Parallel Graphs Algorithms
גרף הוא מבנה נתונים מהצורה של
BFS
BFS הוא אלגוריתם סריקה של גרף שמוצא את ה Single-Source Shortest Paths (SSSP) מקודקוד מקור לכל הקודקודים האחרים בגרף. זמן הריצה שלו הוא
על פניו האלגוריתם המקבילי ה״טריוויאלי״ יהיה להוציא קודקודים מהתור כמספר הthreads (נזכיר שהאלגוריתם הסדרתי טוען שכנים של קודקוד לתור ואז שולף אותם מהתור להמשך סריקה).
האלגוריתם ייראה מהצורה

נשים לב שהאלגוריתם הזה דרוש טיפול בבעיית ה critical section וסנכרון על כל קודקוד כיוון ששני threads יכולים לסרוק את אותו שכן וצריך שאחד מהם יעצור כי צביעת קודקוד אמורה להיות פעולה אטומית. (במקרה של האלגוריתם שורות
. ש עם האלגוריתם הזה בעיה נוספת. האלגוריתם הנ״ל עלול לחשב מרחקים לא נכונים. יכול להיות מצב ש
הפתרון: לסיים טיפול בכל הקודקודים בשכבה הנוכחית לפני שעוברים לשכבה הבאה. את זה , ניתן להשיג על ידי כלי סנכרון שנקרא barrier.
בואו נרשום את האלגוריתם בצורה קצת אחרת שתואמת לפתרון הזה.

ניתן לראות שהמקביליות כאן באה לידי ביטוי רק בשכבה ה
זמן הריצה במצב הזה תלוי במבנה של הגרף שכן, גרף שהוא ״גרף נחש״ זמן הריצה של אלגוריתם כזה יהיה כמו זמן הריצה של אלגוריתם סדרתי אבל של גרף מהצורה של עץ בינארי מלא זמן הריצה יהיה
DFS
DFS הוא אלגוריתם לסריקת גרף לעומק ולא בשכבות. ההבדל המשמעותי בין האלגוריתמים הוא שבDFS לא סורקים את כל הגרף אם הוא לא קשיר. יש לו שימושים נרחבים למרות שכשלעצמו הוא לא נותן הרבה, אלגוריתמים רבים משתמשים במידע שהוא נותן כדי לבנות דברים נוספים למשל מיון טופיולוגי.
הפתרון המקבילי הוא להצמיד thread לכל
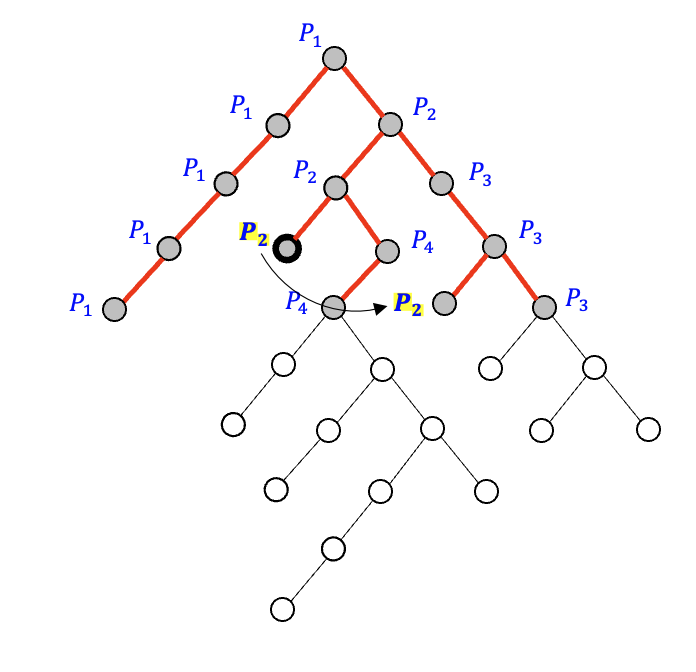
נשים לב שמעבד שסיים לטפל בענף שקיבל מועבר לטפל בקודקוד אחר שמתגלה בשלב זה.
כמו כן האלגוריתם המקבילי הזה לא צריך לצבוע בשחור את הקודקוד שכן אין צורך לחזור אחורה רקורסיבית כמו באלגוריתם הסדרתי כדי לבדוק מסלולים נוספים להמשיך איתם.
DFS כאמור משמש אותנו כדי להשיג
א) רכיבי קשירות
ב) זיהוי מעגלים בגרף
ג) מיון טופולוגי
נשאלת השאלה האם הגרסה המקבילית הנ״ל מאפשרת לנו לקבל את התוצאות האלו. וגם, מה ההבדל בטיפול הנ״ל בין גרפים מכוונים לגרפים לא מכוונים?
חיפוש מעגלים באמצעות DFS
ב DFS הסטנדרטי, מציאת מעגל בגרף דורשת מאיתנו לבדוק בפונקציה DFS_VISIT האם אחד הקודקודים שאנחנו סורקים כבר צבוע באפור. אם הוא צבוע באפור, הרי שיש מעגל בגרף.
האלגוריתם המקבילי באותו אופן גם ימצא מעגל בגרף שכן אם
אבל בגרף מכוון בעוד שבDFS הסדרתי אכן נמצא מעגל, בDFS המקבילי אנחנו עלולים לזהות מעגל שלא קיים למשל:
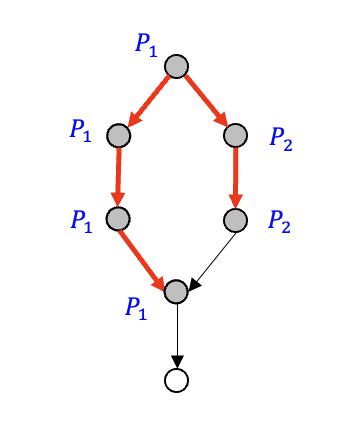
בגרף הנ״ל
Kahn algorithm
האלגוריתם של קאן מאפשר למצוא מעגל בגרף מכוון.
האלגוריתם כל פעם מוציא קודקודים שמקיימים ש
אם בסופו של דבר הגרף הוא ריק אזי אין מעגל בגרף. אחרת נתקענו על איזה קודקוד שהדרגת כניסה שלו היא לא

בגרסה המקבילית של האלגוריתם הזה, נוציא מהתור את כל הקודקודים האפשריים כך שלכל thread יהיה קודקוד ואת כל תהליך הסרת הקשתות ובדיקת השכנים נעשה בצורה מקבילית.

אינטואיטיבית האלגוריתם הזה אכן יעבוד כיוון שהתנאי שלו למציאת מעגל הוא דווקא זה שאם קיים מעגל בגרף בגלל העובדה שאין פה אלמנט של בדיקת data של קודקוד מסויים ששני threads נגעו בו, כמו ב DFS שבדקנו את הcolor של צבע מסויים ב״זמן״ לא מתאים. באלגוריתם של קאן, מידע שכבר סרקנו הוא בגדר ״לא קיים״ כי העפנו אותו מהגרף ומהיצוג שלו ולכן אין thread אחר שיבדוק את המידע הזה, כלומר שני threads לא יגעו באותו קודקוד באלגוריתם הזה. לכן זה עובד.
Maximal Independent Set
נרצה למצוא את הקבוצה המקסימלית של קודקודים בגרף לא מכוון כך שאין בינהם קשתות. הכוונה בקבוצה מקסימלית היא שבהינתן S קבוצה מקסימלית של קודקודים שהיא MIS מתקיים שלכל v שנוסיף ל S יתקיים ש S היא כבר לא MIS.
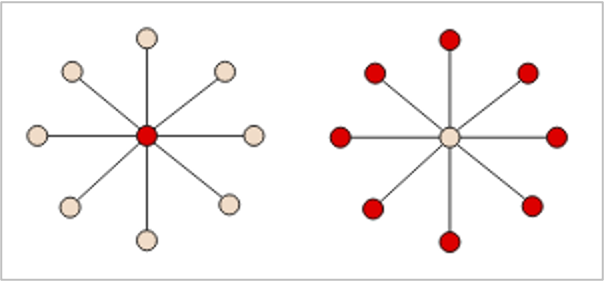
למשל כאן יש שני MIS בגדלים שונים אך זה לא משנה מבחינת ההגדרה.
האלגוריתם הוא greedy algorithms שעובד באופן הבא: נוסיף לקבוצה שנגדיר מראש כקבוצה ריקה, קודקודים עם הדרגה הנמוכה ביותר (אם יש כמה כאלה, בוחרים אחד באופן שרירותי). על כל קודקוד כזה, נוריד אותו ואת כל השכנים שלו ונמשיך ככה עד שקבוצת הקודקודים תהיה ריקה.

זמן הריצה הוא
Luby parallel MIS
הבעיה באלגוריתם הנ״ל הוא שבבסיסו הוא אינו ניתן למיקבול, שכן באלגוריתם הנ״ל הצעד הבא תלוי ממש בצעד הקודם. הסרה של קודקוד כלשהו גורמת לעדכון מחדש של כל הגרף ולכן אי אפשר להסתמך באופן מלא על מקביליות.
לכן, נשתמש באלגוריתם אחר לפתרון הבעיה הזאת: האלגוריתם נקרא Luby MIS :

האלגוריתם בעצם מקנה לכל קודקוד בגרף מספר אקראי ומוסיפים לקבוצה I את כל הקודקודים שמקיימים שהערך שהם קיבלו הוא הנמוך ביותר מבינו לבין הערכים שקיבלו שכניו.
לאחר מכן נוריד את כל הקודקודים שהוספנו ואת השכנים שלהם מ C ונמשיך בלולאה עם הקצאת מספרים חדשה.
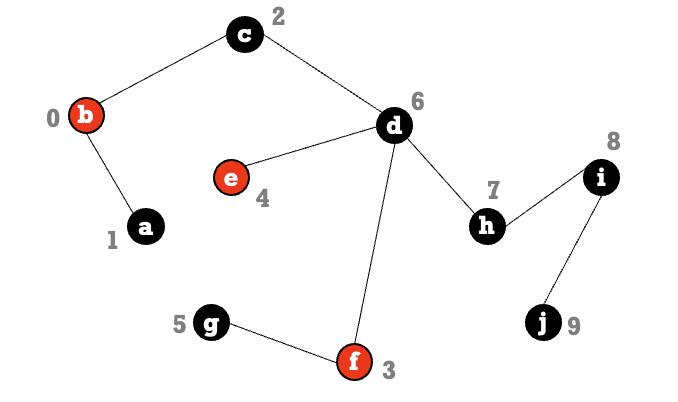
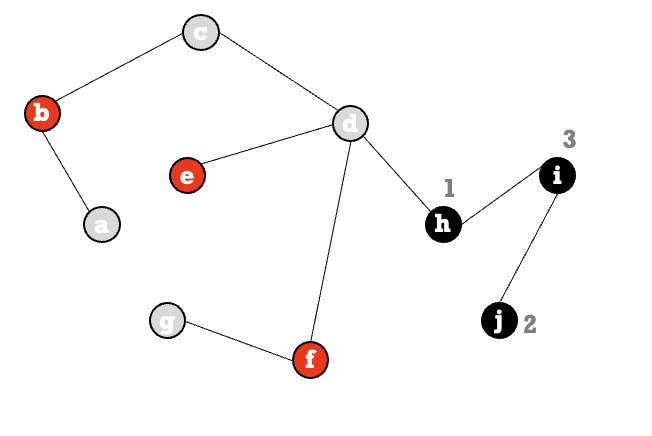
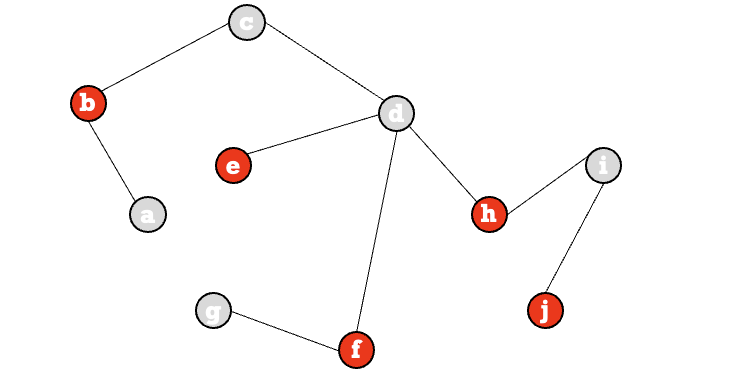
האלגוריתם הזה הוא אלגוריתם לאס וגאס כלומר, זה אלגוריתם שתמיד מצליח אבל זמן הריצה שלו הוא אקראי מספר האיטרציות תלויה במספרים שמגרילים, אך הוא תמיד נכון.
המעבר לאלגוריתם מקבילי יעשה בצורה הבאה:
א) את שורה 4 באלגוריתם נעשה בצורה מקבילית בO(1)
ב) את שורה 5 ו 6 גם אפשר לעשות באופן מקבילי על ידי החזקת
לאחר מכן את שורה 6 גם נעשה באופן מקבילי, נפתח thread לכל קודקוד ב I.
ההיבט המרכזי באלגוריתם של לובי המאפשר הקבלה הוא שלב התחרות המקומית. כל קודקוד מקבל החלטה רק על סמך שכניו המיידיים. לכן, קודקודים רבים יכולים לקבל החלטות אלה בו-זמנית ללא הפרעה. תהליך קבלת החלטות מקומי זה מאפשר לבצע את האלגוריתם ביעילות על מספר מעבדים במקביל, מה שהופך אותו לנקודת ציון בפיתוח אלגוריתמים מקבילים.