Sorting Algorithms
שיטות מיון וחסמים תחתונים
דיברנו על מספר שיטות מיון כמו מיון מיזוג וגם HeapSort נדבר על מספר שיטות מיון נוספות ונראה טענה מעניינת על חסם תחתון למיון בהמשך .
כמו כן נגדיר מיון יציב - כמיון שאם באוסף המקורי יש שני איברים זהים , לאחר מיון הם יהיו מסודרים לפי האינדקס שלהם ככה שזה שהיה לפני במערך המקורי יהיה לפני גם במערך החדש.
כל שיטת מיון אפשר להפוך למיון יציב, אדבר על כך בהמשך .
נתחיל ממיונים מבוססי השוואה- כלומר הדבר היחיד שיודעים על המידע זה יחס סדר כלשהו.
הסיבה שנרצה בכלל למיין היא שהדבר מאפשר לנו שיטות חיפוש נורא יעילות בזמן לוגריתמי כמו
חיפוש בינארי
חיפוש אקספוננציאלי
בניגוד לחיפוש ליניארי שהוא חסום בגודל האיברים.
insertion sort
אדגים על מערך דוגמה באופן ויזואלי ונתאר בקוד
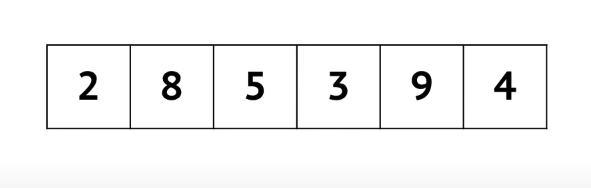
כל איבר נשווה עם האיבר שמשמאלו , אם האיבר שמשמאלו קטן יותר נסמן שהאיבר שלנו נמצא במיקום שלו ונעבור לאינדקס הבא, אם האיבר שמשמאלו גדול יותר, נחליף בינהם ונמשיך להשוות אחורה עד שנגיע למצב הראשון.
על המערך שלנו זה ייראה ככה:
- נעבור על 2 ועל 8 כי כל אחד מהם גדול מהמספר שמשמאלו.
- נגיע ל5 והוא קטן יותר מהמספר שמשמאלו ולכן נחליף עם 8 , הוא יותר גדול מ 2 אז נא נחליף יותר ונעבור לאיבר הבא
- 3 יותר קטן מ8 ולכן נחליף עם 8 וכנל לגבי 5
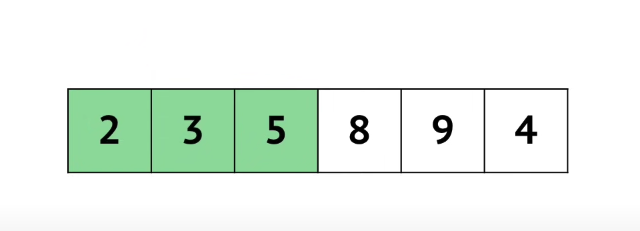
- ממשיכים מעל 8 ו 9, נשארנו עם 4 ומזיזים אותו על לפני האינדקס של 5 ונקבל
.
סיבוכיות הזמן היא
class InsertionSort {
void sort(int arr[])
{
int n = arr.length;
for (int i = 1; i < n; ++i) {
int key = arr[i];
int j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
bubble sort
האלגוריתם הכי פשוט ונאיבי,
רצים בלולאה כפולה, ועל כל איבר מקדמים אותו למיקומו המתאים באוסף, האלגוריתם לא מתאים לאוסף גדול של מידע כי הוא חסום ב
אופטימיזציה ניתן להוסיף flag שעוצר את הלולאה אם לא עשינו החלפה אחת .
static void bubbleSort(int arr[], int n)
{
int i, j, temp;
boolean swapped;
for (i = 0; i < n - 1; i++)
{
swapped = false;
for (j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
// swap arr[j] and arr[j+1]
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true;
}
}
// IF no two elements were
// swapped by inner loop, then break
if (swapped == false)
break;
}
}
selection sort
המטרה של מיון זה היא להכניס כל איבר לאינדקס המתאים לו , כלומר בכל איטרציה אנחנו נמצא את האיבר המינימלי ביותר עבור המערך ונכניס אותו למיקום המתאים. כל פעם עובדים על מערך קטן ביותר כלומר באיטרציה הראשונה נרוץ כל המערך ונמצא את איבר המינימום המתאים למקום ה0 , באיטרציה השנייה נרוץ על תת המערך ללא האינדקס הזה , וכן הלאה...
המיון הזה אינו יציב
class SelectionSort
{
void sort(int arr[])
{
int n = arr.length;
// One by one move boundary of unsorted subarray
for (int i = 0; i < n-1; i++)
{
// Find the minimum element in unsorted array
int min_idx = i;
for (int j = i+1; j < n; j++)
if (arr[j] < arr[min_idx])
min_idx = j;
// Swap the found minimum element with the first
// element
int temp = arr[min_idx];
arr[min_idx] = arr[i];
arr[i] = temp;
}
}
quick sort
זה מיון בשיטת הפרד ומשול ואלגוריתמים הסתברותיים , בוחרים pivot שזה איבר עוגן כזה שנרצה למיין את כל האיברים שגדולים ממנו אחריו ואת כל הקטנים ממנו לפניו. מסדרים אותם בשני תתי קבוצות , ומפעילים את אותו אלגוריתם עליהם בצורה ריקורסיבית .
בחירת הpivot יכולה להיות אקראית , לרוב מומלץ לבחור את האיבר האמצעי או האחרון כ pivot .
איך מסדרים את איבר ה pivot במקום המתאים לו?
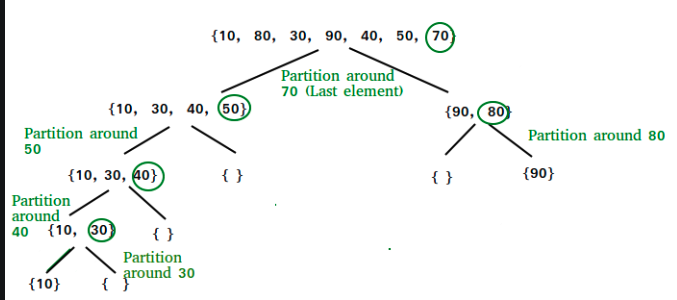
בישביל זה יש מתודה שנקראת partition שלוקחת את הpivot ומוצאת את האיבר המתאים לו הדרך הקלאסים היא להחזיק מצביע שנע לאורך המערך ומצביע שמתקדם רק כאשר איברים שקטנים יותר מהpivot נכנסים מאחורים על ידי המצביע הנע. בסוף האיטרצייה המצביע השני אמור להיות במקום המדוייק ש האיבר אמור להיות בו .
סך הכל נקבל :
static int partition(int[] arr, int low, int high)
{
int pivot = arr[high];
int i = (low - 1);
for(int j = low; j <= high - 1; j++)
{
if (arr[j] < pivot)
{
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, high);
return (i + 1);
}
static void quickSort(int[] arr, int low, int high)
{
if (low < high)
{
// pi is partitioning index, arr[p]
// is now at right place
int pi = partition(arr, low, high);
// Separately sort elements before
// partition and after partition
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
זמן ריצה: המקרה הגרוע הוא שהpivot תמיד יהיה האיבר הגדול ביותר או הקטן ביותר בכל איטרציה ואז נקבל נוסחה ריקורסיבת שצד אחד של הריקורסייה לא עובד בכלל והצד השני עובד על כל האוסף, כלומר יעשה
במקרה הטוב תמיד נבחר את האיבר האמצעי בגודלו בכל תת מערך ואז נקבל
המיון אינו יציב.
נשים לב quick sort הוא מיון די מיוחד כיוון שהאלגוריתם אינו דטרמינסטי, הוא מבוסס על מידה מסויימת של אקראיות, על זה נלמד בקורס באלגוריתמיקה.
AVL sort
שיטת המיון הפשוטה ביותר , פשוט להכניס את האיברים לעץ AVL ונכניס למערך בצורה inorder. נקבל מיון ב
המרה ממיון לא יציב למיון יציב
בגדול אלה הן שיטות המיון המוכרות כאשר אנחנו יודעים רק את יחס הסדר על האיברים.
בגדול לא כל מיון הוא יציב אבל אם נרצה נוכל להמיר לכזה על ידי עבודה עם זוג סדור של האינדקס המקורי במערך ושל הrecord המקורי שעבדנו איתו. ונשנה קצת את יחס הסדר להגדיר שאם ביחס המקורי שמוגדר על הrecord יצא שיוויון, תקבע שיחס הסדר < על האינדקסים יהיה זה שיקבע.
חסם תחתון למיונים מבוססי השוואה
נרצה להוכיח שהמקרה הכי טוב שנוכל למיין מיון מבוסס השוואה הוא
באופן כללי , חסם תחתון לבעיה
לא לכל הבעיות הצלחנו למצוא פתרונות המגיעות ל
בישביל להוכיח נבנה משהו שנקרא עץ החלטות
בשיביל להתחיל לבנות אותו נרצה קודם כל להגדיר אלגוריתם מיון על ידי כלל ההשוואות שאפשר לבצע על האיברים בתוכו נסמן

עץ ההחלטות של מיון הוא עץ בינארי המכיל את אפשרויות המיון שנקבל עבור רצף השוואות מסויים. כאשר שורש העץ מכיל את כל הסידורים האפשריים לאוסף זה,
למשל זה יהיה עץ החלטות עבור אוסף המכיל את האיברים
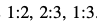
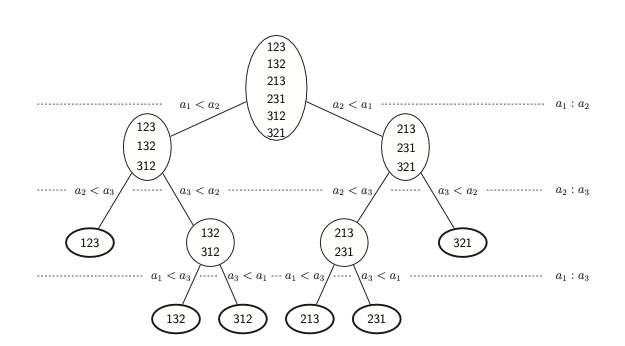
הרמה ה
השורש תמיד יכיל
אבל איך מכלילים את כל הסיפור הזה כי עד עכשיו דיברנו על סדר השוואות ספציפי וסדר השוואות מאוד מסויים . לשם כך נשתמש בתכונות העצים הבינאריים. אנחנו יודעים שתמיד יהיו
אנחנו יודעים בעץ בינארי יש לכל היותר
כלומר אם הגובה לא הגיע למספר הזה בוודאות יש עלים שמכילים יותר מצירוף אחד אחרי השווה , למעל לא נצליח למיין מערך עם 5 איברים ב 6 השוואות כי
וזה החסם מלמעלה, אם נרצה חסם תחתון :
וסה״כ ניסינו להוכיח חסם תחתום אבל הוכחנו חסם הדוק על מיון מבוסס השוואה שאומר שמספר ההשוואות הזקוקות כדי למיין
מיונים מיוחדים
דיברנו על מיונים מבוססי השוואה בלבד אבל הרבה פעמים אנחנו נדע עוד מידע על הrecord ושאיתו אנחנו עובדים. נוכל לנצל את המידע הזה כדי למיין בזמן יעיל יותר מהחסם שהראנו למעלה. בפרק זה נתמקד במיון ה
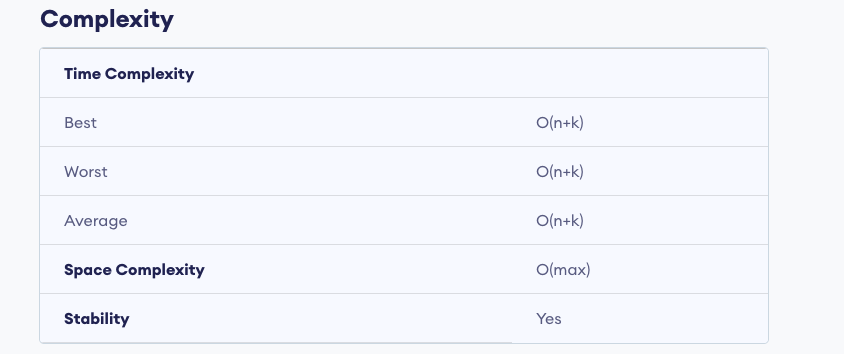
count sort
מיון מנייה כשם הוא מתבסס על כך שאפשר למנות את מספר הערכים שאותו ערך נמצא ולאחר מכן ניקח את הrecord שהופיע הכי הרבה פעמים . בישביל שזה יוכל לעבוד צריך שיהיה טווח לערכי ה record שיכולים להופיע. אנחנו נדגים את זה על מספרים שלמים אבל אפשר לקחת את זה למחוזות נוספים כמו תווים וכו.
יהי
השיטה
- יצירת מערך חדש בגודל
כך שהתא ה ישמש למספר הפעמים שהאיבר הופיע במערך . לדוגמה:
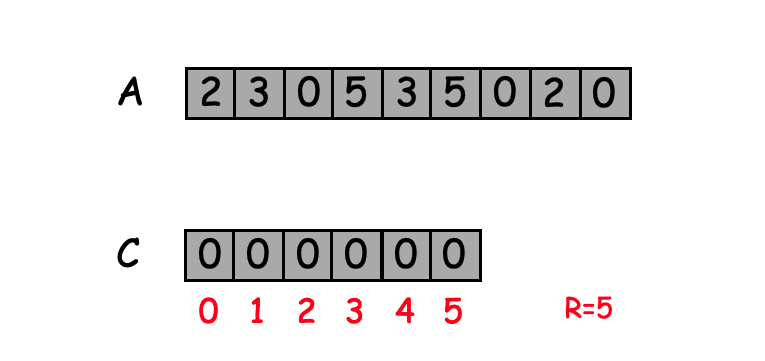
רצים על המערך וכל ערך שנתקל בו נוסיף מנייה לאינדקס המתאים לו, סך הכל נקבל :
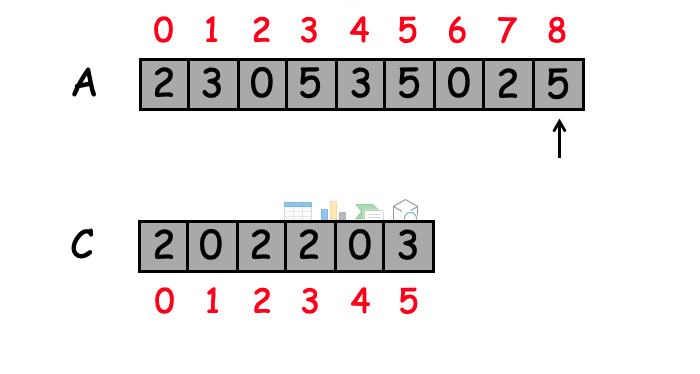
כעת, אנחנו יודעים כמה פעמים כל איבר , נרצה לסדר את האיברים במערך המקורי לפי סדר הופעת במיון יציב.
כעת כדי לדעת איפה כל איבר
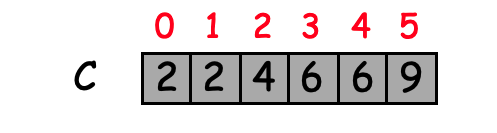
(לדוגמה באינדקס 2 חישבנו את 0 + 2 כי זה מה שיש באינדקסים 0 ,1)
עכשיו כל איבר ב
סה״כ רצים על איברי המערך
פלט:

סיבוכיות
void countingSort(int array[], int size) {
int output[10];
// Find the largest element of the array
int max = array[0];
for (int i = 1; i < size; i++) {
if (array[i] > max)
max = array[i];
}
int count[10];
// Initialize count array with all zeros.
for (int i = 0; i <= max; ++i) {
count[i] = 0;
}
// Store the count of each element
for (int i = 0; i < size; i++) {
count[array[i]]++;
}
// Store the cummulative count of each array
for (int i = 1; i <= max; i++) {
count[i] += count[i - 1];
}
for (int i = size - 1; i >= 0; i--) {
output[count[array[i]] - 1] = array[i];
count[array[i]]--;
}
// Copy the sorted elements into original array
for (int i = 0; i < size; i++) {
array[i] = output[i];
}
}
radix sort
מיון radix נועד לפתור את הבעיה הבעיה, שלפעמים אנחנו נקבל טווח נורא גדול של ערכים על קבוצה קטנה של מספרים. למשל עבור קבוצה
הרעיון כאן הוא שבמצב שאנחנו עובדים עם מספרים , נוכל למיין לפי ספרות המספר ולא לפי הטווח שהוא נמצא בו. (בישביל זמן יעילות אופטמילי צריך להמיר לבסיס שהוא
נוכל למיין לפי ה
דוגמה ויזואלית
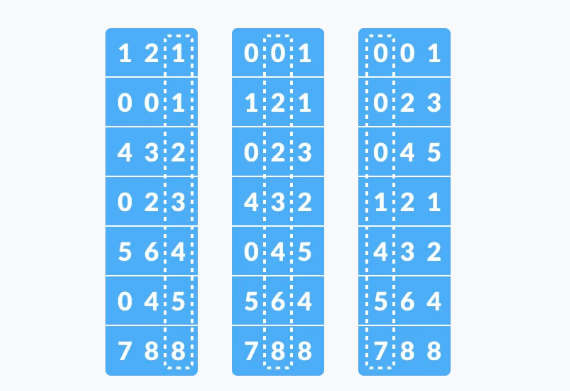
הקלט יהיה המערך
class RadixSort {
void countingSort(int array[], int size, int place) {
int[] output = new int[size + 1];
int max = array[0];
for (int i = 1; i < size; i++) {
if (array[i] > max)
max = array[i];
}
int[] count = new int[max + 1];
for (int i = 0; i < max; ++i)
count[i] = 0;
// Calculate count of elements
for (int i = 0; i < size; i++)
count[(array[i] / place) % 10]++;
// Calculate cumulative count
for (int i = 1; i < 10; i++)
count[i] += count[i - 1];
// Place the elements in sorted order
for (int i = size - 1; i >= 0; i--) {
output[count[(array[i] / place) % 10] - 1] = array[i];
count[(array[i] / place) % 10]--;
}
for (int i = 0; i < size; i++)
array[i] = output[i];
}
void radixSort(int array[], int size) {
// Get maximum element
int max = getMax(array, size);
for (int place = 1; max / place > 0; place *= 10)
countingSort(array, size, place);
}
}
סיבכויות :
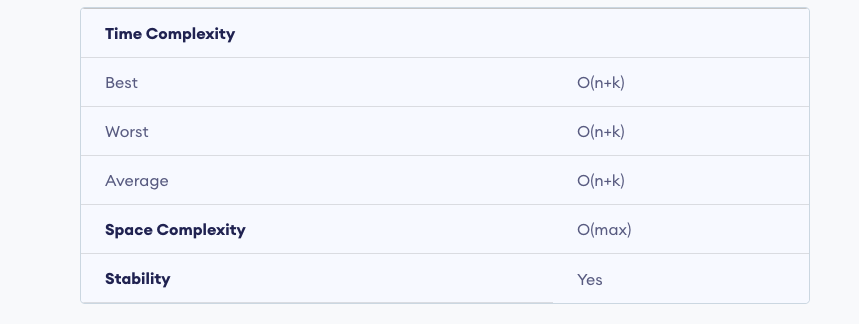
כאשר
מציאת האיבר ה k בגודלו
הרבה פעמים נרצה למצוא את איבר החציון באוסף מסויים . על פניו נשמע שכדאי לנו למיין וככה נוכל למצוא כל איבר שנרצה אבל לפעמים נרצה איבר במיקום ספציפי או רק את איבר החציון (האיבר האמצעי באוסף שלנו אם הוא היה ממויין) ואין סיבה למיין את כל האוסף בישביל זה כי הוכחנו בפרק הקודם שיש חסום הדוק על מיון מבוסס השוואה והוא לא חסם כזה טוב. במונח מקצועי זה יהיה
הרמז שלנו לתחילת הרעיון לפתרון מציאת החציון, יהיה להסתכל על מיון מהיר. הבעיה בגישה של quick sort לפתרון של מציאת איבר באינדקס מסויים בפרט האיבר האמצעי תהיה שיש סיכוי גבוה שחלק מסויים בריקוסיה לא יעשה כלום (אם בחרנו pivot באופן כזה שלאחר סידור תת המערך הימני או השמאלי לא יכילו את
הרבה פעמים הכללה של הבעיה שלכאורה תיראה קשה יותר, תהיה בעצם קלה יותר לפתרון. במקום לפתח אלגוריתם שמחזיר את החציון , נכליל את הבעיה למציאת אינדקס מסויים

וכעת נוכל לבחור 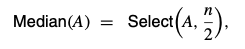
הגמישות שקיבלנו על ידי הכנסת אינדקס מאפשר לנו לדעת יותר טוב עם איזה תת מערך כדאי לנו לעבוד אחרי ה partition.
מבחינת סיבוכיות עדיין נקבל שבמקרה הגרוע כמו ב מיון מהיר נקבל
לפי נוסחת המאסטר.
נשאלת השאלה, האם נוכל לבנות אלגוריתם דיטרמינסטי , התשובה היא כן. גם פה אופן ההסתכלות יהיה למצוא קירוב של איבר החציון (כמו שבאלגוריתם הלא דטרמינסטי בחרנו להכליל על מנת שנוכל למצוא את החציון). אופן האלגוריתם ילך בצורה הבאה :
- חלוקת המערך לחמישיות (תתי מערכים של 5 איברים בכל מערך) ובכל אחד כזה מציאת החציון (הראנו שאפשר לעשות זאת ב 8 צעדים ובהמשך נראה שאפשר גם ב7).
- נבנה מערך חדש המכיל את חציוני החמישיות שלנו
- מציאת חציון החציונים על ידי שימוש באותו אלגוריתם על המערך החדש.
- כעת יש לנו את איבר האמצע, ניקח את ערכו נסמנו
- מאופן סידור החציונים אנחנו נקבל אחרי כל חציון שנמצא שהאיברים מימין יהיו הגדולים יותר והאיברים משמאל יהיו הקטנים יותר אבל לאו דווקא בסדר ממויין כלומר שיתקיים :
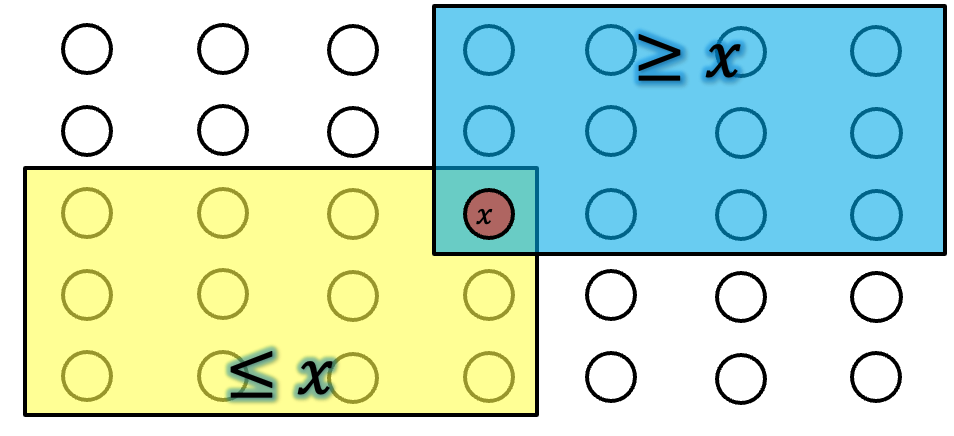
אלה המיקומים שיהיו אם ה
- נבצע חיפוש ליניארי בצד הרלוונטי עד שנגיע לאיבר.
נבנה לזה נוסחת נסיגה (היא יכולה להיות קצת מורכבת) :
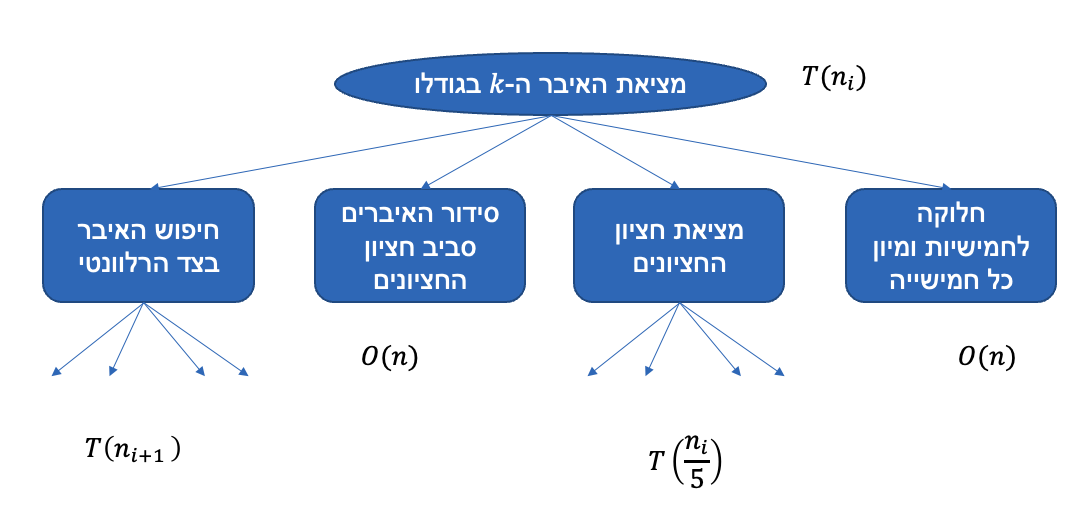
לפיכך יתקיים כי :
צריך לבטא את
לא אפרט את ההסבר המדוייק אבל
נוכיח על ידי שיטת ההצבה שזה שייך ל
בסיס :
צעד: נניח שהטענה מתקיים לכל
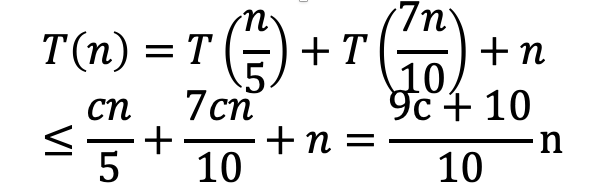
האי שיוויון נובע מהנחת האינדקוצייה כמובן .
יתקיים שהביטוי שיצא לנו יהיה קטן מ