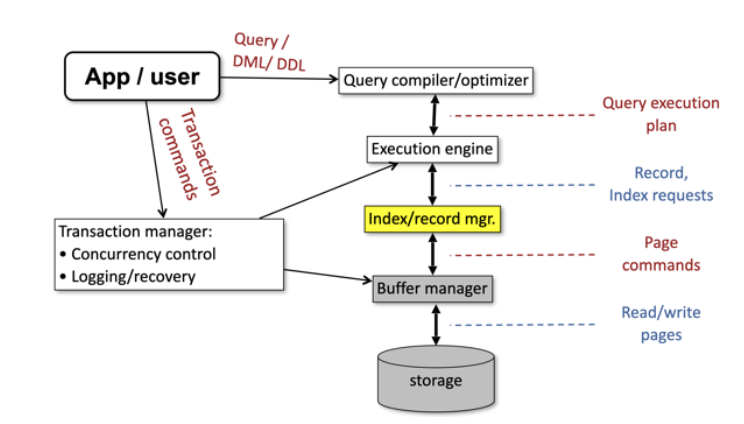
Index manager
נתמקד בחלק של ה index manager שבצד השרת של ה DBMS. תפקידו כמובן הוא להשתמש בתכונות של הrecords כמו indexes על מנת לשלוף את המידע מהזכרון בצורה יעילה יותר.
אינדקסים
באמצעות אינדקסים ניתן להקל על מערכת בסיס הנתונים. כפי שכבר אמרנו באמצעות הגדרת index אנחנו בעצם מייצרים איזשהו יחס סדר על האיברים ובכך מאפשרים חיפוש לא ליניארי של רשומות בטבלה באמצעות הערך שמוגדר כ index.
מדוע בכלל אינדקסים זה דבר נחוץ? הרי בסופו של דבר אמרנו שבניהול האחסון של מסד נתונים לוקחים מידע מתוך הדיסק ושזמן הקריאות והכתיבות הוא החשוב ביותר.
אחסון records
כדי לענות על השאלה הזאת נרצה להבין תחילה כיצד מאוחסנות רשומות של מסד נתונים בתוך הדיסק.
בסופו של דבר כל המידע שלנו הוא מספר גדול של קבצים שמוגדר בתוך הדיסק בסקטורים.
בעצם כל סקטור מכיל קבוצה של רשומות לפי הכמות שהוא יכול להכיל בתוך הקובץ הזה.
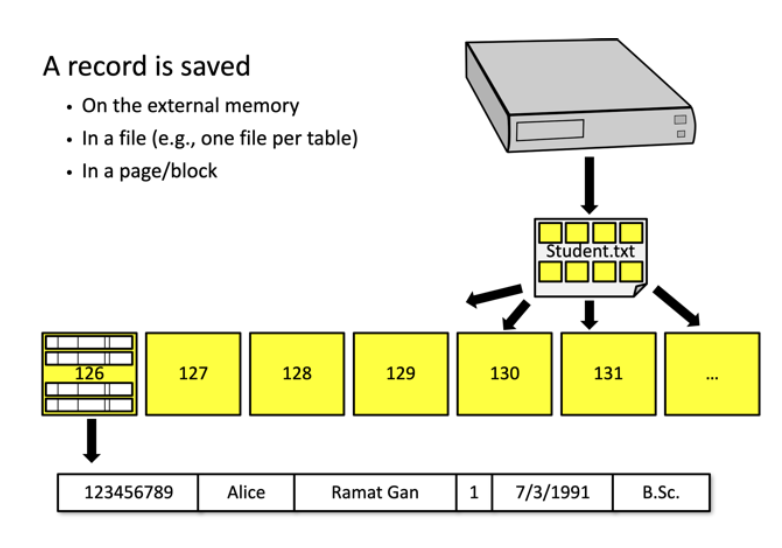
כעת ישנם שתי מקרים שצריך להכיר מהסכמה של טבלה-
כאשר רשומה היא fixed size
כלומר כל השדות הן בגודל חסום מלמעלה. נוכל להעזר בסכמה כדי לבנות מנגנון פרסור לפי הבייטים שכל שדה צורך
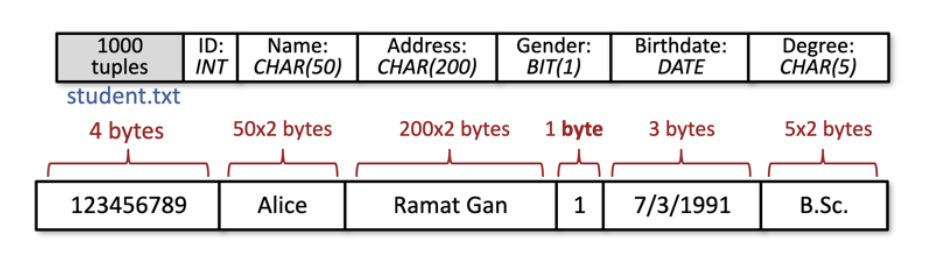
לפי ה טיפוסים בסכמה נוכל לדעת מה הגודל של הrecord.
כאשר רשומה היא variable length
כלומר חלק מהשדות הן בגודל שתלוי בערך למשל VARCHAR .

מצבים אלו הם יותר מורכבים כי למרות שבחלק מהמשתנים יש חסם עליון עדיין זה יכול להיות redundent בכל הקשור לגודל הrecord להחזיק חסם עליון שכזה כמספר הבתים בפרסור, מה גם שברוב המקרים אם נתייחס לחסם זה אנחנו נגלוש למשתנים אחרים.
כדי לטפל במשתנים בגודל לא קבוע נוכל להחזיק metadata על הרשומות כמו למשל הגודל של כל משתנה, זה יבוא לידי ביטוי על ידי:
- header לקובץ והגודל של המטא מידע יהיה קבוע.
- page header שמחזיק את ה record size בכל page
- table header ששומר את מספר ה records בדף.
שיטה זו נוחה וחוסכת זכרון אבל מקשה כמובן על מציאת records ובפרט שדות ספציפיים שכן צריך גם לפרסר meta data.
File organization
נראה 3 גישות לארגון הנתונים בקבצים שירכיבו את מסד נתונים.
Heap File
לא כמו מבנה נתונים של ערימה אלא יותר כמו תור . כל רשומה חדשה תכנס לסוף הקובץ בלי לבזבז זמן על ארגון המידע מחדש. כאשר נרצה למחוק מידע מהקובץ, פשוט נסמן אותו כ deleted.
יתרון - אין overhead עבור הוספת רשומות. פשוט מוסיפים לסוף הקובץ.
חסרון- כיוון שאין יחס סדר על הרשומות, כל שינוי של רשומה או מחיקה ידרוש חיפוש ליניארי.
Sorted File
נאחסן את הרשומות בקובץ באופן ממויין לפי Index כלשהו, בפרט לפי primary key.
יתרון- עריכה של רשומה ומציאה של רשומה הן פעולות מהירה יותר בגלל יחס הסדר.
חסרון- הוספת רשומות יכולה אינן בזמן קבוע שכן כעת צריך למצוא את המקום המתאים עבורן.
Hash Files
הרשומות יהיו מאורגנות במבנה של טבלת Hash. על ידי שימוש בפונקציית הגיבוב על הindexes. בניגוד לקודמים כאן הכנסה וחיפוש תלויות בעיקר בפונקציית הגיבוב ובאיך הטבלה מנוהלת.
זמני ריצה
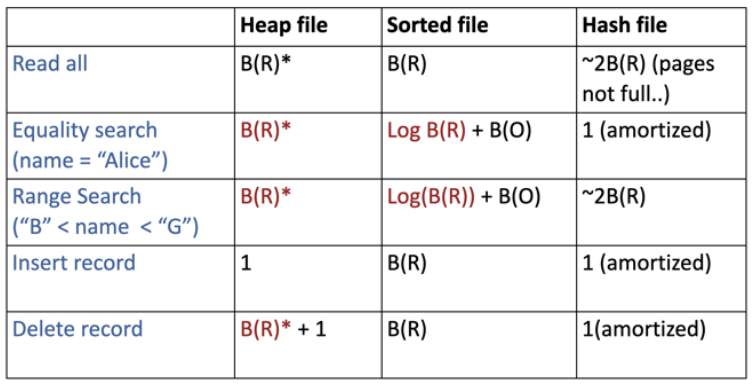
כאשר
מימוש Indexes במסד נתונים
בסופו של דבר index הוא מעין רשימה של פוינטרים במסודר באיזשהו אופן שיאפשר לנו לבצע שאילתות מהירות יותר.
הindexes מוגדרים על שדה אחד או כמה שנקראים Search Key שלפיהם יאורגן המידע. נסמן:
נזכיר שdata entry זה חלק מrecord כלומר שדה ממנו (יכול להיות גם כולו)
סוגים של רשומות ב
- נשמור את כל הרשומה המלאה מהטבלה בתוך מבנה הנתונים שלנו עם מפתח זיהוי שהוא ה Search key ולפי יחס הסדר של אותו מפתח. כלומר המשמעות של זה היא ששומרים את כל הטבלה במבנה הנתונים פשוט בסדר אחר. כמו כן באופן די הגיוני יכול להיות רק index אחד מהצורה הזאת מחשש של שכפול המידע שידרוש תחזוקה רבה יותר.
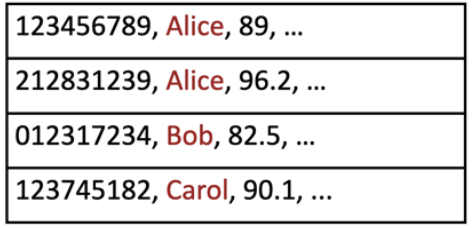
- נשמור tuple מהצורה כך ש הוא פשוט ערך המפתח שלפיו מוצאים את הערך בindex ו RID הוא מזהה כלשהו עבור הרשומה (מצביע לרשומה). כאן נצטרך לעשות שלב נוסף כדי להגיע לרשומה שלנו לפי הsearch key כדי לכתוב ערכים או לגשת לערכים , אבל אנחנו משלמים על index הרבה פחות כבד, גם באחסון וגם בחיפוש.

- נשמור tuple מהצורה כך ש הוא שוב ערך מפתח החיפוש ו הוא רשימה שמכילה את כל המספרים המזהים של כל הרשומות בעלות מפתח . מימוש זה שומר על היתרונות של ובנוסף מוסיך יעילות במקרים בהם יש הרבה רשומות עם ערך כלשהו. למעשה בחיפוש אחד נוכל להגיע לכולם בניגוד לקודם שהיינו צריכים לבצע סריקה ליניארית לשתי כיוונים לאחר שמצאנו ערך בודד.
על פניו
Index classification
כל אינדקס יכול להיות מסווג לפי 6 פרמטרים (כל שורה שאראה עכשיו היא מספר פרמטרים שמתוכם יש לבחור אחד) ואלו מאפיינים את האינדקס.
- סיווג
. - primary או secondary
- clustered או unclustered
- Sparse או Dense
- Single או Multiple
- organization כלומר באיזה פורמט הוא שמור - hash, sorted וכו
Primary/Secondary
על פי פרמטר זה אנחנו מגדירים האם השדה שיוגדר כמפתח חיפוש במבנה הנתונים הוא שדה ה Primary key של הטבלה (מצב זה נקרא primary index) או שדה/ות אחרים (מצב זה נקרא secondary indices).
במצב זה כפי שכבר אמרתי למעלה מתקיים ש
Clustered / Unclustered
מסמן שהרשומות בdata files שמורות באופן זהה לאיך שהערכים מסודרים במבנה הנתונים. אם אינדקס הוא clustered אז הוא מסדר גם את הטבלה המקורית להיות ממויינת לפי האינדקס הזה ולכן יש רק אחד כזה.
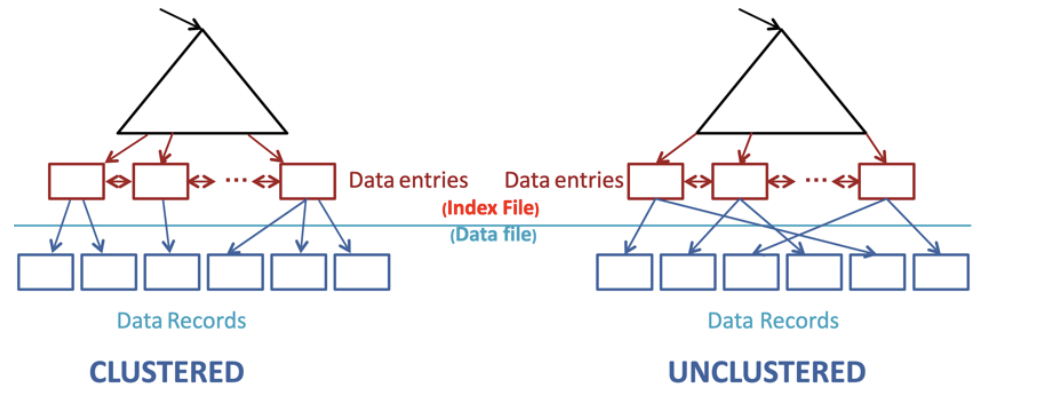
היתרון של clustered הוא ייעול זמני ריצה של פעולות מסויימות למשל כאלו שעוברות על מבנה הנתונים לפי הסדר. זה לא יעילות זמן ריצה אסימפטוטית אלא יעילות מבחינת מטמון והירכיית זכרון שכן אנחנו קופצים בין כתובות סמוכות ומקבלים לוקליות טובה במרחב .
clustered יכול להיות מוגדר עבור מפתח חיפוש אחד בלבד. כלומר יש רק אינדקס אחד מהסוג הזה בטבלה. לכן הוא יבוא בצורה טובה עם אינדקס מסוג
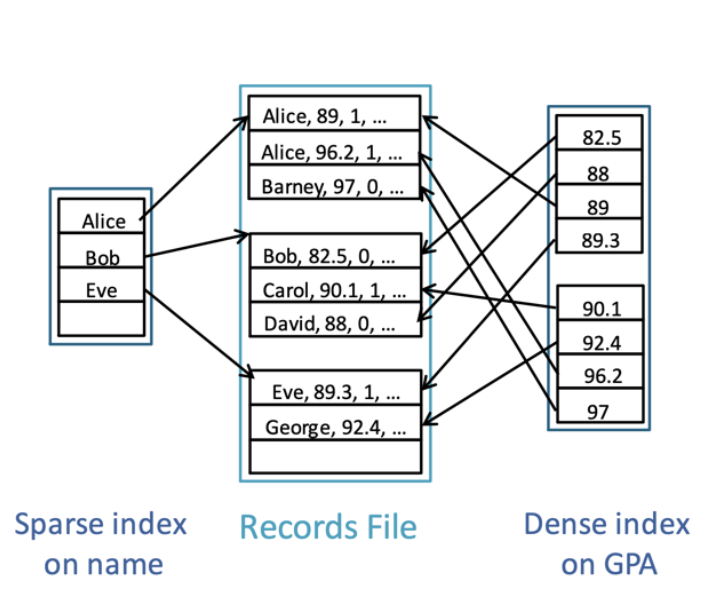
Sparse / Dense
flag שמתאר על מה מצביע כל איבר במבנה הנתונים.
sparse הוא מצב שבוא אני יכול להחזיק באינדקס מצביע לכל דף בדיסק, בגלל שאני מבטיח שהערכים בטבלה נמצאים בין שתי דפים כאלה.
למשל נוכל לדמיין ספרייה שבה אנחנו מחפשים ספר לפי המדף וכל מדף מייצג אות ראשונה בשם הספר.
אינדקס dense מייצג מצב שבו כל ערך שנמצא בטבלה נמצא גם באינדקס זה יכול לקרות במצב שהמידע בטבלה לא ממויין לפי ה search key ואז יש צורך לקפוץ למקומות שונים בזכרון.
מסקנה dense ו unclustered באים ביחד וגם sparse ו clustered באים ביחד.
Single / Multiple
האם מפתח החיפוש מורכב משדה אחד מתוך הטבלה או קבוצה של שדות. כאשר המפתח הוא קבוצה של שדות. במצב שבו מפתח החיפוש הוא מורכב מכמה שדות , ישנה חשיבות לסדר שכן האיבר הראשון בקבוצה יקבע את הסידור של כל הrecords באינדקס והמפתחות הבאים ייקבעו את הסידורים הפנימיים כאשר יש שתי records שהשדה הראשון עבורם שווה (ממש כמו מילון).

Index Organization
אם כן , שאלנו בתחילת הסיכום כיצד אינדקסים יעזרו לנו לנהל את הקבצים. וכאן כבר אנחנו יכולים לענות ולהגיד שלפי המידע שיש על האינדקס מהסיווגים שהראנו למעלה, נוכל לשמור את המידע בקובץ באופן מסויים כלומר, במבנה נתונים כלשהו שיהיה הכי יעיל עבור האינדקסים הקיימים.
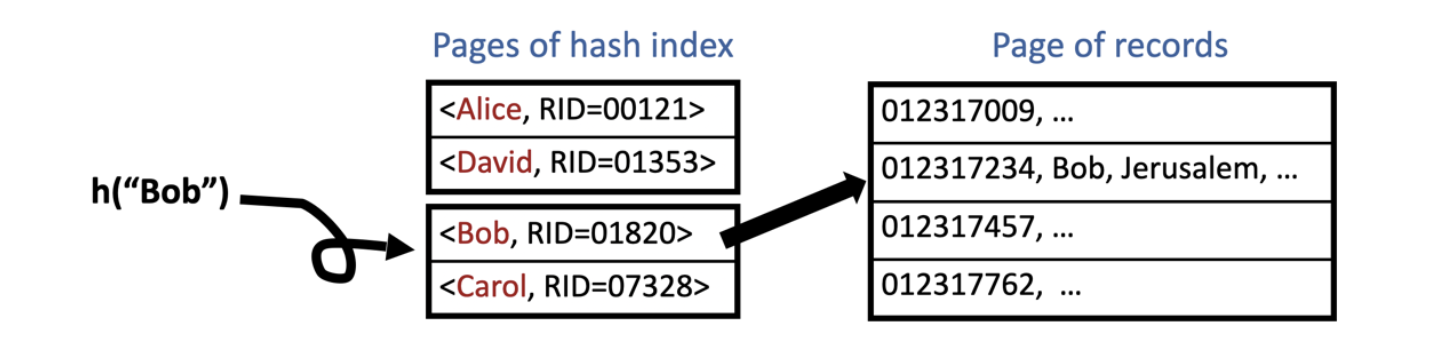
טבלת hash
מימוש אחד של שמירת המידע הוא ב טבלת גיבוב . בהינתן ערך
עצי B+
מקרה פרטי של B-trees שבו כל המידע נמצא בעלים כלומר יש כפילויות של ערכים אבל באופן הזה נוכל לחבר בין העלים עם מצביע וליצור רשימה מקושרת ממויינת. ברמות מעל יש עותקים של המידע. במקרה של מסד נתונים יש כמה דברים שצריך לשים לב אליהם בהקשר של עצי B+ במסדי נתונים
- כל צומת תהיה בגודל page בדיסק על מנת לצמצם את מספר הדפים שניגש אליהם כאשר מסתכלים על ערכים בטווחים קרובים.
- הרשימה המקושרת בהקשר של מסד נתונים מכילה כתובות לדיסק, כיוון שכל צומת ובפרט עלה היא בגודל של page, ערכים שנמצאים באותו עלה מצביעים בדרך כלל על ערכים באותו הpage (מעיד על Rתכונת הspare).
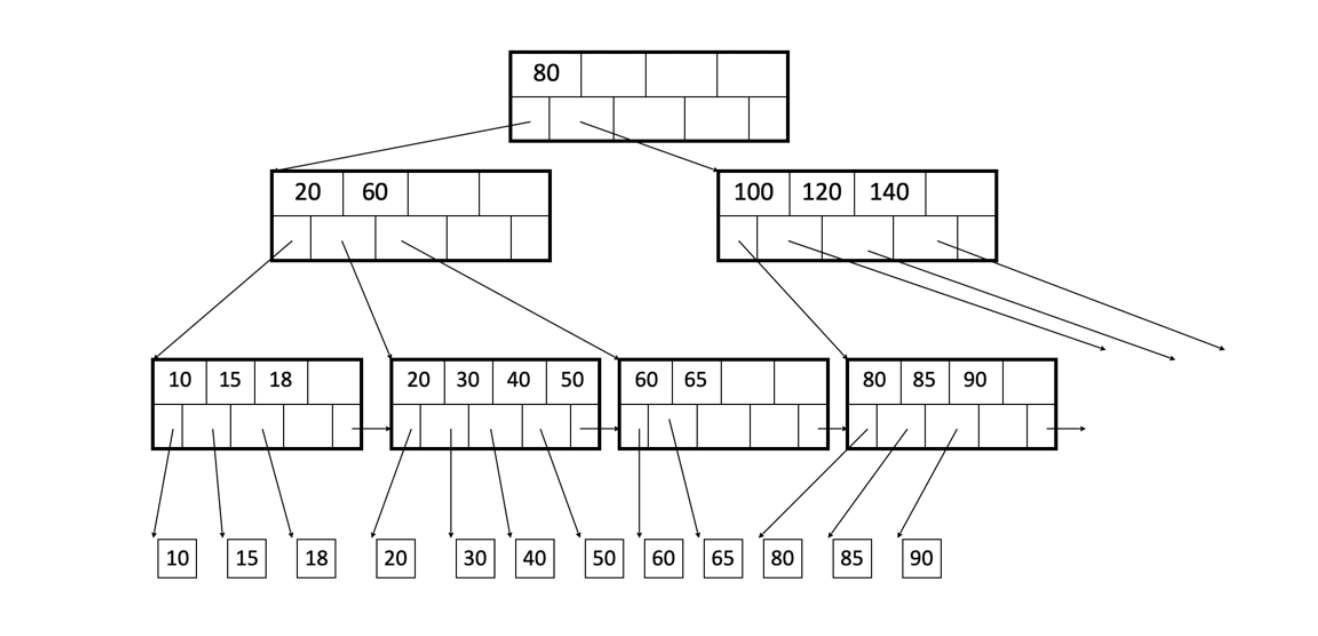

כאשר נניח שבעץ B+ העץ יהיה בעומק שלכל היותר 4 ונוכל תמיד לטעון הכל בזכרון הראשי