Prefix Code - Huffman Code
קודי-הפמן שימושיים מאוד וטכניקה אפיקטיבית לדחיסת מידע , שחוסכת 90% − 20% בד"כ , תלוי במאפייני המידע שצריכים לדחוס . נסתכל על המידע כסדרה של אותיות , האלגוריתם החמדן
נגדיר קוד בינארי חוקי לא״ב
- חח״ע
- שרשור של ביטים יכול לייצר רק שרשור אחד של תווים מהא״ב.
דוגמה טובה לכך היא ASCII שבו כל תו משתמש ב 8 ביטים ולכן יש לכלהיותר
דוגמה לקוד שלא מקיים את התכונה השנייה היא
| c( |
|
|---|---|
| a | 0 |
| b | 01 |
| c | 11 |
| d | 1 |
באופן הזה נקבל ש
prefix-free code
קוד תחילי עבור
- חח״ע
- לכל שתי תווים שונים בא״ב יתקיים שהפעלת c על אחד מהם היא לא רישא של השני ולהיפך
| c( |
|
|---|---|
| a | 000 |
| b | 01 |
| c | 1111 |
| d | 001 |
| e | 1110 |
| f | 110 |
בטבלה הראשונה c(d) הוא רישא של c(c) וכאן זה תרחיש שלא יתקיים.
prefix-free tree
נוכל להתייחס ל prefix-free code כעץ בינארי באופן הבא:
- התווים הם עלים
- הבן השמאלי משוייך ל 0 והימני ל 1
הוא שרשור של הביטים מהשורש לעלה.
למשל עבור הטבלה למעלה העץ ייראה כך
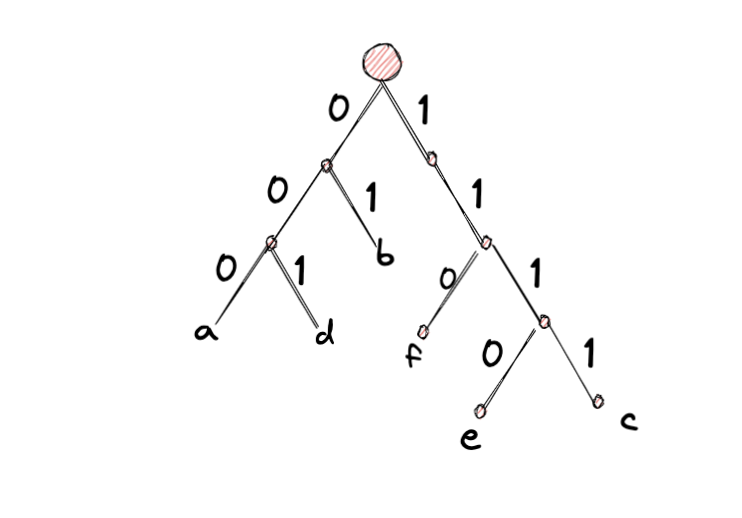
כמו כן נשים לב שקריאה של מחרוזת בינארית בשיטה הזאת תהיה קריאה של המחרוזת משמאל לימין עד שמגיעים לעלה וזה הופך להיות תו ואז ממשיכים מהתחלה מהשורש כדי להגיע לתו הבא.
נסמן:
(הסימון מייצג את מספר האיברים במחרוזת הבינארית)ֿ
optimal prefix-free code
נניח שיש לנו קובץ מאוד גדול ואנחנו רוצים לקודד את האותיות בקובץ על ידי שימוש ב prefix-free code שמביאה את ההגודל הקובץ המקודד למינימום.
נסמן את קבוצת האותיות בקובץ ב
אם נשתמש בקוד תחילי
זה בעצם הסכום של כל התדירות לאות כפול העומק שלה בעץ כלומר כמה פעמים נצטרך לרדת בעץ כדי להגיע לאות הזאת.
נרצה לבנות עץ קוד תחילי אופטימלי שעבורו COST יהיה מינימלי. נשים לב שאנחנו מקבלים כקלט את הא״ב והתדירות של כל תו בא״ב.
השאיפה שלנו היא להגיע למצב שבוא אנחנו בונים Variable length code שזה אומר שנשים קוד קטן יותר לאותיות עם תדירות גבוהה וקוד ארוך לאותיות עם תדירות נמוכה. למשל עבור הקידוד והתדירויות

נרצה להגיע למצב הבא

השאלה היא איך מגיעים למצב כזה?
כיוון אינטואיטיבי היה למיין את כל התווים לפי התדירות ולכל
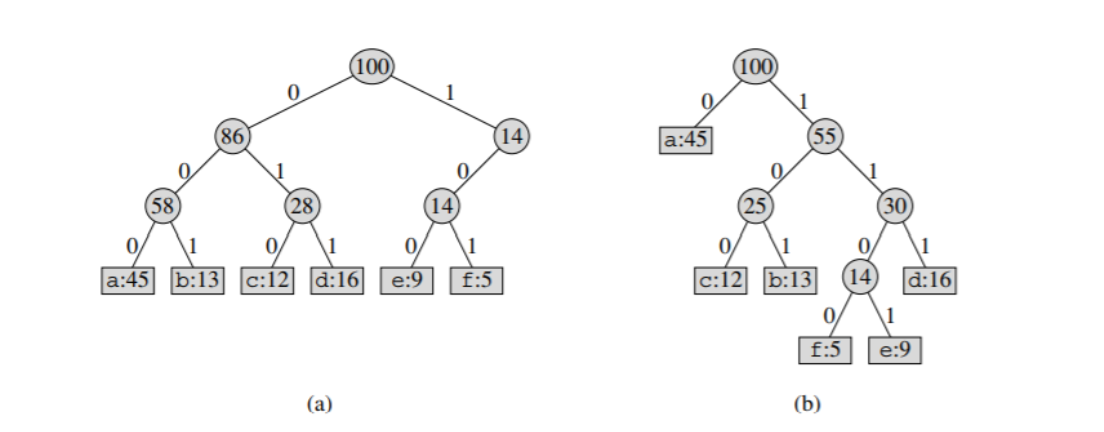
העץ השמאלי הוא הרגיל והעץ הימני הוא האופטמילי וזה בניגוד לאינטואיצייה שתיארתי למעלה שהייתה נותנת עץ אחר.
בשביל שנוכל לבנות את המבנה האופטימלי הזה בצורה פורמלית ולהוכיח את נכונותו כאלגוריתם חמדני נרצה להוכיח את הטענה הבאה:
למה
עץ קוד תחילי אופטימלי לא מכיל קודקוד פנימי עם ילד אחד, כלומר הוא עץ שלם
נניח בשלילה שלעץ תחילי אופטימלי
לפי אלגוריתם מחיקה מעץ בינארי , זאת מחיקה די פשוטה שכל מה שהיא עושה זה להקטין את עומק הילד , במקרה הזה
בסתירה לכך ש
בניית Huffman code
נרצה ללכת על משהו דומה לאינטואיצייה שתיארנו למעלה, במקום לתת את המסלול הכי קצר לתווים עם תדירות נמוכה נרצה ללכת בגישה של להעניק את המסלול הכי ארוך לתווים עם התדירות הכי גבוהה.
נראה אלגוריתם חמדן שמממש עץ קוד תחילי אוטפימלי שמראה בידיוק את הנ״ל. הוכחת נכונות האלגוריתם מבוססת על התכונות של אלגוריתם חמדני שהם הבחירה החמדנית ו תת המבנה האופטימלי . נראה את הפסודו קוד ואז נסביר ונוכיח אותו
HUFFMAN(E)
n = |E|
Q = E
for i=1 to n-1
do allocate a new node z
z.left = x = GET-MIN(Q)
z.right = y = GET-MIN(Q)
f[z]= f[x]ִ+f[y]
INSERT(Q,z)
return GET-MIN(Q)
אם
האלגוריתם בונה עץ חילי אופטימלי בשיטת bottom-up, כלומר קודם כל בונים את העלים ועולים למעלה לשורש.
מתחילים בא״ב בגודל
דוגמת הרצה עבור
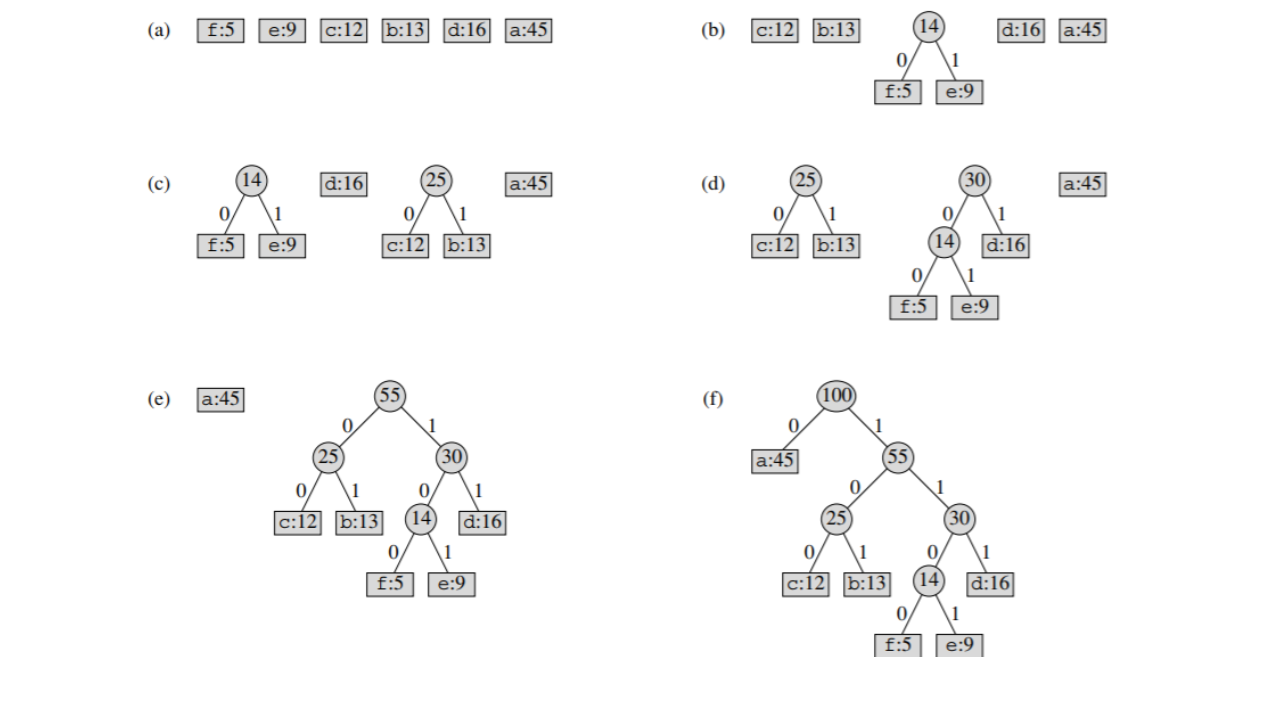
זמן הריצה עבור
הוכחת נכונות
תכונת הבחירה החמדנית
קודם כל נבין מהי הבחירה החמדנית שעשינו כאן, עבור א״ב
הוכחה:
יהי עץ קוד תחילי אופטימלי
בעץ
(זה עניין סמנטי בלבד כי אנחנו ל יודעים את המיקומים של
כעת נתבונן בעץ שבו מחליפים את
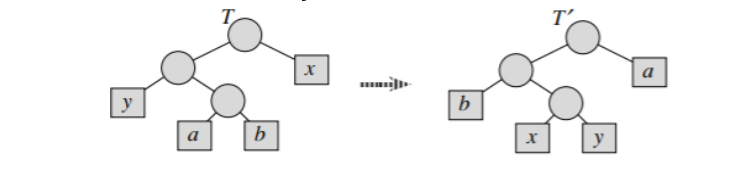
כלומר
ולכן
נשים לב שהגורמים היחידים שלא יצטצמטו הם ההחלפות שעשינו ולכן
נשים לב שכל הביטויים האלה גדולים מ 0 ולכן קיבלנו שההפרשת בין העלויות של העצים גדול מ 0 כלומר העלות של
כלומר גם
תת המבנה האופטימלי
כעת נוכל להוכיח את התכונה השנייה של אלגוריתם חמדן. בניגוד לחיפוש בינארי, באלגוריתם הזה אנחנו צריכים לזכור את כל הבחירות החמדניות המקומיות שעשינו כדי להגיע לתוצאה כיוון שאלו בונות את העץ. אנחנו נרצה לאפיין ולהוכיח שהמבנה של האלגוריתם הוא אכן תת מבנה אופטימלי בצורה שתתאים לבחירה של האלגוריתם ובפרט להראות שאם הריקורסיה מחזירה פתרון אופטימלי אז ״מיזוג״ הפתרון עם הבחירה החמדנית נותן פתרון אופטימלי למופע מקומי.
יהי
הוכחה :
נשים לב שכאן המטרה היא שונה בניגוד להוכחה של התכונה הראשונה, אנחנו רוצים להראות כאן באופן כמעט אינדוקטיבי שהרחבת המבנה שלנו על ידי הבחירה החמדנית באופן ריקורסיבי תוביל לפתרון אופטימלי. הטענה הראשונה שהוכחנו תעזור לנו בכך כיוון שאנחנו יודעים בוודאות שקיים עץ אופטימלי שמקיים את תכונת הבחירה החמדנית כלומר נוכל להניח שתת המבנה האופטימלי שלנו הוא אכן כזה.
נשים לב ש
כלומר קיבלנו
כעת, ניקח
ניקח
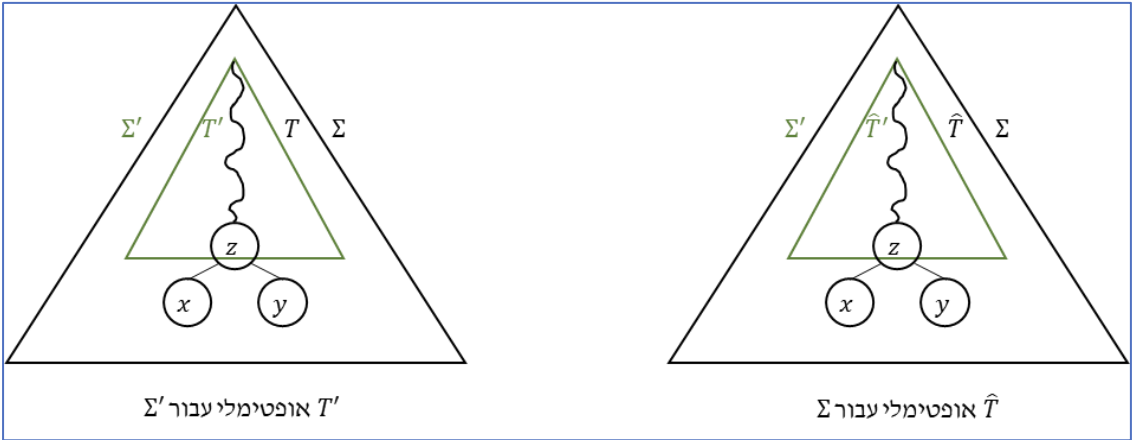
מההגדרה יתקיים ש
סך הכל מכל העצים שבנינו יתקיים
אבל
זה נכון בגלל ש