ניהול אחסון ב DBMS
מערכות מסדי נתונים תמיד מערבים בתוכן יחידת אחסון נוספת שהיא nonvolatile, הדיסק ורכיב אחר שמאחסן מידע גדול של מידע שלא נמחק ומתעדכן לאורך זמן.
בסופו של דבר צריך לזכור ששרת הוא בסך הכל עוד מחשב והירכיית הזכרון שלו עובדת באופן דומה עד כמעט זהה למחשבים האישיים שלנו. אם כן אנחנו יכולים להסיק שנרצה להבין איך לשמור את המידע ב טכנולוגיית הזכרון שבה נשתמש כדי לגשת למידע שלנו בצורה טובה יותר. למשל אם נשתמש בדיסק נרצה להבין כיצד לשמור את המידע בסקטורים השונים על מנת לגשת אליו בצורה יותר מהירה. יש לכך חשיבות רבה באיך אנחנו נבחר לנהל את הנתונים שלנו.
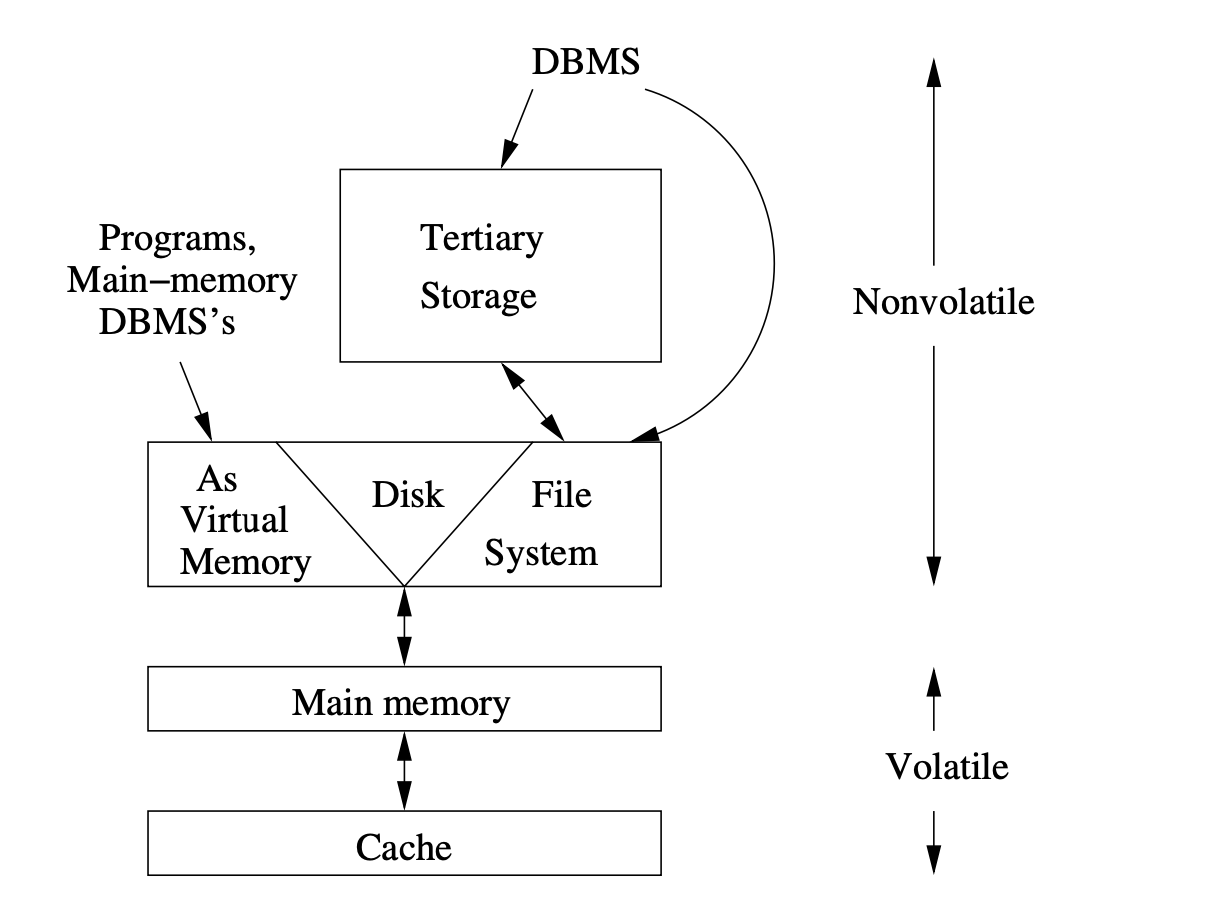
יחידת האחסון המעניינת ביותר ובה נתמקד ברוב ההסבר היא יחידת האחסון המשנית, ה secondary storage. שלרוב היא תהיה מורכבת בעולם של מסדי הנתונים, מדיסק או ממספר כאלו.
יחידת האחסון חשובה נוספת בעולם של מסדי נתונים היא ה tertiary storage שהוא בעצם יחידת האחסון הגדולה ביותר שפותחה לשם החזקת מידע מיחידות מידה של טרה בייטים. הוא מאופיין בזמני read/write גדולים מאוד באופן די הגיוני אבל הוא יכול להחזיק כמות גדולה מאוד של מידע בעלות יותר טובה מדיסק.
האצת הגישה לרכיבי הזכרון
אנחנו כבר יודעים כיצד לחשב את זמן הקריאה והכתיבה בדיסק , אבל בעולם של מסדי נתונים שהוא ברובו עולם מקבילי , ישנה אפשרות שהדיסק יהיה עסוק עם בקשה אחרת עבור process כלשהו.
נגדיר את מודל ה I/O שמאפיין באופן טוב את הזמן שלוקח לפעולה בשרת שלנו להסתיים. ונגדיר מספר שיטות לזירוז של הגישה של מסד הנתונים לדיסק:
- מיקום של מידע באוסף סקטורים בדיסק שנמצאים על אותו track
- חילוק המידע למספר דיסקים קטנים מקום דיסק אחד גדול.
- Mirror של דיסק, יצירת מספר עותקים של המידע על דיסקים אחרים למקרה של כשלון באחד מהם.
- disk scheduling algorithms במערכת ההפעלה או ב DBMS שלנו.
- ביצוע prefetch של מידע ל main memory.
כלים אלו הם חשובים אבל לפני כן נרצה בכלל להבין איך מערכת השרת מבצע
Buffer Manager
ישנם מספר שלבים שצד הserver של הdbms מבצע כדי להחזיר תשובה, אתמקד בשלב הקשור לניהול הזכרון
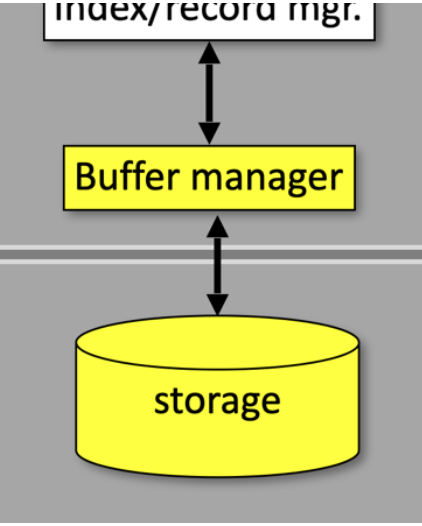
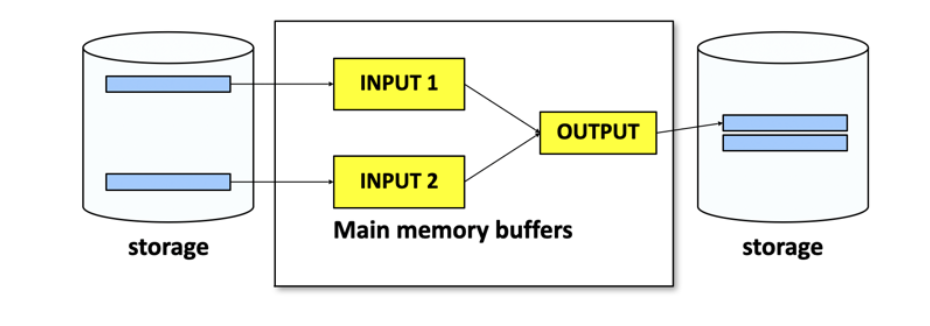
במערכת המסד יש את ה buffer manager שתפקידו לדבר ישירות עם רכיב האחסון ובמצע את פעולות הread write אליו. בדרך כלל גודל של סקטור ממוצע בדיסק הוא כ 4096 בתים והפעולות של ה buffer manager תלויות במגבלה הזאת, שכן, הדיסק יודע לבצע פעולות IO על גודל של סקטור ולא גודל קטן יותר מזה. למעשה ה buffer manager הוא מעין מטווח בין מידע ב DRAM לבין מידע בדיסק. תפקידו של הבאפר הוא להחליט איזה מידע לקחת מהדיסק ולשים אותו בזכרון הראשי, כיצד לכתוב אותו ואיך לאכסן את הסקטורים השונים שנקראים מהדיסק.
הסקטורים שנשמרים ב main memory נקראים frames והאוסף שלהם נקרא buffer pool . אפשר להסתכל עליו כמעין cache policy בין הדיסק לזכרון הראשי כי הוא צריך להחליט את מי להביא ואת מי לשמור בpool.
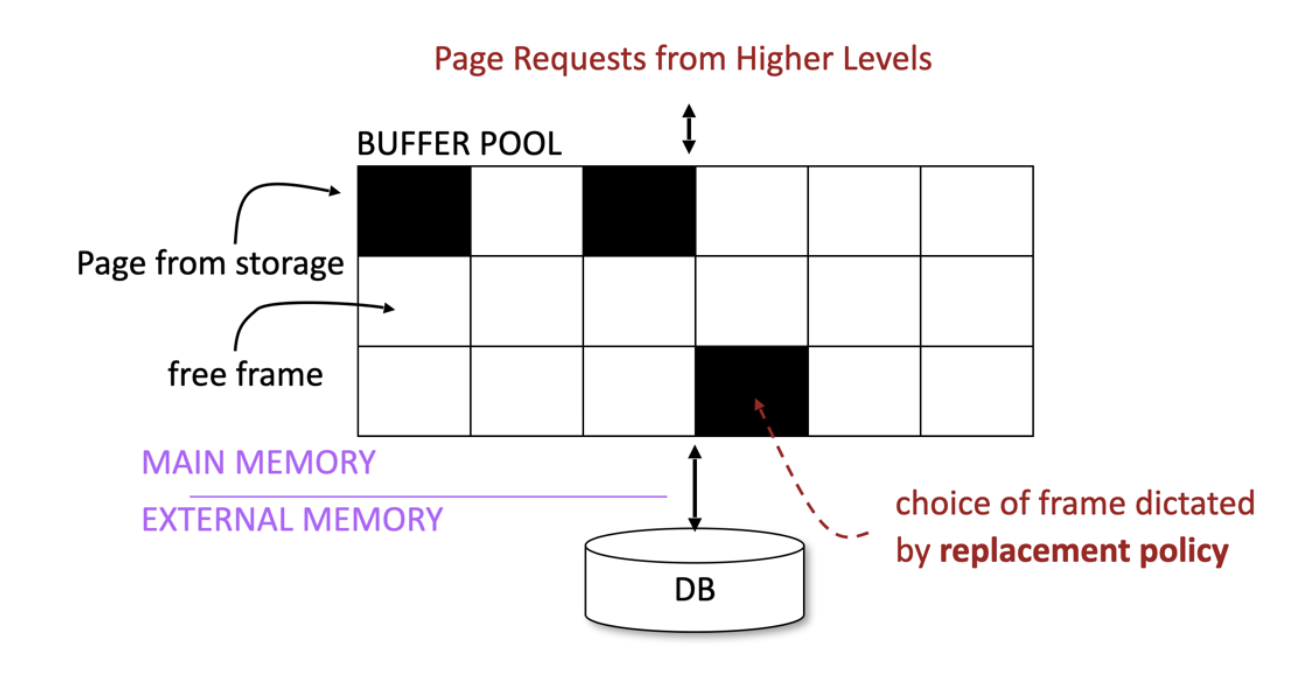
The I/O Model of Computation
נדמיין מחשב פשוט שמריץ DBMS ומנסה לשרת מספר משתמשים שמבצעים שאילתות ושנים את השרת.
נניח גם שלמחשב שלנו יש מעבד אחד , disk-controller אחד ודיסק אחד.
השרת עצמו גדול מדי כדי להיות ב main memory של המחשב שלנו. חלקים אינטרגליים במסד עלולים להיות מועברים לדיסק. מכאן נובע החוק הבא
Dominance of I/O cost
הזמן שלוקח לבצע גישה לדיסק גדול בהרבה מהזמן שלוקח לעדכן את המידע הזה בזכרון הראשי. לכן, מספק הגישות לבלוקים של מידע בדיסק הוא קירוב טוב לזמן שנדרש על ידי אלגוריתם עדכון או חיפוש כלשהו.
דוגמה: נניח שיש לנו מסד נתונים עם טבלה
המשמעות של מודל הניתוח הזה היא שנוכל לתת לקריאה וכתיבה מהדיסק עלות של
מיון
נבין מה קורה במצב שבו ננסה למיין 100 ג״ב של מידע תוך שימוש בזכרון עם מעבר של 4 ג״ב RAM. המיון נעשה בהרבה מאוד הקשרים בשימוש של בסיסי נתונים למשל בפקודות SQL כל הפקודות ORDER BY ו GROUP BY ונוספות משתמשות במיון כזה או אחר.
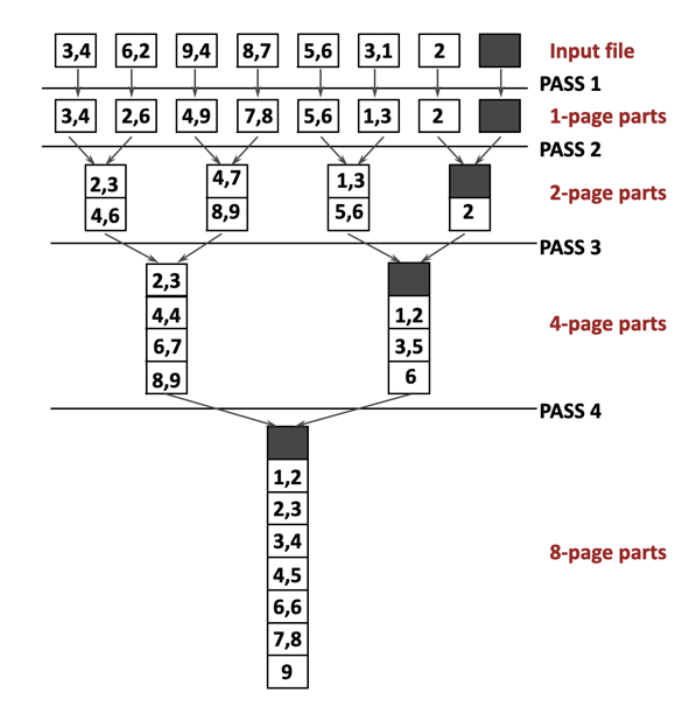
שלב ראשון בשלב הראשון נקרא סקטורים מהדיסק נמיין אותם in place (כלומר לא נייצר עותק ממויין אלא נמיין את מי שלקחנו) ונחזיר לדיסק. בממוצע אנחנו ממלאים כל פעם 4 ג״ב של מידע בתוך הpool.
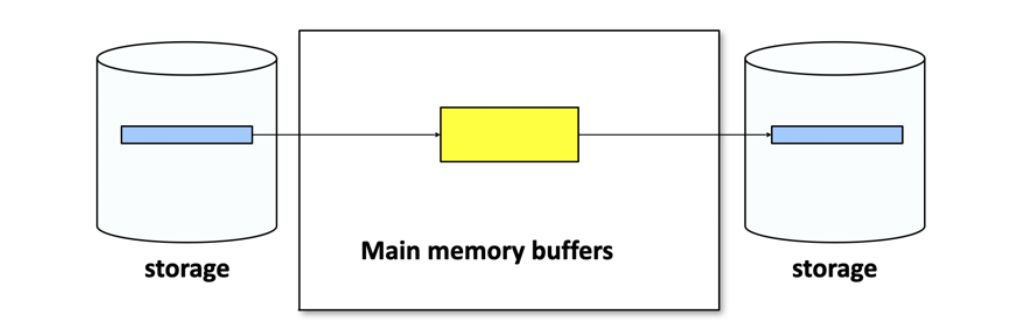
שלב שני יש לנו סקטורים ממויינים של מידע שנמצאים בדיסק, ניקח זוגות שלהם ונאחד אותם לפלט ממויין אותו נכתוב בחזרה באחסון.
נצטרך עבור פעולה זאת 3 פריימים בלבד מתוך הבאפר. שתי פריימים ישמשו לאחסון שני הדפים. פריים נוסף יכיל את החצי הראשון של המידע הממויין לאחר המיזוג, יכתוב אותו, ולאחר מכן ייקח את החצי השני ויכתוב גם אותו.
למעשה האלגוריתם הנ״ל ממשיך ככה באופן שמאוד דומה ל merge sort . כל פעם ניקח יותר סקטורים ממויינים לזכרון , באיטרציה ה
ניתוח סיבוכיות :
כפי שאמרנו אנחנו מנתחים סיבוכיות שהקשר של פעולות
ננסה לנתח את הדפוס שהבאנו למעלה,
נשים לב שהאלגוריתם בכל שלב קורה כל פעם את כל
נשאלת השאלה כמה איטרציות? בדומה לmerge sort נבצע
פעולות כתיבה וקריאה לדיסק.
האם ניתן לשפר?
נשים לב שאכן השתמשנו במספר המינימלי של פעולות קריאה/כתיבה בכל איטרציה ולא נוכל לשפר את זה, שכן קראנו וכתבנו את המידע פעם אחת בכל איטרציה. אולי נוכל אם כן , לשפר את כמות האיטרציות שנעשה.
נסמן
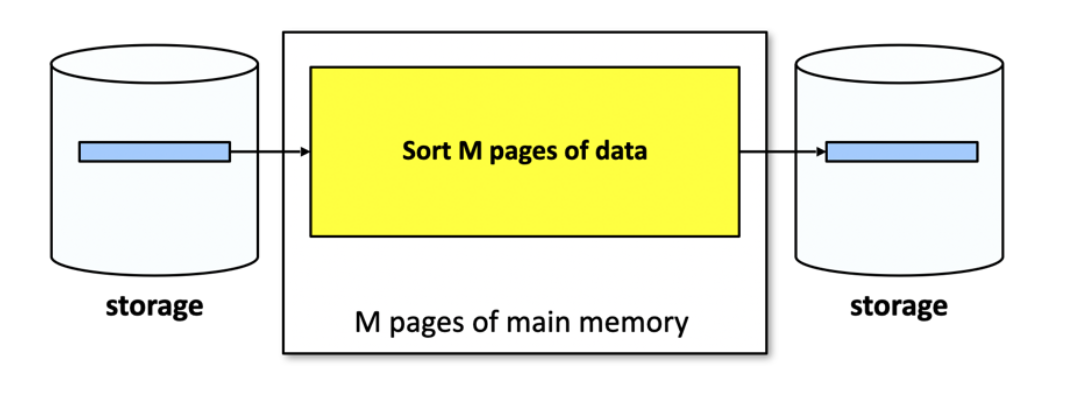
נוכל להקטין את כמות האיטרציות על ידי מילוי הבריכה כלומר בכל איטרציה למיין ולכתוב
שלב ראשון העלה לזכרון
שלב שני יש לנו כעת
מכאן כבר בגלל פעולת המיזוג נרצה לשמור output page אחד בדומה לאלגוריתם הקודם. כעת אנחנו מחזיקים דף אחד שתפוס לנו ל output. בדומה לאלגוריתם הקודם נמלא את הram ב
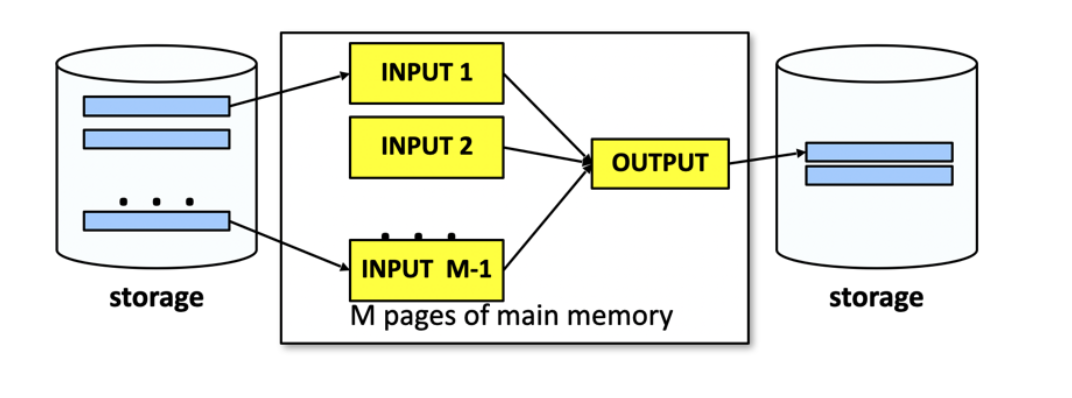
שלב שלישי כעת, נעשה אותו דבר פשוט הפעם יש לנו קבוצות בגודל
באופן כללי באיטרציה ה
סך הכל זמן I/O יהיה
כאשר אנחנו מנסים לתכנן אלגוריתם לשליפת מידע מהאחסון שנמצא בשרת השיקול המרכזי שלנו יהיה מספר הקריאות והכתיבות לדיסק.