אופטמיזציית שאילתות
נרצה להבין את התהליך שבו ה Query Compiler לוקח שאילתה דיקלרטיבית ושולח אותה מתורגמת בצורה היעילה ביותר באופן אימפרטיבי באמצעות אלגברה רלציונית .
מה שחשוב לזכור זה שבהינתן שאילתה, ישנן כמה דרכים שבאמצעותן ניתן לחשב את מה שהיא מבקשת אם נסתכל למשל על הדוגמא הבאה:
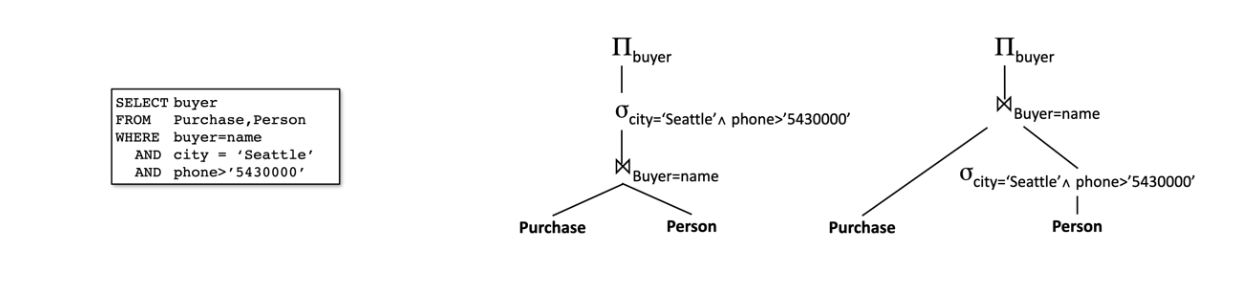
שני עצי החישוב הם דרכים אפשריות להביא את התוצאות המבוקשות, אך כל דרך עלולה לדרוש מידת מאמץ שונה מה Execution engine. בעצם התפקיד של ה Query Optimizer הוא לקחת את האשילתה המילולית כמו שמופיעה בצד שמאל ולתרגם אותה לעץ חישוב שייצג את הדרך היעילה ביותר לבצע את הפעולה.
Query Plan
סדר הפעולות שה dbms צריך לבע על מנת להוציא שאילתה כלשהי לפועל. למעשה מה שמיוצג בכל אחד מהעצים הנ״ל זה plan עצמו שמתאר באופן אימפרטיבי את סדר הפעולות שיש לבצע כדי להביא את המידע הדרוש.
תרגום שאילתה ל Query plan
נבנה אלגוריתם כללי שמתרגם את השאילתה לתוכנית ביצוע
א) מתחילים ברשימת ה FROM. באמצעות שורה זו אנחנו יכולים לדעת בידיוק מה הרלציות שמעורבות בשאילתה וכמו כן אנו יכולים לקבל אינדיקציה ראשונית האם מתבצעת פעולת JOIN (בדרך כלל קורה כאשר יש יותר מטבלה אחת בשורה זו). על כל אלו מבצעים מכפלה קרטזית.
ב) נעבור ל WHERE. על מה שהחוזר מהמכפלה הקרטזית מבצעים Selection על כל התנאים שמופיעים ברשימה זו.
ג) נבצע Group By או Having מעל מה שהתקבל בשלב הקודם.
ד) מסתכלים על שורת הSelect ועל כל מה שהתקבל בתת העץ של הפעולות הקודמות מפעילים Projection לפי זה.
כללי אצבע לאופטימיזציית שאילתה
א) לבצע פעולות Selection שכלולות בשאילתה הכי מוקדם שאפשר ואיפה שאפשר.
הסיבה בעצם שנרצה להקדים Selection לשלב מוקדם יותר בחישוב השאילתה היא שאם אנחנו עושים זאת אנחנו מבצעים סינון בסיסי ראשונים לרלציות עליהן אנחנו עובדים ונשארים עם פחות ערכים, וכך כל שאר הפעולות שיתרחשו בהמשך חישוב השאילתה יפעלו על פחות עצמים.
ב) לבצע פעולות Projection הכי מוקדם שאפשר ואיפה שאפשר. נזכור כי בפעולת
Projection אנחנו בעצם מסננים עמודות מתוך הטבלה ומעיפים את אלו שלא רלוונטיים אלנו. חשוב אם כך לשים לב שכאשר אנחנו מבצעים את פעולת ה-Projection בשלב הראשוני אנחנו לא זורקים עמודות שיתכן ונשתמש בהם בהמשך. מקרה כזה הוא למשל כאשר אנחנו עושים Join בין שתי טבלאות לפי שדות מסוימים אבל בסופו של דבר מה שאנחנו מחזירים ב-SELECT של השאילתה זה אחד מהשדות שלא היו רלוונטיים ב-Join. במקרה כזה אם היינו מעיפים מהרלציות את אותן שדות בשלב הראשוני לפני ה-Join היינו נתקלים בבעיה מאוחר יותר כשהיינו צריכים להחזיר ערכים.
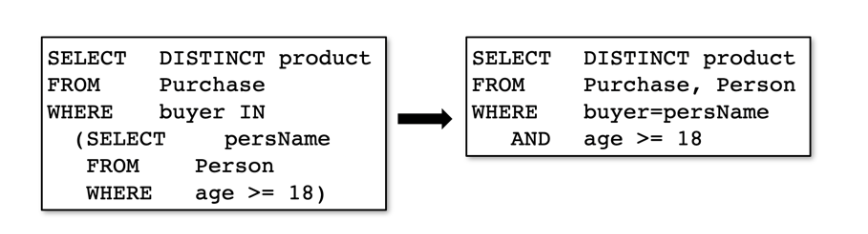
ג) נרצה שיהיו לנו כמה שפחות שאילתות מקוננות Nested Queries. הרבה פעמים יותר נוח לוגית לכתוב שאילתה בעזרת שאילתה מקוננת, בזמן של-Optimizer שאילתות כאלה בדרך כלל יותר קשות לביצוע. על כן מומלץ לנסות לעשות Unnesting לשאילתות מקוננות ולשלב אותן בצורה לוגית נכונה בשאילתה הראשית:
Pipelining
נשים לב שכאשר יש לנו Query Plan שמורכב משרשרת של הרבה פעולות שמתבצעות על רלציה העלות של כל פעולה אינדיבידואלית בעץ תלויה בגודל הקלט שלה עצמה, או במילים אחרות תלויה בגודל הפלט של הפעולה שלפניה. על פי עקרון ה-Pipelining, נרצה להעביר כל רשומת פלט מפעולה אחת ישירות לפעולה הבאה בתור ב-Main Memory במידה ואנחנו יכולים לעשות זאת. דבר זה בעצם יחסוך לנו פעולת כתיבה של פלט הפעולה הקודמת ופעולת קריאה של פלט זה על ידי הפעולה הבאה בתור. נשים לב שלא ניתן תמיד לעשות Pipeline לפלט של כל פעולה- זה תלוי בפעולה, גודל הפלט שהיא מחזירה וכמות הזיכרון הפנוי שנשאר לנו ב-Main Memory.