עצים כלליים ובינארים
דיברנו על מבני הנתונים הליניארית - יש להם יתרונות רבים, עם זאת , הבעיה הכי גדולה שלהם היא שתמיד נצטרך לבחור בין היכולת לחפש ביעילות, לבין היכולת לגשת למידע ולעדכן מידע במהירות. ברוב המקרים תהיה התנגשות בין השניים. המגבלה הזאת שלכל record יש רק איבר אחד הבא אחריו יכולה להיות יתרון ומגבלה גדולה. בשביל זה עצים נכנסים לתמונה והם יאפשרו לנו להגיד מבני נתונים שלא מגבילים אותנו מהבחינה הזו.
הגדרה : עץ במונחים של מבנה נתונים (בתורת הגרפים יכול להיות מוגדר אחרת) הוא אוסף של אלמנטים הנקראים
- יש אלמנט הנקרא
- כל מי שאינו ה
בעץ יכול להיות ה בתת עץ משלו או חלק מתת עץ אחר. במילים אחרות אם ניקח תת קבוצה של הקבוצה שלנו בלי ה ואפשר גם בלי אלמנטים נוספים, נקבל עץ .
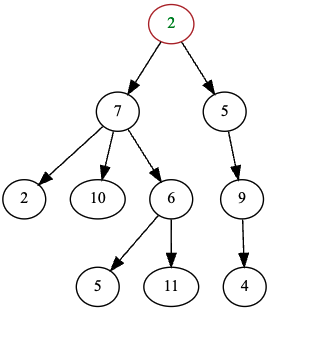
לדוגמא, 2 במקרה זה הוא שורש העץ אבל אם ניקח את הקבוצה ת 7,10,11,6 נקבל עץ גם כן. אחת הדוגמאות מוכרות של עצים היא ה DOM שזה אובייקט שמתאר את תגיות ה
למעשה כמעט כל מבנה נתונים ליניארי יכול להחשב כעץ שלכל עץ יש ילד אחד.
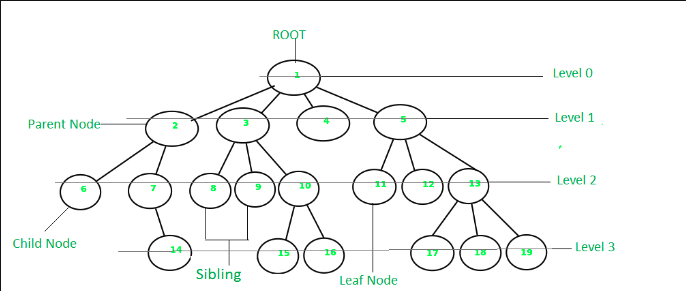
טרמינולוגיה חשובה בעצים
- השורש - ה node העליון ביותר (ללא אבא)
- node/צומת - קודקוד בעץ - יכול להכיל data כלשהו ובנוסף מחזיק בתוכו מצביע לילדים שלו (לפי סוג העץ נקבע כמה ילדים יש לו אבל בעץ כללי אין מגבלה).
- ילד- קודקוד שיש לו אבא
- קשת- חיבור בין בני קודקודים
- עלה- קודקוד שאין לו ילדים
- גובה- המרחק הארוך ביותר בין שורש לעלה
- עומק / רמה - המרחק בין קודקוד כלשהו לשורש העץ. (נשים לב שעומק תלוי ב node שבוא אני נמצא)
- שכנים/קרובים - כל הקודקודים שיש להם אבא משותף.
הגדרות בסיס
- לעץ כללי יש לפחות קודקוד אחד
- עץ עם קודקוד יחיד (שורש בלי ילדים) , גובהו
.
בעצים שיטת הסריקה המומלצת ביותר היא על ידי ריקורסיה כמו כן , עץ הוא מבנה נתונים מופשט וניתן לממשו בשיטות רבות ומגוונות (אולי כאלו שגם לא דורשים סריקה ריקורסיבית). השיטה הקלאסית למימוש עץ היא על ידי אובייקט
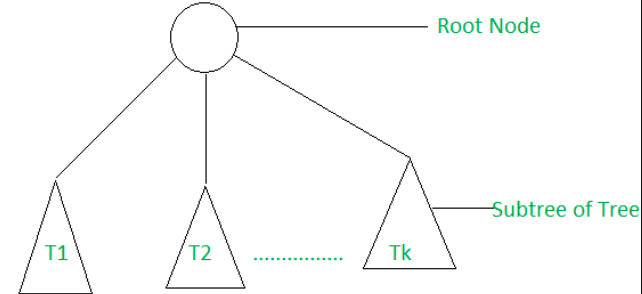
באופו כללי ניתן להסתכל על עץ באופן הריקורסיבי הבא :
עץ בינארי
הגדרה: עץ בינארי הוא אוסף המקיים את התכונות הבאות
- או שהוא ריק
- אם לא ריק , השורש מכיל שני תתי עצים שהם בעצמם עצים בינאריים .
במילים אחרון לכל אב יש שני בנים לכל היותר.
נשים לב שעץ בינארי הוא לא מקרה פרטי של עץ כיוון שהקבוצה הריקה היא יכולה להיות העץ הבינארי הריק בעוד שבעץ כללי חייב שיהיה לפחות שורש.
העץ הריק הוא עץ ללא שורש וללא קודקודים וגובהו מסומן כ
מעצים כלליים לעצים בינאריים
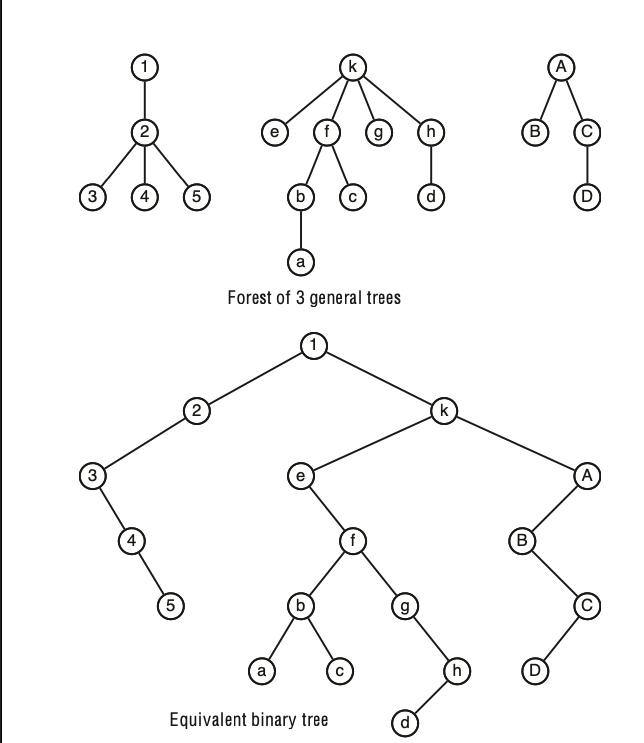
ניקח ״יער״ מסודר שזה בעצם אוסף של עצים כלליים.. ניתן להמיר יער סדור (אוסף של עצים כללים שמוגדר עליהם יחס סדר כלשהו) לעץ בינארי על ידי פונקצייה חח״ע כלומר שלכל עץ יער יש עץ בינארי שקול .
הפונקצייה תעבוד באופן הבא : יהי
- השורש של
יהיה השורש של העץ השמאלי ביותר ביער . - הילד שמאלי של קודקוד
ב יהיה הילד השמאלי (אם יש ילד אחד אז הוא אוטומטי שמאלי, כי אין פה יחס סדר עדיין על האיברים בעץ) של אותו הקודקוד ביער. הילד הימני יהיה השכן המיידי מצד ימין של ב אם יש כזה (אם אין אז אין ילד ימני). השורשים של היער הם מקרה מיוחד והם נחשבים שכנים אחד של השני.
בצורה ויזואלית -
אנקדוטה דיברנו על כך ניתן לייצג יער כעץ בינארי עם שימוש בפונקצייה הפיכה, נוכל לקבוע משהו יותר חזק מזה, בהינתן
זאת הגדרה ריקורסיבית ולכן נפתח סוגריים על כל תת עץ של תת עץ וכן הלאה... למשל עבור העץ הבא
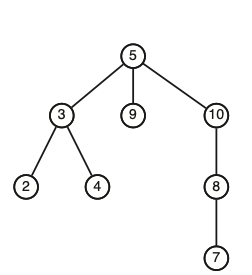
הסידור יהיה
למעשה נוכל להגדיר את זה גם בלי ערכים כלל , אם מעוניינים רק במבנה העץ.
לא נפרט את ההוכחה המלאה אבל ראינו משהו דומה , [מספר קטלן](https://he.wikipedia.org/wiki/%D7%9E%D7%A1%D7%A4%D7%A8_%D7%A7%D7%98%D7%9C%D7%9F) יכולים להגדיר לנו בידיוק כמה סוגריים כאלה ניתן לשים על $n$ ערכים שונים. לכן יש סך הכל :
$$\frac{1}{n+1}\binom{2n}{n}$$
אפשרויות ליצור יערות מ $n$ קודקודים שונים.
תכונות העצים הבינאריים
נדבר על שיטות הסריקה של עץ בינארי. מטרת הסריקה יכולה להיות שונה ולכן בחירת שיטת הסריקה תהיה קשורה למטרה שלשמה רוצים לסרוק :
סריקות DFS (חיפוש עומק)
pre-order - עבור כל צומת נדפיס את ערכו , לאחר מכן נעבור לבנו השמאלי של העץ, לבסוף נלך לבנו הימני.
in-order - עבור כל צומת יש להדפיס תחילה את הבן השמאלי, לאחר מכן לעבור לערכו שלו ולבסוף לבן הימני.
post-order - עבור כל צומת יש להדפיס את הבן השמאלי, לאחר מכן את הבן הימני ולבסוף את ערך הצומת עצמו.
נשים לב שזאת סריקה ריקורסיבית לכן, למשל, בסריקת in-order אנחנו נמשיך לרדת בצמתים כל עוד יש בן שמאלי ורק אז נעלה למעלה .
struct Node{
int data;
Node *left, *right;
};
void preOrderPrint(Node *root)
{
print(root->name); //record root
if (root->left != NULL) preOrderPrint(root->left); //traverse left if exists
if (root->right != NULL) preOrderPrint(root->right);//traverse right if exists
}
void inOrderPrint(Node *root)
{
if (root.left != NULL) inOrderPrint(root->left); //traverse left if exists
print(root->name); //record root
if (root.right != NULL) inOrderPrint(root->right); //traverse right if exists
}
void postOrderPrint(Node *root)
{
if (root->left != NULL) postOrderPrint(root->left); //traverse left if exists
if (root->right != NULL) postOrderPrint(root->right);//traverse right if exists
print(root->name); //record root
}
חשוב מאוד סריקת
סריקות BFS (חיפוש רוחב)
נשתמש בתור כדי לסרוק את האיברים בעץ , קומה קומה
כל קומה נכניס איברים לתור ונדפיס אותם , מיד לאחר הדפסה נוציא אותם מהתור ונכניס את האיברים הבאים בקומה... נמשיך ככה עד שנגיע לעלים .
void printLevelOrder(Node* root)
{
if (root == NULL)
return;
queue<Node*> q;
q.push(root);
while (q.empty() == false) {
// Print front of queue and remove it from queue
Node* node = q.front();
cout << node->data << " ";
q.pop();
if (node->left != NULL)
q.push(node->left);
if (node->right != NULL)
q.push(node->right);
}
}
עץ בינרי שלם complete binary tree
עץ המכיל איבר יחיד או מכיל שורש ושתי תתי עצים שהם בעצמם עץ בינארי שלם. במילים אחרות, זה עץ שלכל קודקוד יש או 0 בנים, או 2 בנים .
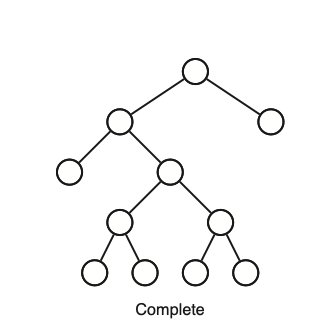
ההגדרה הריקורסיבית הזו מופשטת ומאפשרת לנו ״להפריט״ אותה למבנים אחרים , למשל נוכל להשתמש בה כדי לייצר ביטויים אריתמטיים המכילים אופרטים בינאריים. במבנה של עץ בינארי שלם נוכל להגדיר ביטוי אריתמטי כעץ כזה שלכל קודקוד יכול להיות משתנה (orpand) או אופרטור שלו יש שני ילדים או שני תתי עצים שהם בעצם ביטויים אריתמטיים . ויזואלית:
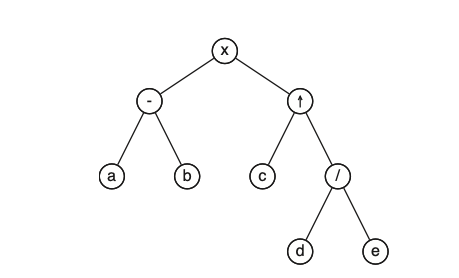
זה בעצם הביטוי
נזכיר ש
יותר מזה צורות הסריקה השונות יביאו לנו את הביטויים האלה בצורת
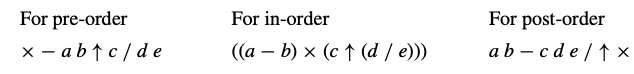
עץ בינארי כמעט מלא / כמעט שלם
הטרמינולוגיה קצת מבלבלת אבל עץ בינארי כמעט שלם (אני מעדיף לקרוא לו כמעט מלא) הוא עץ שלם שכל העלים הם ברמה
אפשר להגדיר את זה גם באופן הבא:
- לכל קודקוד (צומת) ברמה
יש בוודאות שני בנים - ברמה
אם יש קודקוד שיש לנו שני בנים, גם לשכן שלו יש שני בנים. - ברמה
אם יש קודקוד שיש לו בן אחד , אז הוא שמאלי ולכל הקודוקדים משמאלו יש שני בנים.
עץ בינארי מלא full binary tree
זה עץ שבוא לכל הצמתי מלבד העלים יש שני בנים בידיוק והעלים כולם נמצאים באותה רמה. (מקרה פרטי של עץ בינארי שלם).
עץ בינארי מלא מוגדר ריקורסיבית באופן הבא:
כל קודקוד הוא או עלה או קודקוד בעל שני בנים שהם עצים בינאריים מלאים
עץ חיפוש מאוזן
משפחה של עצים תקרא מאוזנת אם לכל עץ במשפחה המכיל
נשים לב ההגדרות המדויקות יכולות להשתנות במקומות מסוימים שבוא אתם צורכים את הידע שלהם , עם זאת התכונות יישארו אותם תכונות.
הוכחות בעצים
בגלל המבנה הריקורסיבי של עץ בינארי , את רוב ההוכחות המתמטיות על עצים נוכל ונרצה להוכיח באינדוקציה, הרבה הוכחות נוכל לעשות באינדוקציה שבסיסה הוא מספר הקודקודים , מספר העלים , העומק וכו... אלטרנטיבה תהיה לבצע אינדוקציה על מבנה העץ עצמו . כלומר על תתי העצים (כפי שהגדרנו עץ בינארי שילדיו הם עצים בינאריים בעצמם). באופן הזה, נוכל בעצם להתחמק מלהראות תכונות מסוימות כל קודקודים, קשתות, וכו.
משפטים
- בעץ בינארי שלם עם
עלים, יש קודקודים פנימיים (קודקוד פנימי זה כל קודקוד שהוא לא עלה כולל השורש).
הוכחה:
הבסיס יהיה פשוט בכל מקרה, אם יש קודקוד אחד הוא שורש ועם 0 קודקודים פנימיים.
נוכל להוכיח באינדוקצייה על מספר העלים ובהנחת האינדוקצייה נתחיל להסתבך, לכן נעשה אינדוקציה על מבנה העץ.
בצעד האינדוקציה , נרצה להניח שהטענה מתקיימת על עצים עם
נסתכל על השורש ונסמן את תתי העצים כ
נסמן את מספר העלים של כל תת עץ כזה כ
מספר הקודקודים הפנימיים בכל תת עץ כזה, לפי הנחת האינדוקצייה יהיה
(ההוספה של האחד היא בגלל שסופרים את השורש של העץ הגדול שלא שייך לתתי העצים בספירה).
- עץ בינארי עם עומקי עלים
( עלים וכל עלה יש עומק שלו , לאו דווקא שונים) יהיה עץ שלם אם ורק אם מתקיים . (אם זה קטן מאחד נקבל עץ לא שלם, אם זה גדול מ1 נקבל שאנחנו לא עובדים עם עץ).
נוכיח באינדוקצייה על מבנה העץ :
בבסיס אם
בצעד נסתכל על תתי העצים ונסמן שבתת העץ השמאלי יש
המעבר האחרון נובע כי זה בידיוק הנחת האינדוקצייה, על תתי העצים האלה.
אפשר לנסח את המשפט גם באופן הבא: בעץ בינארי שלם עם
משפטים נוספים (בלי הוכחה)
- בעץ בינארי מלא בכל רמה
יש קודקודים.
וסה״כ בעץ בינארי מלא ישקודקודים (כי עולים עד ואז זה סדרה חשבונית פשוטה). כאשר הגובה זה כאשר k זאת הרמה הנמוכה ביותר בעץ, נזכיר שמתחילים מ 0.
עץ חיפוש בינארי
עד עכשיו דיברנו על עץ בינארי ברמה המופשטת שלו, אבל לא ממש הגדרנו איך אנחנו מסדרים את האיברים בתוך המבנה הזה. בשיטה זו אנחנו מכניסים את ה records לעץ בהתאם לערכיהם ויחס הסדר המוגדר על האיברים. וניתן לזהות את האיבר לפי ערכו.
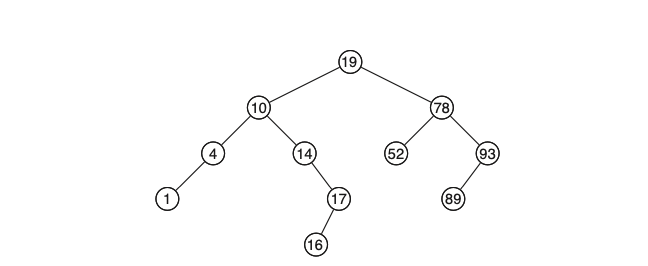
הגדרה : בעץ חיפוש בינארי על כל node עם ערך
חיפוש
החיפוש מתחיל בשורש, אם האלמנט לא נמצא שם נבדוק האם הערך קטן יותר או גדול מהשורש או מהקודקוד עליו אנחנו נמצאים, לאחר מכן באופן ריקורסיבי נרד בתת העץ המתאים עד שנגיע לעלה (הילד הימני והשמאלי של עלה יהיה null ואם נגיע למצב הזה נדע שלא מצאנו את האיבר שאנחנו מחפשים בתת עץ זה). את מתודת החיפוש ניתן לבנות באופן כזה שאנחנו נותנים מצביע לתחילת העץ או תת העץ אותו נרצה לבדוק (לרוב זה יהיה השורש).
בפסודו:

נשים לב שאנחנו מחזירים שלישייה סדורה, שמגידרה האם מצאנו או לא מצאנו את האיבר , מצביע לאותו קודקוד ומיקום בעץ הכולל (האם זה עץ ימני או שמאלי).
קשה לדבר על זמני ריצה בעצי חיפוש בינאריים, זאת כיוון שבהתאם לסוג העץ זמני הריצה משתנים אבל כשאין מגבלות על העץ זה חסום במספר האיברים בעץ במקרה הגרוע.
הכנסה
כדי להכניס ערך מסויים יש לבדוק שהוא לא קיים בעץ קודם, אם לא מצאנו אנחנו נקבל מצביע לעלה בו נצטרך להכניס אותו ובאיזה צד הוא אמור להכנס. זה בידיוק המידע שאנחנו צריכים כדי לבצע הכנסה בזמן קבוע :

במילים מה שקורה בקוד הוא ששאילת החיפוש תחזיר flag אם הערך נמצא או לא, במידה ולא אנחנו אמורים לקבל מצביע לעלה
מחיקה
השאילתה המעניינת היא שאילתת המחיקה , במבני הנתונים הליניאריים היחס בין הכנסה להוצאה היה די סימטרי (גם בקוד לא היה הרבה שוני). המצב שונה בעצי חיפוש בינאריים כיוון שיש מספר מקרים שצריך לקחת בחשבון . נדגים ויזואלית על העץ הזה מהתמונה למעלה:
- השלב הראשון, בדיקה שהאיבר נמצא במידה וכן נבדוק את המקרים הבאים.
- אם הוא עלה, צריך רק לשחרר אותו מהזכרון ולהחליף את ערכו ב null. (למשל נרצה למחוק את 52).
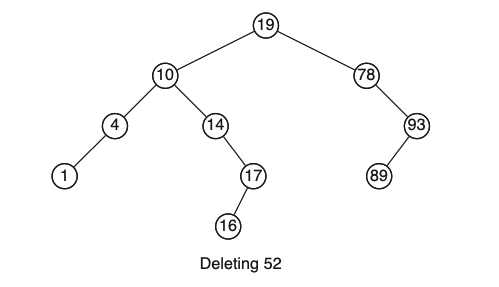
- אם לקודקוד שנרצה למחוק יש ילד אחד, המחיקה תתבצע בדומה לרשימה מקושרת, נקשר בין האבא לילד ונעיף את הקודקוד המחבר מהעץ. למשל נמחק את הקודקודים הפנימיים עם ילד אחד : 4,17
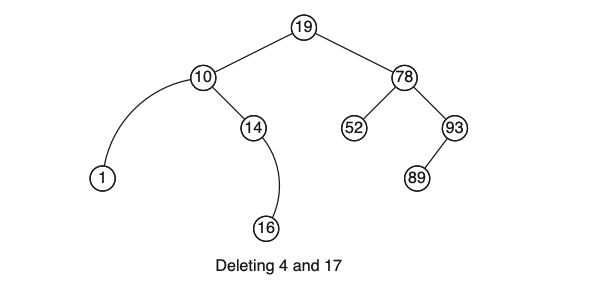
אם לקודקוד שנרצה למחוק יש שני ילדים , זה המקרה המסובך יותר כיוון שלאותו קודקוד יש מצביע אחד לאבא ושני מצביעים מתחתיו , קישור שלהם ישירות לאבא יכול לשבש את העץ. הפתרון הוא פשוט , לא נמחק את הקודקוד עצמו אלא נחליף את ערכו בערך של האיבר השמאלי ביותר (הקטן ביותר) של תת העץ הימני של אותו קודקוד (כלומר, לצאת ימינה לתת העץ הימני , ומייד לאחר מכן ללכת הכי שמאלה שאפשר, אם אי אפשר פשוט לוקחים את השורש של תת העץ הימני) . אם זה נשמע מוכר לכם, אז זה בידיוק ההדפסה של inorder שדיברנו עליה מקודם כלומר פשוט לקחת את האיבר הבא בהדפסת inorder ולשים את ערכו במקום האיבר שלנו. לבסוף מוחקים את הקודקוד שמייצג את האיבר הזה שהוא בוודאות שייך למקרה שיש לו ילד אחד או שהוא עלה (אחרת הוא לא היה השמאלי ביותר).

בדומה לרשימות מקושרות נוכל לטפל במקרה קצה שבוא מוחקים את השורש על ידי החזקת מצביע ללא ערך לשורש
אנדקודטה שחזור עצים בינאריים על ידי
דיברנו על זה שבעצי חיפוש ההדפסות הללו יכולות לעזור לנו לשחזר את העץ במדויק במיפוי של 1:1 (כלומר יש רק עץ אחד בהינתן הצורות האלה שיקיים את זה), נראה איך :
post and in :
בהינתן שתי התצוגות האלה נוכל לשחזר את העץ באופן הבא:
- האיבר האחרון ב
יהיה השורש - נמצא את השורש ב
וכעת אנחנו יודעים שכל האיברים ב מימין ל שורש הזה הם תת העץ הימני וכל מי שמשמאל יהיו האיברים בתת העץ השמאלי. - ״משמיטים״ את האיבר שמצאנו משני ההדפסות, כעת מבצעים את אותו תהליך באופן ריקורסיבי על
ו של תתי העצים.
דוגמה
עבור ההדפסות
in[] = {4, 8, 2, 5, 1, 6, 3, 7}
post[] = {8, 4, 5, 2, 6, 7, 3, 1}
תת העץ השמאלי יהיה
[5, 2, 8, 4]
ותת העץ הימני יהיה
[6,3,7]
וההדפסות שלהם ב
אני לא אדגים זאת בקוד אבל נוכל לאתר בקלות את ההדפסות post על ידי שימור באיבר הבא אחרי השורש ב. inorder. בדוגמה שלנו, ניקח את 6, נמצא אותו בpost וכל מי שמשמאלו חייב להיות בתת העץ השמאלי בצורת post. (הסברתי את זה כי אומנם ויזואלית קל לראות את זה אבל מבחינת קוד זה דורש קצת עבודה להפעיל את הקריאה הריקורסיבית על שתי ההדפסות האלו).
חשוב לציין שאם מבקשים מאיתנו להמיר לעץ בינארי שלם על בסיס inorder
בלבד, הדבר אפשרי, הפתרון יהיה למטה בתרגילים.
pre :
בהדפסת
- האיבר הראשון הוא תמיד השורש
- כעת נמצא את האיבר הראשון בהדפסה שהוא יותר גדול מהשורש.
- כל האיברים מימינו כולל אותו הם תת העץ הימני, כל האיברים משמאלו הם תת העץ השמאלי.
- מפעילים את הפעולה באופו ריקורסיבי על שני תתי העצים
על post זה יהיה הפוך
node* constructTreeUtil(int pre[], int* preIndex, int low,int high, int size) {
if (*preIndex >= size || low > high)
return NULL;
node* root = newNode(pre[*preIndex]);
*preIndex = *preIndex + 1;
if (low == high)
return root;
int i;
for (i = low; i <= high; ++i)
if (pre[i] > root->data)
break;
root->left = constructTreeUtil
(pre, preIndex, *preIndex,i - 1, size);
root->right
= constructTreeUtil(pre, preIndex, i, high, size);
return root;
}