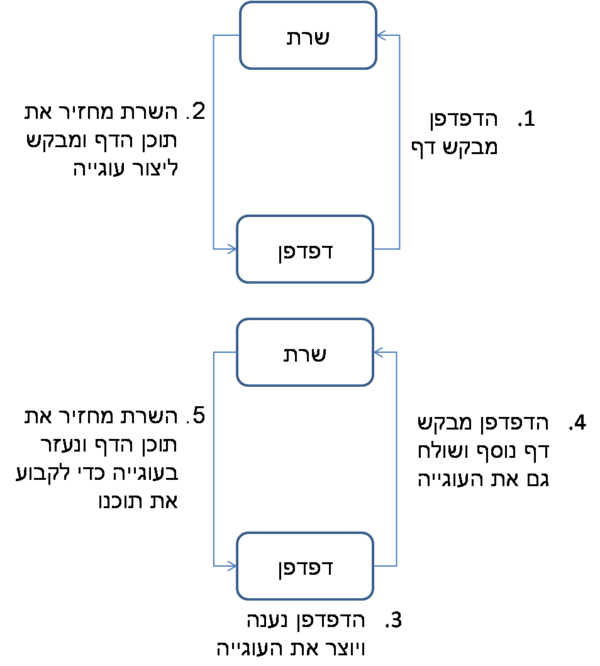
מההסבר שהבאנו למעלה, אפשר להניח שמשיכת כתובת IP היא תהליך ארוך שיכול לעבור בכמה וכמה שרתים. כדי לייעל את התהליך הזה ישנם שני פתרונות
א. שימוש ב Cache כדי להכיל מיפוי לכתובות שכבר חיפשנו כדי לא לחפש אותם שוב.
ב. פרוטוקול DHCP יביא כתובת לשרת DNS של הרשת המקומית (לרוב זה יהיה הראוטר) והמטמון ישב שם. היתרון בזה הוא שהמטמון משותף בין כל הhosts ברשת המקומית ויש שיתופיות של כתובות , resolver אחד ישתף המון לקוחות.
ה Resolver עובד בצורה חצי איטרטיבית וחצי רקורסיבית, הבקשה עולה לשרת ה DNS המתאים ומשם הולכים לפי העץ, תחילה פונים ל root שמחזיר את הכתובת הבאה של השרת שעלינו לשאול אותו (במקום שהוא יעשה זאת וככה יורד ממנו עומס) השרת DNS המקומי שלנו מכאן ממשיך לשאול בתורות את השרתים שחוזרים עד שמתקבלת תשובה כפי שמתואר בתרשים הבא
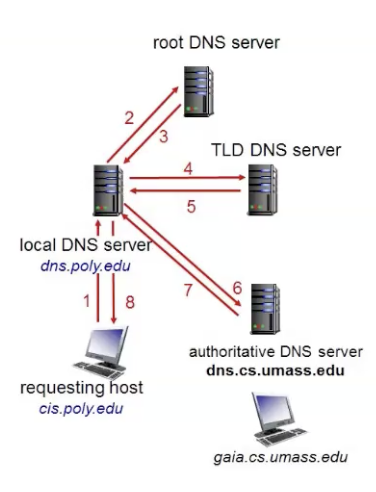
הריקורסיה באה לידי ביטוי בכך שיכול להיות שגם השרתים עצמם יצטרכו לעבור תהליך דומה.
בעצם הבעיה שחסכנו בשיטה זאת היא heavy load על השרתי root כפי שהיה קורה אם היינו עובדים בשיטה ריקורסיבית מלאה :
שדות DNS
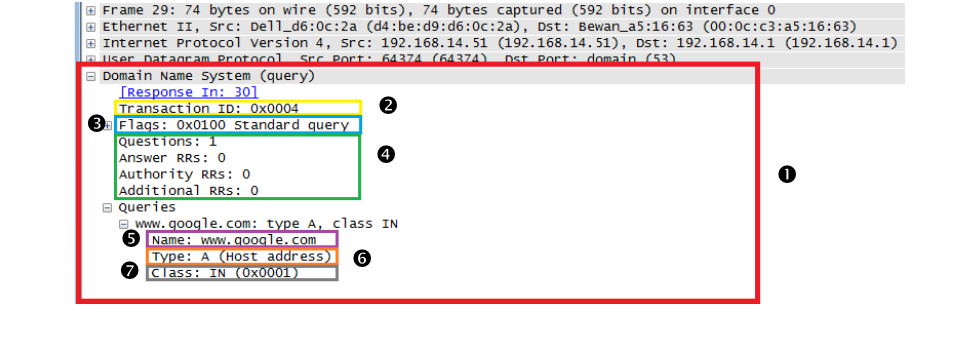
כפי שאמרנו ניתן לראות שהחבילה נשלחת בשכבת האפליקציה מעל UDP.
א) בצהוב ניתן לראות את ה Transaction ID שאמרנו שהוא נפוץ מעל UDP
ב) השדה בכחול הוא flags ששדה זה מורכב משמונה דגלים בעלי משמעויות שונות, הדגל הנ״ל מציים שמדובר בשאילתה סטנדרטיץ
ג) RR- Resource Records בירוק זה מידע שמתאר כמה רשומות מכילה חבילת ה DNS.
ד) השאלתה עצמה בסוף של הבקשה מכילות Name,Type ו Class כאשר האחרון מתאר את סוג הרשת בד״כ יהיה רשום IN.
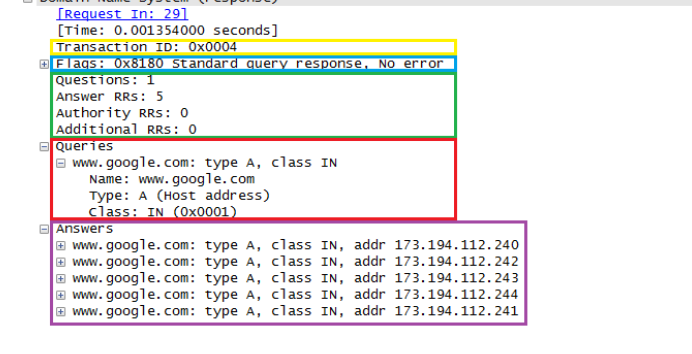
בResponse אפשר לראות שגם התווסף תשובת Answers וב RR אפשר לראות שעבור שאלה אחת יש חמש רשומות תשובה. הסיבה לכך היא שלפעמים כתובת דומיין אחת מצביעה לכמה כתובות IP וכך אם שרת אחד נפל יש שכפולים.
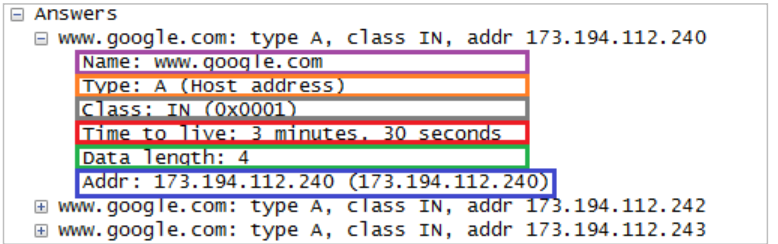
ברשומה של שאילתה יש את השדרות הטריוויאלים אבל נשים לב שיש גם ttl ששדה זה קובע כמה זמן יש לשמור את הרשומה בCache.
באופן כללי רשומת DNS היא רביעייה מהצורה
ה type מתחלק ל4 :

הרשמת Domain חדש
כאשר אנחנו מרימים domain חדש צריך לרשום אותו ב DNS registrar.
כאשר רושמים אותו מייצרים לו גם Name Server רלוונטי שיודע להחזיר את ה IP הרלוונטי ל domain . בעצם הregistrar מייצר שני RRs חדשים ל Top Level Domain Server של
הראשון הוא המיפוי בין הdomain ל NS הרלוונטי, השני הוא הכתובת IP של הNS

כל רשומה כזאת נשמרת בcache לTTL זמן כפי שאמרנו.
DNS Redirection
טכניקה שנועדה לפזר עומס על שרתים. בהינתן Domain מסויים, יהיו מספר העתקים שלנו כאשר לכל אחד יש IP שונה. שרת ה DNS מחזיר כתובת IP שונה לצורך פיזור העומס, באמצעות אלגוריתם Round Robin.
HTTP
Hyper-Text Transfer Protocol. פרוטוקול זה מאפשר לאפליקציות לגשת ולעשות שימוש במשאבי האינטרנט (תמונות, קבצים וכו׳). בפרוטוקול זה כתובת ה URL היא מרכיב הכרחי כדי לקבוע מהו המשאב הרלוונטי שאנחנו רוצים למשוך

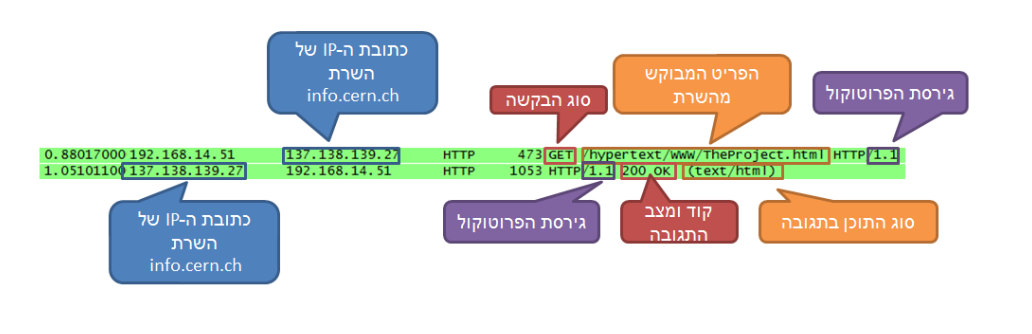
HTTP עובד בעקרון של בקשה ותגובה כלומר הלקוח שולח בקשה לשרת וכאשר היא מתקבלת, השרת ישלח תגובה. בתקשורת HTTP השרת לא יוזם שיח עם הלקוח.
כמו כן חשוב לציין ש HTTP רץ על TCP .

גרסאות HTTP
ישנם מספר גרסאות ל HTTP שחשוב להכיר:
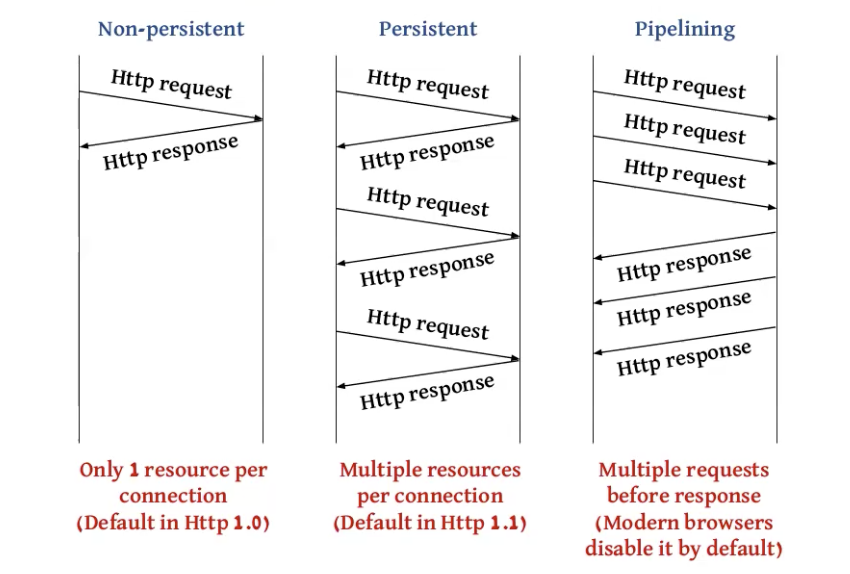
Non-persistent:
על גבי חיבור TCP בודד ניתן לקבל משאב אחד ואז החיבור נסגר.
Persistent:
כמה וכמה בקשות ניתנו לביצוע פר חיבור TCP בודד.
Pipelining:
ניתן לשלוח מספר בקשות HTTP לפני שמתקבלת עליהן תשובה על אותו החיבור .
Format
יש שני סוגי הודעות ל Http: הודעת request והודעת response .
שני הבקשות עוברות בקידוד ASCII .
בקשת request נראת המצורה:

נשים לב שה
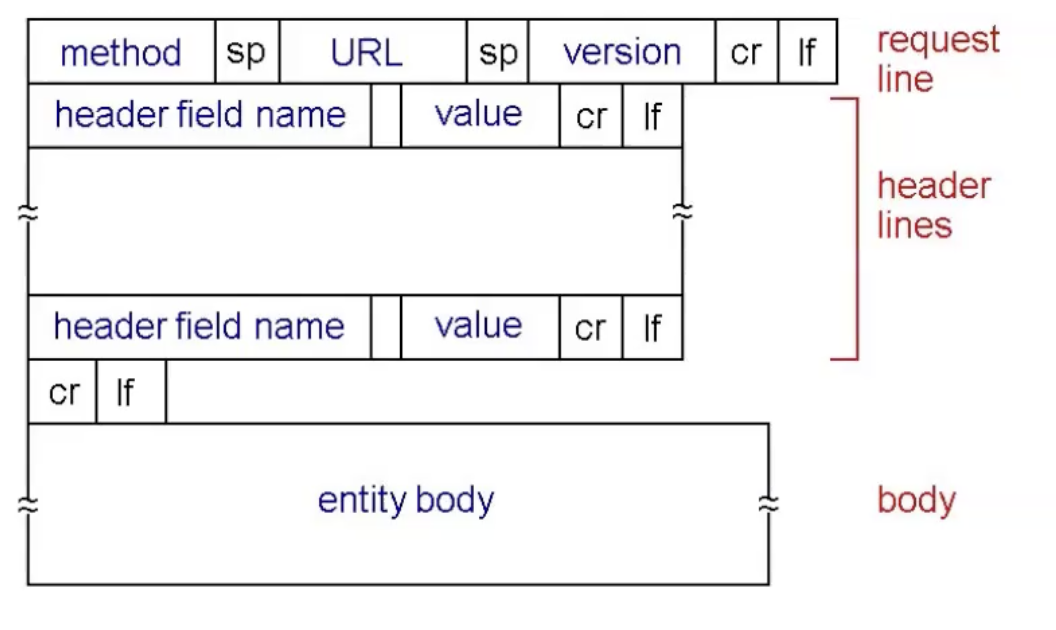
הresponse נראה מהצורה:
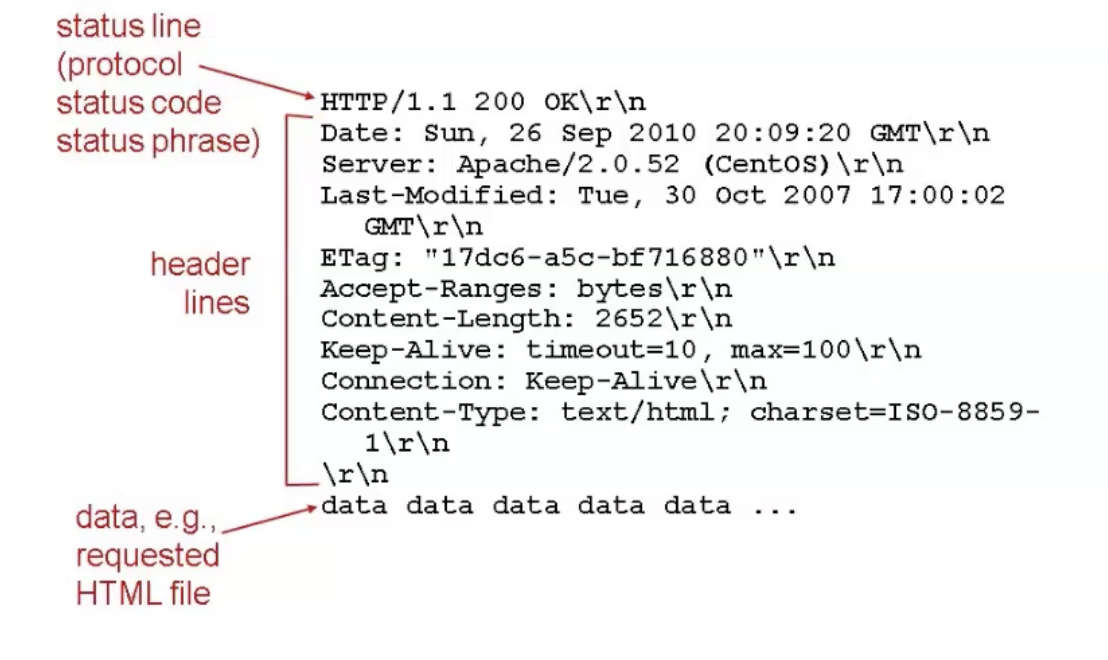
Http Request
Start line
בקשות HTTP הן הודעות שנשלחות על ידי הלקוח כדי ליזום פעולה בשרת. קו ההתחלה שלהם מכיל שלושה אלמנטים:
HTTP method
מתאר איזה פעולה הבקשה רוצה לעשות:
GET- מבקשת לקבל משאב מסויים.
HEAD- מבקשת את אותה תגובה כמו בקשת ה GET רק בלי ה body.
POST- שליחה של יישות עבור משאב מסויים במערכת, לעתים זאת משנה את ה state שלו או משפיעה על השרת.
DELETE- מחיקה של משאב מסויים.
PUT-החלפה של משאב מסויים בתוכן הבקשה.
PATCH- ביצוע מודיפיקציה של משאב בשרת.
Request target
בדרך כלל זה URL או נתיב אבסולוטי שמכיל בתוכו queries, פורט וכו׳.
בעצם זה יכול להיות כל נתיב שהוא בעצם מורכב מהמבנה המלא של URL

HTTP version
הגרסה קובעת את המבנה של שאר ההודעה וגם כדי לדעת כיצד לבנות את התגובה.
Headers
כותרות HTTP מייצרות בקשה תחת אותו מבנה בסיסי של Header HTTP: מחרוזת לא תלוית רישיות ואחריה נקודתיים (':') וערך שהמבנה שלו תלוי בHeader. הכותרת כולה, כולל הערך, מורכבת משורה אחת בודדת, שיכולה להיות ארוכה למדי.
זה סוג של metadata על הבקשה.
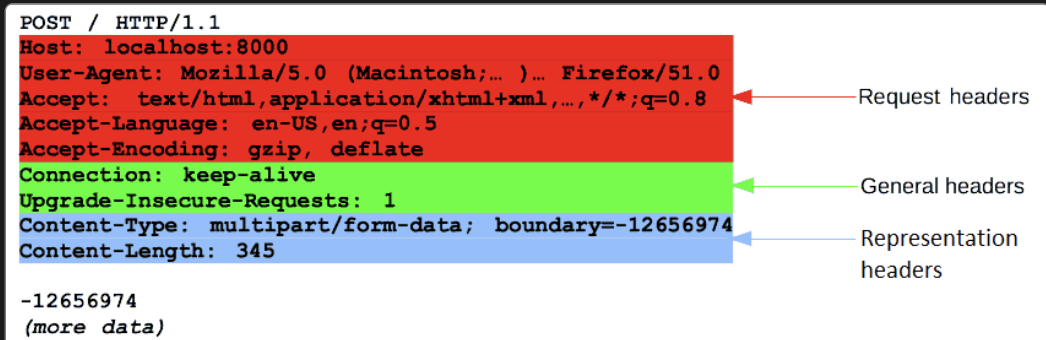
Body
החלק האחרון של הבקשה הוא הגוף שלה. לא לכל הבקשות יש אחת: בקשות שמביאות משאבים, כמו GET, HEAD, DELETE או OPTIONS, בדרך כלל אינן זקוקות למשאבים כאלה. חלק מהבקשות שולחות נתונים לשרת על מנת לעדכן אותם: כפי שקורה לעתים קרובות בבקשות POST (המכילות נתוני טופס HTML).
HTTP Response
כפי שאמרנו המבנה הוא דומה לRequest.
Status line
שורת ההתחלה של תגובת HTTP, הנקראת שורת המצב, מכילה את המידע הבא:
- גרסה של הפרוטוקול, בד״כ
HTTP/1.1 - סטטוס קוד שמעיד על הצלחה או כשלון. ישנן קונבנציות הקשורות לקודים האלה למשל:
מייצג הצלחה
מייצג שגיאה הקשורה בצד client.
זה שגיאה בצד שרת. (505 למשל זה גרסה שונה של Http)
301 - האובייקט שחיפשנו זז בצד שרת למיקום אחר שיפורט בהמשך בheader ה location.
Headers
מבנה זהה לחלוטין של headers בבקשת http. ההבדל היחיד הוא בקונטקסט שיש לheaders האלה כלומר מה המשמעות שלהם.
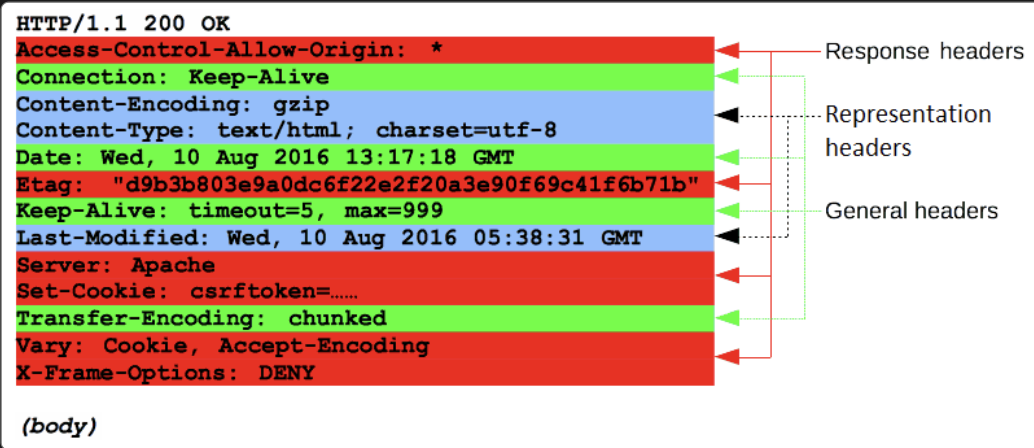
Body
באופן דומה ל HTTP Request. מכילות מידע החוזר מבקשה. הרבה פעמים אנחנו נראה את זה בבקשות מסוג GET.
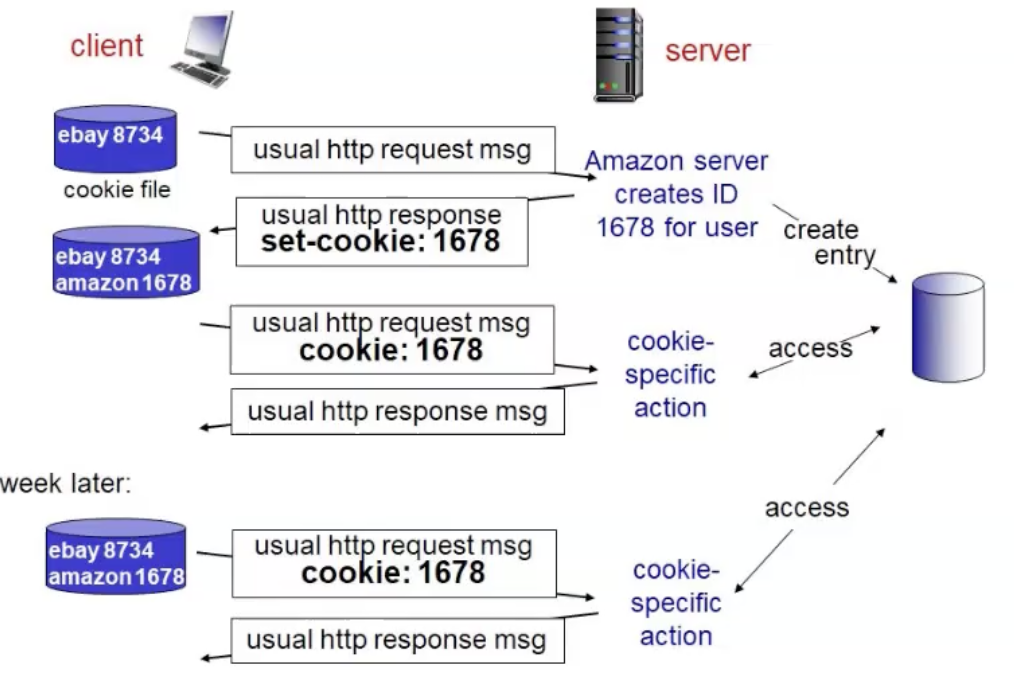
Coockies
באינטרנט, עוגייה היא מחרוזת אותיות או מספרים, המשמשת לאימות, למעקב ולאגירת מידע על אודות גולש באתר אינטרנט, כגון שמירת העדפות המשתמש. העוגייה מייצגת מצב מסוים של גלישה באתר או שימוש באפליקציה. לעיתים, גם אתרים שאינם האתר שיצר את העוגייה יכולים להשתמש בה.
העוגייה נוצרת על ידי השרת שמעביר אותה לדפדפן ששומר אותה בזיכרון המחשב. המחרוזת מוחזרת חזרה לשרת בכל פעם שהדפדפן יוצר קשר עם השרת וכך למעשה יכול השרת לזהות את המשתמש ולאחזר מידע שנשמר בין שיחות שונות.
הדפדפן שומר את העוגיות בקובץ key-value כאשר ה key הוא הdomain והvalues הם הcoockies ששמרת עבור אותו domain.
Http cache
ל Http יש מנגנון Cache בצד הלקוח שמאפשר לדעת האם יש צורך להביא משאבים כבדים מהשרת או לטעון אותם ישירות מהcache למשל על ידי שימור בפרמטר ה last modified.
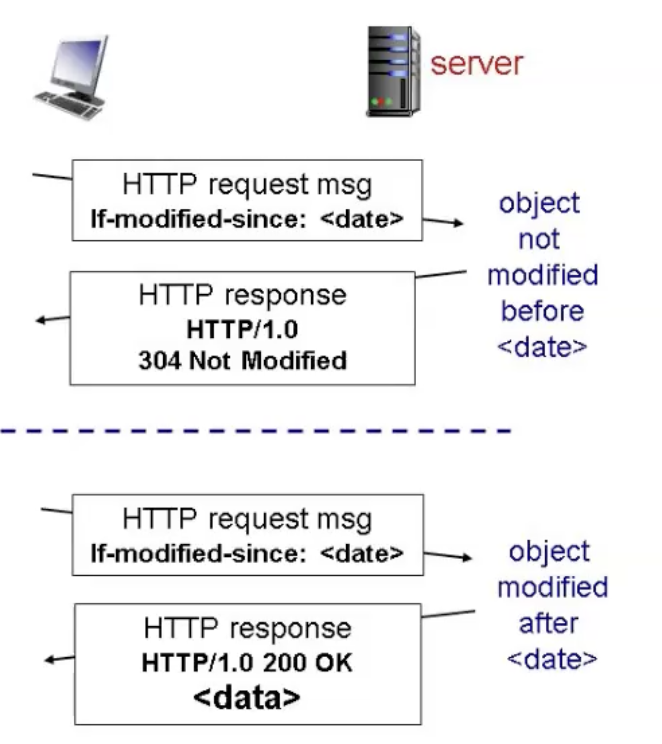
ניתן לראות שהשרת יחזיר 304 שזה אומר שהמידע לא השתנה אם שלחנו בקשה עבור משאב שנמצא במטמון בפרק זמן קצר מדי.
היתרון המשמעותי של זה הוא שניתן לחסוך זמן יקר בטעינת משאבים באתר על ידי שימוש במטמון שנמצא קרוב יותר למחשב הלקוח מאשר השרת המקומי.
כמו כן- גם אם המטמון של הresponse שמור בצד שרת עדיין השרת לא צריך לבצע עיבוד לבקשה.
באמצעות הפרמטר Cache-Control נוכל להגביל את זמן השמירה של מידע במטמון וגם לקבוע האם יש צורך בשימוש במטמון בכלל.
סוגי Cache
ישנם שני סוגים עיקריים של cache :
private: שמשויך ללקוח לספציפי (מטמון של דפדפן). מטמון כזה יכול לשמור בתוכו response שמיועד ללקוח ספציפי.
אם נרצה לשמור מידע במטמון פרטי נוכל לציין זאת באמצעות הוספת הheader
Cache-Control: private
shared: מטמון שממוקם בין הלקוח לשרת ויכול לשמור responses שיכולים להיות משותפים בין מספר משתמשים. אפשר לחלק אותו לשניים, Proxy cache או managed cache .
Proxy
המטרה של Proxy Server היא לספק בקשות לקוח מבלי לערב את השרת המקורי. במילים אחרות, שרת שתפקידו העיקרי לספק גישה מהירה למשאבים חיצוניים ברשת מחשבים.
הסוואת כתובת ה-IP מתאפשרת על ידי חיבור לשרת פרוקסי שדרכו כל חיבורי האינטרנט עוברים (הנתונים נשלחים אליו וממנו אל השרת ומן השרת אליו ועד למשתמש) כפי שניתן לראות בתמונה.
תפקידו העיקרי של שרת הפרוקסי מתאפשר באמצעות תוכנה השומרת בזיכרון המטמון שלו עותקים של דפי אינטרנט ומאפשרת גישה מהירה אליהם מהמחשבים המחוברים לפרוקסי. בחלק מהמקרים משמש הפרוקסי כנקודת הפרדה וביקורת בין רשת המחשבים הפנימית של הארגון אליו הוא שייך לבין העולם החיצוני.
הוא מאפשר מעקב, חסימה או שינוי לדפי HTML על פי מדיניות הארגון בענייני אבטחת מידע ותכני מידע קבילים (אפשר, למשל, לחסום אתרים פורנוגרפיים). יש מקרים שהוא משמש למימוש SSO (מסיר את הצורך בהכנסת שם לכל אפליקציה שונה) ולהוספת הגנות לדפי הארגון על פי הרשאת המשתמש.
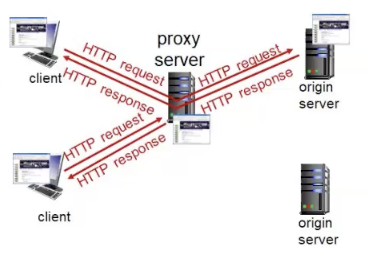
סוגי Proxy:
1) Regular Proxy
2) Transparent Proxy - הלקוח לא מכיר את ה Proxy הזה, הוא מפענח פקטות ומשתמש בהן בהתאם.
3) Reverse proxy- מיועד לצד השרת , מסתיר את השרת והטכנולוגיה של השרת, מבצע בעיקר cache ו load balancing בשביל Scaleability.
HTTP calculations
בחלק זה נראה מספר שאלות חישוב שניתן לעשות מעל HTTP.
שאלה 1:

מכיוון שאליס עובדת בhttp1.0 אזי מדובר על חיבור שהוא ברירת מחדל לא persistent.
נשים לב: תמיד דגל ה ACK דולק בכל החבילות (למעט הראשונה של ה SYN, ובהתאם ערך ה ACK number יהיה הכי עדכני). לא תמיד נקפיד על הצגה של זה בתרשימים הבאים.
נשים לב שהדפדפן של אליס מעולם לא ניגש לאתר של בוב אבל שרת ה DNS המקומי כן ניגש. כלומר כשנשלח אליו בקשת DNS הוא לא יצטרך ללכת להירכייה ומיד יוכל להחזיר תשובה.

נשים לב שDNS הוא מעל UDP כפי שאמרנו.
כעת יתחיל חיבור TCP בין אליס ובוב כיוון ש HTTP הוא פרוטוקול מעל TCP ואליס שולחת בקשת GET כדי לקבל את עמוד האינטרנט. כמו כן כיוון שנתון שבקשה בודדת הייתה קטנה מ MSS כל תהליך ה request ו response יהיה בסגמנט אחד בלבד לכל שלב.
לבסוף נוכל לסגור את חיבור הTCP לאחר שהבקשה הושלמה.
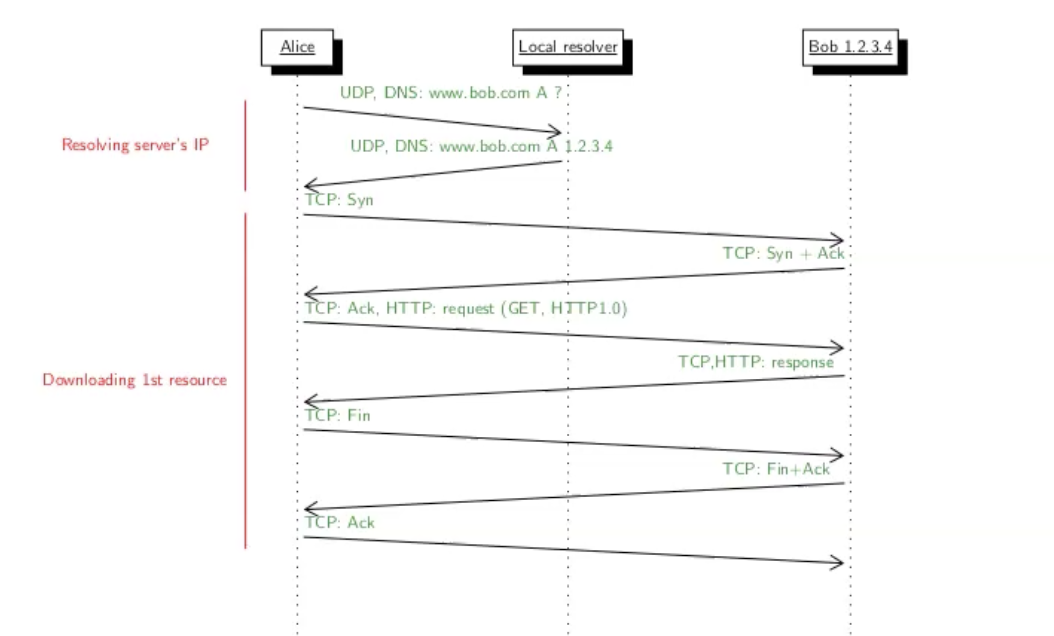
לא סיימנו, כיוון שאתר האינטרנט מכיל גם תמונה אחת הדפדפן צריך להוריד את הasset בבקשת GET נוספת ולכן יפתח חיבור TCP חדש.
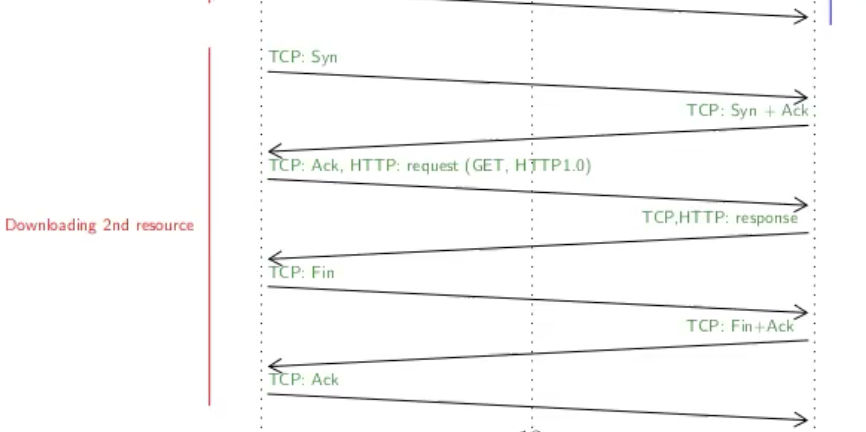
שאלה 2:
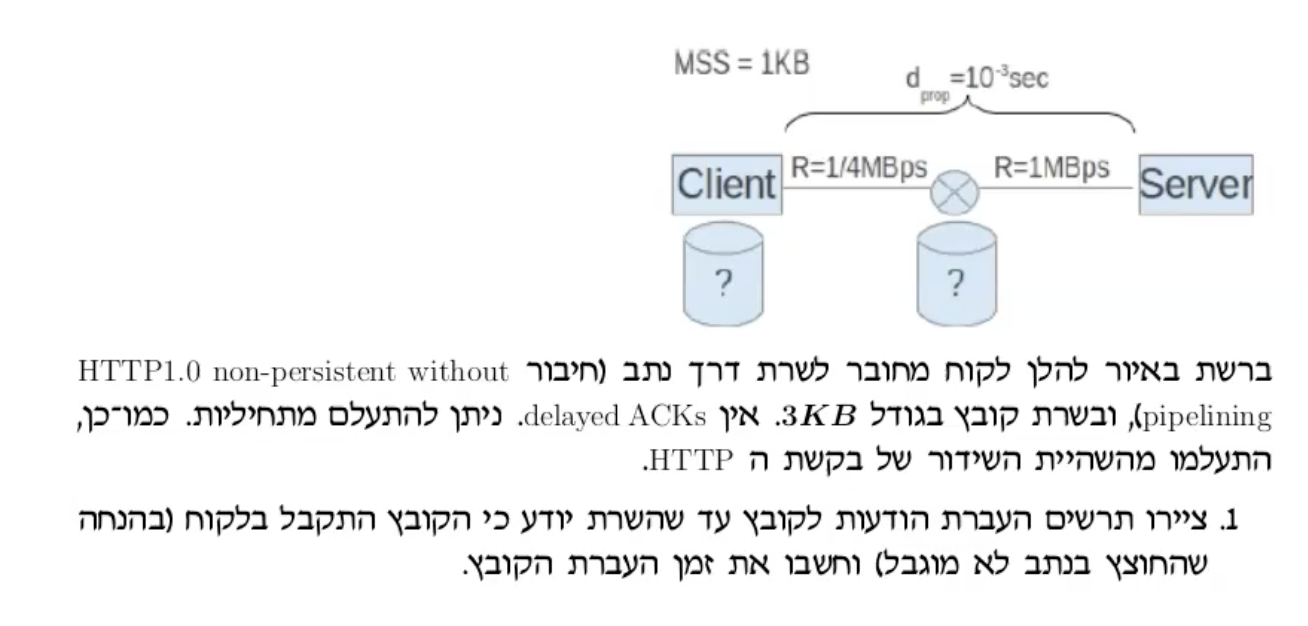
נתון שהשהיית ההתפשטות מהclient ל server היא
כיוון שניתן להתעלם מהשהיית ההתפשטות של תחיליות ושל הבקשה בפרט. לכן אין צורך לחשב את השהיית השידור מהלקוח לראוטר ומשם לשרת. אפשר לחשב ישירות את ההשהייה מהלקוח לשרת
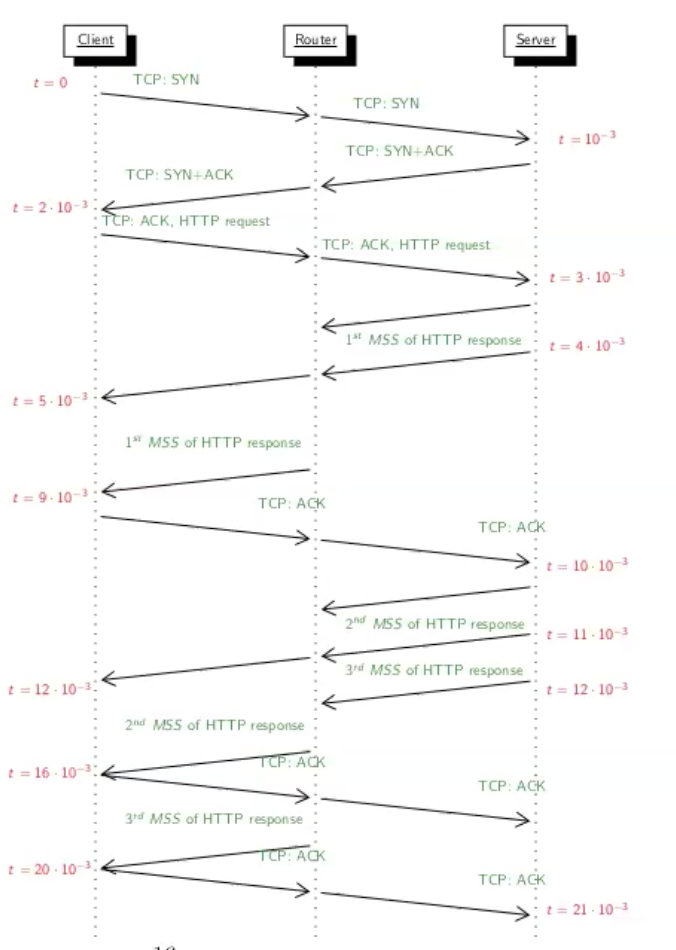
ניתן לראות ששלב הhandshake ושליחת הבקשה לוקח 3 השהיות כלומר
כעת נשים לב שה MSS=1KB אבל הresponse הוא קובץ בגודל 3KB.
נשים לב שלפי נתוני ההתפשטות של כל ערוץ. להעביר MSS אחד בתווך בין השרת לראוטר ייקח
התהליך הזה חוזר על עצמו 3 פעמים אחד אחרי השני (בגלל שאנחנו בstore and forward) וסך הכל התהליך יסתיים לאחר 21 אלפית השנייה.
שאלה 3:

נשים לב שכעת פרוטוקול DNS הולך ״לעבוד קשה״ בגלל שהcache ריק. הלקוח ברשת A ניגש לשרת הפרוקסי ולאחר מכן ניגש לlocal resolver שמשם יבצע את שרשרת ה DNS הרלוונטית למשיכת הip.
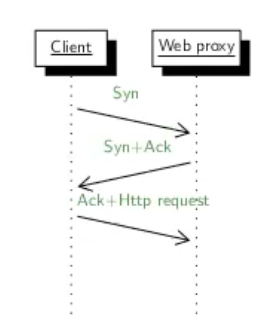
כעת הפרוקסי יבצע פנייה ל local resolver בכוונה למצוא את הdomain וכן הלאה נמשיך בשרשרת פניות ל ns servers כדי למצוא את ה ip. נזכיר ש DNS לא עובד רקורסיבי אלא סדרתי ולכן השרת com יחזיר תשובה ל B.com לresolver וכן הלאה. לבסוף הresolver יחזיר את התשובה ל proxy.
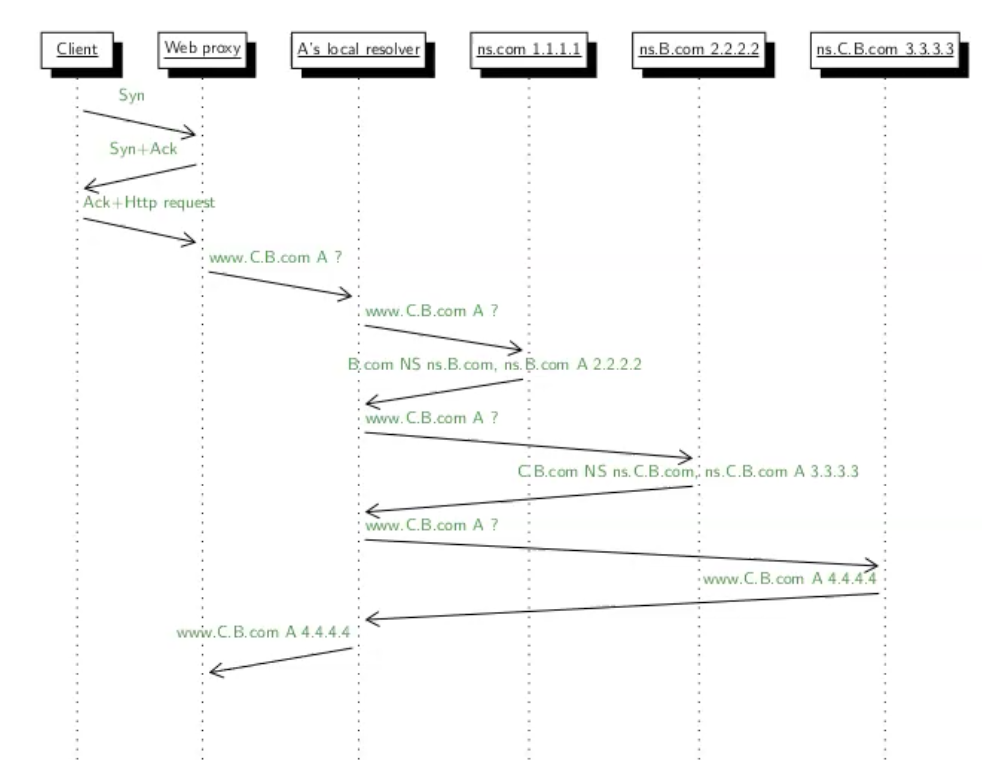
לאחר שכל זה קרה, יתבצע חיבור TCP נוסף בין ה proxy לבין ה web server לקבלת הדף ושמירה ב cache.
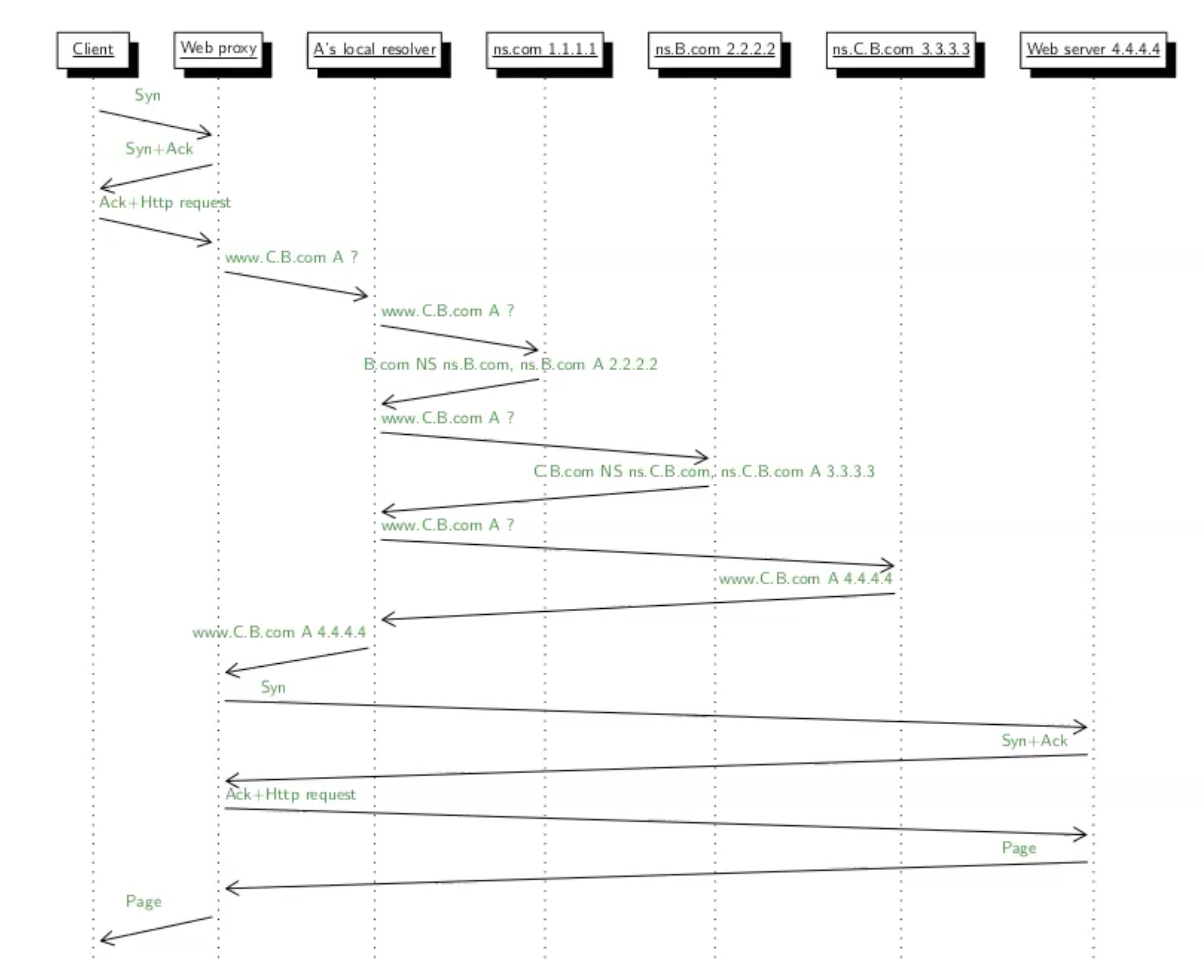
שאלה 3.2

יש 10 חבילות שנשלחות באינטרנט ועוד 6 חבילות באותה הרשת ולכן
שאלה 4:

יש
שאלה 5:
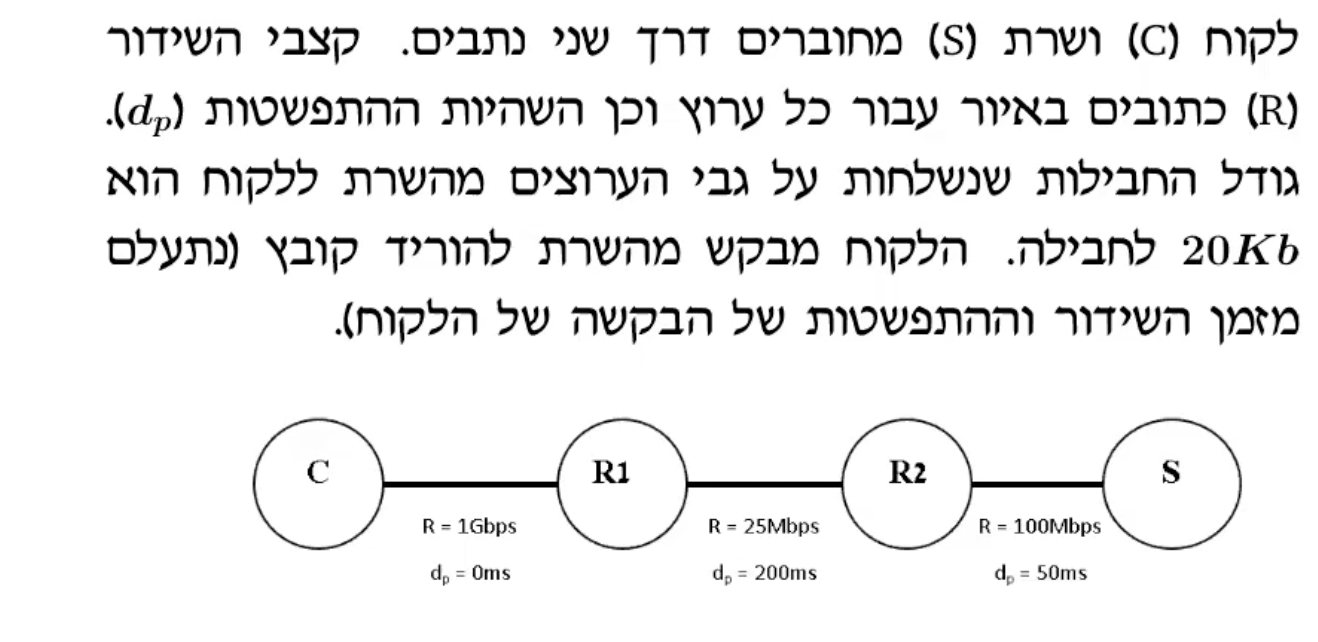

השהיית ההתפשטות נתונה לנו לכן צריך לחשב רק את השהיית השידור ונקבל
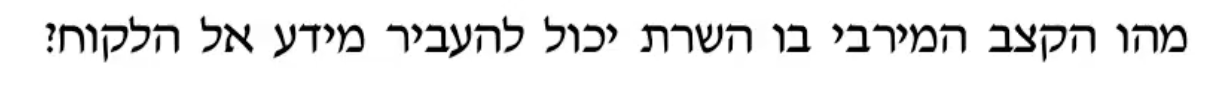
כגודל הערוץ המינימלי 25Mbps .

נחשב ממוצע משוקלל :
שאלה 6:

CDN
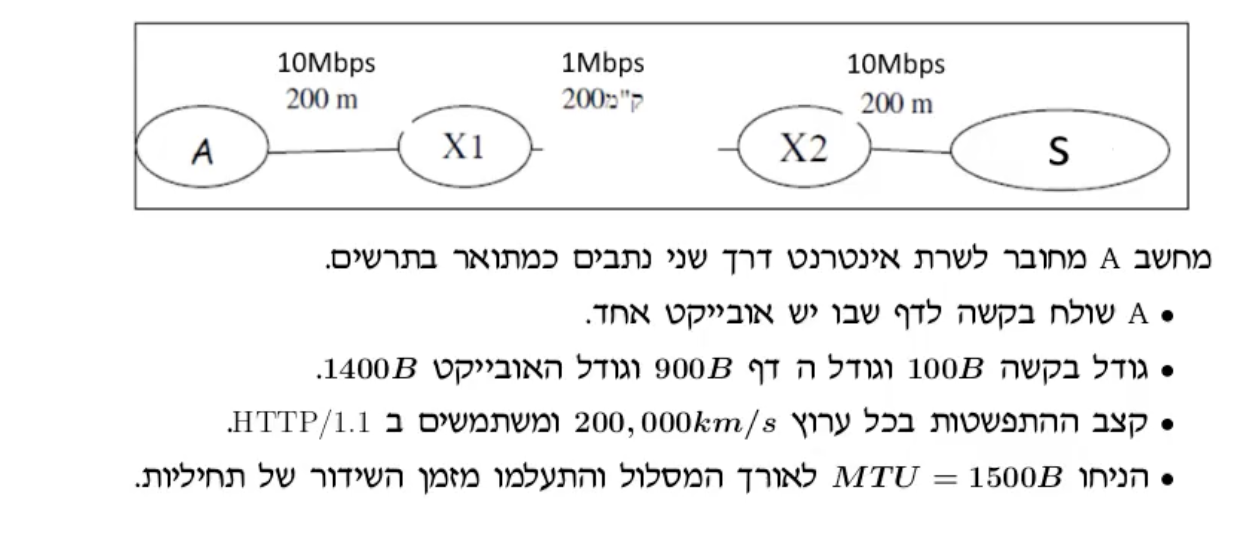
Content Delivery Network היא רשת של שרתים שמאפשר העלאה מהירה יותר של דפי אינטרנט כאשר הן עושות שימוש בהמון data.
אם לא היינו משתמשים בשירות הזה כל הלקוחות שמשתמשים בשירות שלנו ניגשים לאותו שרת. המנגנון הזה נתון להמון בעיות, החל מהעובדה שלקוחות מסוימים יחוו את טעינת האתר בצורה איטית יותר או שהשרת עלול לקרוס ואין לו גיבוי.
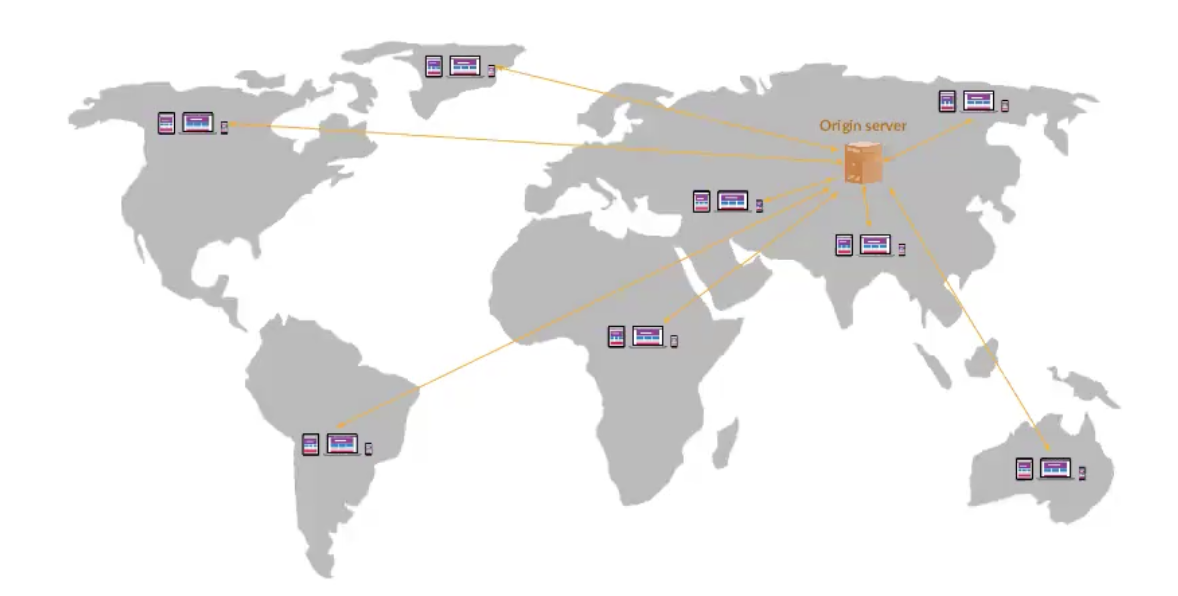
חברות רבות שמציעות שירותי CDN מציעות אלטרנטיבה לרכישה של שרתים מסביב לעולם כדי לתקן את הבעיות האלה.
החברות הנ״ל שמו בכל מיני אזורים שרת שנקרא Edge server. הלקוחות פונים לאחד מהשרתים הקרובים אליהם באמצעות קח שהן מתלבשות על חוות שרתים של ספקי האינטרנט באזורים השונים.
השרתים האלה מהווים מנגנון של Cache עבור השרת שלנו.
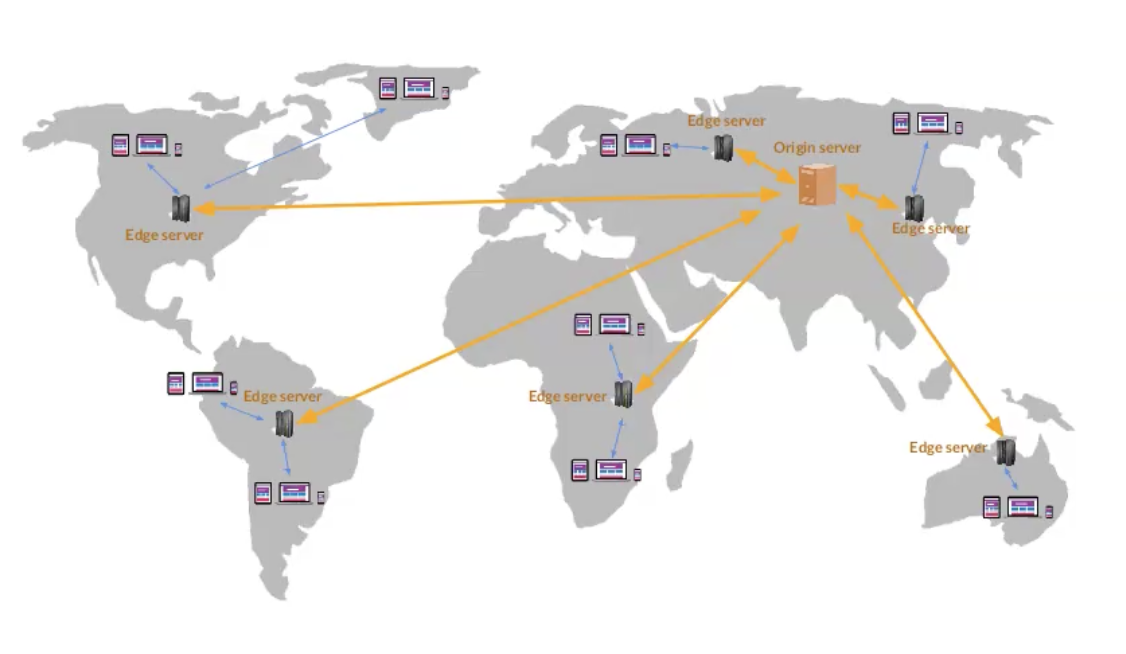
SMTP
Simple Mail Transfer Protocol הוא פרוטוקול שכבת האפליקצייה המכיל 3 רכיבים עיקריים
- user agents
- mail servers
- simple mail transfer protocol
User Agent
- עונה גם לשם mail reader
- מיועד לעריכה קריאה ושליחה של הודעות מייל.
- תוכנות רבות מהוות user agent לפרוטוקול למשל אפליקציית Outlook, Gmail וכו׳
- הודעות יוצאות ונכנסות מאוחסנות בשרת.
כדי לדחוף מיילים מהuser agent לשרת נשתמש ב SMTP.
הייחודיות בפרוטוקול SMTP היא היכולת להעביר מיילים גם בין "domains" שונים, כלומר שאינם קשורים לאותו שרת.
נשים לב: SMTP משמש למשלוח דואר אלקטרוני מuser agent ובין שרתים שונים, עד שיגיע לשרת היעד, אך אינו מאפשר למשתמש לשלוף את הודעות הדואר המיועדות אליו מן השרת. קיימים פרוטוקולים אחרים המיועדים לשליפה של הודעות דואר, כגון POP3 ו-IMAP.
SMTP עובר מעל TCP ומשתמש בדרך כלל בפורט 25. פורט לקבלת נתונים הוא פורט 587.
Flow
- אליס משתמשת ב user agent כדי לנסח הודעה עבור bob@someschool.edu.
- אליס שולחת הודעה לשרת המייל שלה , שם הוא נמצא ב message queue.
- ״צד הלקוח״ של שרת הSMTP הנ״ל פותח חיבור TCP לשרת המייל של בוב.
- SMTP client שולח את ההודעה של אליס על גבי TCP.
- שרת המייל של בוב ממקם את ההודעה של בוב ב mailbox.
- בוב מושך מהשרת את ההודעות שלו (בעזרת פרוטוקול אחר או בעזרת ה web-based mail).
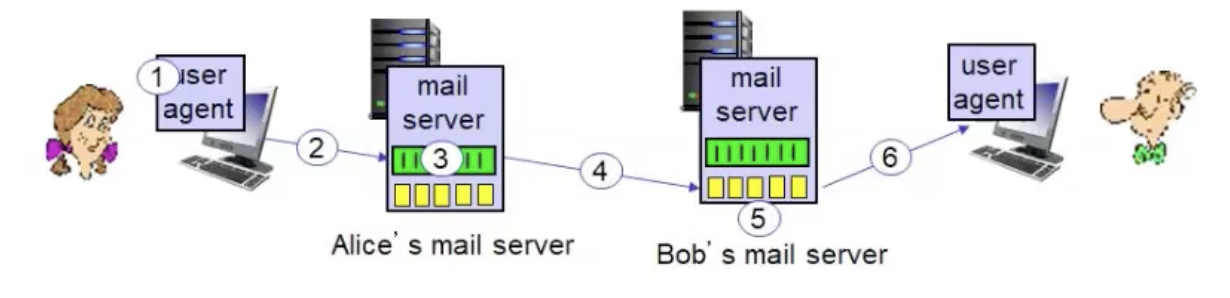
נשים לב שאם אליס ובוב היו באותו שרת web שלבים 4 5 ו6 לא היו רלוונטים אלא שהשרת היה מיד שם את ההודעה בתיבה של בוב והוא היה מושך את זה.
נסתכל על Flow של תקשורת SMTP לדוגמה-

כאן ניתן לראות את התקשורת רק ברמת האפליקציה (בלי TCP). ניתן לראות שהשרת שולח הודעה ראשונה ללקוח עם קוד 220 ו״מציג את עצמו״. לאחר שהלקוח גם מציג את עצמו עם הודעת HELO ואת ה״דומיין״ שלו. ניתן לראות שהשרת שוב מגיב ללקוח עם קוד 250 והודעת Hello. נשים לב שההודעה השנייה, HELO נראת כאילו היא עם מעין שגיאת כתיב אך זה הקונבנציה לשלב שבו השרת השולח מציג את עצמו לשרת המקבל. השרת המקבל יסכים לכל שם שישלח במסגרת הודעה זאת. לעתים ניתן להתקל גם בהודעה EHLO שזה הרחבה של HELO. אם הפקודה הזאת נשלחת מהלקוח השרת צריך להגיב עם מידע נוסף שהוא תומך בו.
לאחר מכן הלקוח שולח לשרת הודעת MAIL FROM. השרת מגיב ב 250 (כמו מקודם) ומאשר את המייל של השולח.
כעת הלקוח שולח לשרת את שם הנמען עם הודעה RCPT TO. השרת מגיב ללקוח עם 250 ומאשר את הנמען (אם היו כמה נמענים השורות האלה היו חוזרות על עצמן כמספר הנמענים).
כעת הלקוח שולח לשרת הודעת DATA כדי להכין את השרת לקבלת מידע (נגמר מידע ה״מעטפה״). השרת מגיב בהודעת 354 ומבקש לסיים את המייל עם הודעת ״.״ בסוף בשורה נפרדת.
הלקוח לאחר מכן שולח את הdata עם נקודה בסוף כמבוקש. השרת מדווח 250 שהוא קיבל את ההודעה וכיוון שהלקוח סיים הוא שולח QUIT והשרת מגיב בהודעת 221 וסוגר את החיבור.
נסתכל על דוגמה נוספת:
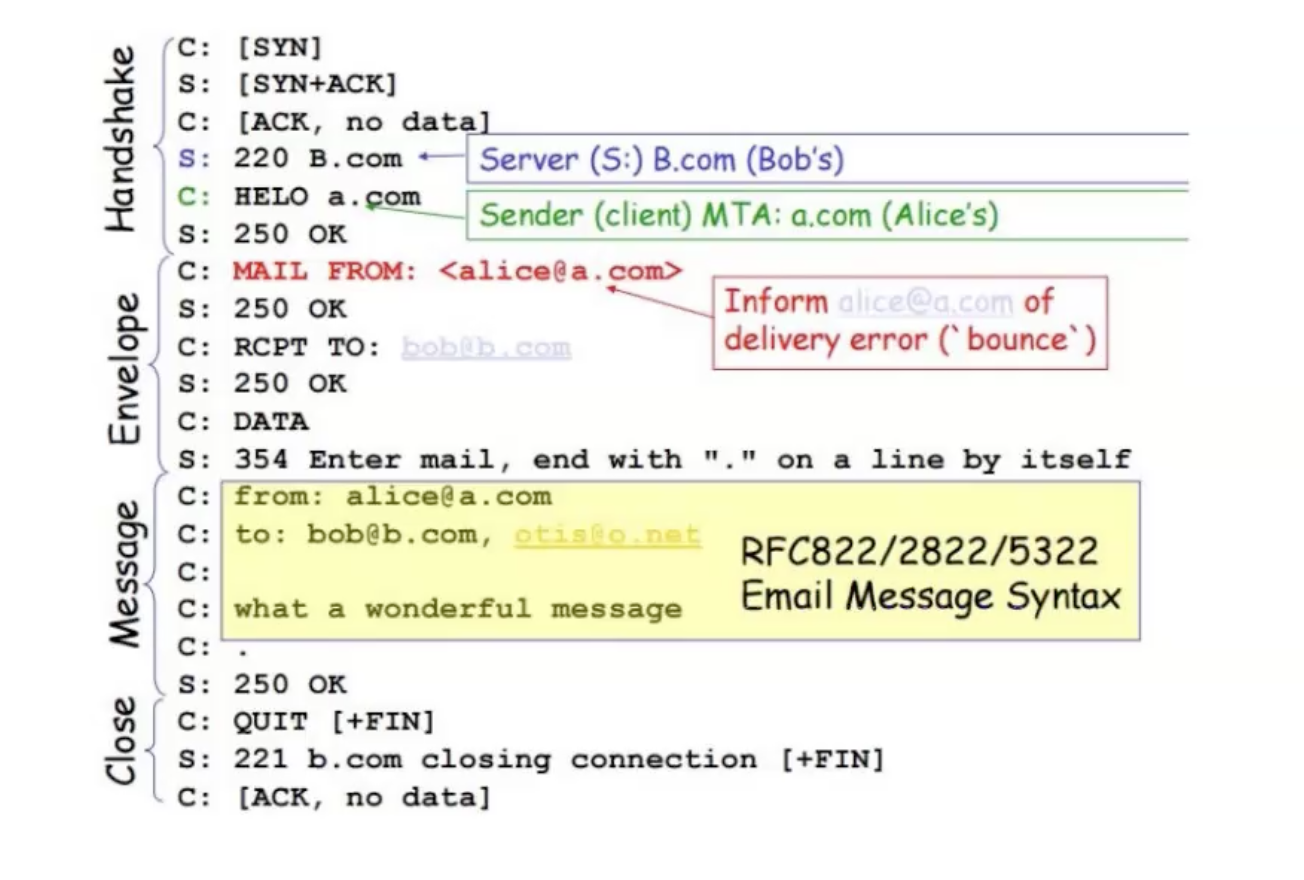
ניתן לראות את שלב ה handshake בשני השכבות גם בתעבורה וגם באפליקצייה.
השלב הבא הוא שלב ה envelope.נשים לב שהמייל המוצמד בהודעת MAIL FROM בשלב המעטפה הוא המייל שאליו השרת ידווח שגיאה במקרה ולא ניתן להעביר את ההודעה.
כאן בשלב ה message הלקוח שולח שתי הודעות דיווח נוספות של from ו to וכאן יש שני נמענים ורק לאחר מכן נשלח הdata הנוסף. הפורמט הזה הוא הפורמט הרשמי של RFC822. ניתן לראות שאומנם יש כאן עוד נמען אך השרת הנ״ל מתעסק ב b.com ולכן הוא לא מתעסק בזה.
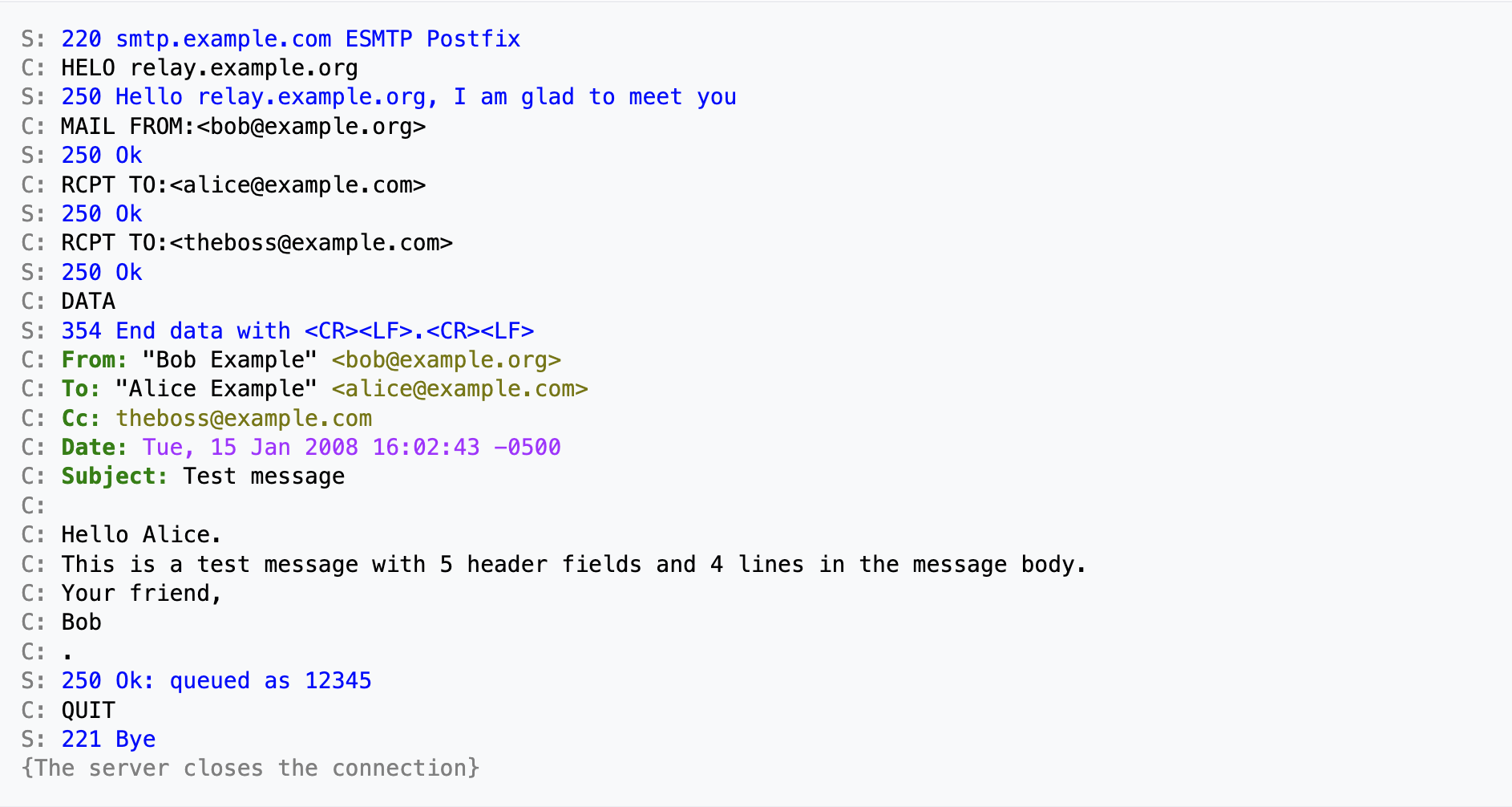
כאן ניתן לראות דוגמה שבה המידע הנוסף (המידע ב Cc) כן היה רלוונטי עבור השרת הנ״ל ולכן הוא גם קיבלת הודעת RCPT נוספת עבור מייל זה (בשניהם הדומיין הוא example.com).
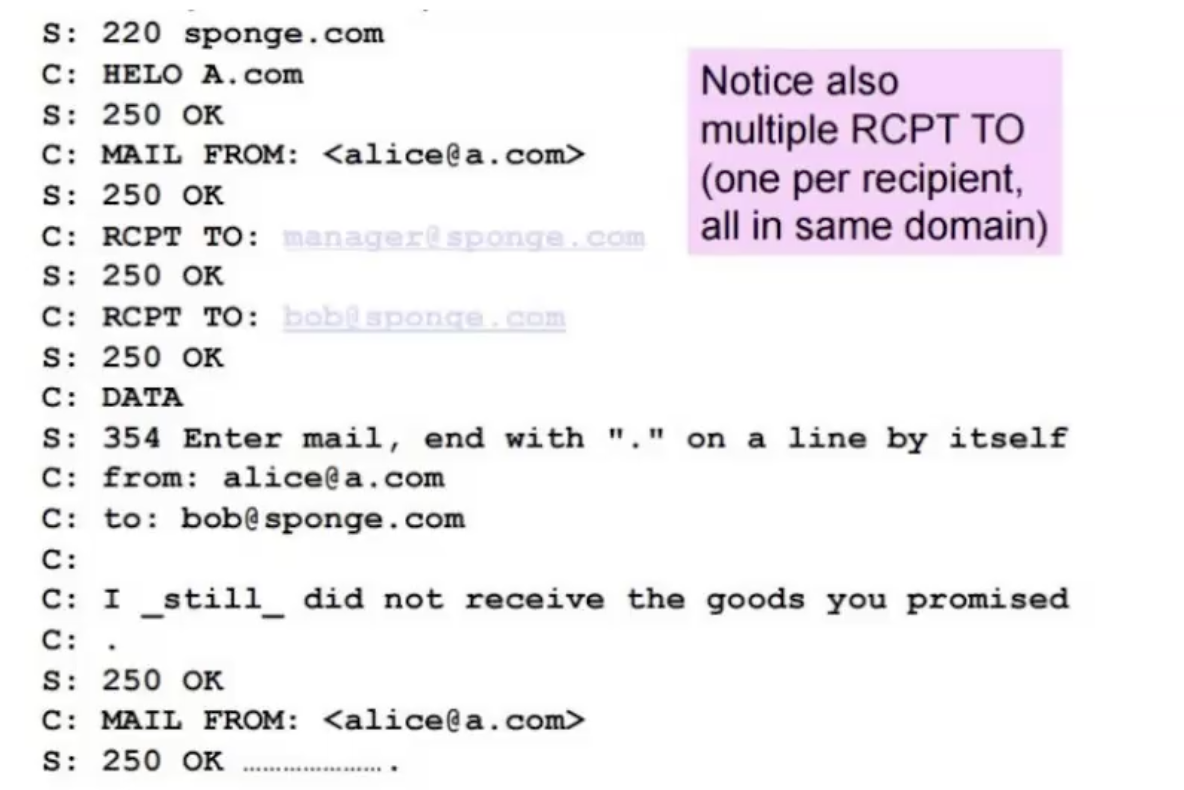
כאן גם יש שני נמענים רק שהפעם אחד הנמענים הוא נסתר ולכן לא נמצא כחלק מהData. כמו כן בסיום ההודעה לא נסגר החיבור אלא נשלח הודעה חדשה אל נמען אחר ב sponge.com.
POP3
פרוטוקול משיכת המיילים בצד הלקוח.
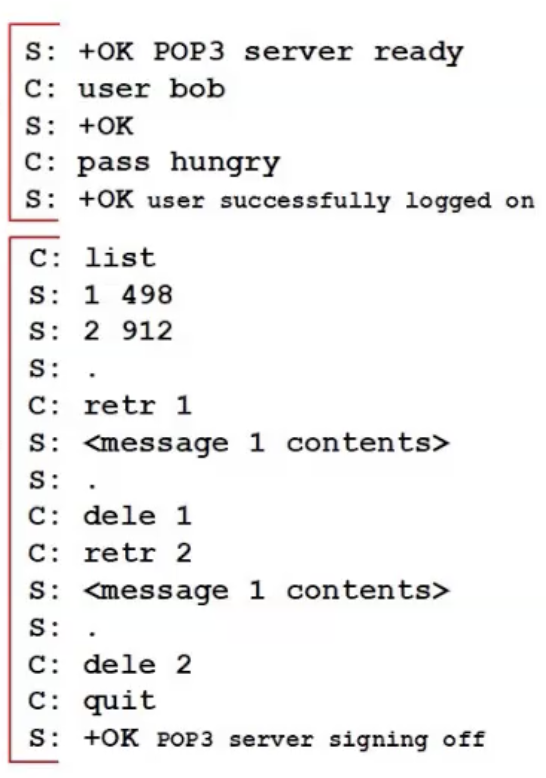
השלב הראשון בflow התקשורת בפרוטוקול זה הוא שלח ה authorization. בשלב זה הלקוח שולח את המשתמש ( user bob ) ולאחר מכן את הסיסמה (pass hungry) והשרת מגיב בהודעת
השלב השני נקרא שלב הtransaction, בשלב זה הלקוח מבקש לקבל רשימת הודעות חדשות באמצעות הפקודה list. השרת יגיב רשימה של tuple של מספר הודעה עם הגודל שלה ויסיים כאשר ישלח את התו ״.״ בשורה ריקה.
לאחר מכן הלקוח יכול להחליט להשתמש בפקודות מסוימות על הודעות מהרשימה למשל dele 1 תמחק את הודעה 1 מהרשימה ו retr 2 תשלוף את המידע מההודעה לפי המספר הודעה.
פרוטוקול POP3 וקודמיו תוכננו במטרה לאפשר למשתמשים שאין להם חיבור-קבוע לשרת הדואר, דוגמת משתמשי מודם חיוג או ADSL, גישה לדואר האלקטרוני שלהם. במרבית המקרים, צד הלקוח מתחבר אל השרת, מוריד ממנו את ההודעות במלואן בסדר שבו התקבלו, ושומר אותן על מחשבו. לאחר מכן ההודעות נמחקות מהשרת. הפרוטוקול תומך באפשרות (אם כי השימוש בה הוא לא-נפוץ) להשאיר עותק מן ההודעה המקורית על השרת. בצורה זו יכול המשתמש לקרוא את הדואר שלו מכמה מקומות וגם מכמה תוכנות לקוח שונות. לכן POP3 הוא stateless לאורך הsession, הוא לא שומר את המידע בשרת.
פרוטוקול נוסף להעברת דואר הוא פרוטוקול IMAP. זהו פרוטוקול חדש יותר ובעל מגוון פונקציות נוספות, כגון אימות מוצפן, הפרדת הדואר לתיקיות-משנה, הפרדה בין כותרי ההודעה לגוף, ועוד. מאחר שזהו פרוטוקול מורכב הרבה יותר, הוא נפוץ פחות ורוב ספקיות האינטרנט אינן מאפשרות גישת IMAP ללקוחותיהן.
בעוד שליחה של דואר אלקטרוני או העברת דואר בין שרתים מתבצעת באמצעות פרוטוקול SMTP והרחבותיו, קריאת דואר על ידי הלקוח תתבצע באמצעות פרוטוקול POP3 או IMAP.

SMTP calculations

קודם כל צריך לדעת מיהו שרת המיילים של israblof.com . לשם כך השולח ירצה לשאול את שרת ה DNS המקומי של הרשת שלו. כיוון שאפשר להניח שיש במטמון את רשומות הNS של COM אז השרת dns המקומי יעבור את השאילתה ״מיהו שרת ה MX של israblof.com?״ אל שרת ה NS של com מבלי לחפש אותו. שרת זה מחזיר את הip של שרת הNS של israblof.com אל שרת הדומיין המקומי והוא ילך לשאול את שרת זה את הכתובת של שרת ה MX המתאים.
כפי שציינו שרתי DNS יודעים לעבור עם priorities ל דומיין וכדי להוריד את העומס השרת ns.israblof.com יחזיר קודם כל העדיפות גבוהה את הכתובת של שרת ה MX : mail.MXrUS.com . ולכן כשהdomain הזה יחזור לשרת הlocal DNS הוא יחזיר את הdomain שאותו יש לחפש (מבלי לצרף הת הIP כמו במקרה של ns.com) ל sender.com . מיד תשלח בקשה נוספת כדי לחפש את הדומיים של שרת הMX והתהליך יעבור שוב דרך ns.com ויוחזר 5.5.6.6 שזה כתובת שרתי ה dns של MXrUS. לאחר פנייה אליו, הוא יחזיר את כתובת ה ip של של המיילים שלהם שתומך בשרת של israblof. כעת אפשר להתחיל לבצע חיבור SMTP לשרת המיילים הזה
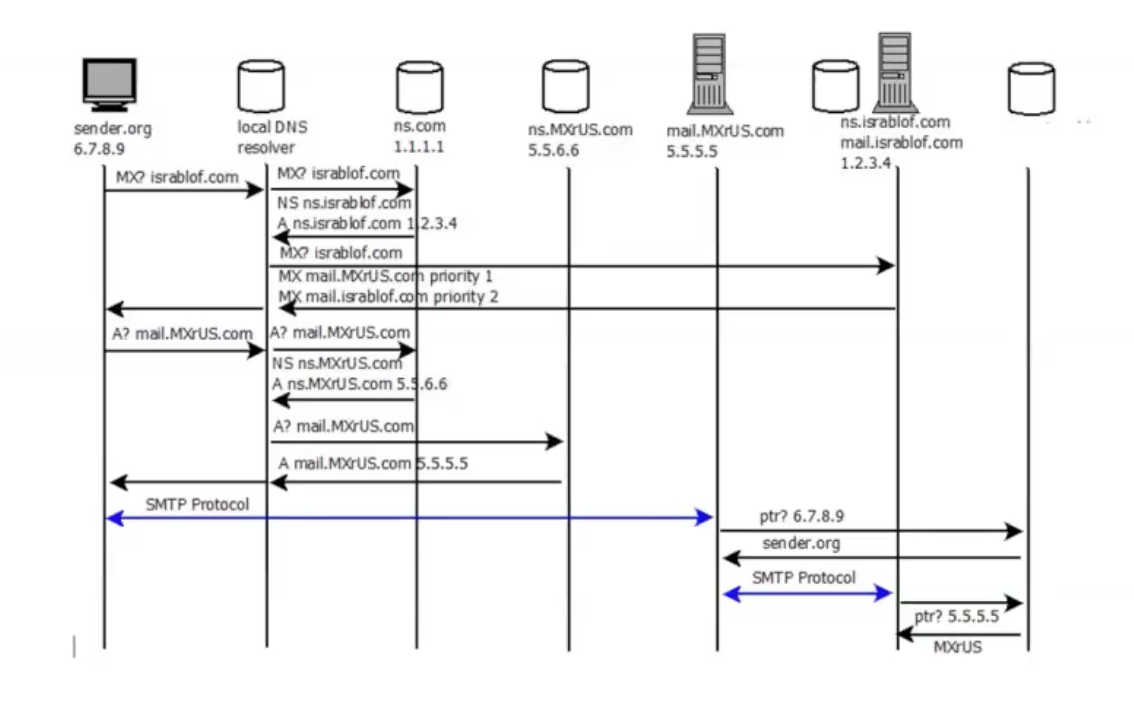
כדי לבדוק את אמינות המידע שרת המיילים שולח בקשת DNS עם ה ip של השולח כדי לוודא שהדומיין הוא אכן שרת מיילים תקין.
מתבצע כעת חיבור SMTP בין שרת המיילים של MXrUS אל mail.israblof וגם הוא מבצע את אותה בדיקת אמינות. והמידע מגיע ליעד.