UTF-8
UTF-8 is an encoding system for Unicode, which mean it can encode all 1,111,998 supported by it. It can translate any Unicode character to a matching unique binary string, and can also translate the binary string back to a Unicode character. This is the meaning of “UTF”, or “Unicode Transformation Format.”
There are other encoding systems for Unicode besides UTF-8, but UTF-8 is unique because it represents characters in one-byte units. Remember that one byte consists of eight bits, hence the “-8” in its name.
More specifically, UTF-8 converts a code point (which represents a single character in Unicode) into a set of one to four bytes. The first 256 characters in the Unicode library — which include the characters we saw in ASCII — are represented as one byte. Characters that appear later in the Unicode library are encoded as two-byte, three-byte, and eventually four-byte binary units.
for example :
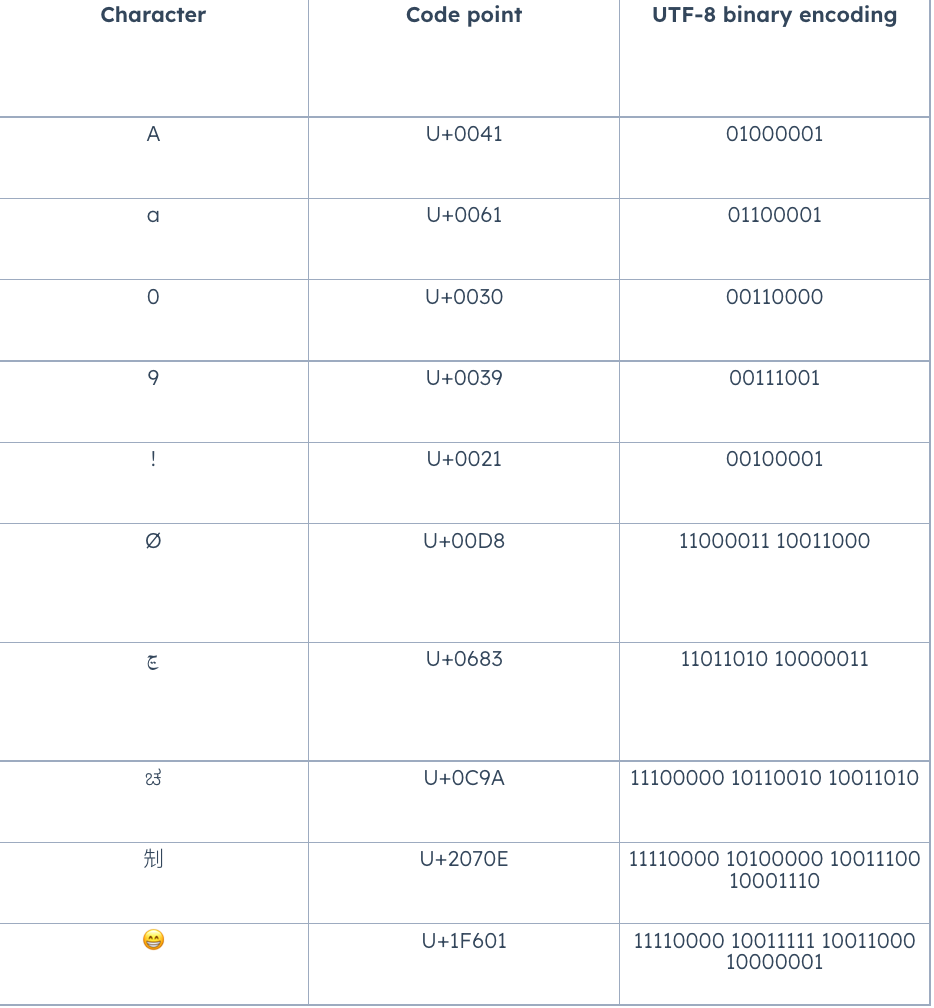
benefits of UTF-8
By using less space to represent more common characters (i.e. ASCII characters), UTF-8 reduces file size while allowing for a much larger number of less-common characters. These less-common characters are encoded into two or more bytes, but this is okay if they’re stored sparingly. Spatial efficiency is a key advantage of UTF-8 encoding. If instead every Unicode character was represented by four bytes, a text file written in English would be four times the size of the same file encoded with UTF-8.
Another benefit of UTF-8 encoding is its backward compatibility with ASCII. The first 128 characters in the Unicode library match those in the ASCII library, and UTF-8 translates these 128 Unicode characters into the same binary strings as ASCII. As a result, UTF-8 can take a text file formatted by ASCII and convert it to human-readable text without issue.
utf 8 and endianness
Since UTF-8 is interpreted as a sequence of bytes, there is no endian problem as there is for encoding forms that use 16-bit or 32-bit code units. Where a BOM is used with UTF-8, it is only used as an encoding signature to distinguish UTF-8 from other encodings — it has nothing to do with byte order.