Parallel Sort
אנחנו מכירים אלגוריתמי מיון סדרתיים וגם שחסם המיון שלהם כאשר היחס היחיד שמכירים הוא יחס הסדר הוא
למרות זאת חשוב לציין כי ההנחה שיש לנו מעבד עבור כל ערך אינה מציאותית. לרוב, מעבד אחד יקבל אוסף של ערכים לעבוד עליהם.
כדי להבין איך נגשים לבעיית המיון המקבילי ננסה לחשוב איך אפשר למצוא את ה
כל פעולת השוואה היא פעולה בזמן קבוע
בעצם הרעיון הוא חשיבה מקבילית מדובר פה גם בחלוקת משאבים (תהליכונים) בצורה נכונה כדי שהאלגוריתם באמת יעבוד בצורה יעילה יותר. בשלב הראשון נלקח אלגוריתם סדרתי יעיל ונבין איך ניתן (אם ניתן) לחלק את המשאבים כדי לקבל אלגוריתם מקבילי יעיל יותר. גם נרצה להבין מהו החסם האופטימלי שנקבל כדי לדעת האם שווה בכלל להקצות משאבים ומאמץ להמרה של האלגוריתם לצורה מקבילית.
Bubble Sort
במיון בועות, המספר הגדול ביותר מועבר תחילה לסוף הרשימה על ידי סדרה של פעולות השוואה והחלפה. ההליך חוזר על עצמו, ועוצר ממש לפני המספר הגדול ביותר שהוצב קודם לכן, כדי לקבל את המספר הבא בגודלו. בדרך זו, המספרים הגדולים יותר נעים (כמו בועה) לקראת סוף הרשימה. זמן הריצה הוא

הקוד הסדרתי נראה כך:

האם ניתן למקבל את האלגוריתם?
מיון בועות הוא אלגוריתם סדרתי בלבד. כל שלב בלולאה הפנימית מתרחש לפני הבא, וכל הלולאה הפנימית הושלמה לפני האיטרציה הבאה של הלולאה החיצונית. עם זאת, רק בגלל שהקוד הסדרתי משתמש בהצהרות התלויות בהצהרות קודמות לא אומר שלא ניתן לנסח אותו מחדש כאלגוריתם מקביל.
פעולת הבעבוע של האיטרציה הבאה של הלולאה הפנימית יכולה להתחיל לפני שהאיטרציה הקודמת הסתיימה, כל עוד היא לא תעקוף את פעולת הבעבוע הקודמת.
פתרון 1
הפתרון הראשון שנציע כדי לממש את bubble sort באופן מקבילי הוא קונספט שמקובל בתחומים שונים של מדעי המחשב שהמטרה שלו הוא למנוע המתנה מיותרת כדי להתחיל איזשהו תהליך. הקונספט הזה נקרא Pipeline והוא יבוא לידי ביטוי באלגוריתם הזה בכך שלא נצטרך לחכות לאיטרציה פנימית שתסתיים כדי להתחיל כבר את האיטרציה הבאה.
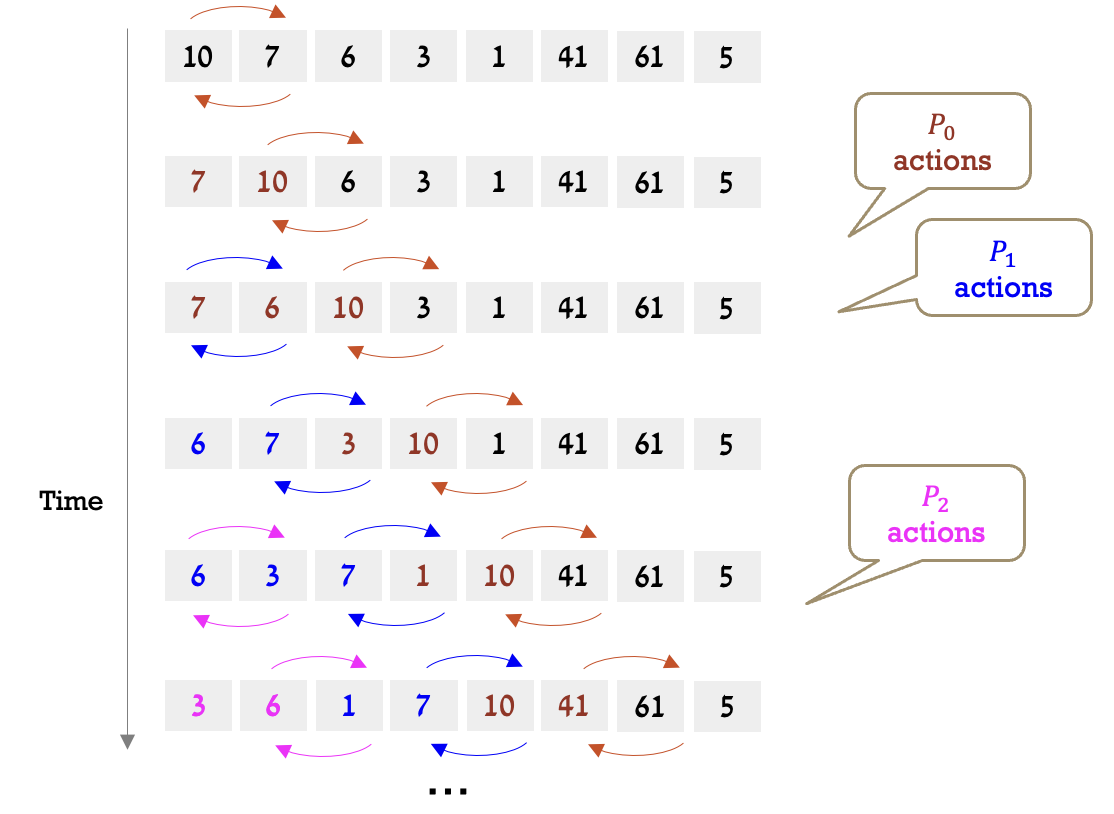
מבחינת זמן הריצה: כשThread הראשון מגיע לסוף המערך נכנס הThread ה
כמובן שצריך להתחשב בבניית האלגוריתם הזה בהקצאת משאבים לסנכרון, למשל אם נרצה ש
Odd-Even Sort
וריאציה נוספת של מיון בועות הנקראת מיון אי זוגי-זוגי (טרנספוזיציה), הפועלת בשני שלבים מתחלפים, שלב זוגי ושלב אי זוגי. בשלב הזוגי, תהליכים זוגיים מחליפים מספרים עם שכניהם משמאל. באופן דומה, בשלב האי-זוגי, תהליכים אי-זוגיים מחליפים מספרים עם שכניהם הימניים.
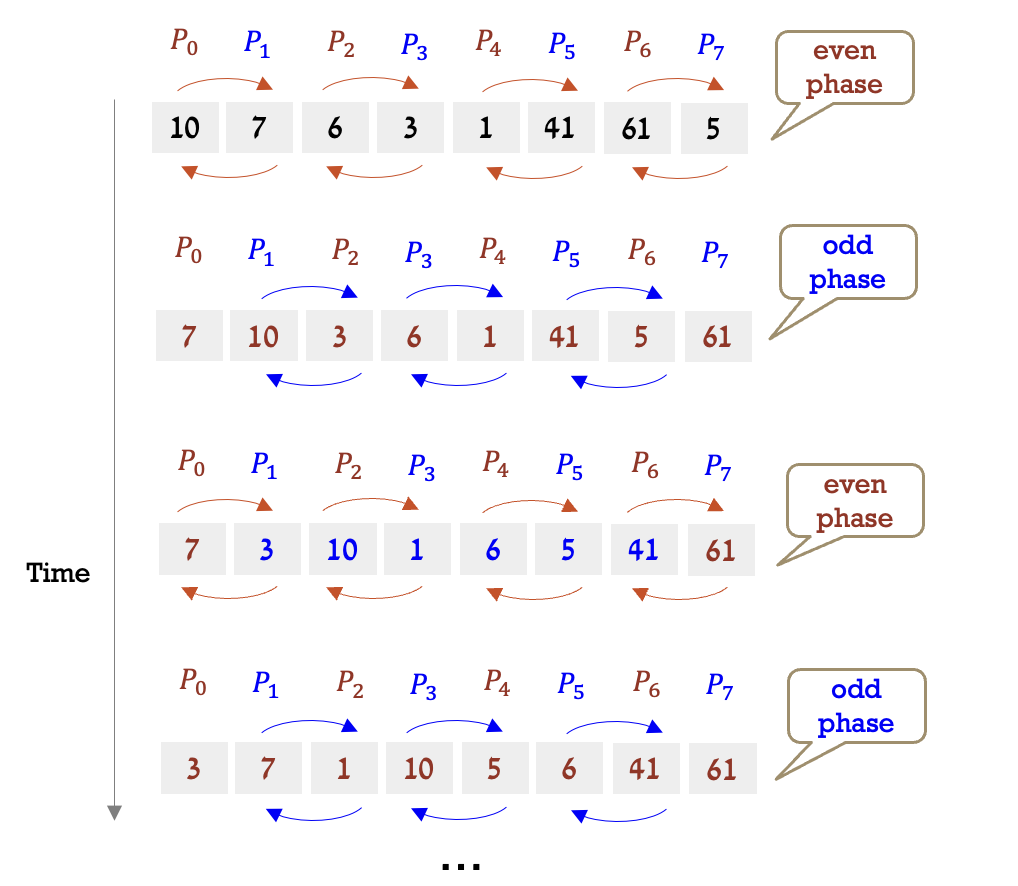
אז ניתן לראות כאן שבשלב ה
דוגמת הרצה נוספת:
האלגוריתם ב C יראה מהצורה:
rank = process_id();
A = initial_value(rank);
for (i = 0; i < N; i++) {
if (i % 2 == 0) { // even phase
if (rank % 2 == 0) { // even process
recv(&B, rank + 1); send(A, rank + 1);
A = min(A,B);
}
else { // odd process
send(A, i - 1); recv(&B, i - 1);
A = max(A,B);
}
}
else if (i > 0 && i < N - 1) { // odd phase
if (i % 2 == 0) { // even process
recv(&B, rank - 1); send(A, rank - 1);
A = max(A,B);
} else { // odd process
send(A, i + 1); recv(&B, i + 1);
A = min(A,B);
}
}
set_final_value(A, rank);
זמן הריצה:
מיון הבועות המקבילי יבצע n איטרציות של הלולאה הראשית, ולכל איטרציה יתבצעו במקביל השוואות
מדדים
נשאלת השאלה כיצד אפשר למדוד את יעילות הביצועים. ניתן להציע כמה אופציות לשאלה הזאת (נדגים מדדים על האלגוריתם הנ״ל של מיון בועות מקבילי)
Scalability
כיצד משתפר הspeedup של האלגוריתם ככל שמוסיפים מעבדים :
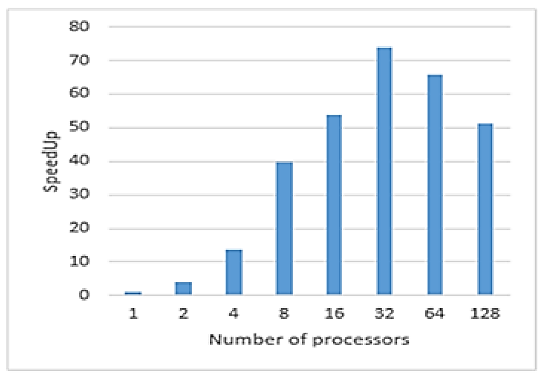
ניתן לראות שהחל ממספר מסויים של מעבדים היעילות יורדת כי הoverhead של לייצר אותם כבר לא משתלם.
Parallel Cost
העלות של זמן הריצה המקבילי במספר המעבדים
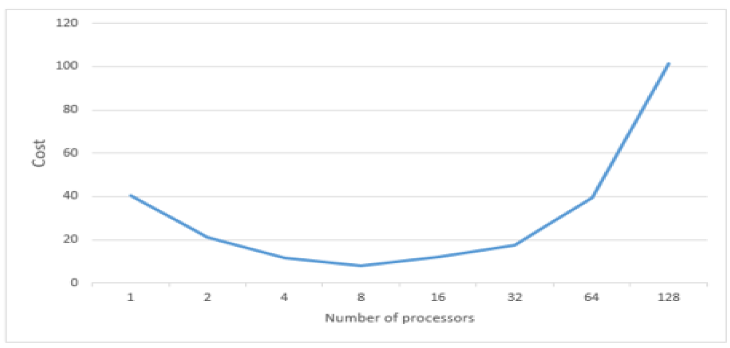
נקודת שפל בשמונה מעבדים שקיבלנו זה בגלל שיש קפיצות התייעלות משמעותיות עד שמגיעים להשתמש ב- 8 מעבדים, ומשם יש תועלת קטנה יותר משמעותית לתוספת מעבדים.
Parallel Efficiency
היחס בין הspeedup למספר המעבדים
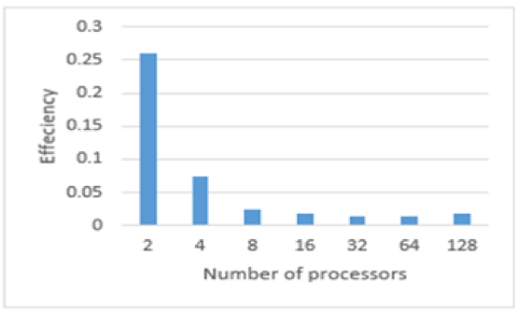
ניתן לראות שהיעילות המקבילית יורדת ככל שמוסיפים עוד מעבדים המשמעות היא שהשיפור ב speedup ככל שמוסיפים מעבדים לא באמת מוסיף הרבה.
runtime
זמן הריצה
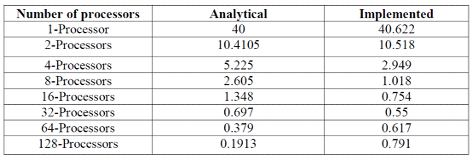
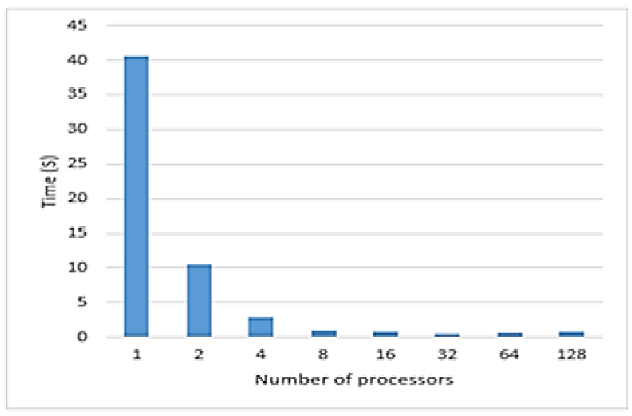
החל מ- 64 מעבדים יש הרעה. למה ? זה יכול לנבוע מחלוקה עדינה מדי (כלומר, לחלקים קטנים מדי) של המערך שלנו בין המעבדים.
כדי להגדיר את המונחים עבור חלוקה עדינה של מעבדים או חלוקה גסה של מעבדים נגדיר שני מושגים:
Fine-grain parallelism: תוכנית מפוצלת להרבה משימות קטנות. כל משימה מוקצית למעבד
א) Granularity נמוך.
ב) התקורה גבוהה (תקשורת, סנכרון, ניהול תהליכים, גישה לזיכרון לעומת חישובים)
Coarse-grain parallelism: תוכנית מפוצלת למספר משימות גדולות
כמות גדולה של חישוב מתרחשת במעבדים ללא צורך בתקשורת עם מעבדים אחרים
א) Granularity גבוה
ב) תקורה נמוכה
Granularity: זה היחס בין זמן החישוב לבין זמן תקשורת של מעבדים אחד עם השני
עבור האלגוריתם של מיון בועות מקבילי רואים שכאשר משתמשים בשני מעבדים, אז ה- overhead עבור תקשורת בין המעבדים וסנכרון בין המעבדים הינו נמוך, ורוב זמן ריצה הוא של חישובים, שזה מצב טוב
Merge Sort
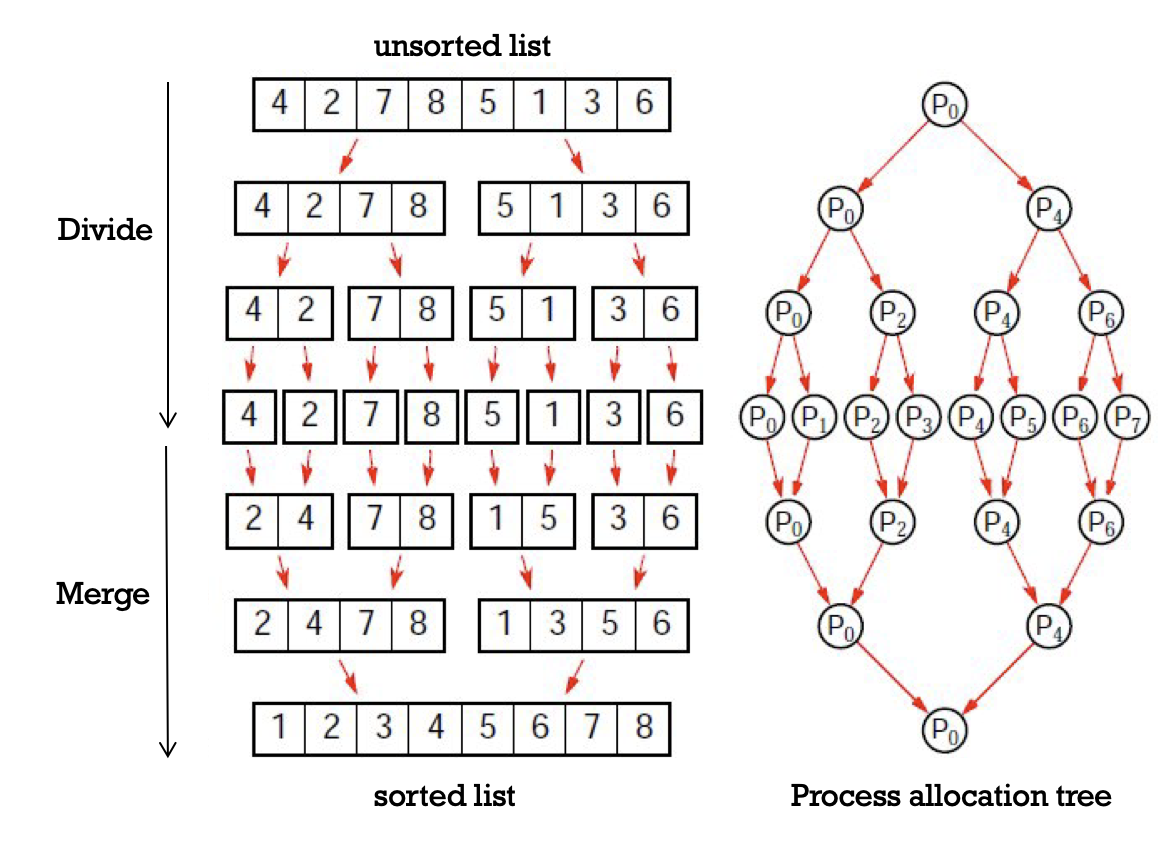
אלגוריתם שהוא אינו in-place ומבצע חלוקה ריקורסיבית של המערך עד שמגיעים לאיברים יחידים לאחר מכן מחברים את המערכים ומחברים בינהם בחזרה כאשר הפלט הוא מערך ממויין. אומנם האלגוריתם לא יעיל מבחינת זכרון אבל הוא מבטיח זמן ריצה של
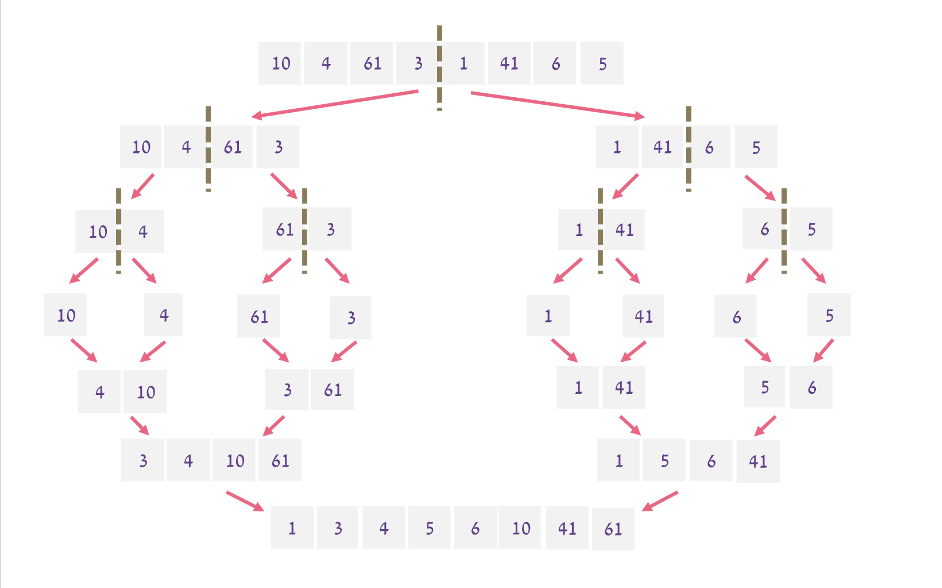
בתור חשיבה ראשונית היינו יכולים לעשות שכל ההשוואות והפיצולים יהיו בצורה מקבילית והחלק של הmerge יהיה בצורה סדרתית. במצב כזה אבל נקבל זמן ריצה של
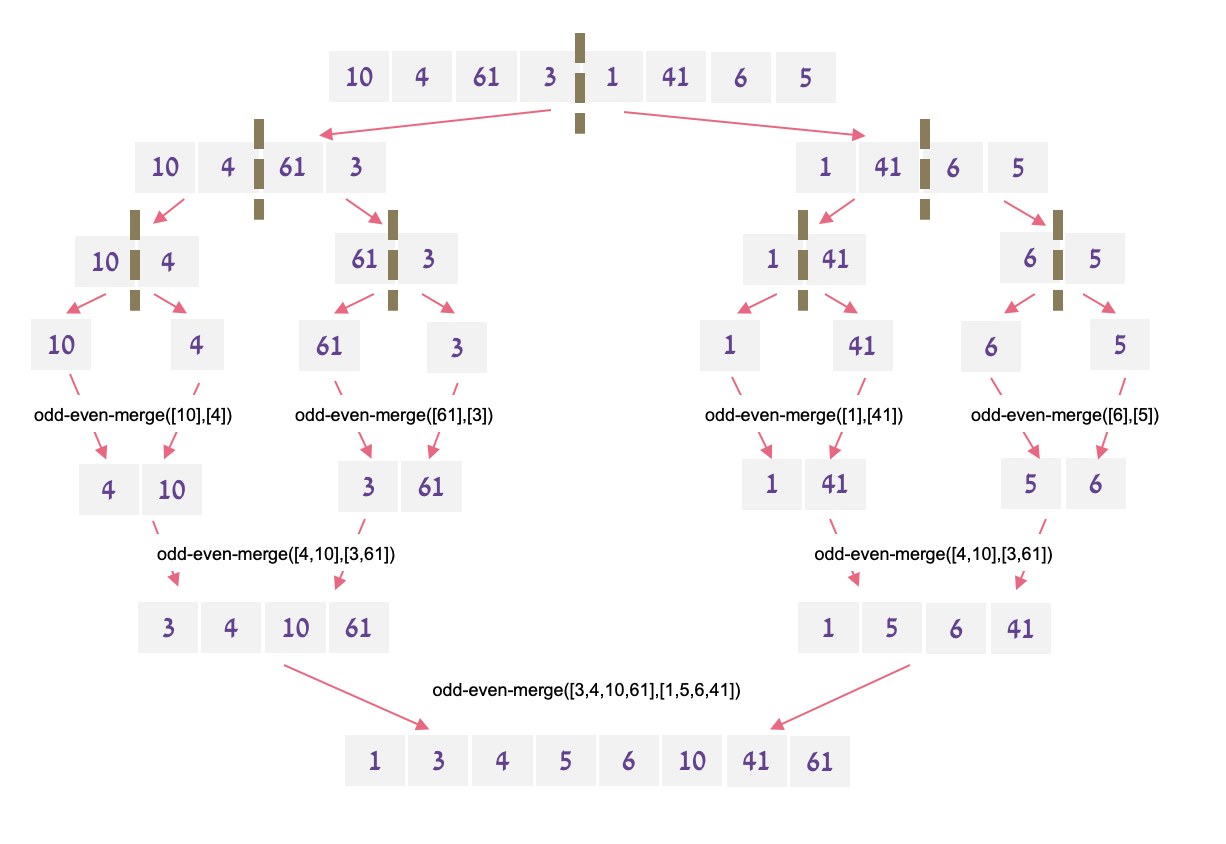
Odd Even Merge
נסתכל על הדוגמה הבאה:

כל תהליך מקבל מערך עם האינדקסים הזוגיים של המערך או האינדקסים האי זוגיים במערך. לבסוף מתקבל מערך ״semi-sorted" כלומר מערך ממוזג שהאינדקסים הזוגיים ממויינים בפני עצמם וגם האינדקסים האי זוגיים ממוינים בפני עצמם. בקוד סדרתי היינו רצים על כל זוגות האיברים ומבצעים החלפות לפי הצורך. בקוד מקבילי נעשה זאת בזמן קבוע.
לבסוף בשלב המיזוג כל תהליך מקבל זוג איברים סמוכים, מבצע את הנוסחה שרשומה בפסודו קוד למטה כדי לדעת האם יש להחליף בין המיקומים שלהם. סך הכל זמן הריצה הוא
הסיבה שזה

Odd Even Merge Sort
כעת נסביר איך לממש את אלגוריתם ה merge sort בצורה מקבילית. אנחנו נשתמש בצורה רקרוסיבית ב Odd-Even Merge. זמן הריצה של האלגוריתם הזה יהיה
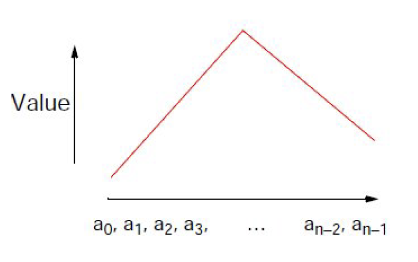
Bitonic Merge Sort
הבסיס של אלגוריתם ביטוני הוא bitonic sequence. רצף ייקרא bitonic אם הוא מכיל שני רצפים, אחד עולה ואחד יורד כך ש :
או
תכונה מיוחדת של רצף ביטוני הוא שאם נבצע פעולות השוואה והחלפה של האלמנטים
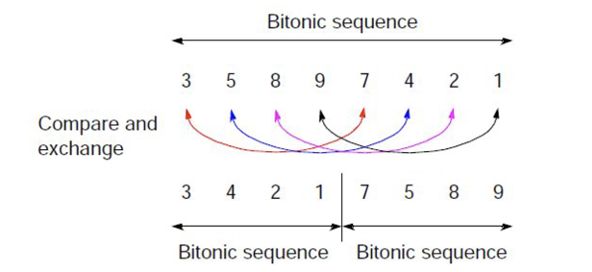
המשמעות היא שאנחנו יכולים לבצע את פעולות ההחלפה וההשוואה באופן רקרוסיבי עד שמקבלים מערך ממוין
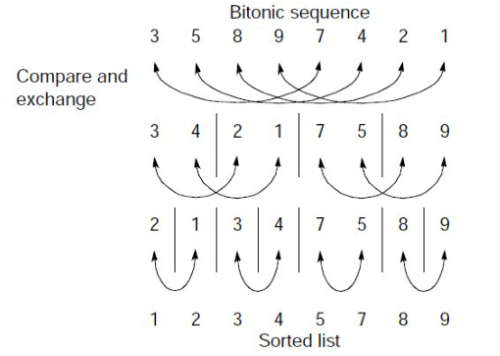
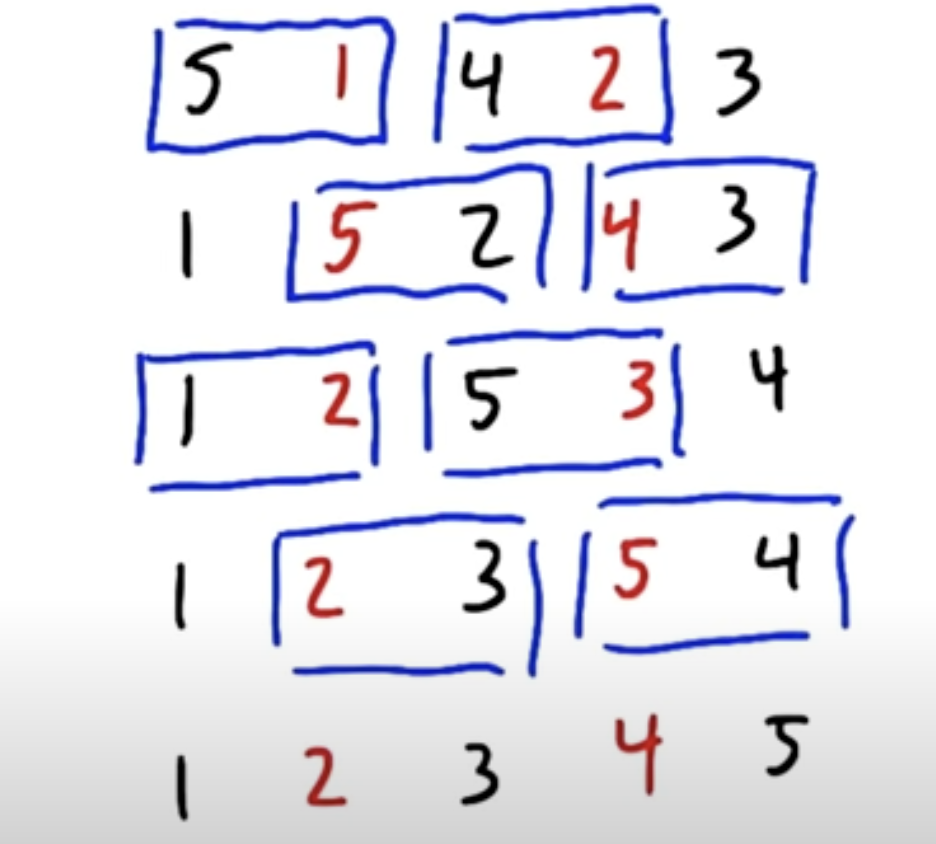
כעת נשאלת השאלה, כיצד אפשר להמיר כל מערך למערך מהצורה של bitonic sequence. כדי לעשות זאת נוכל לחלק את המערך לזוגות כך שזוגות באינדקס זוגי נסדר אותם להיות רצף ביטוני וזוגות באינדקס אי זוגי נסדר אותם להיות כרצף ביטוני הפוך. באופן רקרוסיבי נמזג את הזוגות האלה כך שיווצרו לנו רצפים ביטונים גדולים פי 2 עד שנקבל שני רצפים ביטונים כל אחד מהם חצי מגודל המערך ונפעיל bitonic merge כדי לקבל מערך ממויין.
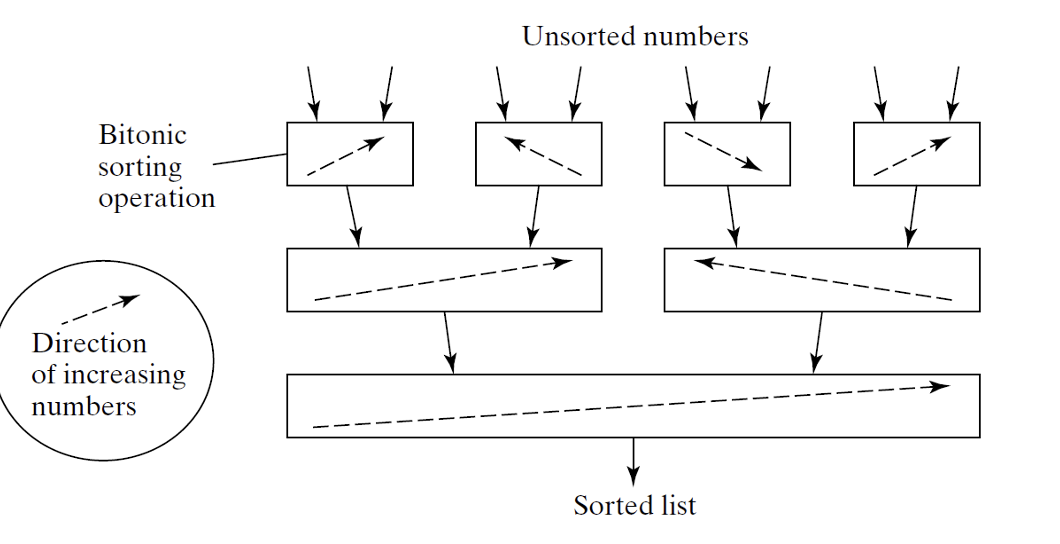
נדגים ריצה על המערך
א. נמיר לזוגות איברים כפי שאמרנו
ב. כעת נמזג בין הזוגות עם bitonic merge כדי לקבל 2 זוגות בגודל 4 של סדרות ביטוניות -
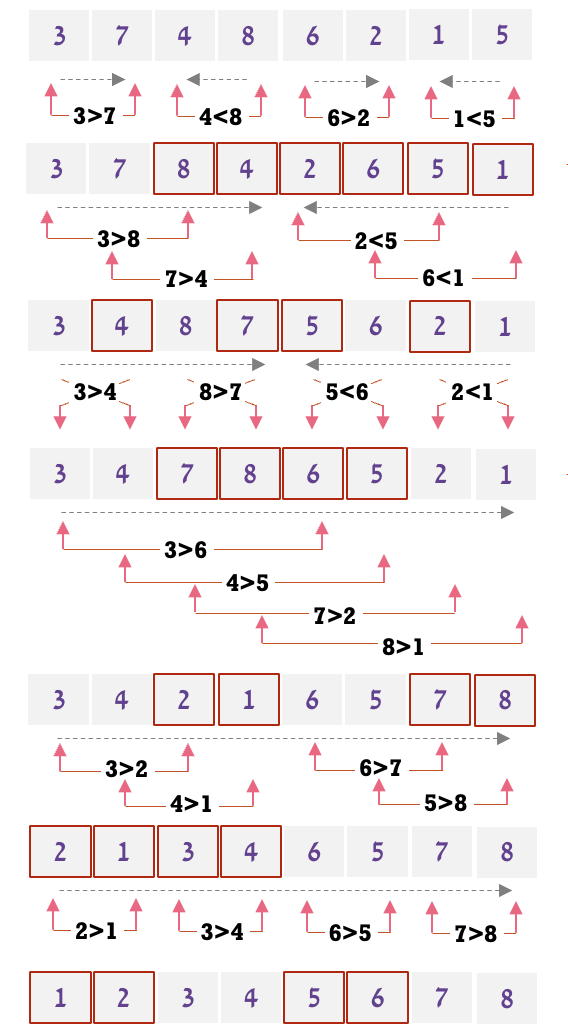
זמן הריצה הוא:
במבחן המציאות
אם נריץ bitonic sort מקבילי, כאשר נייצר שני threads אחד לכל פעולה ריקורסיבית של bitonic merge אנחנו נקבל overhead גבוה מאוד של Threads.
האלגוריתם הסדרתי:
// ----------------- Bitonic Sort -----------------
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void compare_and_exchange(int *arr, int i, int j, int dir) {
if (dir == (arr[i] > arr[j])) {
swap(&arr[i], &arr[j]);
}
}
/*
* Given a bitonic sequence,
* x(1) < x(2) < ... < x(n/2) > x(n/2+1) > ... > x(n)
* Sort the sequence in the given order.
* Note: implemnetation assumes that the sequence is of length 2^k
*/
void bitonic_merge(int *arr, int start, int len, int dir) {
if (len > 1) {
int k = len / 2;
for (int i = start; i < start + k; i++) {
compare_and_exchange(arr, i, i + k, dir);
}
bitonic_merge(arr, start, k, dir);
bitonic_merge(arr, start + k, k, dir);
}
}
void bitonic_sort_rec(int *arr, int start, int len, int dir) {
if (len > 1) {
int k = len / 2;
bitonic_sort_rec(arr, start, k, 1);
bitonic_sort_rec(arr, start + k, k, 0);
bitonic_merge(arr, start, len, dir);
}
}
void bitonic_sort(int *arr, int len) {
bitonic_sort_rec(arr, 0, len, 1);
}
האלגוריתם המקבילי:
// ----------------- Bitonic Sort -----------------
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void compare_and_exchange(int *arr, int i, int j, int dir) {
if (dir == (arr[i] > arr[j])) {
swap(&arr[i], &arr[j]);
}
}
typedef struct merge_args {
int *arr;
int start;
int len;
int dir;
} merge_args;
/*
* Given a bitonic sequence,
* x(1) < x(2) < ... < x(n/2) > x(n/2+1) > ... > x(n)
* Sort the sequence in the given order.
* Note: implemnetation assumes that the sequence is of length 2^k
*/
void *bitonic_merge(void *arg) {
merge_args *args = (merge_args *) arg;
int start = args->start;
int len = args->len;
int dir = args->dir;
if (len > 1) {
int k = len / 2;
for (int i = start; i < start + k; i++) {
compare_and_exchange(args->arr, i, i + k, dir);
}
pthread_t tid1, tid2;
merge_args args1 = {args->arr, start, k, dir};
merge_args args2 = {args->arr, start + k, k, dir};
pthread_create(&tid1, NULL, bitonic_merge, &args1);
pthread_create(&tid2, NULL, bitonic_merge, &args2);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
}
}
typedef struct sort_args {
int *arr;
int start;
int len;
int dir;
} sort_args;
void *bitonic_sort_rec(void *arg) {
sort_args *args = (sort_args *) arg;
int start = args->start;
int len = args->len;
int dir = args->dir;
if (len > 1) {
int k = len / 2;
pthread_t tid1, tid2;
sort_args args1 = {args->arr, start, k, 1};
sort_args args2 = {args->arr, start + k, k, 0};
pthread_create(&tid1, NULL, bitonic_sort_rec, &args1);
pthread_create(&tid2, NULL, bitonic_sort_rec, &args2);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
merge_args merge_args = {args->arr, start, len, dir};
bitonic_merge(&merge_args);
}
}
void bitonic_sort(int *arr, int len) {
sort_args args = {arr, 0, len, 1};
bitonic_sort_rec(&args);
}
יש לנו פה עץ אקספוננציאלי של תהליכים, ברגע שהילדים מסיימים לבצע bitonic_merge האבא מפעיל בעצמו bitonic_merge. בעולם התיאורטי זה יכל לעבוד אבל במבחן המציאות כיוון שאין באמת מחשב שמחזיק כל כך הרבה מעבדים שמאפשרים עבודה במקביל יש פה המון overhead והמון context switch מה שיגרום לזמן ריצה גרוע ביותר בהשוואה לאלגוריתם סדרתי.
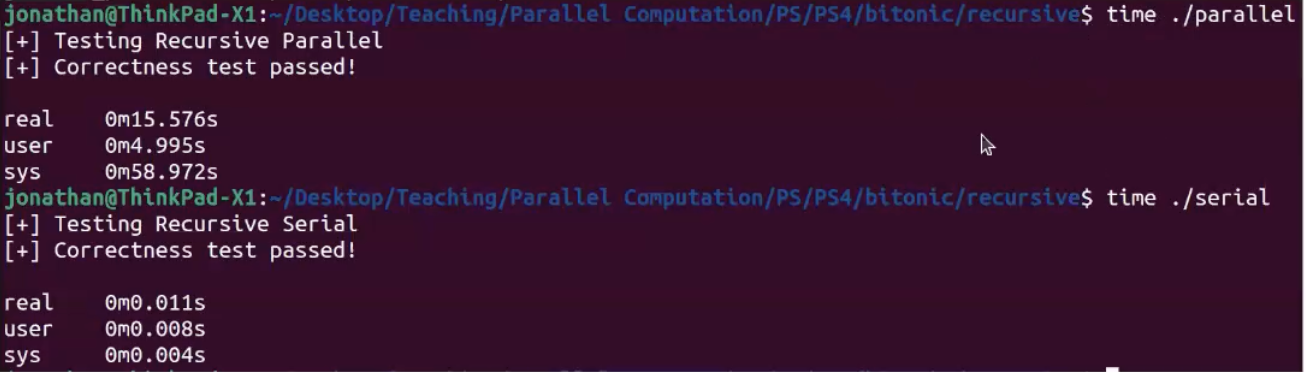
כיצד מטפלים בבעיה?
א. נשאיר את החלק של המיזוג סדרתי.
ב. נשתמש ב Thread Pool או לפחות נגביל את כמות הThreads.
ג. נשתמש ב Parallel Threshold - נשתמש ב Threads בשביל bitonic_merge רק עבור מערכים מעל גודל מסויים.
כדי לייעל את האלגוריתם, ראשית, נשתמש בשיטת Bottom up במקום ב Top down. כלומר לא נפרק את המערך הגדול באופן ריקרוסיבי ונמזג אלא מהתחלה נעבוד על החלקים הקטנים ביותר של המערך ונעלה למעלה.
השיטה הזאת תאפשר לנו לעבוד בקוד מבוסס לולאות ולא רקורסיה.
הקוד הסדרתי:
// ----------------- Bitonic Sort -----------------
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void compare_and_exchange(int *arr, int i, int j, int dir) {
if (dir == (arr[i] > arr[j])) {
swap(&arr[i], &arr[j]);
}
}
void bitonic_merge(int *arr, int start, int len, int dir) {
if (len > 1) {
int k = len / 2;
for (int i = start; i < start + k; i++) {
compare_and_exchange(arr, i, i + k, dir);
}
bitonic_merge(arr, start, k, dir);
bitonic_merge(arr, start + k, k, dir);
}
}
void bitonic_sort(int *arr, int len) {
for (int i = 2; i <= len; i *= 2) {
int dir = 1;
for (int j = 0; j < len; j += i) {
bitonic_merge(arr, j, i, (dir++) % 2);
}
}
}
במימוש זה הדבר היחיד שמשתנה זה ה bitonic_sort (מניחים שגודל המערך הוא חזקה של
הקוד המקבילי:
#define NUM_THREADS 4
#define PARALLEL_THRESHOLD 8192
// ----------------- Bitonic Sort -----------------
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
void compare_and_exchange(int *arr, int i, int j, int dir) {
if (dir == (arr[i] > arr[j])) {
swap(&arr[i], &arr[j]);
}
}
typedef struct merge_args {
int *arr;
int start;
int len;
int dir;
} merge_args;
/*
* Given a bitonic sequence,
* x(1) < x(2) < ... < x(n/2) > x(n/2+1) > ... > x(n)
* Sort the sequence in the given order.
* Note: implemnetation assumes that the sequence is of length 2^k
*/
void *bitonic_merge(void *arg) {
merge_args *args = (merge_args *) arg;
int *arr = args->arr;
int start = args->start;
int len = args->len;
int dir = args->dir;
if (len > 1) {
int k = len / 2;
for (int i = start; i < start + k; i++) {
compare_and_exchange(arr, i, i + k, dir);
}
merge_args args1 = {arr, start, k, dir};
merge_args args2 = {arr, start + k, k, dir};
bitonic_merge(&args1);
bitonic_merge(&args2);
}
}
void bitonic_sort(int *arr, int len) {
pthread_t threads[NUM_THREADS];
merge_args args[NUM_THREADS];
for (int i = 2; i <= len; i *= 2) {
int dir = 1;
if (i >= PARALLEL_THRESHOLD) {
for (int j = 0; j < len; j += i * NUM_THREADS) {
for (int k = 0; k < NUM_THREADS && j + k * i < len; k++) {
args[k] = (merge_args) {arr, j + k * i, i, (dir++) % 2};
pthread_create(&threads[k], NULL, bitonic_merge, &args[k]);
}
for (int k = 0; k < NUM_THREADS && j + k * i < len; k++) {
pthread_join(threads[k], NULL);
}
}
} else {
for (int j = 0; j < len; j += i) {
merge_args args = {arr, j, i, (dir++) % 2};
bitonic_merge(&args);
}
}
}
}
ניתן לראות שבאלגוריתם זה המיקבול קורה רק כאשר גודל המערך גדול מ PARALLEL_THRESHOLD. כמו כן הגבלנו גם את מספר הthreads שניתן להרים בכל רגע נתון. צריך להזהר ממזל של deadlock כשעובדים עם כמות threads חופשית בלי thread pool שכן אין פה מנגנון ניהול מסודר ואם thread אחד מסיים צריך לחכות לו בלולאה נפרדת, יכול להיות מצב שיגמרו לנו הthreads שהקצנו אבל צריך עוד כדי להמשיך באלגוריתם ואז נתקע.
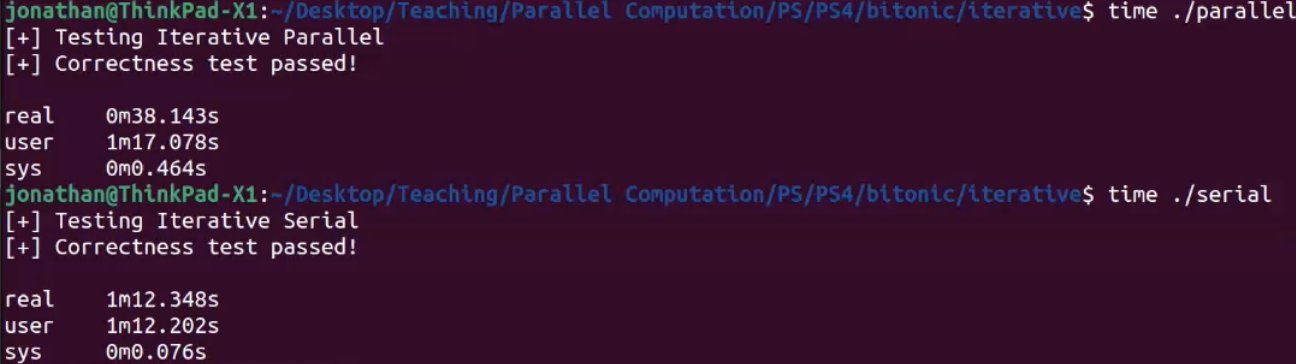
נשים לב שהזמן ריצה יותר מהיר הפעם אבל ה user time די זהה. הסיבה לכך היא ש user time מודד את זמן המעבד שהתוכנית רצה ב user space כלומר הוא סוכם את כל העבודה של המעבדים השונים לזמן אחד. ה real time הוא מה שקובע וזה זמן הריצה בפועל של התוכנית.
QuickSort
אלגוריתם הסתברותי שבונה על בחירת pivot במיקום טוב ( שהאיבר בו מקיים שהאינדקס המתאים שלו הוא בסביבת אמצע המערך) וממיין את כל האיברים סביבו באופן רקורסיבי. זמן הריצה שלו בממוצע הוא

הרעיון המקבילי כאן הוא פשוט אם כי נקבל זמן ריצה גרוע מהאלגוריתמים הקודמים של
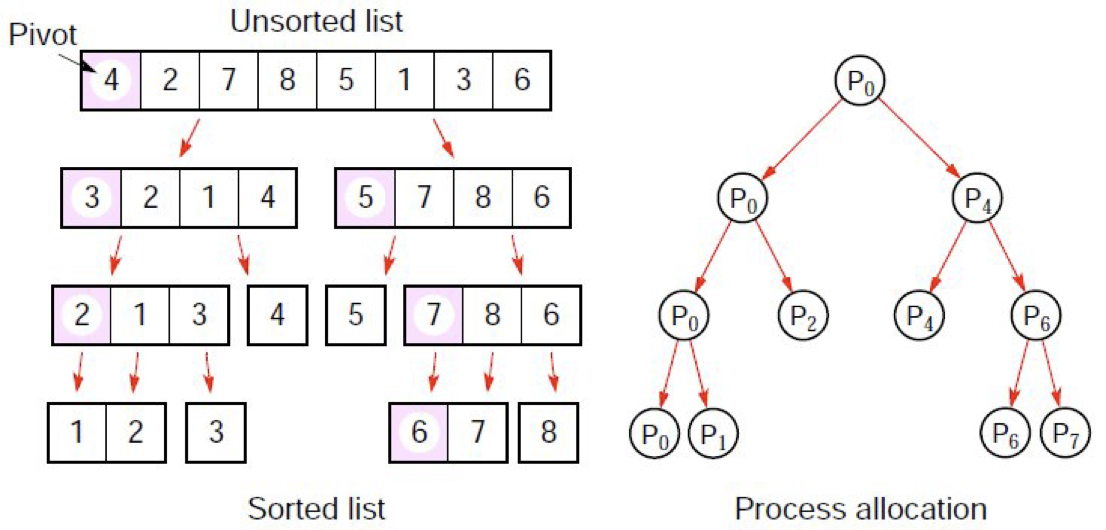
בהנחה שכל חלוקה נעשית במקביל נקבל שמספר הצעדים הוא סדרה חשבונית
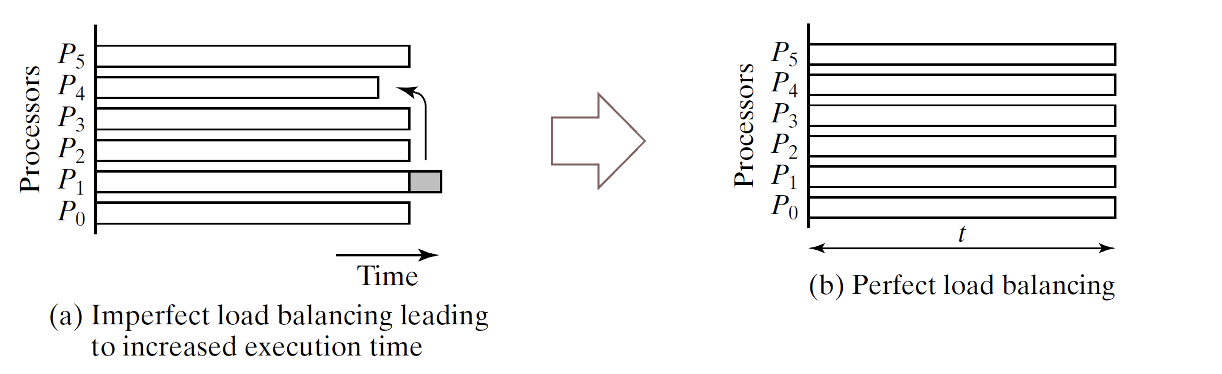
כבר בדוגמה הנ״ל ניתן לראות בעיה נוספת של מקביליות ב QuickSort והיא ה load balance- יכול להווצר מצב שמעבד אחד מקבל מעט עבודה לעומת מעבד אחר שמקבל הרבה יותר עבודה.
באופן אידיאלי נרצה של המעבדים ירוצו באופן שווה כלומר יקבלו משימות שקולות מבחינת מורכבות. הקונספט הזה נקרא load balancing
אפשר לחלק את הload balancing לשני סוגים עיקריים
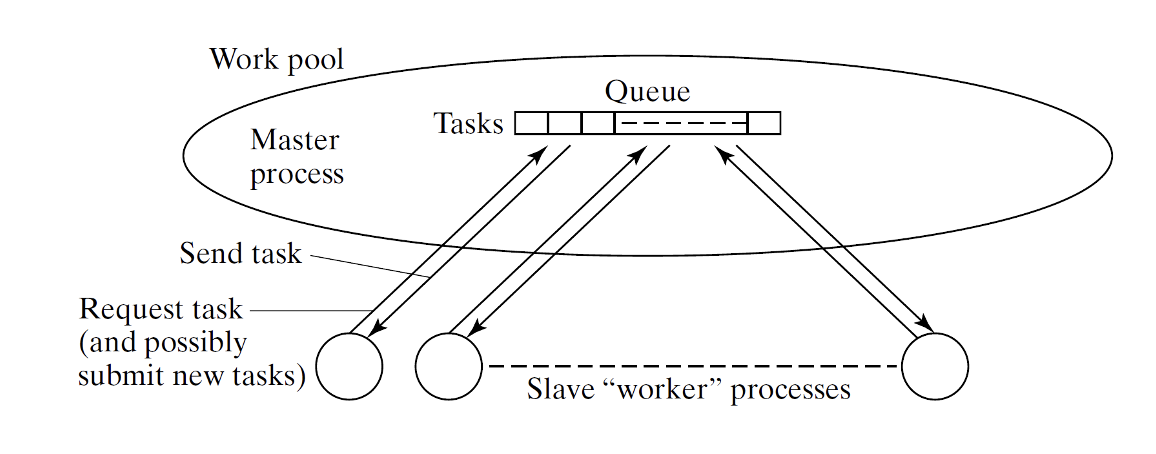
dynamic load balancing - המשימות מוקצות לתהליכים במהלך ריצת התוכנית.
centralized dynamic load balancing - תהליך המאסטר מחזיק אוסף של משימות לביצוע . המשימות מתקבלות ל תהליך בן וכשהוא מסיים אותה הוא מבקש משימה נוספת מתהליך המאסטר. זאת מכניקה מאוד מוכרת בתכנות מקבילי שנקראת work-pool.
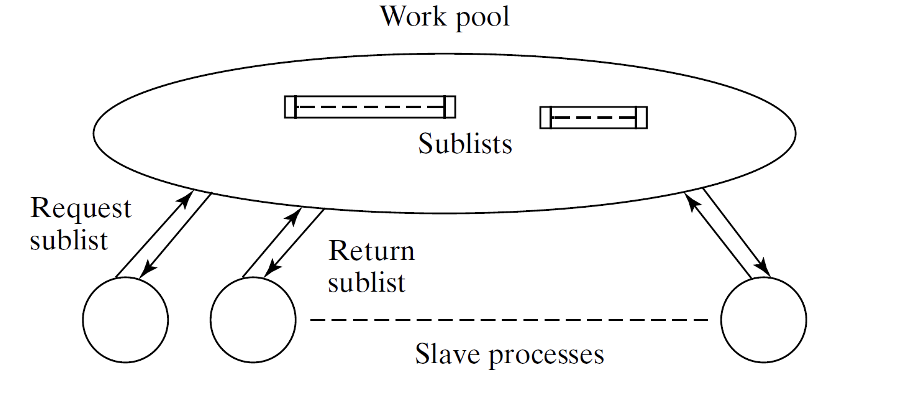
במקרה של Quicksort משימה יכולה להיות sublist כלשהו.
סיכום למיון מקבילי מבוסס השוואות
| algorithm | Sequential | Parallel |
|---|---|---|
| Bubble Sort | O(n) | |
| Mergesort | O(nlog(n)) | O(n) |
| Quicksort | O(nlog(n)) | O(n) |
| Odd-Even Mergesort | ||
| Bitonic Mergesort |
Count sort
מיון מניה הוא מיון שעובד תחת ההנחה שטווח המספרים הוא בין
המיון מחזיק מערך מונים כך שהאינדקס ה
סך הכל זמן הריצה הוא
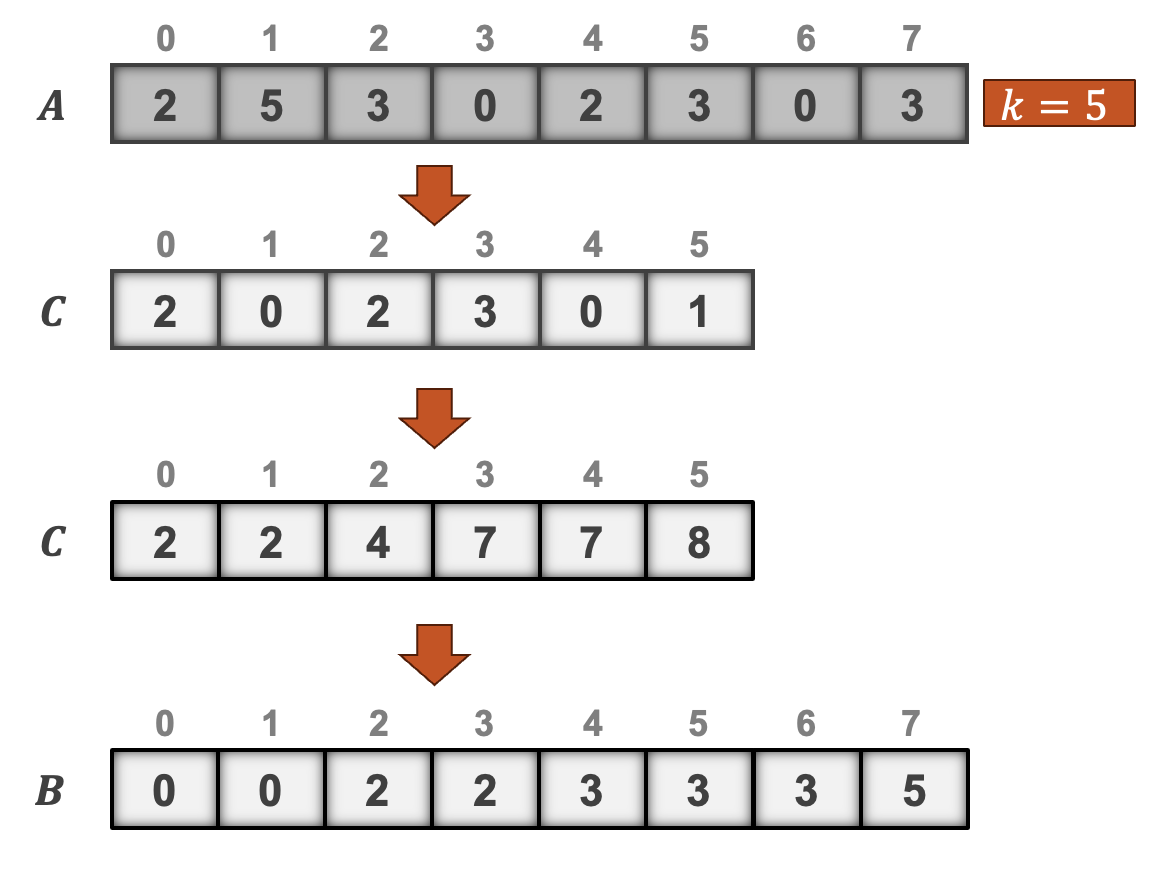
ניתן לבצע את שלב המנייה בצורה מקבילית אך יש בכך סיכון של חוסר יציבות באלגוריתם בגלל race condition. במקרה הטוב ביותר בקבוע
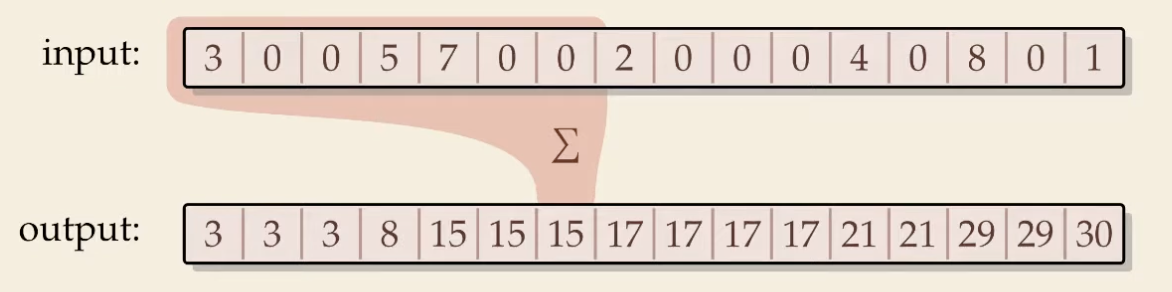
ניתן למקבל גם את שלב הצבירה בו מחושבים הסכומים החלקיים של כל האיברים הקודמים. זאת בעית ה Prefix Sum שהיא ניתנת למיקבול.
אם נרצה לעשות Prefix sum בצורה סדרתית הקוד הוא מאוד פשוט בסיבוכיות ליניארית :

בצורה מקבילית יהיה לנו

הרעיון הוא שככל שמתקרבים לאיברים האחרונים ככה אנחנו מבצעים יותר סכימות ולכן ככל שהלולאה החיצונית מתקדמת ככה התנאי הסכימה נעשת רק על האיברים הימניים יותר במערך. הקפיצה הזאת היא אקספוננציאלית, כלומר עבור
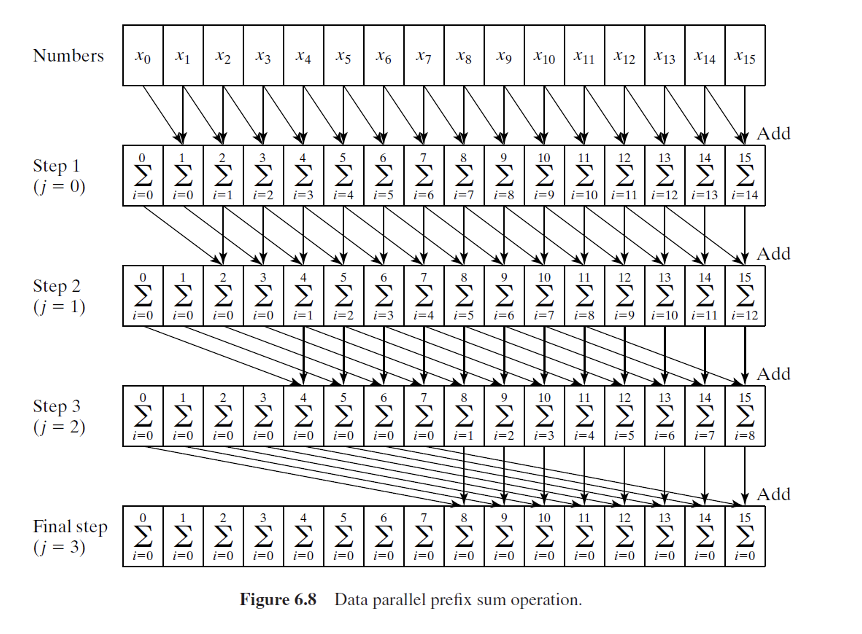
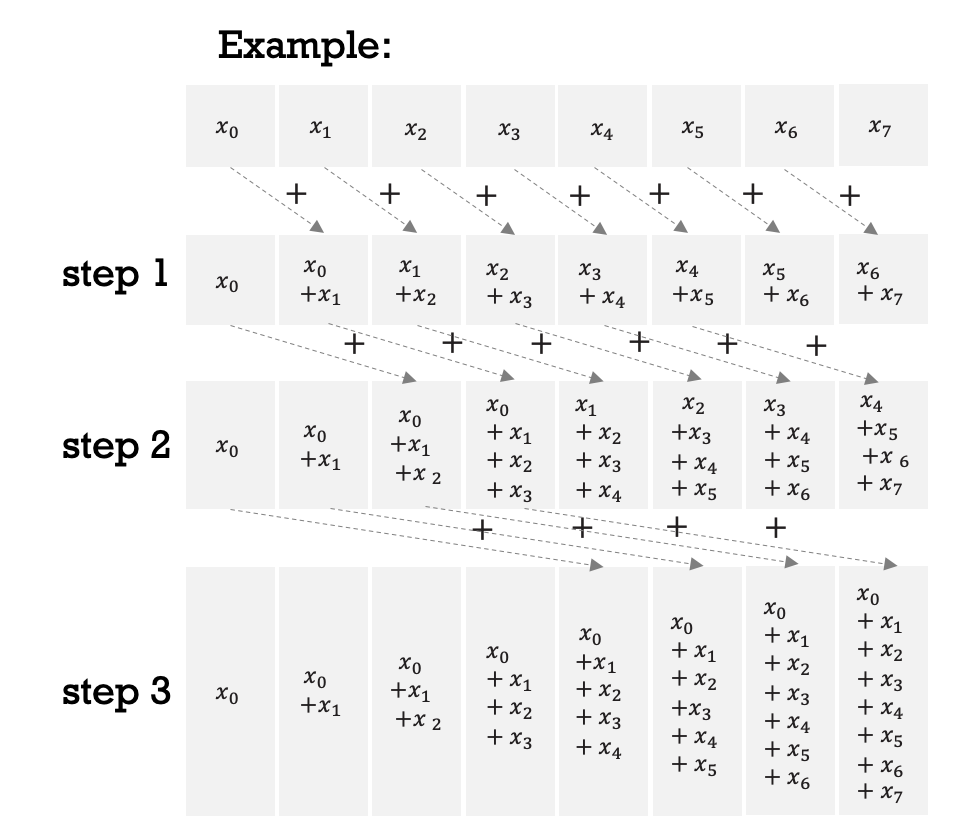
זמן הריצה של זה הוא
שלב בניית המערך ממויין גם כן ניתן לבצע במקביל על ידי
על ידי שימוש בגרסה מקבילית של Prefix Sum ניתן לקבל זמן ריצה של
Prefix sum
דיברנו ב count sort על האלגוריתם המקבילי של prefix sum על קצה המזלג. נרצה להסביר את הבעיה והפתרון שלה יותר לעומק.
קלט: מערך
פלט: כתיבה מחדש של A כך ש יבוצע חישוב על prefix לכל אינדקס i כלומר