Computer system basics
מערכת מחשב מכילה חומרה ומערכות תוכנה שיודעות לעבוד ביחד כדי להריץ תוכנות/אפליקציות. אומנם ככל שהזמן רץ מערכות מחשב נהיות מתוחכמות יותר עם מימושים מורכבים יותר אבל הרעיון מאחוריהם זהה. לכל מערכות המחשב יש חומרה דומה ורכיבי תוכנה שמבצעות פעולות דומות.
לשם ההתחלה נסתכל על אחת התוכנות ״הבסיסיות ביותר״ שניתן לכתוב ב hello.c
שנראת ככה:
#include <stdio.h>
int main() {
printf("hello, world\n");
return 0;
}
על פניו תוכנה מאוד פשוטה אבל מערכת המחשב שלנו צריכה לעבוד בסנכרון על מנת להריץ את התוכנית הזאת לסיומה.
ננסה להבין מה המחשב שלנו עושה (באופן די בסיסי) על מנת להביא את התוכנה הפשוטה הזאת לידי אפליקצייה רצה.
(ייצוג אסקי של התוכנית הנ״ל)

מידע זה ביטים + קונטקסט
התוכנית הנ״ל מתחילה כקובץ מקור source file שהמתכנת יוצר עם תוכנת עריכת טקסט האהובה עליו. כשהוא מסיים את עבודתו הוא שומר את התוכנה כקובץ טקסט שנקרא hello.c.
הקובץ לאחר מכן מתורגן לרצף ביטים, שמאורגנים בבלוקים של 8 ביטים שנקראים בייט.
כל בייט מייצג תו כלשהו בתוכנית. הסטדנרט ברוב המחשבים לייצוג טקסט בצורה בינרית הוא ASCII.
לכל בייט יש ערך מספרי שמייצג אותו (ניתן לראות בטבלה למעלה) שמקושר לתו כלשהו שנקרא מהתוכנית.
שימו לב שכל ירידת שורה בקובץ מיוצגת על ידי התו הבלתי נראה /n בהמספר שמייצג אותו הוא
קבצים שמכילים בתוכן באופן אקסלוסיבי תוי אסקי נקראים קבצי טקסט בעוד שכל שאר הקבצים ידועים כקבצים בינאריים binary files .
הרעיון הוא שכל מידע במערכת מחשב: קבצי דיסק, תוכניות בזכרון, user data ומידע שעובר באינטרנט ועוד, כל זה מיוצג על ידי אוסף של ביטים. הדבר היחיד שמשפיע זה הקונסטקס בו אנחנו קוראים את הבייטים האלה.
תוכנות מתורגמות על ידי תוכנות אחרות
כדי להריץ את תוכנת ה hello שכתבנו, נצטרך לקחת אותה בפורמט הקריא שלה ולתרגם אותה לאוסף פקודות ב שפת מכונה. הפקודות האלה נבנות לתוכנה שנקראת executable object program ולאחר מכאן מאוחסנות כ קובץ בינארי. על מערכות מבוססות UNIX התרגום מקובץ מקור לקובץ object נעשה על ידי הקומפיילר (אם להיות מדויק compiler driver)
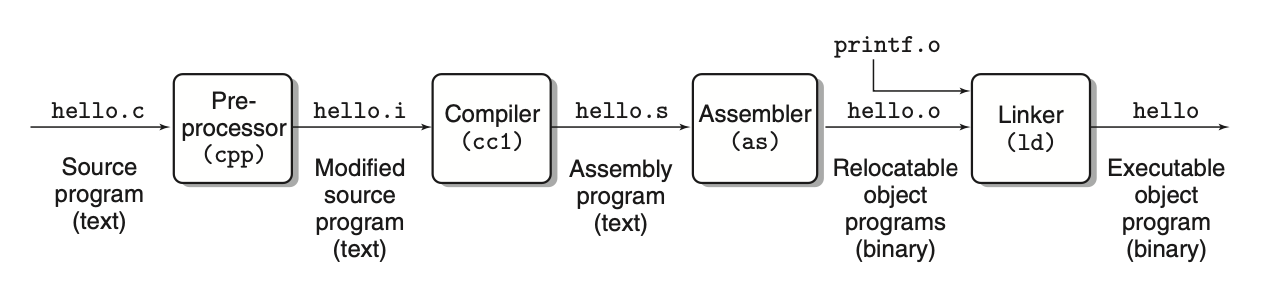
שימוש ב gcc לקריאה של הקובץ שלנו תיראה כך gcc -o hello hello.c. פקודה זאת לוקח את הקובץ hello שכתבנו ומתרגמת אותו של קובץ object שנקרא hello.o גם כן.
לאחר קריאת הפקודה הזאת התוכנה עוברת את ארבעת השלבים המצויינים למעלה וארבעת התהליכים באופן קולקטיבי נקראים מערכת קומפילצייה.
- Preprocessing phase - תפקידו (cpp) להוסיף מידע לקובץ c שלנו בהתאם להנחיות שמתחילות ב # בקובץ. למשל השורה הראשונה ביותר שכתבנו בקובץ
include> stdio.h>#אומרת ל preprocessor לקרוא את התוכן של הקובץstdop.hולשים אותו בקובץ המקור שלנו. התוצר של התהליך הזה הוא קובץשזה גם תוכנת . - Compilation phase - הקומפיילר (cc1) מתרגם מתרגם את הטקסט בקובץ
שנוצר בשלב הקודם לקובץ טקסט שנקרא בשונה מהקבצים הקודמים שהכילו קוד קובץ זה כבר מכיל קוד בשפת assembly. הקובץ הזה ייראה כך
main:
subq $8, %rsp
movl $.LCO, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret
כל שורה בקובץ הזה מתארת פקודה בשפת מכונה. הרעיון בשפת אסמבלי היא שלעיתים היא תראה אותו דבר לשפות וקומפיילרים שונים.
-
Assembly phase האסמבלר
מתרגם את לפקודות בשפת מכונה, אוסף אותם לצורה הידועה בשם relocatable object program ומאחסן את התוצאה בקובץ hello.o שזה קובץ אובייקט שדיברנו עליו. זה קובץ בינארי שמכיל 17 בייטים (bytes) שאותם יש לקודד לפקודות מכונה. בעיניים שלנו המתכנתים זה ייראה גיבריש. -
Linking phase - נשים לב שהקוד שכתבנו מפעיל פונקצייה אחרת של הספרייה הסטנדרטית של שפת C שמסופקת על ידי הקומפיילר. המימוש של פונקצייה זאת נמצא בקובץ אחר שנקרא printf.o שיש צורך לחבר אותו עם הקובץ hello.o שלנו כדי שיהיה אפשר להפעיל את המימוש שלו מהפונקצייה main. הלינקר (ld) מטפל במיזוג המדובר.
מדוע חשוב להבין את תהליך הקומפילצייה
על פניו הראנו עכשיו שהתהליך הזה מנוהל כולו על ידי מערכת הקומפילצייה וניתן לסמוך עליה ״בעיניים עצומות״. למרות זאת, יש מספר סיבות עיקריות למה עלינו להבין איך תהליך הקומפילצייה עובד.
- אופטימיזציות לתוכנית - קומפיילרים מודרנים יודעים לעשות אופטימיזצייה לקוד שלנו וכדאי לנו להכיר ולדעת כיצד הוא עובד כדי שנוכל לקבל החלטות תכנותיות נבונות בקוד שלנו. לפעמים אפילו סדר מסויים בקוד (אפילו לא עניין של יעילות אלא של כתיבה) או שימוש בכלי כזה על פני אחד אחר יכול להועיל רבות ליעילות התוכנית שלנו.
- הבנה של שגיאות linking - השגיאות הקשות ביותר להבנה אלא שגיאות שנעשות בזמן לינקינג בעיקר בזמן בניייה של תוכנית גדולה או פיתוח sdk.
- המנעות מבעיות אבטחה - ישנה חולשה מאוד נפוצה בהרבה מאוד תוכניות שנקראת buffer overflow vulnerabilities. שגיאות כאלה קורות בגלל שמעט מתכנתים מבינים את ההשלכות של תוכן גדול מדי שנקלט בתוכנית שלהם. השלב הראשון כדי ללמוד תוכנה בטוחה הוא קודם כל להבין מהן ההשלכות של האופן שבו מידע מאוחסן במחסנית של התוכנית שלנו.
תפקידו של המעבד בתהליך ההרצה
אחרי שעברנו את ארבעת השלבים למעלה אנחנו מגיעים למצב שיש לנו קובץ exectuable בשם hello שמאוחסן בדיסק. במערכות מבוססות UNIX, נוכל להריץ את התוכנה הזאת אם נרשום את שמה בתוכנה הנקראת shell .
linux> ./hello
hello, world
linux>
ה shell זה command line interpreter שמדפיס למסך ומחכה לפקודת שיירשמו ב command line. לאחר שפקודה נרשמת הוא גם מבצע אותה. אם התוכן שנרשם לא תואם לפקודה ב shell אז הוא מניח שהתוכן הוא תוכנה שיש להריץ אותה. במקרה שלנו הוא מריץ את hello שמבקשת להדפיס למסך את ההודעה hello world.
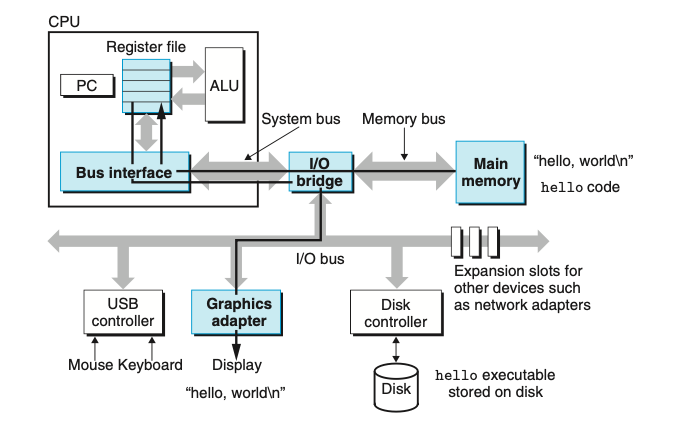
מבנה החומרה במערכת
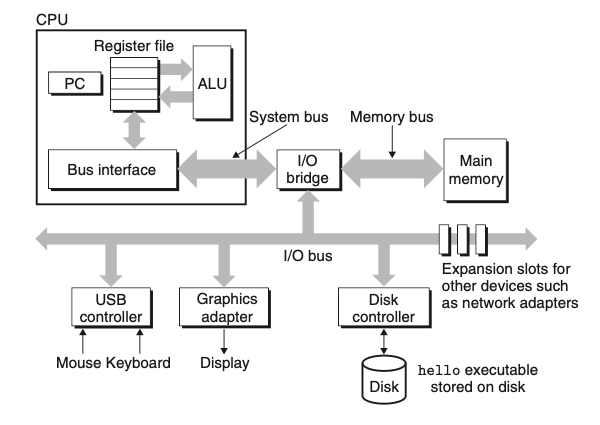
נרצה להבין מה קורה לתוכנה שלנו ברגע שמריצים אותה. בשביל לעשות את זה נרצה להבין את איך החומרה מאורגנת במערכת מחשב סטנדרטית. התמונה למעלה תעזור להבהיר את המצב הזה (התמונה למעלה מבוססת על משפחה של מערכות מבוססות אינטל אבל רוב המערכות בנויות באופן דומה).
buses
אוסף של צינורות חשמל שרצים לכל אורך מערכת החומרה של המחשב והם נקראים buses. תפקידם לשנע בייטים של מידע הלוך ושוב בין רכיבי החומרה. buses מהונדסים כדי לשנע בלוקים בגודל קבוע (fixed size) של בייטים שידועים גם כ words. מספר הבייטים ב word זה פרמטר שמשתנה בין המערכות השונות. רוב המכונות היום הם עם אורך מילה של 4 בייטים (32 bits) או 8 בייטים (64 bit).
I/O
מכשירי IO הם הדרך של המערכת לתקשר עם היוזר או ״העולם החיצוני״ למערכת המחשב. בתמונה ישנן מספר דוגמאות למכשירי IO :
- מקלדת ועכבר לקלט
- מסך לפלט
- disk drive כדי לאחסן מידע תוכניות לטוח רחוק. (ה exe של hello שלנו מאוחסן בדיסק.)
כל מכשיר כזה מחובר ל IO bus באמצעות controller או adapter. קונטרולרים הם בעצם צ׳יפים במכשיר עצמו (בלוח האם) בעוד שאדפטרים אלה כרטיסים שמחובר לslots בלוח האם.
ללא קשר המטרה של שניהם היא העברת מידע בין ה IO BUS ו IO devices .
Main Memory
מכשיר לאחסון זמני שמחזיק את התוכנית והמידע שהתוכנית מייצרת ומשנה בזמן שה #Processor מריץ את התוכנית. פיזית, הזכרון הראשי מכיל אוסף של dynamic random access memory (DRAM) chips. הזכרון מאורגן כמערך ליניארי של בייטים כשלכל אחד יש כתובת ייחודים בהתאם לאינדקס במערך (מתחיל מ 0). באופן כללי הפקודות בשפת מכונה שנמצאות בתוכנית יכולה לכיל מספר מספר בייטים מסויים בתצורת משתנה כאשר גודל המידע הזה משתנה בהתאם למערכת ולטיפוס. למשל במכונה x86-64 שמריצה לינוקס, יתקיים שלטיפוס מסוג short יש צורך ב 2 בייטים, int ו float מצריכים 4 בייטים ו long , double מצריכים 8 בייטים.
Processor
central processing unit או איך שכולנו מכירים אותו CPU הוא המנוע שמבצע ומתרגם את הפקודות מכונה של התוכניות שנמצאות ב main memory. בליבה שלו יש משהו שנקרא register שנקרא program counter או PC (גודלו כיחידת מידה הנקראת word). בכל רגע נתון ה PC מצביע (מכיל בתוכו את הכתובת של) לפקודה בשפת מכונה שנמצא ב #Main Memory . מהרגע שהמערכת דולקת ועד הרגע שהיא נכבת ה CPU באופן רציף מרי פקודות שה PC מצביע עליהם ומעדכן אותו להצביע על הפקודה הבאה. על פניו, נראה כי המעבד פועל באופן די פשוט של מודל הוראות וביצוע שמוגדר על ידי ה instruction set architecture. במודל הזה הפקודות מורצות בסדר מסויים וביצוע של פקודה בודדת כולל בתוכו מספר תתי צעדים לביצוע. המעבד קורא את הפקודה מהזכרון שאותו הוא מקבל מהPC, מפרש את הביטים של ההוראה ומבצע מספר תהליכים פשוטים כדי לקיים את ההוראה. לבסוף הוא מעדכן את ה PC להצביע לפקודה הבאה שיכולה או לא יכולה להיות רציפה במיקומה בזכרון לפקודה הקודמת לה. התהליכים הפשוטים הנ״ל סובבים סביב ה זכרון הראשי, ה register file וה ALU (arithmetic/logic unit). ה register file הוא יחידת אחסון קטנה שמכילה אוסף של רגיסטרים אחרים בגודל word כשלכל אחד מהם שם ייחודי משלו. ה ALU מחשב את הערכים והכתובות של data שמוייצר בתוכנית.
הנה מספר דוגמאות לתהליכים שה CPU יכול לבצע בהתאם להוראה בשפת מכונה :
- Load: מעתיק בייט או מילה מהזכרון הראשי ל register, במצב זה הוא דורס את התוכן הקודם של ה register.
- Store: מעתיק בייט או מילה מה register למיקום ב main memory, דורס את מה שהיה קודם במיקום זה.
- Operate: מעתיק תוכן של שתי registers ל ALU על מנת לבצע פעולה אריתמטית על שתי המילים הללו ולאחסן את התוצאה ב register נוסף.
- Jump: שולף מילה מההוראה בשפת מכונה ומעתיק אותה ל PC, באופן כזה שדורס את התוכן הקודם ב PC.
כאמור, על פניו העקרון של ISA נשמע פשוט, אבל מעבדים מודרנים משתמשים במכניקות מסובכות בהרבה כדי לייעל ולזרז את ביצוע התוכנית. לכן נבצע הפרדה בין הISA של מעבד שמתאר את ההשפעה של פקודה בשפת מכונה על החומרה ל microatchitecture שמתאר איך המעבד בפועל ממומש.
הרצת התוכנית hello
עכשיו אנחנו יכולים קצת להתחיל להבין מה קורה כשמריצים את הexecutable שgcc ייצר עבור התוכנה hello שלנו.
תחילה ה shell קורא את הפקודה /.hello שכתבנו, הוא קולט כל תו שכתבנו ושומר אותו ב register שמאוחסן בזכרון. ברגע שנלחץ אנטר הshell יודע שסיימנו את תהליך הכתיבה והוא טוען את ה exe על ידי ביצוע שרשרת הוראות שמבצעות את הפקודות שתיארנו למעלה שמעתיקות את הקוד וה data שבתוכנית מהזכרון בדיסק ל main memory. המידע כולל את התווים שברצוננו להדפיס בתוכנית. באמצעות שימוש בטכניקה שנקראת DMA-direct memory access המידע יכול לנוע ישירות מהדיסק לזכרון הראשי בלי לעבור בכלל במעבד. ברגע שהקוד והמידע של התוכנית טעון בזכרון, המעבד מתחיל לבצע את פקודות שפת המכונה שבתוכנית. הפקודה מעתיקה את הבייטים שמייצגים את הסטרינג שנרצה להדפיס מהזכרון ל register file ולאחר מכן ל display device כשבשלב זה הן מוצגות במסך .
התהליך הנ״ל מוייצג בתמונות למטה:
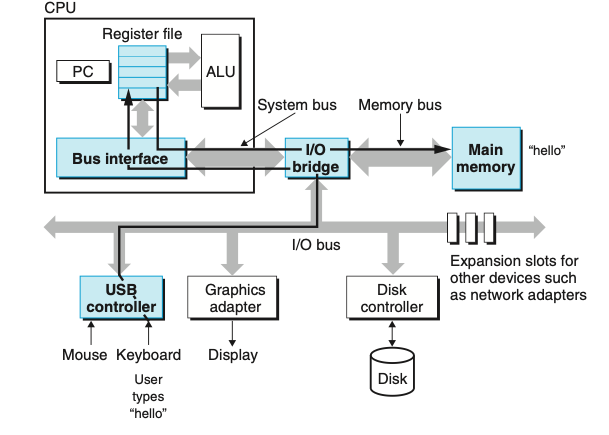
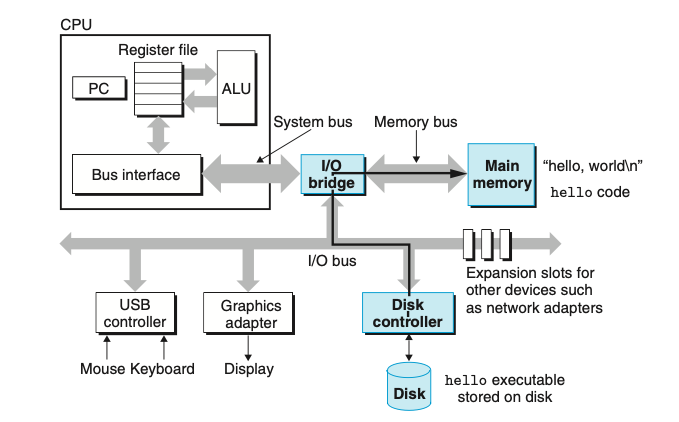
חשיבות ה Cache
אחד הדברים שניתן לראות מהתהליך הנ״ל הוא שזמן רב מושקע על ידי המערכת כדי להזיז מידע ממקום אחד לאחר. פקודות המכונה בתוכנית שלנו מאוחסנות בדיסק וכשהתוכנה טוענת אותם הם מועתקים ל main memory.
כשהמעבד מריץ את התוכנית, הוראות מועתקות מהזכרון הראשי למעבד. באופן דומה הdata string שנרצה להדפיס מועתק מהדיסק לזכרון הראשי ומשם למסך. לכן בעיצוב ובניית המערכת יש צורך לעשות את התהליכים האלה מהירים ככל השאפשר. בגלל התקדמות החומרה נוצר מעין פער בגדלים בין הזכרון בדיסק לזכרון ב main memory ולזכרון ב registers. הפער הזה נקרא processor-memory gap.
יותר זול וקל להכין מעבדים שעובדים מהר יותר מלגרום ל main memory לרוץ מהר יותר.
כדי להתמודד עם הפער הזה ישנה במערכת רכיב אחסון הנקרא cache memory שתפקידו להיות אחסון זמני למידע שהמעבד ככל הנראה יצרוך בעתיד הקרוב.
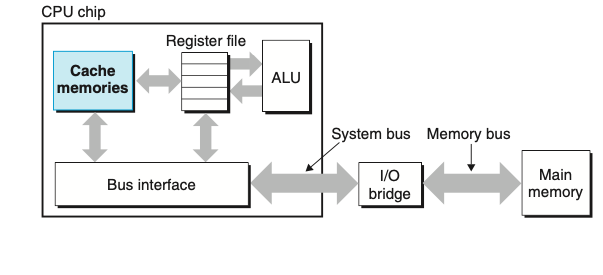
זכרון בשם L1 Cache שנמצא בציפ של המעבד שומר עשרות אלפי בייטים שניתן לגשת אליהם מהר כמעט כמו לגשת ל register file (שכאמור הוא משמעותית קטן יותר בנפח הזכרון שלו). מטמון גדול יותר בשם L2 Cache עם מאות אלפי בייטים זמינים מחובר למעבד באמצעות bus מיוחד. אומנם ייקח כפי 5 יותר זמן לגשת אליו מה L1 אבל הוא מכיל משמעותית כמות גדולה יותר של זכרון.
המימוש של רמות המטמות האלו נעשה באמצעות static random access memory- SRAM. מערכות מתקדמות אף יותר מכילות רמה שלישית של cache. הרעיון מאחורי המטמון הוא שהמערכת יכולה לנצל את האפקט של זכרון גדול מאוד ומהיר מאוד באמצעות שיטות הlocality שמיוצגות במטמון לפי הרמות האלה. ניתן להשתמש בידע הזה כדי לנצל מאוד את התוכניות שלנו.
הירכיית הזכרון
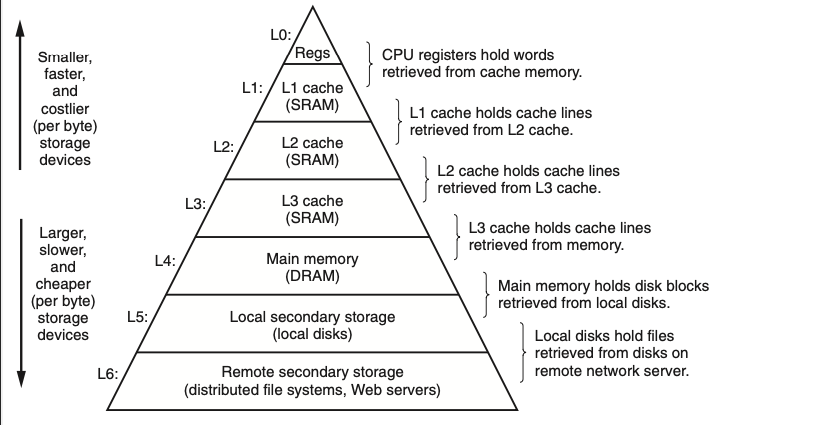
הרעיון הכללי הוא שכל רמה
מערכת ההפעלה מנהלת את החומרה
כשהshell טען את התוכנה והריץ אותה וכשהתוכנית הדפיסה את ההודעה למסך, אף אחת משתי התוכנות האלה באמת הייתה בעלת גישה למקלדת, המסך, הדיסק או הזכרון הראשי באופן ישיר. אלו נעזרו בשירותים שניתנו להם על ידי מערכת ההפעלה. מערכת ההפעלה היא שכבת תוכנה שמחברת בין תוכנית מסויימת לחומרה.
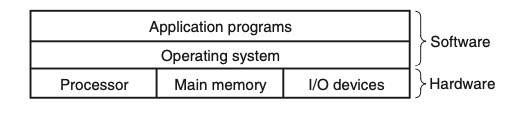
כל ניסיון של תוכנית לגשת לחומרה חייב לעבור דרך מערכת ההפעלה.
מערכת ההפעלה מקיימת שתי מטרות עיקריות
- הגנה על החומרה מפני שימוש לקוי או פוגעני.
- לספק לאפליקציות מכניקה מאוחדת ופשוטה כדי לגשת לחומרה שיכולה להיות לעתים מסובכת וכזאת שמשתנה בין מכשיר למכשיר.
באמצעות אבסטרקצייה היא מצליחה להשיג את שתי המטרות האלה. האבסטרקצייה נראת כך :
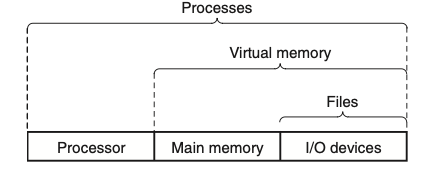
files הם אבסטרקצייה למכשירי IO.
virtual memory זה אבסטרקצייה גם לזכרון הראשי וגם לרכיבי IO.
ו processes הם אבסטרקצייה לכולם.
Processes
במערכות המודרניות, כשנריץ תוכנה כמו hello, מערכת ההפעלה תציג לנו אשלייה שזאת התוכנה היחידה שרצה במערכת. התוכנה מופיע כאילו היא מקבלת גישה אקסלוסיבית להשתמש גם במעבד וגם בזכרון הראשי ובכל רכיבי החומרה האחרים. המעבד נראה כאילו הוא מבצע את פקודות התוכנה שלנו בלבד, אחד אחרי השני ללא הפרעה והקוד והמידע של התוכנית נראים כאילו הם היחידים בזכרון המערכת. האשליות הללו מסופקות לנו על ידי ה process שהוא אחד מהרעיונות היותר מוצלחים בעולם מדעי המחשב.
process זה האבסטרקצייה של מערכת ההפעלה לתוכנה רצה. כמה תהליכים יכולים לרוץ במקבלים באותו זמן וכל אחד מהם נראה כאילו יש לו גישה בלעדית לחומרה. כשאומרים במקביל מתכוונים שהפקודות של תהליך אחד מנוהלות באינטרוולים עם הפקודות של תהליך אחר. ברוב המערכות יש יותר processes להריץ ממעבדים שיכולים להריץ אותם.
מערכות ישנות יותר יכלו להריץ תוכנה אחת בכל פעם בעוד שמעבדים עם מספר ליבות חדשים יותר יכולים להריץ מספר תוכנות ״במקביל״. בכל מקרה CPU בודד יכול להריץ מספר תהליכים באופן מקבילי על ידי כך שהתהליכים מחליפים בינהם. מערכת ההפעלה מנהלת את האינטרוול במכניקה שנקראת context switching.
כדי להמחיש נסתכל על מערכת המכילה מעבד אחד. מערכת ההפעלה עוקבת אחרי הstate information שהתהליך צריך כדי לרוץ. המידע הזה ידוע גם כ context והוא מכיל בתוכו מידע כמו הערכים שנמצאים ב PC , ב register file ובזכרון הראשי. בכל נקודת זמן מערכת עם מעבד בודד יכולה להריץ תהליך אחד בכל פעם. כאשר מערכת ההפעלה מחליטה שצריך להזיז שליטה מתהליך אחד לאחר, היא מבצעת החלפת קונטקסט על ידי שמירה של הקונטסט של התהליך הנוכחי, שחזור הקונטקסט של התהליך החדש והעברת השליטה לתהליך החדש. התהליך החדש שנכנס ממשיך מאיפה שהפסיק כשהוא העביר פעם קודמת את השליטה לתהליך אחר.
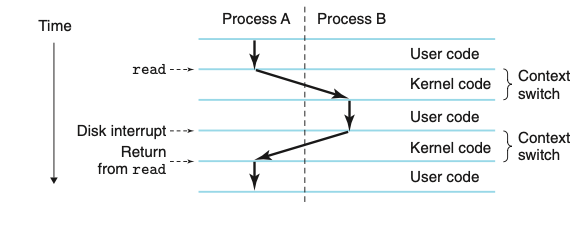
אם נחשוב על הקוד hello שכתבנו, אז ברגע שנלחץ אנטר ה shell ישלח את הבקשה על ידי הפעלת פונקצייה מיוחדת שנקראת system calls שמעבירה את אחריות ההרצה למערכת ההפעלה.מערכת ההפעלה שומרת את הקונטקסט של הshell ומייצרת תהליך חדש וקונטקסט מתאים עבורו ומעבירה אליו את האחריות. ברגע שhello יתסיים האחריות חוזרת ל shell.
כפי שניתן לראות בתמונה למעלה, המעבר בין תהליך אחד לאחר נעשת על ידי תוכנה שנקראת kernel. הkernel הוא חלק ממערכת ההפעלה שתמיד נמצא בזכרון. כשתוכנית מבקשת פעולה כלשהי ממערכת ההפעלה כמו קריאה וכתיבה מקובץ, התוכנית מפעילה את הsystem call שמעבירה לקרנל את השליטה. הקרנל מבצע את הבקשה ומעביר בחזרה את המידע והשליטה לתוכנית.
נשים לב שהקרנל הוא לא תהליך נפרד. הוא אוסף של קוד ומבנה נתונים שהמערכת משתמשת בה כדי לנהל את כל התהליכים.
Threads
ל process בפועל יש יותר מ single control flow , הוא מכיל בתוכו מספר יחידות ביצוע (execution units) הנקראות threads, כל אחד מהם רץ בקונטקסט של התהליך והם חולקים בינהם את אותו הקוד והמידע הגלובלי. threads הם מודל תכנותי חשוב מאוד בגלל הדרישות של תכנות מקבילי (concurrency) בשרתים, בגלל שקל יותר לשתף מידע בין threads לבין processes ובגלל שthreads עובדים בשיטה יעילה יותר מאשר processes. תיכנות multi threading הוא גם דרך לגרום לתוכנית לרוץ מהר יותר כאשר מספר processors זמינים למערכת.
Virtual memory
האבסטרקצייה שמספקת לכל תהליך את האשליה שיש לו גישה אקסלוסיבית לזכרון הראשי. כל תהליך מקבל זווית מבט אחידה על הזכרון שידועה בשם virtual address space . לתהליך של מערכת ההפעלה לינוקס תמונת הזכרון הוירטואלית תיראה כמתואר בתמונה.
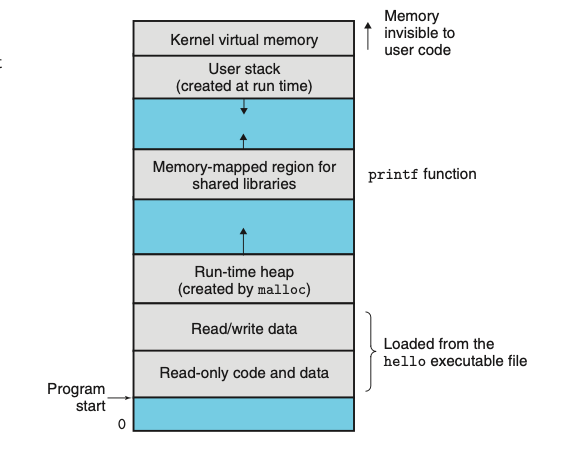
מערכות מבוססות UNIX יכילו מבנה דומה
בלינוקס, האזור למעלה של מרחב הזכרון שמור לקוד ומידע של מערכת ההפעלה שהוא משותף לכל התהליכים. האזור התחתון יותר של מרחב הזכרון מחזיק את הקוד והמידע של התהליך של הuser כלומר התוכנית שהוא הריץ. הכתובות במבנה הזה עולות ככל שמתקדמים למעלה במבנה.
מרחב הכתובות הוירטואלי נראה על ידי כל תהליך ומכיל מספר אזורים מוגדרים היטב שלכל אחד מהם מטרה ספציפית.
- program code and data - קוד מתחיל באותו כתובת קבועה לכל התהליכים, לאחר מכן ה data שמיקומו מושפע בהתאם למשתנים הגלובלים בקוד C. האזורים האלה מאותחים ישירות מהתוכן של קובץ executable.
- Heap - הheap מתרחב ומתכווץ באופן דינאמי בזמן ריצת התוכנית כתוצאה מקריאה לקוד מהספרייה הסטנדרטית של C כמו
mallocוfree. - Shared libraries - נמצא בערך באמצע המבנה ומכיל בתוכו קוד של ספריות שמשותפות עם התתוכנית כמו הספרייה הסטנדרטית ו ספריות מתמטיות.
- Stack - הקומפיילר משתמש במחסנית כדי לממש קריאות לפונקציות במהלך התוכנית. כמו הערימה הוא מתכווץ ומתרחב באופן דינמי בזמן ריצת התוכנית.
- Kernel virtual memory - האזור הגבוה ביותר במרחב הזכרון שמור לקרנל. אפליקציות לא יכולות ומורשות לקרוא ולכתוב לתוכן של האזור הזה או לקרוא לפונקציות משם באופן ישיר. עליהם לקרוא לקרנל כדי לגשת לאזור הזה.
כדי שזכרון וירטואלי יעבוד יש צורך לממש אינטרקציות מורכבות בין החומרה למערכת ההפעלה, למשל, תרגום לחומרה של כתובת במיוצרת על ידי המעבד. הרעיון המרכזי הוא שמירה של התוכן של מרחב הזכרון הוירטואלי בדיסק ולהשתמש בזכרון הראשי כ cache.
Files
אוסף של בייטים. לכל רכיב I/O (דיסקים, מקלדות,מסכים ואף רשתות) יש מידול כקובץ. כל קלט ופלט של המערכת מבוצע על ידי קריאה וכתיבה מקובץ על ידי שימוש ב Unix I/O. היתרון הגדול בקבצים שהן מספקים לתוכניות תמונה אחידה של כל מכשירי ה IO שעשויים להיות חלק מהמערכת. למשל , תוכניות שמשנות את הזכרון בדיסק לא מודעות בכלל לטכנולוגייה שבה משתמש הדיסק וניתן להריץ את התוכניות בכל מערכת אחרת שמשתמשת בטכנולוגיות דיסק אחרות.
תקשורת בין מערכות באמצעות הרשת
בעולם המודרני מערכות מחוברות אחת לשנייה באמצעות הרשת. מנקודת מבט של מערכת בודדת, הרשת יכולה להיות כמו עוד רכיב IO.
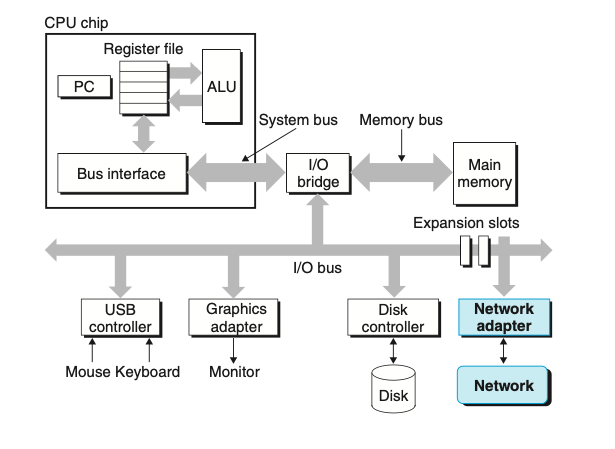
כשהמערכת מעתיקה אוסף של בייטים מהזכרון הראשי לרכיב הרשת ה network adapter, המידע משונע ברכבי הרשת למכשיר אחר במקום לרכיב אחר באותה מערכת. באופן דומה המערכת יכולה לקרוא מידע שמגיע מהרשת ולהעתיק אותה לזכרון הראשי.
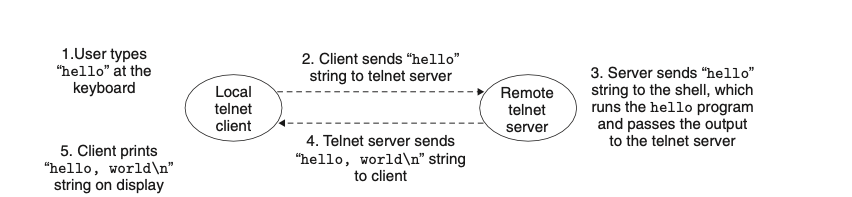
הרצת התוכנית hello על גבי הרשת באמצעות שרת telnet.
קונספטים נוספים חשובים
Amdahl’s Law
הרעיון מאחורי החוק הזה מגיע מהשאלה ״מה יקרה האם נחזק חלק מסויים במערכת ונשפר את הביצועים שלו?״ התושבה לשאלה הזאת ידועה כחוק הזה. הרעיון מאחוריו הוא שכאשר מריצים יותר מהר חלק אחד במערכת, האפקט על המערכת כולה תלוי בחשיבותו במערכת ובכמה שיפרו את מהירותו (ביצוע = מהירות ברוב החלקים בחומרה).
נסמן את הזמן שלמערכת לוקח להריץ תוכנה כלשהי כ
ומפה נסמן את
Concurrency and Parallelism
משתמשים במונח concurrency כדי לתאר קונספט של מערכת עם מסםר פעולות בו זמנית ובמונח prallelism כדי להתייחס לשימוש של concurrency כדי לגרום למערכת לרוץ מהר יותר. parallelism ניתן לשימוש במספר רמות אבסטרקצייה במערכת מחשב.
Thread-Level Concurrency
המצאנו מערכת מעל האבסטרקצייה process שמאפשרת למספר תוכנות לרוץ באותו הזמן. באמצעות threads אפשר אפילו להריץ באופן מקבילי מספר control flows באותה התוכנית, תחת process יחיד.
במערכת של מעבד יחיד uniprocessor system אין באמת ריצה במקביל של תוכנות אלא יש סימולצייה של זה על ידי כך שהמחשב מחליף בין כל התהליכים שרצים בכל רגע נתון. הצורה הזאת של concurrency אפשרה למספר משתמשים להתממשק עם מערכת באותו הזמן כמו למשל מספר משתמשים שמנסים לגשת לעמוד דפדפן. באופן דומה משתמש יחיד יכול כעת להריץ מספר תהליכים במחשב שלו בו זמנית.
ישנן מערכות multiprocessor system כלומר מערכת מרובת מעבדים שמנוהלת על ידי הkernel של מערכת ההפעלה. מערכות אלו הופכות להיות הנורמה עם הופעתן של multi-core processors ו hyperthreading. ִ
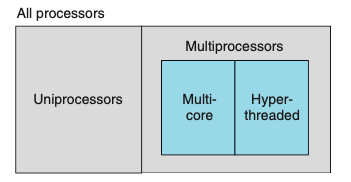
מעבדים מרובי ליבות מכילים מספר CPU שידועים גם כ cores והם משולבים ל integrated-circuit chip.
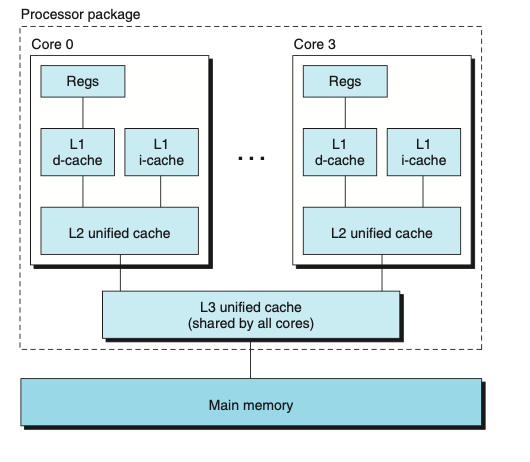
לכל ליבה יש L1,L2 מטמון משלהם וכל L1 מפוצל לשניים: הראשון כדי להחזיר פקודות מכונה והשני להחזיק data. הליבות האלה חולקות בינהן מטמון ברמה גבוהה יותר (למעשה כל 4 ליבות חולקות בינהן L3 cache) .
hyper-threading נקרא גם simultaneous multi-threading היא טכניקה שבמאפשר ל CPU יחיד לבצע מספר flows of control. הטכניקה הזאת מאפשרת לייצר מספר עותקים של רכיבים מהCPU כמו ה PC ו register files ובו זמנית מחזיק עותק יחיד של רכיבים אחרים כמו הרכיב שמחשב אריתמיקה של מספרים עם נקודה עשרונית.
הטכניקה הזאת מאפשרת שימוש מורכב ויעיל יותר של threads , במצב רגיל התהליך היה צריך להשקיע כ 20,000 סיבובי שעון (זה יחידת זמן במונחים של מעבדים) כדי להחליף בין threads. באמצעות הטכניקה הזאת והשכפול המעבד יכול לתזמן מספר תהליכים ו threads בהתאם למשאבים שכל תהליך מבזבז או לא מבזבז.
השיפורים האלה מאפשרים לתוכנות בודדות שמשתמשות ב multi-threading לרוץ מהר יותר וגם למזער את מספר ההחלפות בין threads שהמעבד עושה כאשר הוא מריץ מספר תהליכונים.
Instruction-Level Parallelism
ברמה נמוכה יותר של אבסטרקצייה, מעבדים מודרנים יותר יכולים להריץ מספר פקודות בבת אחת, יכולת זאת ידועה בשם instruction-level parallelism.
פקודה בשפת מכונה דורשת בערך 20 סיבובי שעון או יותר כדי לבצע אותה באופן סינכרוני. עם זאת, המעבדים משתמשים בטכניקות מסויימות כדי לבצע כ100 פקודות בבת אחת. אחת הטכניקות נקראת pipelining שמשמעותה היא שהפעולות הדרושות כדי לבצע פקודה מחולקות לשלבים שונים והחומרה מסודרת בצורה כזאת שכל חלק בה יודע לבצע את אחד השלבים וכל חלק יודע לעבוד במקביל.
Single-Instruction, Multiple-Data (SIMD) Parallelism
ברמה הנמוכה ביותר, מעבדים מודרנים מכילים חומרה מיוחדת שמאפשר לפקודה יחידה לגרום לכך שמספר פעולות ירוצו במקביל. מצב זה נקרא SIMD parallelism. היכולת הזאת מאוד טובה לתוכניות שמעבדות תמונות , גלי קול ומידע מוידאו.
קומפיילרים מנסים באופן אוטומטי להשתמש בתכונות המקביליות הללו בתוכניות C אבל דרך יותר יעילה היא להשתמש במשתנה מסוג vector שהוא נתמך על ידי הקומפיילר כמו gcc כך שניתן לבצע פקודה מסויימת על כמה אלמנטים בתוכו , במקביל.
The Importance of Abstractions in Computer Systems
הקונספט של אבסטרקצייה הוא קונספט שיחזור על עצמו במדעי המחשב עוד הרבה. אחד הדוגמאות הקלאסיים ביותר היא בנייה של API פשוט עבור מספר פעולות, באופן כזה שמאפשר למתכנת אחר להשתמש באותו ממשק בלי לצלול עמוק למימוש.
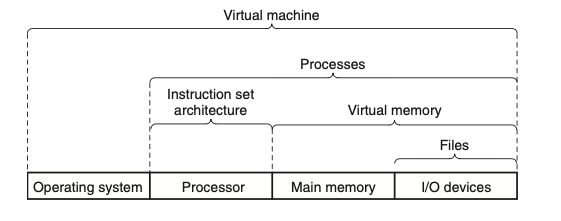
שפות תכנות שונות מספקות רמות שונות של אבסטרקצייה, כמו למשל המחלקה של java ו פונקציות פרוטוטייפ ב C .
כמו שראינו וניתן לראות בתמונה למעלה, הכימוב בא לידי ביטוי גם במערכות מחשב. מבחינת המעבד ה ISA הוא אבסטרקצייה לחומרת המעבד. באמצעות כך, קוד בשפת מכונ מתנהג כאילו הוא מורץ על מעבד שמבצע פקודה אחת בכל פעם. מתחת לפני השטח החומרה מורכבת הרבה יותר ומריצה מספר פקודות במקביל אבל תמיד שומרת על כך עקבי עם המודל הסנכורני.
באופן הזה מימוש שונה למעבדים יכולים לבצע את אותם פקודות בשפת מכונה כאשר כל מימוש מקיים עלויות ריצה שונות.
מבחינת מערכת ההפעלה כבר הראנו את שכבות האבסטרקצייה שלה, עליהן נוסיף שכבה נוספת שלא דיברנו עליה, המכונה הוירטואלית (virtual machine). הוא מספק אבסטרקצייה לכל המחשב, כולל מערכת ההפעלה, המעבד והתוכניות. הרעיון הזה מתאים לניהול תוכנות שחייבות לרוץ על מספר מערכות הפעלה או גרסאות שונות של אותה המערכת.