אלגוריתמים הסתברותיים
אלגוריתם הסתברותי הוא אלגוריתם שמקבל מחרוזת אקראית
ישנם מספר דרכים למדל את
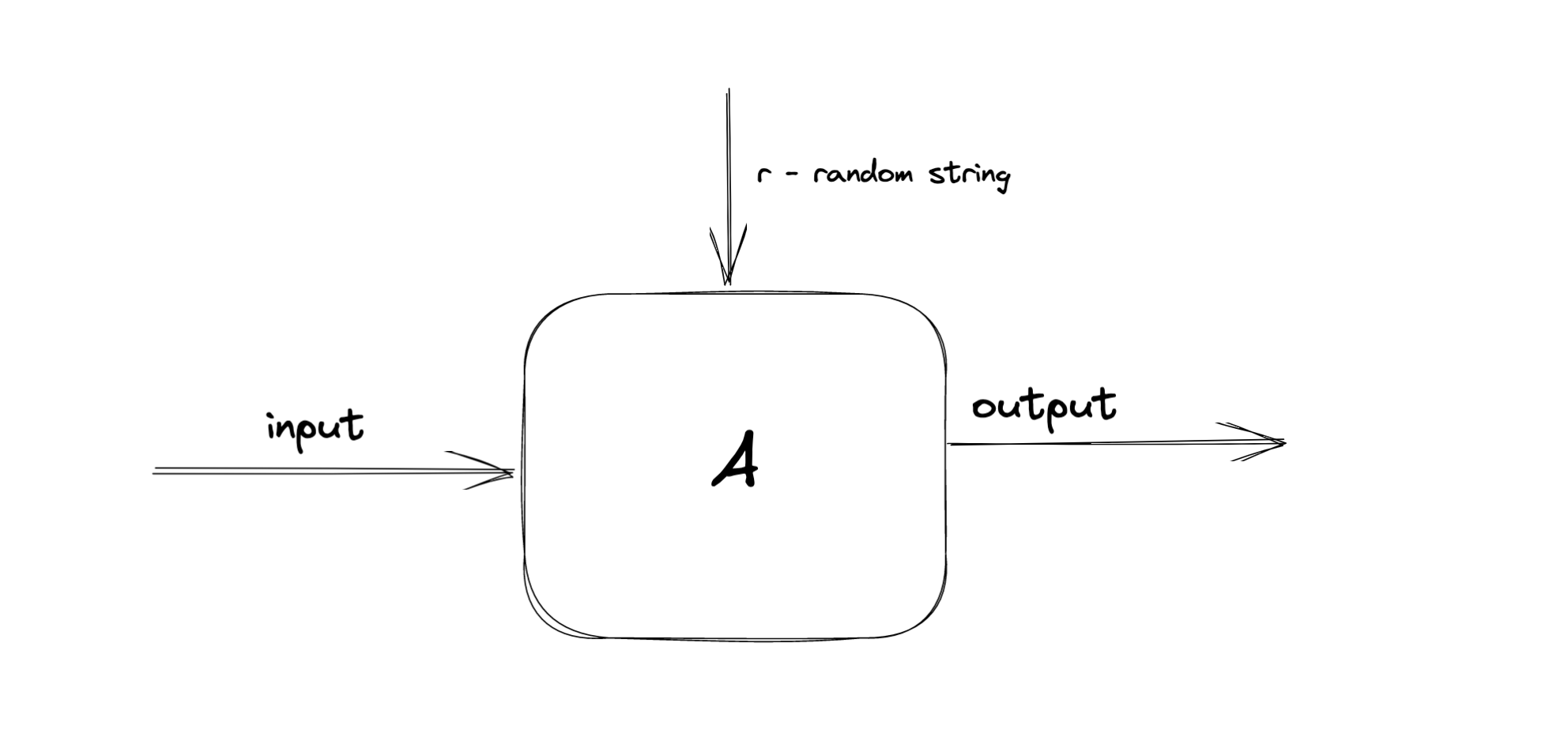
בדרך כלל, כאשר אנחנו מריצים אלגוריתם דטרמיניסטי שלא משתמש בכלים אקראיים, זמן הריצה והנכונות ברורים לנו – אנו יודעים להוכיח אותם.
ברגע שאנחנו משתמשים באקראיות ובמחרוזת
- לרוץ בזמן שונה
- להחזיר תשובה שונה
למשל אם האלגוריתם בוחר מספר אקראי
מקרה אחר למשל, אם המערך הוא בגודל
- זמן הריצה הוא משתנה מקרי (תלוי ב
) - נכונות האלגוריתם היא גם כן משתנה מקרי (היא תלויה ב
)
הדוגמה הכי קלאסית לאלגוריתם עם זמן ריצה מקרי הוא Quick Sort שבו ה pivot נקבל בצורה אקראית. אם הבחירה של הפיבוט היא רעה אנחנו יכולים להגיע לזמן ריצה של
דוגמא לאלגוריתם שלא תמיד נכון – אלגוריתם שמקבל סדרה של מספרים ורוצה להחזיר מספר זוגי מתוך הסדרה. הוא בוחר מספר באופן אקראי, אם המספר אי-זוגי והוא מחזיר אותו, אז האלגוריתם טעה. אם בוחרים רק מספרים זוגיים, אז צודקים. כלומר, נכונות האלגוריתם תלויה בקלט האקראי של הריצה.
סוגים של אלגוריתמיים רנדומים
ישנם מספר סוגים של אלגוריתמיים מקריים שאתעמק בהם כאן.
מונטה קרלו-
זמן הריצה הוא דטרמיניסטי אבל הנכונות היא משתנה מקרי, האלגוריתם עלול להצליח או לטעות. נרצה לנתח את הסיכוי לטעות ונרצה שהסיכוי לטעות יהיה כמה שיותר קטן כלומר אם גודל הקלט הוא
לאס וגאס-
האלגוריתם תמיד מצליח אבל זמן הריצה הוא משתנה מקרי. נרצה לנתח את התכונות ההסתברויות של זמן הריצה:
- תוחלת זמן הריצה.
- חסם עליון לזמן הריצה בסיכוי גבוה.
וידוא כפל מטריצות בינאריות
נציג אלגוריתם מונטה קרלו לוידוא של כפל מטריצות בינאריות. כלומר כל האריתמטיקה של המטריצות היא מעל
קלט: 3 מטריצות בינאריות
פלט: האם
הנאיבי הוא כמובן להכפיל עם כפל מטריצות מהיר בזמן ריצה
אם כן, נראה אלגוריתם שזמן הריצה שלו הוא
לאחר מכן נשפר את סיכויי ההצלה לאלגוריתם שזמן הריצה שלו הוא
אלגוריתם בסיסי
verify_binary_MM_basic(A,B,C)
choose random vector V = (v1,....,vn) of bits
Vb = B * V
Vab = A * Vb
if Vab = C * V
return true
return false
נשים לב שאם
זמן ריצה
בחירת הוקטור היא ב
כל כפל עם וקטור לוקחת
השוואה לוקחת
סה״כ
אם
ניתוח הסיכוי לטעות
יהי
לשם הסמנטיקה נאמר שוקטור
אם הוא לא רע נאמר שהוא טוב. נשים לב
למה
מספר הווקטורים הטובים הוא לפחות כמספר הווקטורים הרעים .
הוכחה
נתאר פונקצייה חח״ע שממפה וקטורים רעים לווקטורים טובים. יהי
בגלל ש
כאשר
יתקיים ש
נראה ש
כלומר הצלחנו לבנות פונקצייה שממפה וקטור רע לטוב.
קל להראות שזאת פונקצייה חח״ע שכן אם הפלטים הם וקטורים טובים שווים אם נחסר מהם את
מסקנה - הסיכוי לבחור וקטור רע הוא לכל היותר
אמפליפיקציה
נרצה לשפר את הסיכוי לטעות. נעשה זאת באמצעות אמפליפיקציה. בשיטה זו מריצים את האלגוריתם הבסיסי
verify_binary_MM(A,B,C)
k = alog(n)
for i = 1 to k
if verify_binary_MM_basic(A,B,C) = false
return false
return true
חישוב הסיכוי לטעות:
על מנת שהאלגוריתם הנ״ל יטעה מספיק שנבחר פעם אחת וקטור רע כלומר שהפלט של האלגוריתם הבסיסי אמור להחזיר שהם ״לא שווים״ אבל הוא מחזיר ״שווים״ נחשב את ההסתברות לכך
המעבר הראשון נובע מאי תלות בין הבחירה של הוקטור.
כפי שאמרנו מטרתנו היא לטעות בסבירות של לכל היותר
שזה הסיבה שבחרנו את k הזה
זמן ריצה
Quick sort פרנואידי
נסתכל על Quick Sort בהיבט יותר הסתברותי. נשים לב שזה אלגוריתם מסוג לאס וגאס שבו זמן הריצה הוא משתנה מקרי.
באלגוריתם זה אנחנו בוחרים אינדקס אקראי
המקרה הרע הוא מצב בו
המקרה טוב
לא חייב שהחלוקה תהיה בהכרח כמו במקרה הטוב כדי לקבל זמן ריצה כזה, גם אם החלוקה היא כזו שגודל כל צד הוא לפחות
מההבחנה הזאת אנחנו יכולים לבנות גרסה אחרת של האלגוריתם שנקראת מיון מהיר פרנואידי. מה שהוא עושה באופן די פשוט זה , אם לאחר חלוקה התנאי הנ״ל לא מתקיים כלומר, אם נסמן
נוסחת הנסיגה של האלגוריתם הרגיל ייראה ככה
נרצה להבין מהי תוחלת זמן הריצה כלומר ה״ממוצע״ של זמן הריצה שלנו.
נשים לב שבחירת הפיבוט היא ניסוי שמבצעים שוב ושוב עד שמצליחים ולכן זה ניסוי מתפלג גיאומטרית .
נסמן את הסיכוי להצלחה כ
על מנת שהפיבוט יהיה רע הוא צריך להיות או ברבע האיברים הכי קטנים או ברבע האיברים הכי גדולים. כדי שפיבוט יהיה טוב הוא צריך להיות בטווח שבין

סך הכל אם נציב ונחשב את התוחלת נקבל
Quick sort - ניתוח תוחלת זמן הריצה
נרצה לחשב את תוחלת מספר ההשוואות שכן ראינו שזאת הפעולה שמשפיעה על זמן הריצה של האלגוריתם בשלמותו כי היא זאת שמושפעת מבחירת הפיבוט. נשים לב שאנחנו לא משווים את כל האיברים אחד עם השני למשל אם שני איברים משוייכים ל
אז מתי האלגוריתם כן משווה בין
נסתכל על זה קצת אחרת
עבור
נבנה
מתי האלגוריתם משווה בין
אם אחד שכזה כן נבחר אז לא הגיוני שתהיה השוואה בינהם לכל אורך האלגוריתם שכן הם יופרדו ברגע שאחד כזה ייבחר.
נגדיר משתנה אינדיקטור
נחשב את התוחלת
ומתקיים מתוחלת של משתנה אינדיקטור
בטווח בינהם יש
סך הכל נציב בתוחלת ונחשב נקבל
מסקנה: מיון מהיר מבצע בתוחלת
Bucket sort
האלגוריתם הוא דטרממינסטי כאשר הקלט מיוצר בצורה אקראית.
נרצה לפתר את בעיית המיון כאשר כל מספר בקלט נבחר בהתפלגות אחידה מטווח המספרים
בעזרת מיון מבוסס השוואות ניתן למיין בזמן
הרעיון נקח את טווח המספרים ונחלק ל
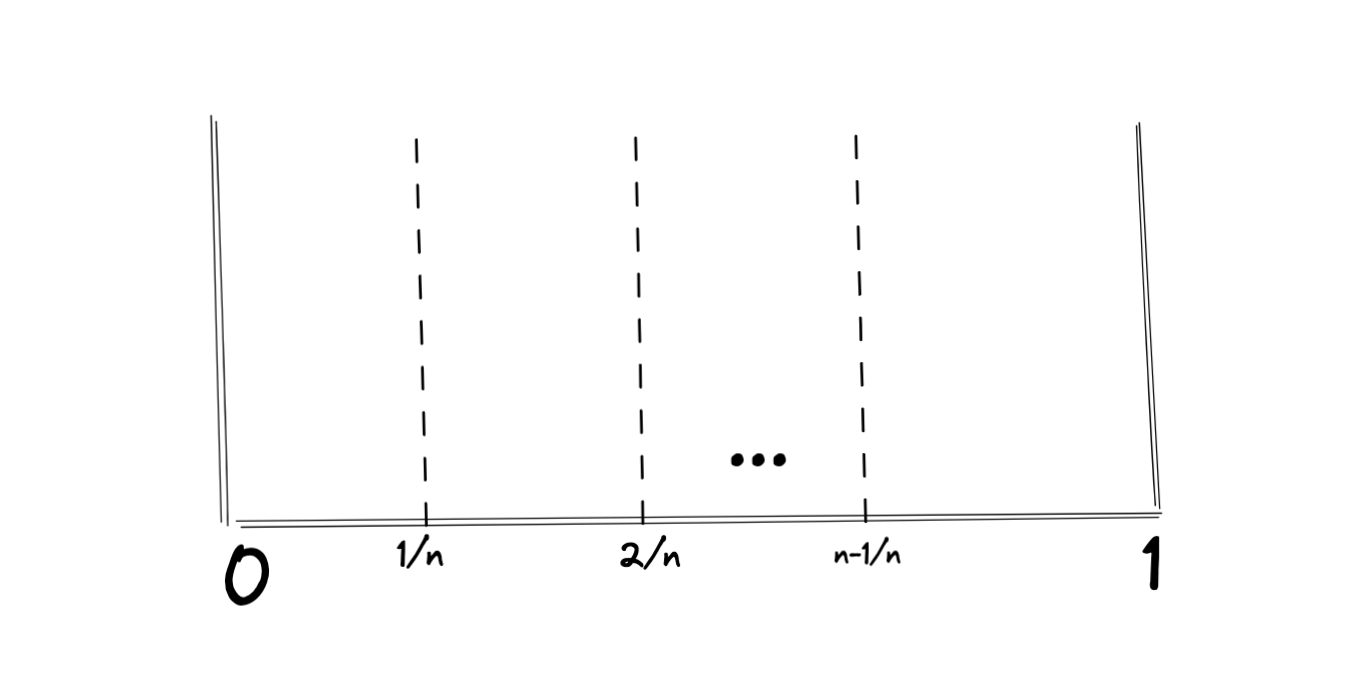
לכל איבר יש סיכוי של
אם כן אלגוריתם מיון דלי יעבוד באופן הבא:
א) נכניס כל איבר לדלי המתאים
ב) נמיין כל דלי בעזרת מיון הכנסה
ג) נשרשר את הדליים לפי סדרם
function bucketSort(array, k)
buckets ← new array of k empty lists
for i = 0 to length(array)
insert arr[i] into the correct bucket
for i = 0 to k
nextSort(buckets[i])
return the concatenation of buckets[0], ...., buckets[k]
נסמן את הדלי ה
נגדיר
זמן ריצה
הכנסה לדלי המתאים ליניארית
נמיין כל דלי בעזרת מיון הכנסה
שרשור הדליים לפי סדרם
סך הכל
תוחלת זמן ריצה
נשים לב שהאלגוריתם לוקח
עם תוחלת
מהגדרת השונות אנחנו יודעים ש
סה״כ נקבל
תוחלת זמן הריצה של האלגוריתם היא ליניארית בכמות האיברים במערך.
הסיבה העיקרים היא שיותר קל לחסום אותו מתמטית שכן הוא ריבועי ל