עצי B
עצי חיפוש מסדר גבוה
אם נרצה, נוכל להכליל את כל המונחים שדיברנו עליהם עד עכשיו בהקשר של עצי חיפוש בינאריים, נוכל להגדיר עץ חיפוש מדרגה
עצי חיפוש בינאריים הם מקרה פרטי של ההגדרה הזאת שכן
הגדרה סדר= דרגת קודקוד= מספר הבנים שיש לאותו קודקוד.
- אם דרגת הקודקוד היא
אז לקודקוד יהיו ערכים פנימיים ו מצביעים.
הגדרת ההכנסה לעץ כזה תהיה הכללה להכנסה לעץ בינארי :
יהי שורש
- תת העץ השמאלי יכיל את הערכים שקטנים מ
- תת העץ ה
יכיל רק אלמנטים שגדולים מ - תת העץ הימני ביותר (ה
-י) יכיל רק את האיברים שגדולים מ
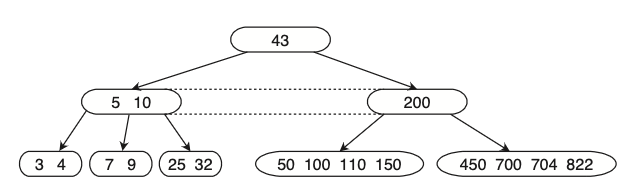
למשל עץ חיפוש מסדר 4:
שימו לב שמותר להצביע לילד שהוא null בעץ חיפוש מסדר m כללי
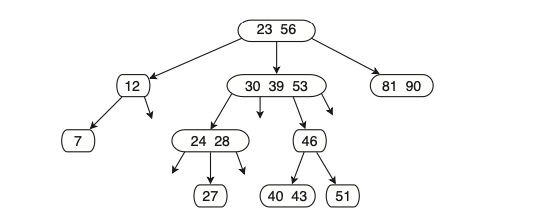
שיטת החיפוש זהה לגמרי למה שאנחנו מכירים מהמקרה הפרטי של עץ חיפוש בינארי, עבור ערך
לא נתעמק ממש על הכנסה ומחיקה בעצי חיפוש מסדר גבוה כי כמו עצי חיפוש בינאריים הם חסומים ב
אבל!! ראינו עצי AVL ואיך הם עוזרים לנו להקטין את החסם על הפעולות על ידי הקטנת גובה העץ. וכעת, נדבר על האלטרנטיבה לעצי חיפוש מסדר גבוה שנותנת לנו בידיוק את הכוח הזה.
הגדרה של עצי B
עץ
- כל קודקוד חוץ מהשורש מכיל לפחות
ערכים . השורש מכיל לפחות ערך אחד. - רק לקודקודים ברמה הנמוכה ביותר יכול להיות ילד ריק.
מתנאי 2 ניתן להסיר שכל העלים בעצי
מהתנאי הראשון ביחד עם ההגדרה של עצי חיפוש מסדר
דוגמה לעץ חיפוש מסדר
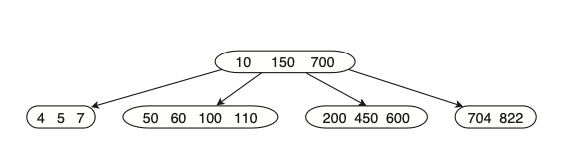
עומק של עץ
באופן כללי יתקיים עבור עץ
כאשר
מכאן אפשר להסיק ש
בשביל להמחיש את היעילות של זה, עבור עץ מדרגה
לפיכך, כדאי שנראה גם איך שומרים על התכונות האלה בהכנסה והוצאה .
הכנסה
השלב הראשון הוא חיפוש , שלב החיפוש זהה לשלב החיפוש בעץ חיפוש מסדר m רגיל.
כעת לשם ההכנסה נחלק למקרים בהינתן שנרצה להכניס את הערך
- הגענו לקודקוד
המקיים וגם הערך יכול להכנס באינדקס , במצב זה נכניס אותו פשוט לרשימה במקום המתאים . - הקודקוד שאליו נרצה להכניס כבר בתפוסה מלאה, הכנסה של הערך
תשבור את התנאים של עצי . (למשל הכנסת 55 לעץ למעלה).
במצב זה, נעשה מספר פעולות:
- נכניס את הערך הרצוי ל קודקוד המתאים תוך כדי התעלמות ממצב ה
שיצרנו.
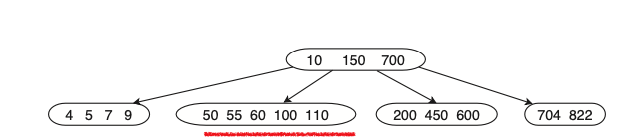
- בשלב השני נצטרך לתקן את החוסר איזון שיצרנו, (בהכרח חוסר איזון יהיה כשבקודקוד יש
ערכים, לא יהיה יותר).
נסמן את האיברים בקודקוד
החדים בינינו ישימו לב ש
כעת נעשה את הדבר הפשוט הבא : נפצל את הקודקוד שהכיל את
שני הקודקודים החדשים יהיו ילדים ישירים של האבא ושכנים אחד של השני(נדבר מה יכול לקרות בהמשך), כמו כן הערך שלא נכנס לרשימה ייכנס באופן ריקורסיבי לאבא שמעליו מהסיבה שכעת הוספנו עוד ילד לאבא ולכן מהגדרת העץ צריך להוסיף עוד ערך (יש הפרש של 1 בין השניים) (אם גם באבא יש
התוצאה על העץ הנ״ל תהיה :

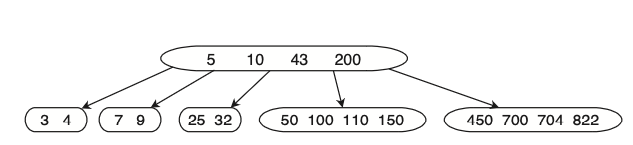
בוא נראה מה קורה אם נכניס עכשיו את הערך 3 לפי השלבים הנ״ל :
שלב ראשון :

והשלב השני:

אופס! קיבלנו
מה שיקרה בדוגמה שלנו בשלב הזה היא שנמשיך כרגיל אבל הפעם בגלל שהגענו ל
במקרה הגרוע אנחנו נבצע פיצולים כאלה כגובה העץ, המקרה הזה יהיה די נדיר ולכן המבנה הזה כל כך טוב .
מבחינת יעילות, כמו חיפוש הפעולה חסומה באופן הדוק בגובה העץ
נשים לב לנקודה נוספת, מבחינת הבנייה של המבנה עבור
מפתה להגיד שפשוט מבצעים את פעולה ההכנסה
מחיקה
כמו בעצי חיפוש בינאריים הכי קל לנו יהיה למחוק ערכים מעלים, ואם נרצה למחוק מערכים שאינם כאלה נמצא לו יורש בתוך העץ שיחליף אותו (ב
ה״יורש״ להחלפה במקרה של מחיקת קודקוד שאינו עלה יימצא באופן הבא
- מציאת הקודקוד
שבוא נמצא ערך המחיקה , ברגע שמצאנו יציאה מיידית לפוינטר הימני - אם הקודקוד אינו עלה, יש לצאת מיד לפוינטר השמאלי ביותר ולהמשיך ככה עד להגעה לעלה
- הערך השמאלי ביותר בעלה שנגיע אליו הוא היורש.
(מאוד דומה למציאת הערך הבא בהדפסת inorder של עץ בינארי).
הבעיה עם מחיקה זה שיכול להיות מצב של
כעת, נניח שנרצה למחוק את הערך
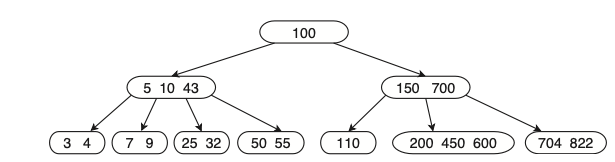
על פניו נשמע מצויין , עם זאת , ניתן לראות שעלול להווצר מצב שבו בעלה יש מספר מועט מדי של ערכים, מה שלא מתאים להגדרה של עצי
נשמע כאילו הפתרון יהיה למזג? כמו שעשינו פיצול בהכנסה, עם זאת זה לא המצב, כי בעוד שפיצול קודקוד זה אך ורק לפי ערכי הקודקוד , מיזוג לא בהכרח יהיה אפשרי בגלל שיש תלוי בערכי האבא. למשל אם נמזג את 110 עם הקודקוד מימינו , לא רק שנצטרך להוריד ערך אחד מהאבא אלא גם שהמצביעים לא יתאימו לערכים כלומר המצביע השמאלי לקודקוד (150,700) יכיל ערכים שקטנים וגדולים מ 150 וזה לא טוב.
בכל מקרה , נקטין את מספר הילדים ולכן קודקוד אב יצטרך להוריד ערך אחד. אבל נעשה את זה במהלך שנקרא
המהלך הזה יתבצע בצורה הבאה :
- אם השכן המידי של קודקוד
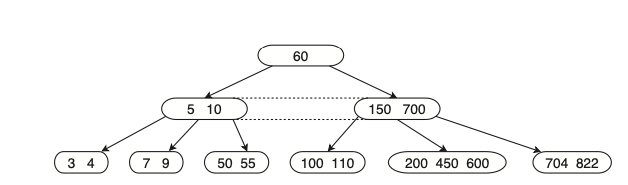
שהוא במצב מכיל מספר שיותר גבוה ממספר המינימום המותר של ערכים (כלומר שהסרת ערך אחד לא תפגע) . ניקח את הערך שהכי קרוב לקודקוד שממנו מוחקים בשכן המיידי (נסמן ) , ואת הערך שמפריד בין שני הילדים באבא נסמן . נשים את בקודקוד שמצב במקום המתאים, ואת נשים במיקום של למשל עבור העץ הנ״ל ניקח את 150 , נשים אותו בקודקוד 110 מצד ימין, ואת 200 נשים במקום 150, באופן הבא :
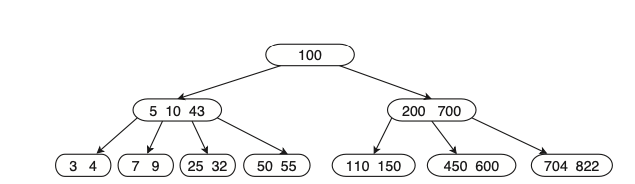
נשים לב, שכן מידי = שכן ימני אם קיים ואם לא אז שכן שמאלי
- המצב השני יתרחש כאשר הורדת ערך מהשכן המידי לא מתאפשרת בגלל שגם לו יהיה
, (למשל אם נרצה למחוק את 600) לא נוכל להשאיל את 704 . במצב זה נצטרך להשלים את הערך המתאים מהאבא ואם יש יותר מדי ילדים לאבא, יתקיים מיזוג של הקודקוד עם שכנו הימני. בגלל המצב של underflow אנחנו יודעים שניתן לעשות מיזוג כזה אחרי שהוספנו ערך מהאבא .
המיזוג ייראה כך (על מחיקת הערך 600)
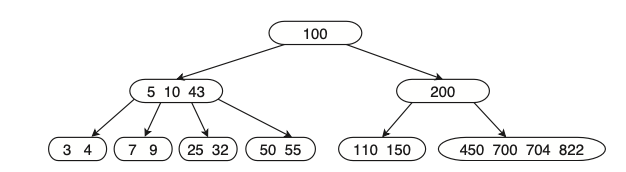
גם כאן יש בעיה מחיקת הערך 700 מהאבא יצרה
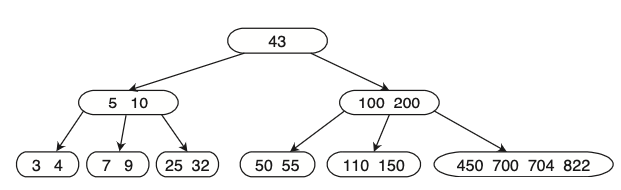
המקרה השני , הוא מצב לא גם באבא לא ניתן לאזן מהשכן המיידי ולכן נמזג ונשלים מהאבא שמעליו (ופה נכנסת הריקורסיה המדוברת) למשל, אם נמחק את 55 זה ייראה כך :
וככה נמשיך באופן ריקורסיבי עד הגעה לשורש.
גם פעולת המחיקה חסומה בגובה העץ כמו פעולה ההכנסה.
וריאנטים לעצי
ישנם וריאנטים מכל מיני סוגים שמיועדים לייעל טיפה את המימוש הנ״ל או לתאר מקרים ספציפיים למשל עצי
עץ 2-3
זה עץ
הסיבה שאני מדבר עליו היא שאני רוצה להדגים באופן ספציפי (אך ניתן לממש את זה באופן כללי) אלגוריתם בנייה של עץ כזה ממערך ממויין בזמן ליניארי.
האלגוריתם יעבוד בצורה הבאה:
- אם המערך מכיל 2-3 ערכים , סיימנו , נקבל שורש יחיד
- אחרת נחלק את המערך לשלישיות, כל שלישייה תהיה עלה בעץ , ואת הערך הגדול מבין השלושה נפעפע למעלה ונבנה קודקוד אבא לכולם, אם הוא מכיל 2-3 ילדים, סיימנו, אחרת נבצע את אותו התהליך ריקורסיבי על תת המערך שהוא הערכים בקודקוד האב (בעצם זה הפרס ומשול קלאסי כשתנאי העצירה הוא הסעיף הראשון של האלגוריתם). חשוב, כשמחלקים ל3 השארית תמיד תהיה איבר אחד או שניים, עלינו לדאוג שהם תמיד יהיו האיברים האחרונים במערך בחלוקה שלנו , באופן זה הם אוטומטית יהיו העלה הכי ימני בעץ.
דוגמה:
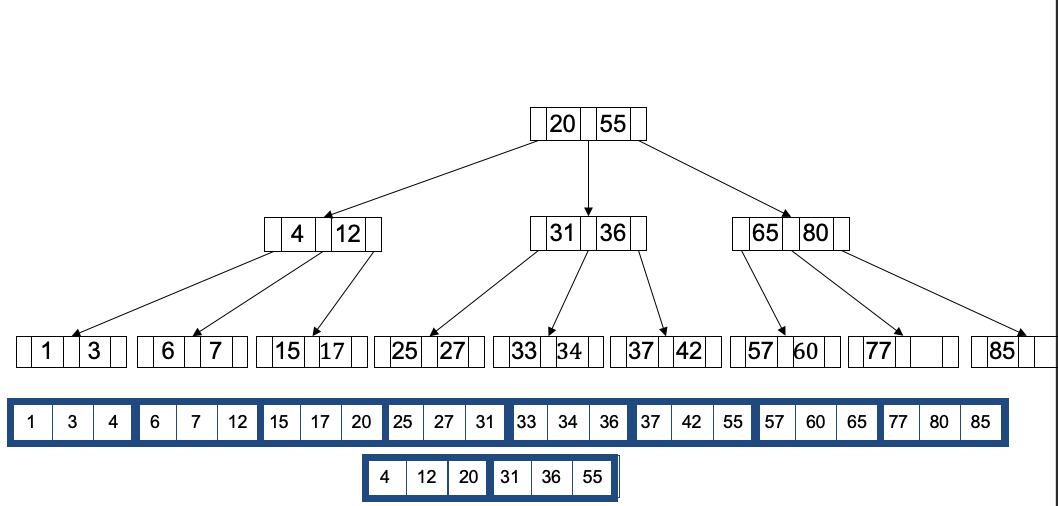
עצי +B
מוריד את כל ערכי העץ לילדים ומחבר מצביע בינהם וככה מקבלים את היכולת לסרוק את כל הערכים בצורה ליניארית במקום לסרוק את העץ בצורה אחרת.
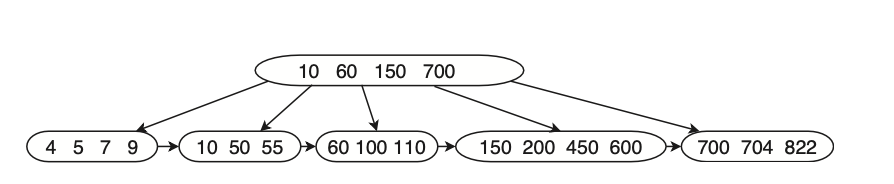
נשים לב שברמות מעל העלים יש עותקים של הערכים המקומיים שנועדו לאפשר חיפוש מהיר יותר
הכנסה -
ההבדל כעת הוא שעל מנת שלא נשבור את הסדר של העלים למטה, נעלה כל פעם עותק של המידע במצב של overflow בהכנסה ופשוט מפצלים את העלים לפי הערך שהעלנו.
מחיקה-
מוצאים את הערך ברמת העלים ומוחקים אותו (בוודאות הוא נמצא כעלה). נשים לב שאין צורך למחוק את העותקים כי הם עדיין משמשים עבורו כ seperators תקינים בין העלים.
חיפוש-
בהתאם למה שאמרנו על מחיקה, יש צורך לחפש עד לרמת העלה על מנת למצוא את הערך. שכן יכול להיות שהשארנו את העותק כ seperator. עבור החיפוש עדיין לוגריתמי בגובה העץ.