Design of Relational Database Schemas
כפי שאמרנו ב בבסיס של עיצוב מסדי נתונים, בחירה חסרת שיקול של סכמה עבור מסד נתוניום רלציוני יכולה להוביל לדו משמעויות במסד, למידע מיותר ולחריגות בהתאם.
למשל נתבונן בטבלה הבאה
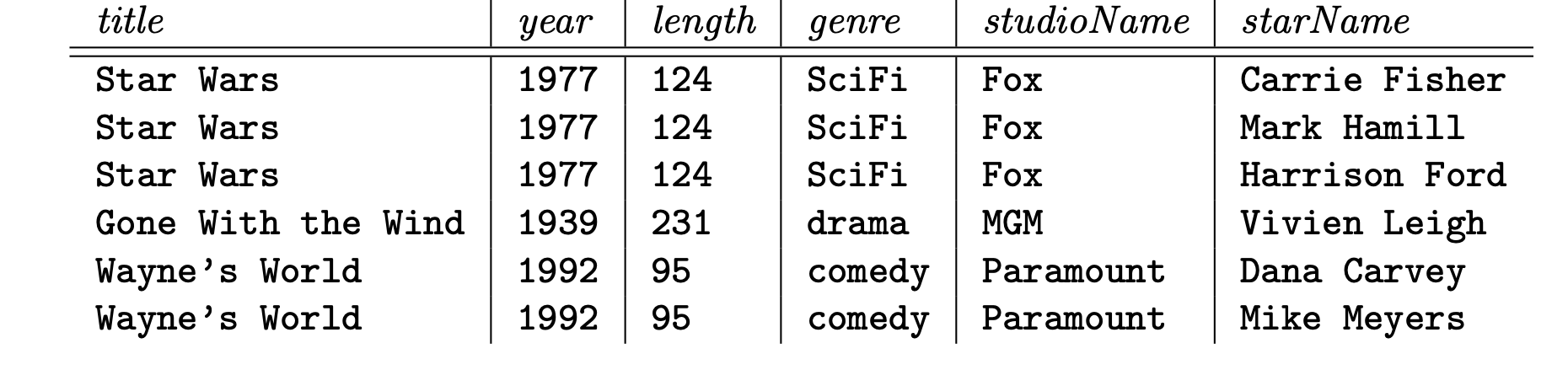
נשים לב שישנה חזרה על פרמטים בגלל בעמודה של שם השחקן. החזרה הזאת היא מיותרת והיא יכולה לגרום למספר שגיאות שנראה בהמשך.
אם כן, נרצה להבין
א) איזה שגיאות יכולות להגרם מתכנון לא נכון של סכמה
ב) נרצה להציג את הרעיון של decomposition כלומר, שבירה של סכמה לסכמות קטנות יותר.
ג) איזה תנאים נוכל לבדוק על סכמה כדי להמנע מהמצבים למעלה
ד) נרצה לראות כיצד ניתן להבטיח שהבעיות הנ״ל לא יתקיימו על ידי שימוש בדיקומפוזיציה.
חריגות
בעיות כמו redundancy שקורות כאשר אנחנו מנסים לדחו יותר מדי מידע לטבלה אחת נקראת ״חריגה״. החריגות הראשיות שנתקל בהם:
א) Redundancy- מידע עלול לחזור על עצמו במספר tuples.
ב) עדכון חריגות- נוכל לעדכן מידע ב tuple מסויים אבל לשכוח לעדכן באחד אחר.
ג) מחיקת חריגות- אם קבוצת ערכים הופכת לריקה, אנחנו עלולים לאבד מידע נוסף כתוצר לוואי. למשל, אם נמחק את Vivien מהטבלה שבתמונה למעלה אנחנו נמחק גם את הtuple האחרון עם המידע על הסרט gone with the wind.
Decomposing relations
הדרך המקובלת להורדת החריגות הנ״ל היא על ידי דיקומפוזיציה של טבלאות.
דיקומפוזיציה של
כעת, נבחן כיצד ניתן ליצור דיקומופוזציה שמטפלת בחריגות
בהינתן
ניקח את הטבלה לדוגמה מלמעלה ונבצע עליה דיקומפוזציה
נגדיר טבלה חדשה Movies2 בלי starName.
נגדיר טבלה חדשה Movies3 עם התכונות title, year, starName נקבל את הטלבאות הבאות
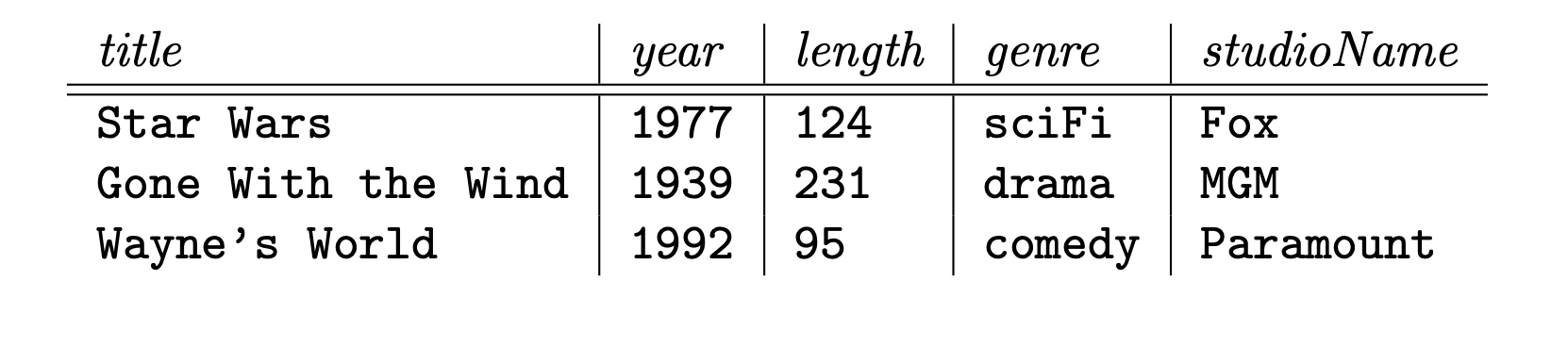
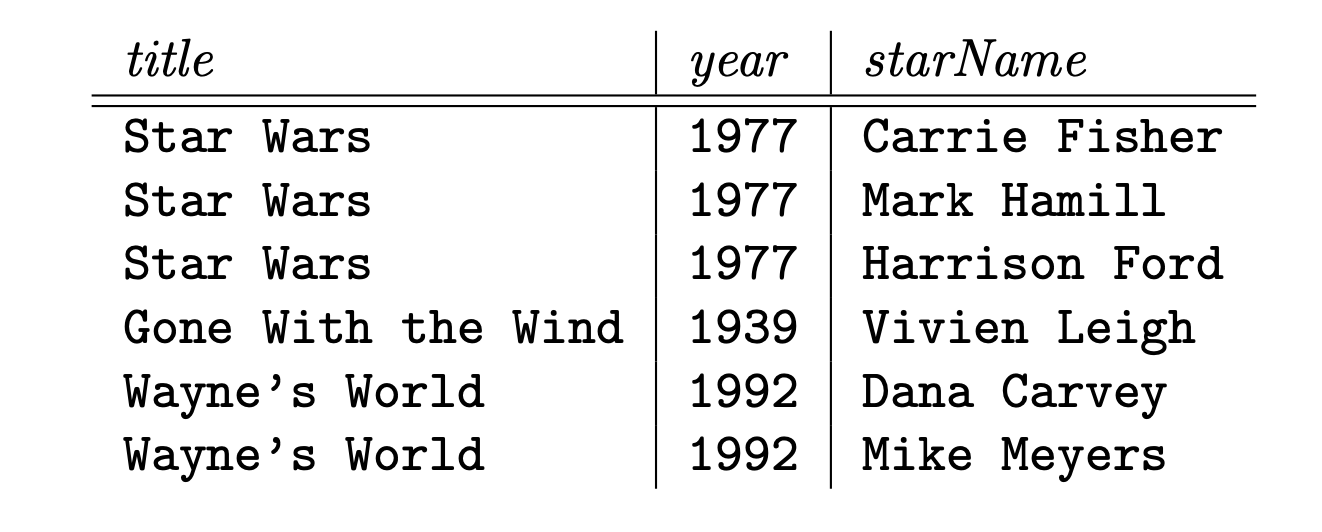
נשים לב שהדיקומפוזציה שביצענו מורידה את החריגות שדיברנו עליהן, למשל האורך של כל סרט מופיע רק פעם אחת בטבלה Movies2.
הסיכון בעדכון חריגה נעלם גם כן, כעת עדכון אורך של סרט יקרה רק בשורה אחת בלבד ולא נצטרך לעשות זאת על מספר רב של שורות.
ולקינוח, גם אם נמחק את השחקן מ gone with the wind לא נסתכן באיבוד מידע על הסרט כיוון שהוא שמור בטבלה אחרת.
על פניו גם נראה שכן יש דברים מיותרים ב movies3 כי השנה והכותרת של הסרט מופיעים מספר פעמים, אבל זאת חזרה תקינה כי שתי הפרמטרים האלו מהווים מפתח לסרטים ואין דרך חלופית לייצג סרט. כמו כן אין אפשרות לעדכון חריגה בטבלה 3 שכן, אם נשנה את השם או השנה זה לכאורה סרט אחר לגמרי, ואם נשנה את השחקן אין לזה השפעה בשום מקום אחר.
Lossless decomposition
נשים לב שהדיקומפוזיציה שעשינו למעלה נקראת Lossless.
הגדרה:
בהינתן
היא דיקומפיזצייה חסרת הפסד אם איחוד שתי ההקרנות ייתן את
Boyce-Codd Normal Form
המטרה של דיקומפוזציה היא להחליף את הטבלה על ידי כמה כך שלא יהיו חריגות.
אם כן, מסתבר שיש תנאי פשוט שניתן להשתמש בו כדי לבדוק האם אחת מהחריגות שנמצאות למעלה לא קיימות.
התנאי הזה נקרא Boyce-Codd normal form או BCNF.
טענה: טבלה
במילים אחרות, נוכל להגיד שאם קבוצת תכונות מאפיינת תכונה מסויימת, אז היא חייבת לאפיין את כל התכונות האחרות.
מסקנה: אין צורך שכל המפתחות של טבלה יהיו נוכחים בצד שמאל של FD כדי לקיים BCNF. (כמובן שיכולים להיות יותר ממפתח אחד לטבלה).
נחזור לדוגמה של Movies1 הטבלה הראשונה למעלה. זאת אינה BCNF אומנם קשה לראות את זה, אבל כדי להבין נרצה להגיד קודם את המפתחות. קל לראות שהמפתח הוא
נוכל לראות שזה לא מקיים את התנאי של BCNF בגלל ש יתקיים ש
title year -> lenght genre studioName
כלומר, הצלחנו למצוא FD לא טריוויאלי שבצד שמאל אין סופר מפתח. נשים לב שבטבאלות שיצרנו לאחר הדיקומפוזציה זה אכן BCNF .
טענה:
כל טבלה עם שתי תכונות תקיים את הBCNF. ההוכחה פשוטה רק צריך לבחור את כל המקרים האפשריים כאשר יש שתי תכונות A,B.
א) אם אין בכלל FD אינם טריוואלים, התנאי מתקיים באופן ריק. כיוון ש
ב)
ג)
ד) גם
Decomposition into BCNF
על ידי בחירה חוזרת של דיקומפוזיציות מסוימות, נוכל לפרק כל סכמה לאוסף של תתי קבוצות של התכונות שמוגדרות מהסכמה הזאת עם התכונות הבאות
א) כל תתי הקבוצות הם סכמות שמקיימות BCNF
ב) הדיקומפוזיצייה חסרת הפסד, כלומר, שום מידע לא נאבד כתוצאה מהפירוק הזה.
על פניו נראה מהטענה למעלה שכל מה שצריך לעשות זה לפרק את הסכמה לתתי קבוצות של 2 והתוצאה היא בטוח BCNF. עם זאת, דיקומפוזציה כה שרירותית לא תקיים את תנאי 2 ומידע עלול להיאבד בדרך.
אם כן עלינו להיות זהירים ולהשתמש ב FD שמפירים את תנאי ה BCNF כדי להנחות את הדיקומפוזצייה שלנו.
אלגוריתם 1:
BCNF-decompose(R={A1,...,An,B1,...Bm,C1,...Ck}) {
if exists a FD A1,...,An-> B1,...Bm that violate BCNF {
R1 = {A1,....An,B1,....Bm}
R2 = {A1,....An, C1,.... Ck}
return BCNF-decompose(R2) unison BCNF-decompose(R1)
}
else return R
}
הבנייה של R1,R2 הנ״ל נקראת lossless decomposition step , זה פירוק שמובטח שיהיה פירוק lossless בגלל שהעובדה שאנחנו מעבירים את כל המפתחות רק להקרנה אחת של הטבלה.
נסביר מה שכתוב למעלה, האסטרטגייה שנלך לפיה היא לחפש תלויות פונקציונליות לא טריוויאליות
לאחר מכן נרצה להוסיף לצד ימין כמה שיותר תכונות שנקבעות על ידי
נשים לב שהתכונות למעלה מפורקות ל2 סכמות שעולות עליו על השנייה (זה נעשה באמצעות הprojection) בצד ימין זה כל התכונות שקשורות לFD הלא תקין ובצד השני כל אלה שלא קשורות ל FD שמפרים את התנאים.
ננסה להבין את האלגוריתם עם דוגמת הסרטים ממקודם:
בטבלה הראשונה שמנו לב להפרה
title year-> length genre studioName
במצב הזה, צד ימין כבר מכיל את כל התכונות שנקבעות על ידי title ו year , כלומר לא נצטרך להוסיף אותם וכעת נוכל לפרק את הטבלה כדי לבצע דיקומפוזיציה של Movies1 ל
א) הסכמה {title, year, length, genre, studioName} שמכילה את כל התכונות משתי הצדדים של FD
ב) הסכמה {title, year, starName} שמכילה את כל התכונות מצד שמאל של FD ובנוסף את כל אלה שלא קשורות בכלל.
נסתכל על דוגמה קצת יותר מורכבת
נניח שיש לנו את הסכמה {title, year, studioName, president, presAddr}
עם ה FD הבאות
title year -> studioName
studioName -> president
president -> presAddr
נשים לב ש title,year זה המפתח היחידי בסכמה הזאת. כלומר 2 הFD האחרונים מפרים את BCNF , נתחיל לבצע דיקומפיזציה עם השני
נוסיף לצד ימין את כל התכונות שב closure של studioName ונקבל studioName -> president presAddr
הדיקומפוזיציה מבוססת על FD הזה תיצור לנו את שתי הסכמות הבאות
{title, year, studioName}
{studioName, president, presAddr}
אם כן השלב הבא באלגוריתם הוא לחשב את הבסיס כדי שנוכל לבצע בדיקה נוספת של הפרות
בראשון נקבל שהבסיס הוא title year -> studioName וכמובן ש
president-> presAddr כ FD שמפר את התנאים כ studioName הוא המפתח היחיד.
ולכן סך הכל נקבל שלוש סכמות
{title,year,studioName}
{studioName, president}
{president, presAddr}
באופן כללי נמשיך לבצע דיקומפוזיציה עד שבמקרה הגרוע נגיע לסכמה עם שתי טבלאות כמו במצב הנ״ל.
אלגוריתם 2 - BCNF Decomposition Algorithm
קלט: טבלה
פלט: דיקומפוזיציה של
א) אם
ב) אם יש הפרות , בלי הגבלת הכלליות
ג) הפעל את האלגוריתם לחישוב מספר ה FD החלים על הטבלה המוקרנת
ד) חשב באופן ריקורסיבי את
נשים לב שאחרי ביצוע של פירוק לפי הפרה אחת ההפרה השנייה נעשית ביחס לטבלאות החדשות שנוצרות מהפירוק! אחרת, נעבוד כפול
Decomposition: The Good, Bad, and Ugly
ראינו שלפני ביצוע דיקומפוזיציה סכמה יכולה להכיל חריגות. לאחר הדיקומפוזיציה התוצאות כבר לא יכילו חריגות. זה ה ״טוב״ אבל לכל דבר טוב יש גם חסרונות.
בחלק הזה נרצה לשקול 3 תכונות ייחודיות שנרצה שיהיה לדיקומפוזיציה:
- אלימינצייה של חריגות
- האם נוכל להשיג את כל המידע שהיה לי לפני הדיקומפוזיצייה ?
- האם נוכל להבטיח שבנייה מחדש של הטבלה המקורית על ידי איחוד טבלאות המפורקות תיתן תוצאה שתספק את התלויות הפונקציונליות המקוריות?
מסתבר אם כן, ש BCNF נותן לנו את 1 ו 2 אבל לא בטוח את 3. בהמשך נראה דדרך אחרת שנותנת את 1 ו 2 אבל לא את 3. למעשה, אין דרך להשיג את כל השלושה ביחד.
Recovering Information from a Decomposition
נשאל שאלה שכבר שאלנו בסיכום זה, למה הלכנו כל כך רחוק עם האלגוריתם אם אנחנו יודעים שתמיד סכמה של שתי תכונות תקיים את הBCNF ?
התשובה לכך היא שהמידע שבפירוק, גם אם הtuples שלהם היה איזשהו הקרנה של מופע של הטבלה, עדיין עלול שלא לאפשר לנו לאחד את הפירוק ולקבל את המופע בחזרה. אם אכן נקבל את הטבלה בחזרה אז אנחנו יכולים להגיד שהדיקומפוזיצייה היא loseless .
נשים לב שאם נבצע פירוק לפי האלגוריתם של פירוק BCNF אנחנו נוכל תמיד לקבל את הטבלה המקורית באמצעות natural join בניגוד למצבים של פירוקים אחרים שלא כך המצב.
לדוגמה עבור הסכמה
| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 4 | 2 | 5 |
כלומר ניתן לראות שאין תלות פונקציונלית מ B לערך אחר.
כעת אם נפרק
| A | B |
|---|---|
| 1 | 2 |
| 4 | 2 |
ובאותו אופן
| B | C |
|---|---|
| 2 | 3 |
| 2 | 5 |
אם נבנה באמצעות
| A | B | C |
|---|---|---|
| 1 | 2 | 3 |
| 1 | 2 | 5 |
| 4 | 2 | 3 |
| 4 | 2 | 5 |
וקיבלנו ערכים מיותרים שלא היו בטבלה המקורית.
Dependency Preservation
אם כן היכולת של האלגוריתם של BCNF לפרק את הטבלה באופן שהוא loseless אינה מובנת מאליו אך כמו שאמרנו זה בא במחיר שאנחנו משלמים על כך שלא תמיד נקבל את אותן תלויות פונקציונליות שהיו לנו בטבלה המקורית.
למשל, עבור הטבלה
| Film | Actor | Character |
|---|---|---|
עם התלויות
| Film | Character |
|---|---|
| Actor | Character |
|---|---|
כעת אם נאכלס את שתי הטבלאות בערכים הבאים
| Film | Character |
|---|---|
| Austin Powers | Austin Powers |
| Austin Powers | Doctor Evil |
| Actor | Character |
|---|---|
| Myke miers | Austin Powers |
| Myke miers | Doctor Evil |
באיחוד הטבלאות נקבל
| Film | Actor | Character |
|---|---|---|
| Austin Powers | Myke miers | Austin Powers |
| Austin Powers | Myke miers | Doctor evil |
וזה הפרה של התלות
שמירה של תלויות פונקציונליות לאחר דיקומפוזיציה ואיחוד נקראת Dependency Preservation.
The Chase Test for Lossless Join
נרצה דרך לבדוק האם בהנתן רלצייה
יש כמה דברים שחשוב לזכור לפני שנדבר על המבחן עצמו
א) הפעולה natural join היא אסוציטיבית וקומוטטיבית כלומר אין חשיבות לסדר שמאחדים את הפירוקים, נגיע בסוף לאותה תוצאה.
ב) כל tuple נסמנו
ג) השיוויון הנ״ל מתקיים אמ״מ כל tuple ב איחוד יהיה גם ב
המבחן לבדיקת loseless היא דרך מסודרת לבדוק האם
אם
כלומר אם עבור איבר כללי ב
אם כן נבנה את מבחן הchase באמצעות דוגמה:
נניח שיש לנו
כעת נרצה לבנות משהו שנקרא tableau לדיקומפוזיצייה שזאת מעין טבלת אמת שתעזור לנו לקבוע האם תנאי מתקיים או לא. במקרה הזה נבנה את טבלת האמת באופן הבא.
א) כל התכונות מכל הפירוקים יהיו עמודות טבלת האמת. כל שורה תייצג ערך דמה בסכמה. כלומר השורה ה
ב) אם בשורה ה
| A | B | C | D |
|---|---|---|---|
| a | b1 | c1 | d |
| a | b2 | c | d2 |
| a3 | b | c | d |
כעת אנחנו רוצים לדעת האם tuple מסויים מהטבלה הזאת יהיה ב
כעת נתחיל לעדכן את הטבלה ביחס לתלויות האלה, למשל שתי השורות הראשונות מסכימות על
| A | B | C | D |
|---|---|---|---|
| a | b1 | c1 | d |
| a | b1 | c | d2 |
| a3 | b | c | d |
כעת בגלל שיש להם את אותו ה
| A | B | C | D |
|---|---|---|---|
| a | b1 | c | d |
| a | b1 | c | d2 |
| a3 | b | c | d |
כעת אנחנו שמים לב שהשורה השלישית והראשונה מסכימים על
Third Normal Form
הפתרון לבעיה שהצגנו למעלה היא לבצע הקלה על הדרישות של BCNF טיפה, זאת על מנת לאפשר לפרק סכמות שאם היינו מפרקים לפי האלגוריתם שלמדנו, לא היו שומרות על התלויות הפונקציונליות שלהן. ההקלה הזאת נקראת ״third normal form".
נרצה להגדיר את ההקלה, להבין איך דיקומפוזיציה לאחר שהגדרנו את ההקלה הזאת על מנת להשיג טבלאות שהם גם lossless וגם dependency preservarion.
הגדרה:
נגיד שטבלה
או ש כל ה
תכונה שהיא חלק ממפתח כלשהי נקראת לרוב prime. נוכל לנסח את תנאי ה 3NF כך ״לכל FD לא טריווילי, או שצד שמאל הוא סופר מפתח, או שצד ימין מכיל תכונות prime בלבד״.
זה בעצם מבצע מאפשר FD כמו זה שהפר את הדוגמה הנ״ל .
אם כן אנחנו יודעים להגיד שהפירוק של 3NF בוודאות אמור להיות loseless וגם לשמור על תלות פונקציונלית
צורות נורמליות אחרות
השאלה המיידית המתבקשת היא, אם יש ״צורה נורמלית שלישית״ האם קיימות 2 אחרות?
אז כן קיימות אבל כמעט ולא משתמשים בהם.
1NF
זה מודל טריוויאלי בשרתים קטנים. המודל מבקש שהמידע יהיה שטוח ככל האפשר כלומר, כל טבלה מייצגת סוג יחיד של מידע וכל עמודה בטבלה צריכה להכיל מידע אטומי בלבד והמידע הזה לא אמור לחזור על עצמו בשום צורה בטבלה.
למשל סכמה של שרת שמקיים את זה
CREATE TABLE Students (
student_id INT PRIMARY KEY,
first_name VARCHAR(255),
last_name VARCHAR(255),
gender CHAR(1),
date_of_birth DATE,
enrollment_date DATE
);
CREATE TABLE Courses (
course_id INT PRIMARY KEY,
course_name VARCHAR(255),
course_description TEXT
);
CREATE TABLE Enrollments (
enrollment_id INT PRIMARY KEY,
student_id INT,
course_id INT,
enrollment_date DATE,
FOREIGN KEY (student_id) REFERENCES Students(student_id),
FOREIGN KEY (course_id) REFERENCES Courses(course_id)
);
ניתן לראות ששמירה על מודל שהוא שטוח נעשת כאן על ידי טבלאות מקשרות שזאת טכניקה מוכרת ב SQL ליצירת חיבוריות בין שתי סכמות.
2NF היא מקרה מפחות מגביל של 3NF ויש גם 4NF שלא אתמקד בסיכום זה.
The Synthesis Algorithm for 3NF Schemas
נשים לב שתמיד אפשר להשתמש בפירוק loseless כמו BCNF ולקבל פירוק 3NF אבל כאן נדבר על פירוק שנותן לנו יותר מזה
נרצה לפרק סכמה של
א) כל הטבלאות המפורקות מקבלות 3NF
ב) הדיקומפוזיציה היא lossless
ג) הדיקומפוזיציה שומרת תלות.
אם כן האלגוריתם יעבוד בצורה הבאה
synthesis algorithm:
קלט:
פלט: דיקומפוזיצייה של
- תמצא בסיס מינימלי ל
נסמנו . - לכל תלות
ב השתמש ב XA כסכמה של אחת הטבלאות בדיקומפוזיציה - אם אף אחת מהסכמות XA שיצרנו בשלב הקודם היא סופר מפתח עבור
, הוסף טבלה נוספת שהסכמה שלה היא מפתח עבור .
יש לוודא שכל טבלה בפירוק איננה מכילה משתנים שתלויים באופן טרנזיטיבי אחד בשני, אחרת זה לא יעבוד. במידה ונתקלנו במצב כזה יש לפצל את הטבלה הזאת כך שהגורם המקשר טרנזיטיבית נמצא בשתי הטבלאות.
למשל: עבור
נסתכל על דוגמה נוספת,
עבור
בהתחלה נשים לב שהקבוצה הנ״ל היא כבר בסיס מינימלי. הבדיקה של זה דורשת קצת עבודה אך לא אפרט אותה כאן.
כעת ניקח כל אחד מה FD כסכמה של טבלה נקבל
נשים לב ש
כעת צריך לבדוק הם המפתחות והאם צריך להוסיף סכמה שהיא מפתח
ל
כיוון שאף אחד מהם מוקרן מהסכמות שהבאנו נצטרך להוסיף אחד מהם ולכן נוסיף
לא אפרט עד הסוף את נכונות האלגוריתם, אלא רק אגיד שהוא שומר על תלות כי כל FD בבסיס המינימלי מכיל את כל התכונות באופן כזה או אחר תחת דיקומפוזיצייה מסויימת, כלומר ניתן לבדוק אותן בטבלה מפורקת כלשהי.
יחסים בין Normal Forms
אומנם לא דיברנו על 4NF אבל אסכם זאת באיור הבא
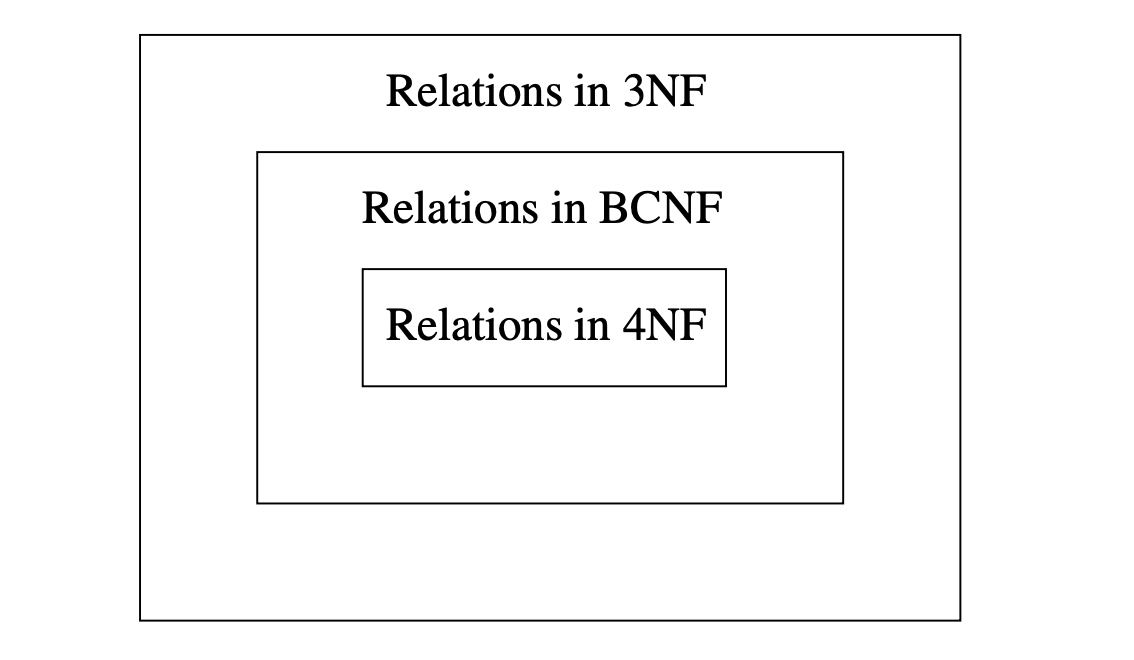
כלומר אם relation מסויים הוא בצורת BCNF אז הוא בפרט בצורה 3NF. זה גם משתמע מכך ש3NF הוא מעין הקלה של BCNF, כלומר אנחנו מקלים בבדיקה שלנו להפרות.