Generalization
הכללה בלמידת מכונה מתייחסת ליכולת של מודל לבצע ביצועים טובים על נתונים חדשים, בלתי נראים, שאינם חלק ממערך ההדרכה. מודל שמכליל היטב הוא כזה שיכול לבצע במדויק תחזיות או החלטות על סמך תשומות חדשות, במקום רק לשנן את נתוני האימון.
ישנם מספר מתווים עיקריים יכולת כזאת:
- supervised learning - פונקציה הממפה קלט לפלט.
- unsupervised learning - מידע לא מאורגן
- reinforcement learning - למידה מסביבה אינטראקטיבית.
Supervised learning
בהינתן אוסף של דוגמאות
המטרה: להפעיל את הפונקציה על קלט חדש
הפונקציה h נבחרת ממשפחה של פונקציות H כל פונקציה נקבעת על ידי פרמטרים שונים W. נרצה למצוא את הפרמטרים המתאימים ביותר לפונקציה הטובה ביותר.
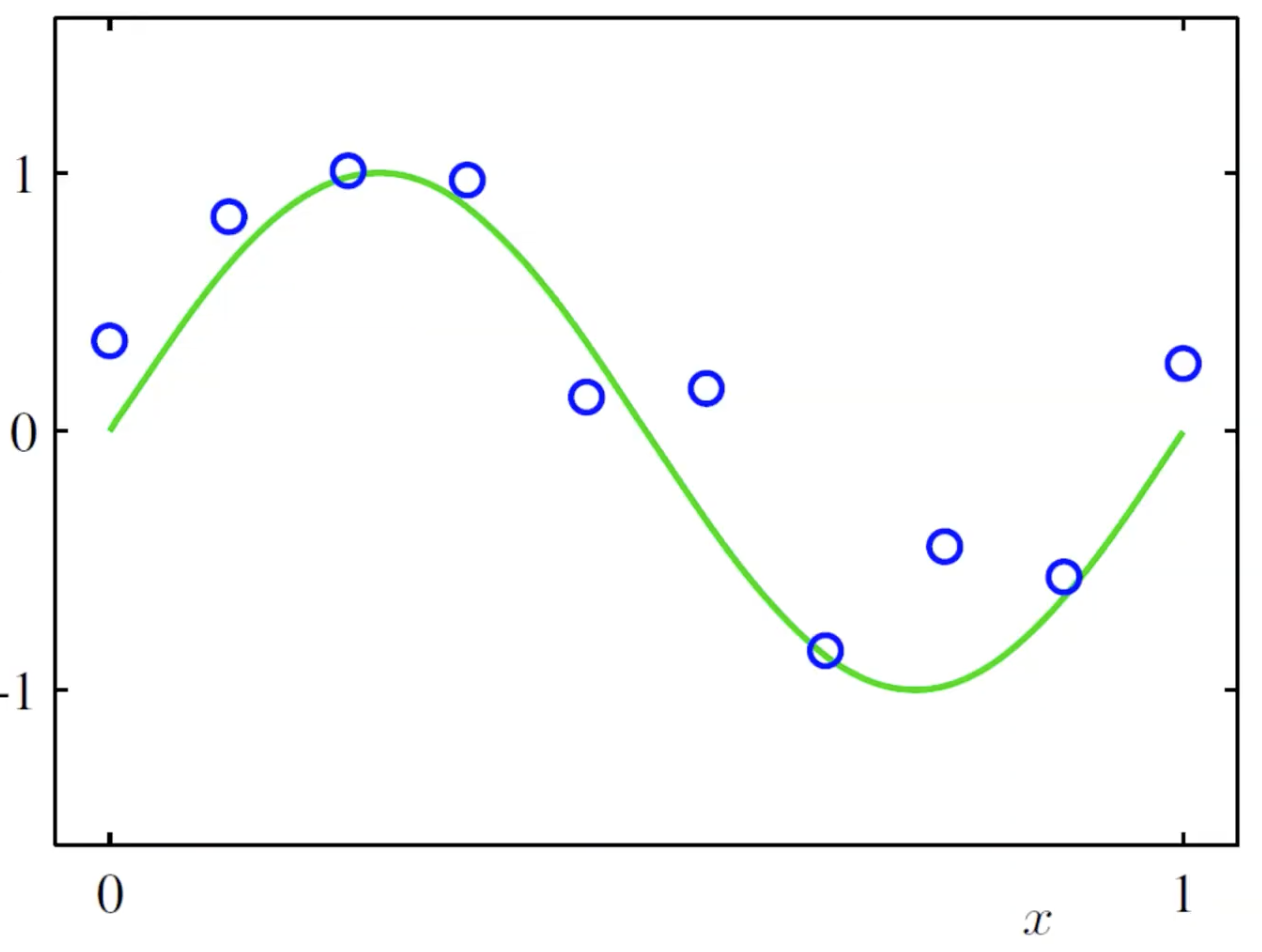
בעצם נרצה למצוא את הגרף הירוק (מייצג את ה truth) והנקודות הכחולות מייצגות את הערך של f(x) עם סטיית ״רעש״. המטרה היא בעצם למצוא את הפונקציה הירוקה לפי הערכים הכחולים. כלומר מציאת הכלל לפי הדוגמאות.
polynomial
משפחת הפונקציות הפולינומיות יכולה לעזור לנו להשיג קירוב טוב לכל פונקציה. זאת משפחה של פונקציות שיכולה לעזור לנו לתאר התנהגות של data, משפחה ״אקספרסיבית״. כיוון שבפועל אנחנו לא יודעים מה הכלל אנחנו צריכים לבחור משפחה מספיק עשירה שנוכל להשתמש בה על הדוגמאות שלנו כדי לקרב את הדוגמאות לכלל.
בmachine learning בעית הלמידה היא למצוא ערכים טובים למקדמים. בהינתן מודל w נגדיר
על ידי קביעת המקדמים נוכל לקבוע האם הפונקציה שלנו קרובה לדוגמאות (חישוב הפרשים)
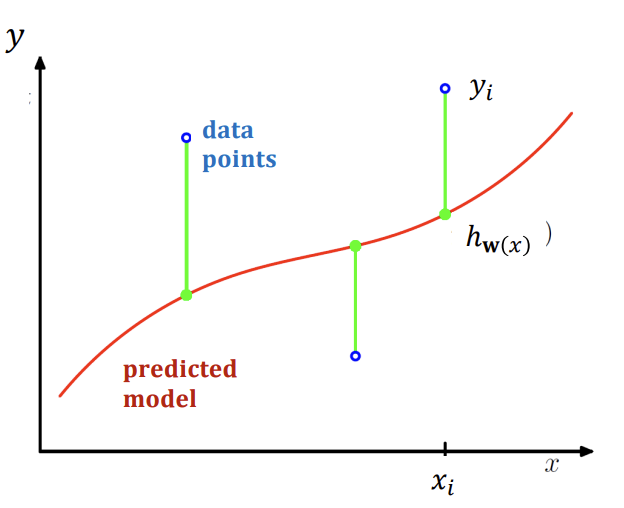
את השגיאה נגדיר באופן הבא
הביטוי
ישנן מספר סיבות לבחירת פונקצית השגיאה הזאת. בעיקר בגלל הנחת ההתפלגות של הdata והנוחות לעבוד עם הפרש ריבועי.
נראה כיצד למצוא את הערכים האופטימליים של המקדמים לפי הדרגה של המודל. לשם הדוגמה לקחנו את הפונקציה sin(x).
הרעיון הוא פשוט לצמצם את השגיאה או למצוא עבור אילו ערכי w אנחנו מקבלים את השגיאה המינימלית. כלומר נרצה לגזור ולהשוות ל 0 לפי כל אחד מהמקדמים.
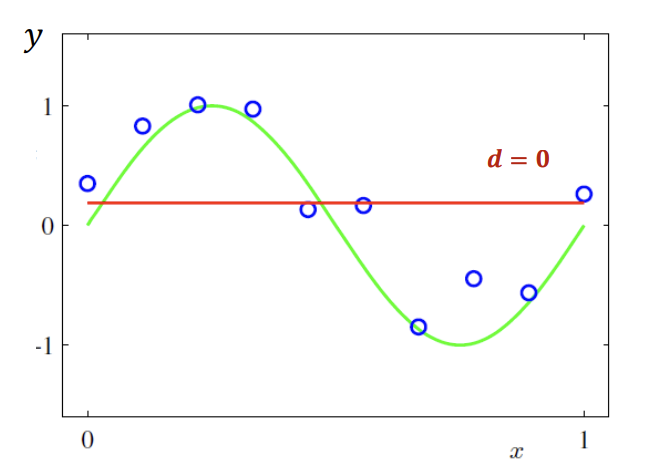
אם הדרגה היא 0 - כלומר מתקיים
נגזור
בעצם כאשר הערך של
באופן דומה כאשר הדרגה היא 1 נוכל למצוא את את המקדמים האופטימליים כאשר
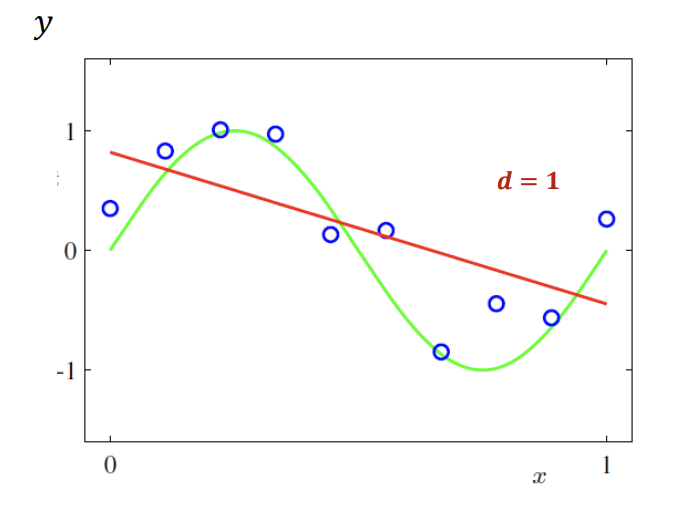
נשים לב לתופעה מעניינת, ככל שמעלים את הפולינום השגיאות ביחס ל training set (הנקודות הכחולות) יקטן והדיוק ישתפר. אבל הביצועים על הקו הירוק נעשים גרועים.
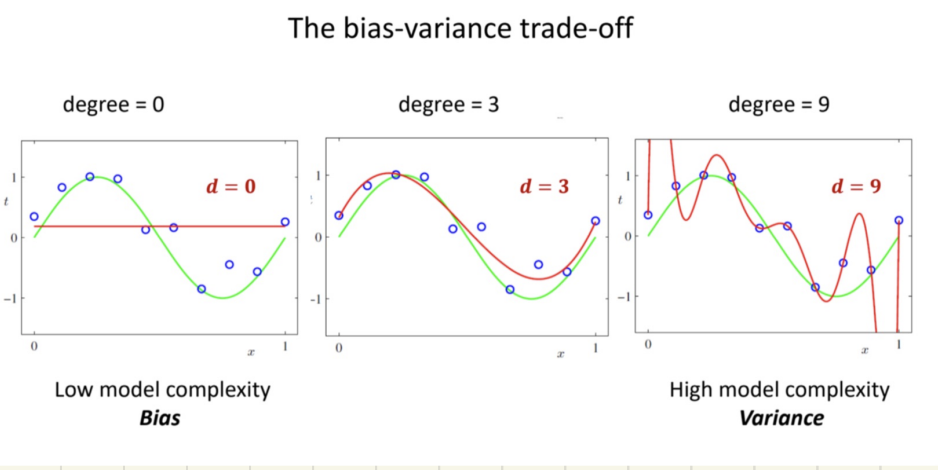
כלומר ישנן 2 בעיות, או שהביצועים לא טובים במצב שהדרגה נמוכה מדי או שעשינו יותר מדי אופטימיזציות על ידי דרגה גבוהה מדי.
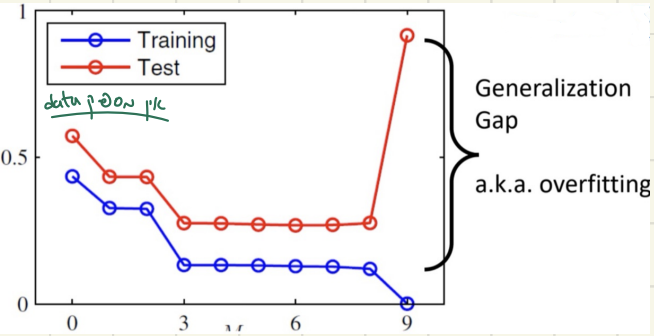
הפער הזה שנקרא overfitting מייצג את העובדה שבדרך כלל הdata שהמודל עובד איתו , כולל בתוכו גם איזה bias או רעש וככל שעולים בדרגת הפולינום המודל לומד גם את הרעש הזה ולכן בסופו של דבר הוא לא ייצג את הכלל האמיתי.
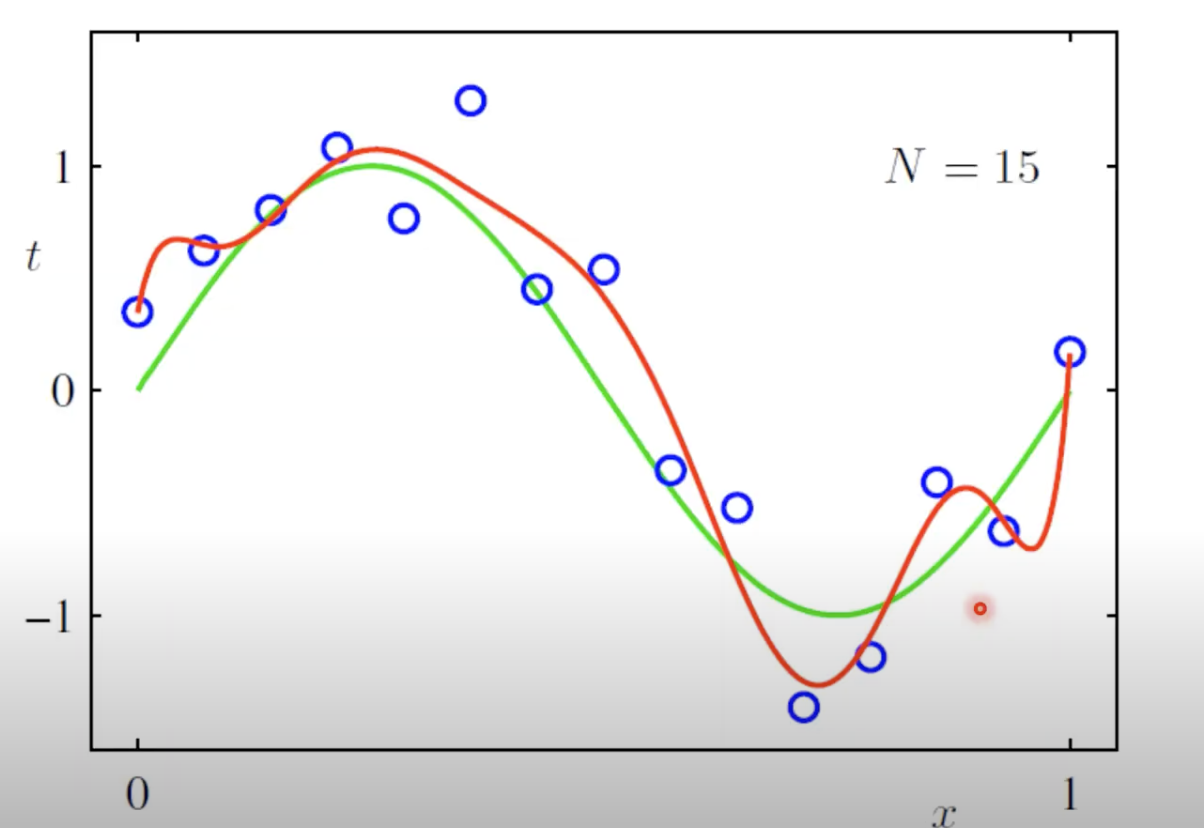
הפתרון הפשוט ביותר הוא להוסיף עוד data:
למשל עבור 15 דגימות פולינום ממעלה 9 יתנהג כך-
ועבור 100 דגימות-
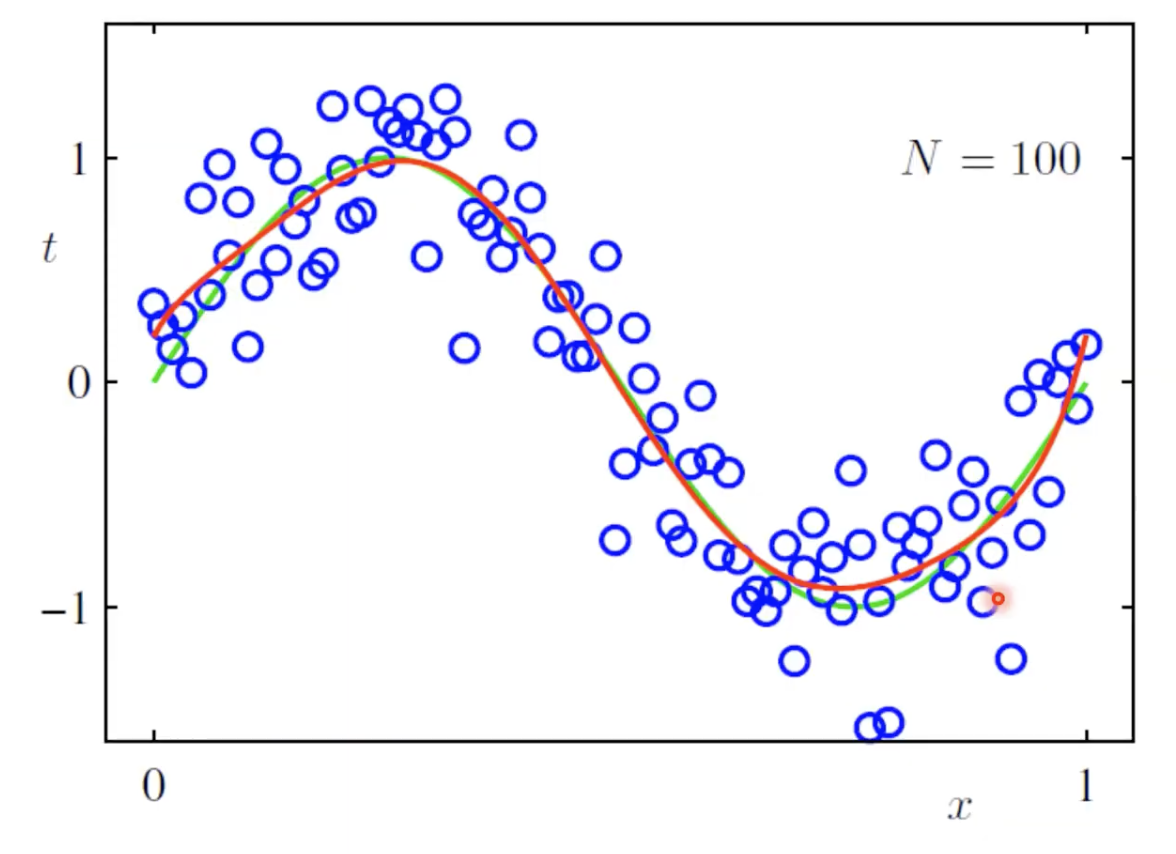
כלומר תמיד אפשר לשפר את המידע על ידי מתן עוד data.
הפתרון השני הוא generalization
אם נסתכל על ערכי w ככל שהדרגה עולה נראה שהם מקבלים מספרים מאוד גבוהים מה שיוצר את הפונקציות המסורבלות שראינו.

הרעיון כעת אומר שנרצה למצוא שתי מרכיבים לבעיה הראשון זה השגיאה והשני הוא מרכיב שבודק את הגודל המשוואות של w. נגדיר:
החלק השני נקרא regularizer
מתקיים ש
סוגי שגיאות
Training Error (1 - שגיאה אמפירית. נרצה שיהיה נמוך
Test Error (2 - שגיאה אמפירית. טיב המודל. בחירת hyper parameter שנותן מינימום test error.
3 ) generalization error - לא יודעים את הכלל. אין אינסוף מידע. התוחלת תניב את התוצאה בקירוב.