שיערוך שאילתות
לאחר שתיארנו שבסוף שאילתה שכתובה בשפה דיקלרטיבית כמו SQL מתורגמנת ל אלגברה רלציונית נשאלת השאלה כיצר מערכת בסיס הנתונים יודעת לקחת את ה Query plan ולהביא באמצעותה מידע קונקרטי ממאגר הנתונים בצורה יעילה וחכמה.
סימונים:
מייצג את הגודל ב Pages בדיסק. מספר הרשומות מייצג את מספר הערכים הייחודיים שיש בעמודה של ״.״.
כאשר ״.״ יכול להיות
מימוש פעולת DISTINCT
נרצה להוריד כפילויות מטבלה נתונה.
אם יש מספיק מקום בזכרון ניתן לממש את הפעולה על ידי מבנה נתונים חיפושי כמו טבלת גיבוב. לכל רשומה ב
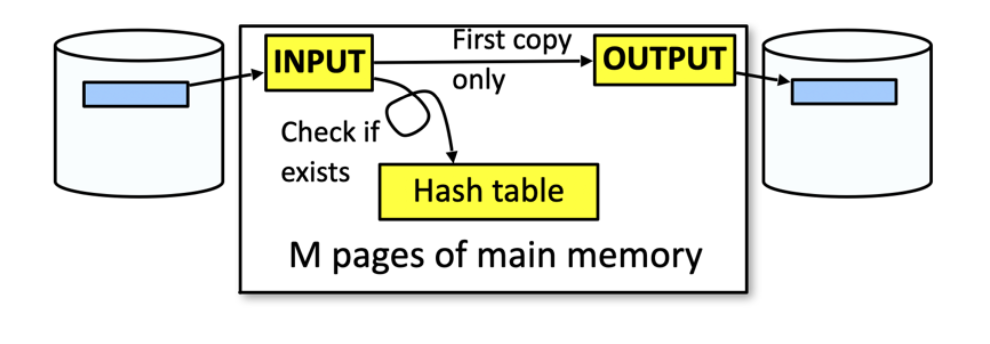
כיוון שאת טבלת הגיבוב מחזיקים בזכרון ולא באחסון חיצוני, אנחנו מבצעים על כל רשומה פעולת קריאה אחת ופעולת כתיבה אחת לכל היותר. וכן העלות היא
במצב שבו אין מספיק זכרון לאחסן טבלת גיבוב אבל כן המידע מאורגן בצורה ממוינת בתוך הזכרון, נוכל פשוט לקרוא את כל המידע מהאחסון ולרשום בחזרה רק את העותק הראשון של כל רשומה. העלות היא זהה.
במצב זה נוכל פשוט למיין עם מיון מיזוג Storage Management והעלות תהיה כעלות המיון
מימוש פעולת UNION
כל מה שצריך כדי לממש את הפעולה הזאת היא פשוט סריקה מלאה של שתי הטבלאות. אם נרצה לשלב את שתי הטבלאות בלי כפילויות נוכל לבצע full scan ואז distinct.
אם נרצה לממש פעולה הפרש כלומר למצוא רק את מה ששייך לטבלה
אם הזכרון גדול מספיק, נוכל לתחזק טבלת גיבוב כמו מקודם ולהוסיף אליה את טבלה
מימוש פעולת SELECT
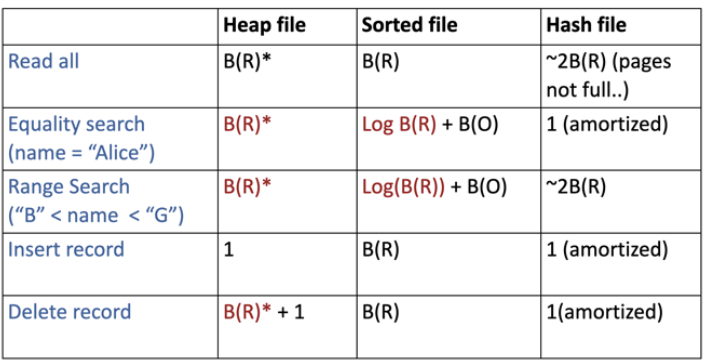
זמני הריצה מצויינים תחת השורה של equality search במידה ואין לנו אינדקסים על בסיס הנתונים. אם יש סידור כלשהו לפי אינדקס בבסיס הנתונים נחלק למקרים.
אם האינדקס הוא clustered אז מספר פעולות הקריאה יהיה
במידה והאינדקס הוא unclustered הסדר באינדקס לא בהכרח מעיד על הסדר בזכרון ולכן העלות יכולה להיות לכל היותר
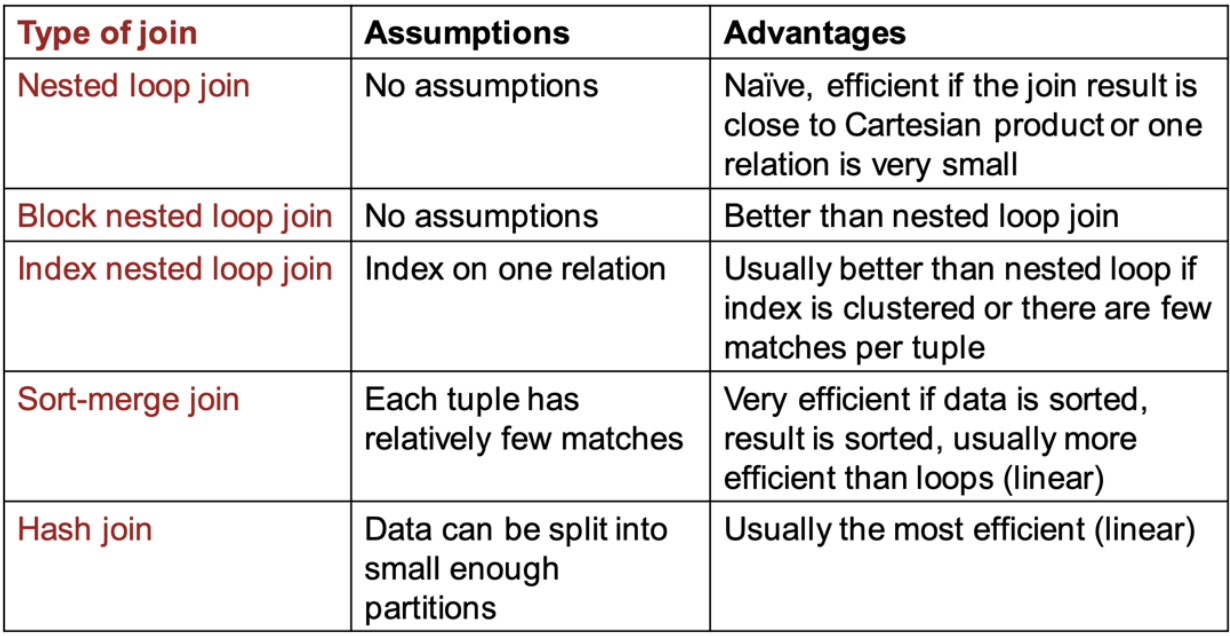
מימוש מכפלה קרטזית
פעולה זאת תבסס את העלויות של פעולות JOIN.
המשמעות של מכפלה קרטזית בין שתי רלציות
ניתן לממש זאת פשוט בצורה נאיבית על ידי לולאה מקוננת- עוברים על אובייקט בטבלה
מימוש פעולת JOIN
לאחר שראינו כיצד לממש פעולת מכפלה קרטזית באופן נאיבי, נרצה לנתח את עלות פעולת הjoin.
המימוש ה״נאיבי״ יהיה לבצע לולאה מקוננת ליצרת כל קומבינציה אפשרית בין שתי רשומות מהטבלאות אבל משאירים בסוף רק את הרשומות שמקיימות את תנאי ה JOIN. מימוש זה לא חכם במיוחד שכן אנחנו בונים את כל המכפלה הקרטזית רק בשביל זה.
נממש באופן יותר טוב עם Block Nested Join Loop, ובו במקום לקרוא דף בודד מ
נניח שיש מספיק מקום ל
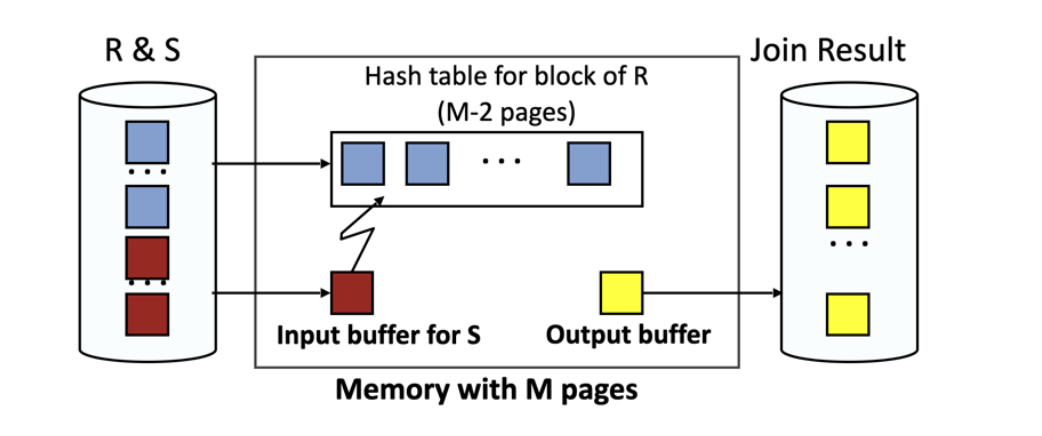
נשים לב שהתיקון הזה צמצם את כמות הקריאות שלוקחים את
מימוש ל JOIN מבוסס אינדקסים
נניח כי יש לנו אינדקס על העמודה
כלומר שמירת הרשומות בטבלאות המקיימות שיוויון בין העמודות
באופן מסויים נוכל להסתכל על זה בצורה הנאיבית של שילוב של שתי שאילתות, כלומר נבצע מכפלה קרטזית ואז SELECT. כלומר, עבור כל דף ב
כי נצטרך לקרוא את כל הדפים של
הסיבה לכך היא שאם נניח שההתפלגות של מספר ההופעות של הערכים השונים משדה
מכאן, שמתוך
Sort-Merge Join
הרעיון מאחורי אלגוריתם זה הוא שאם הרלציות
- נקרא דף מ
ודף מ - נמצא התאמות בין שניהם (שזה יחסית קל בגלל הסדר הממוין)
- אם הגענו לסוף של
והערך האחרון שם קטן לפי יחס הסדר מהערך שאנחנו עליו ב , נקרא דף נוסף מ , אחרת נקרא דף נוסף מ . - נמשיך ככה עד שנסיים גם את
וגם את .
נוכל למיין על ידי שימוש ב Merge Sort והעלות של שלב המיון של כל רלצייה יהיה
העלות על חיפוש הערכים בין שתי הטבלאות תהיה כעלות של מעבר על שתי רלציות בשלמותן
Hash Join
ניקח את כל הטבלה
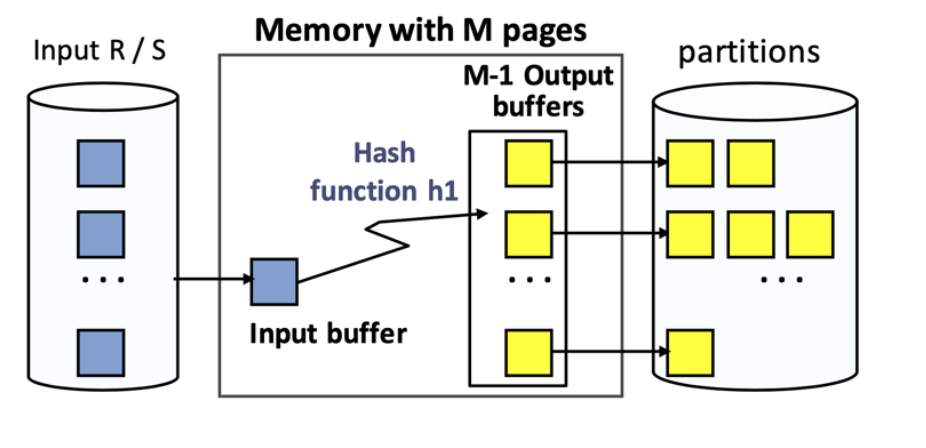
כעת אנחנו יודעים עבור כל טאפל לאיזה תא הוא שייך בטבלת ההאש. על כל חלוקה
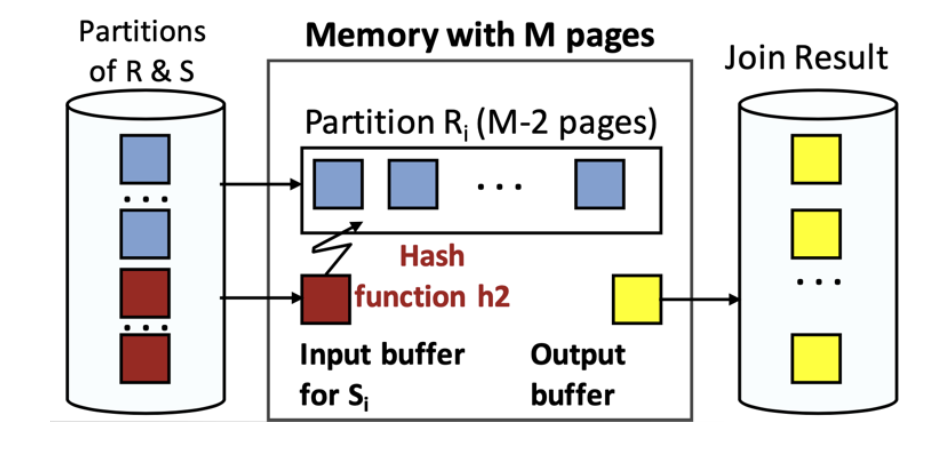
העלות של אלגוריתם היא
א) קריאת של שתי הטבלאות כדי להפעיל עליהן hash.
ב) כתיבת כל המיפויים לזכרון
ג) הוצאת כל קבוצה בחלוקה שזה וכתיבה שזה סך הכל שקול לשתי השלבים הנ״ל
כלומר סך הכל כתבנו את
לא תמיד ניתן להשתמש באלגוריתם זה ביעילות שכזו. יש לנו מגבלה שהיא הזכרון ראשי. אם הוא יכול להכיל בכל רגע נתון רק
לסיכום: האלגוריתמים של join