פרדיגמת קל כבד
כפי שאמרנו ב אלגוריתמים לזיהוי משולשים בגרף . נרצה לפתוח בעיה שדומה לבעיה זו. אם כן, נרצה למצוא פתרון לבעיית דיווח המשולשים על
נדגים כאן מספר אלגוריתמים פשוטים יחסית לפני שנכנס לאלגוריתם המשתמש בפרדיגמת הקל כבד ואז נסביר גם מהי.
דיווח המשולשים בגרף
האלגוריתם הנאיבי
triangle_report(G=(V,E))
for each (u,v,w) in V
if (u,v) and (v,w) and (u,w) are in E
report triangle (u,v,w)
האלגוריתם הנאיבי הזה עונה על בעייה שדיברנו עליה בהקשר שלכפל מטריצות מהיר, בזמן זהה לזמן של זיהוי משולש אני יכול לדווח על המשולש עצמו. כמובן שזמן זה הוא
האלגוריתם הפחות נאיבי
ניתן לשים לב, לכך שזמן הריצה כלל לא תלוי במספר הקשתות בגרף ־ והרי ברור שאם בגרף אין בכלל קשתות למשל, אז אין סיבה שהאלגוריתם ייקח הרבה זמן. נרצה שהאלגוריתם יתחשב בקשתות הגרף. נשים לב לכך שכל משולש, אפשר להסתכל עליו כקשת "בסיס"
triangle_report(G=(V,E))
for each (u,v) in E
for each w in V - {u,v}
if (u,w) and (v,w) are in E
report triangle (u,v,w)
זמן הריצה של אלגוריתם זה הוא
האלגוריתם השלישי
באלגוריתם הקודם על כל קשת רצנו על כל הקודקודים האפשריים שוב ושוב בלי להתחשב בשכנים האופציונליים של
נשים לב שאם הגרף מיוצג ברשימת שכנויות, וכל הרשימות ממוינות לפי סדר גלובלי של קודקודי הגרף, אזי ניתן לחשב חיתוך כזה במעבר אחד מסונכרן על שתי הרשימות שייקח
אם כן מהבנה זו נבנה את האלגוריתם הבא
triangle_detection(G=(V,E))
for each (u,v) in E
for each w in (N(u) ∩ N(v))
report triangle (u,v,w)
זמן הריצה יהיה
נשים לב שבמקרה הגרוע של גרף קליק יש בידיוק
זאת כל עוד, מסתכלים על קודקודי הגרף כפרמטר יחיד לזמן הריצה. מה אם נחפש את זמן הריצה של אלגוריתם לבעיה כפונקציה של מספר הקשתות והקודקודים? בגרף עם
אלגוריתם משולב
מההבחנה שהעלנו אנחנו מבינים שנרצה אלגוריתם שתלוי כמה שיותר במספר הקשתות וכמה שפחות במספר הקודקודים. זמן הריצה כתלות של במספר הקשתות במקרה הגרוע על גרף קליק הוא
באלגוריתם השלישי קיבלנו זמן ריצה שתלוי בדרגות הקודקודים. נשים לב שדרך אחת לחשוב על דרגות הקודקודים היא להזכר בכך שכל קשת תורמת 1 לדרגה של שני קצוותיה. לכן אפשר לחשוב שכאשר ידוע על גרף עם
הגדרה - עבור
נזכר בלמת לחיצת הידיים שאומרת ש
נשתמש במשפט זה כדי להוכיח חסם על מספר ה״קודקודים הכבדים״ בגרף. בכל מקרה האינטואיצייה היא שקודקוד כבד לוקח יותר אסימונים מהממוצע ולכן לא ייתכן שהרבה קודקודים לוקחים הרבה יותר מהממוצע כלומר
כאן נכנס האלמנט של פרדיגמת קל כבד לתמונה, אנחנו מסווגים את הגרף לשתי סוגים קל וכבד ולפי זה מבצעים אלגוריתם כלשהו
למה בכל גרף יש לכל היותר
הוכחה-
מלמת לחיצת הידיים סכום הדרגות הוא
בסתירה ללמת לחיצת הידיים.
כעת, נפריד את המשולשים בגרף לשני סוגים גם כן:
• משולשים שמכילים קודקודים כבדים .
• משולשים שכל קודקודיהם קלים.
תחילה, נפעיל את האלגוריתם השני על הקודקודים הכבדים בלבד. כלומר, נעבור על כל הזוגות של קודקוד כבד וקשת כלשהי ונבדוק אם הם יוצרים משולש. הרעיון הוא שבאמצעות הסיווג הזה אנחנו נחסוך זמן יקר של בדיקת החיתוך עבור קודקודים שבממוצע יש להם המון שכנים ולכן בסבירות גבוהה שהחיתוך לא יקטין משמעותית את כמו הקודקודים שנצטרך לרוץ עליהם ולכן נבזבז זמן מיותר.
triangle_report(G=(V,E)):
for each v in V:
v.isHeavy = deg(v) > sqrt(|E|)
for each w in V where w.isHeavy is true:
for each (u,v) in E
if (v,w) in E and (u,w) in E
report triangle (u,v,w)
for each (u,v) in E
if u.isLite and v.isLite
for each w in (N(u) ∩ N(v))
report triangle (u,v,w)
נכונות
נכונות האלגוריתם נובעת מהעובדה שהיא משתמש באלגוריתמים שכבר הוכחנו את נכונותם. ראשית, בוודאות האלגוריתם לא מדווח על שלשה שאינה משולש בגלל הסיבה שתיארתי. כעת עבור משולש כלשהו
אם אחד מהקודקודים כבד אז היינו שמים לב אליו בחלק הראשון של האלגוריתם. אחרת במעבר על הקשת
זמן ריצה
סריקת הגרף לצורך סיווג לוקח
השלב הראשון -
השלב השני-
סך הכל
מרחק האמינג עבור א״ב כללי
אם כן, בבעיית דיווח המשולשים התחלנו להבין מה הרעיון בפרדיגמת קל כבד.
- הגדרת ערך
שקובע שכל מי שגדול ממנו יהיה קבע וכל מי שקטן ממנו יהיה קל. - סיווג אוסף המידע לפי אותו
ומציאת חסמים למספר האפשרויות שיקיימו כל אחד מהתנאים. - אם ״כבד״ הרץ אלגוריתם א לחישוב בעייה כלשהי, אם ״קל״ הרץ אלגוריתם ב.
בהסבר על דיווח משולשים נתנו עובדה ואמרנו ש
נזכיר שבפתרון לבעיות של FFT כבר הצגנו את מרחק האמינג על א״ב בינארי.
נרצה לפתור את בעיית מרחקי האמינג עבור המקרה הכללי שבו
בדומה לפתרון באמצעות FFT, גם כאן נרצה למצוא את מספר ההתאמות של כל מיקום, ולא את מספר אי ההתאמות, כיוון שניתן לעבור בין אחד לשני באופן פשוט בזמן ליניארי לפי אורך הא״ב.
אלגוריתם ראשון
ראינו כבר כיצד אפשר לפתור את בעיית FFT על א״ב גדול יותר למשל עבור
אם כן הרעיון על א״ב כללי הוא זהה פשוט ארוך יותר

סף הכל זמן הריצה יהיה מספר התווים במחרוזת כפול זמן הפעולה שלוקח לעשות FFT כלומר
נשים לב שנוכל לייעל את האלגוריתם הנ״ל על ידי ביצוע הבדיקה רק על
האלגוריתם הנאיבי ביותר של השוואה פשוטה של ההיסטים מול הטקסט ייקח
נשים לב אם כן, שהאלגוריתם הזה הוא טוב במקרים שבהם התבנית היא עם מספר קטן יחסית של אותיות מהא״ב וגרוע כאשר יש מספר גדול של אותיות מהא״ב. אנחנו לא יודעים בידיוק מה זה המספר הזה וכאן ייכנס לתמונה הסיווג לקל וכבד שהגדרנו מקודם.
אלגוריתם שני
נדגים על מקרה פשוט ואז נסביר.
נסתכל על מקרה שבתבנית יש בסה״כ מופע אחד של
נוכל לספור את ההתאמות של
אם למשל יש
אם הפעולה הזאת זולגת בגבולות המערך לא מוסיפים בשום מקום כי זה יכול להעיד שבהמשך נתקל בתו הזה או שהוא לא תורם להיסט שאני נמצא בו.
נשים לב שעבור תווים נוספים למשל
נשים לב שמערך המונים
בעצם באופן ויזואלי זה ייראה כך
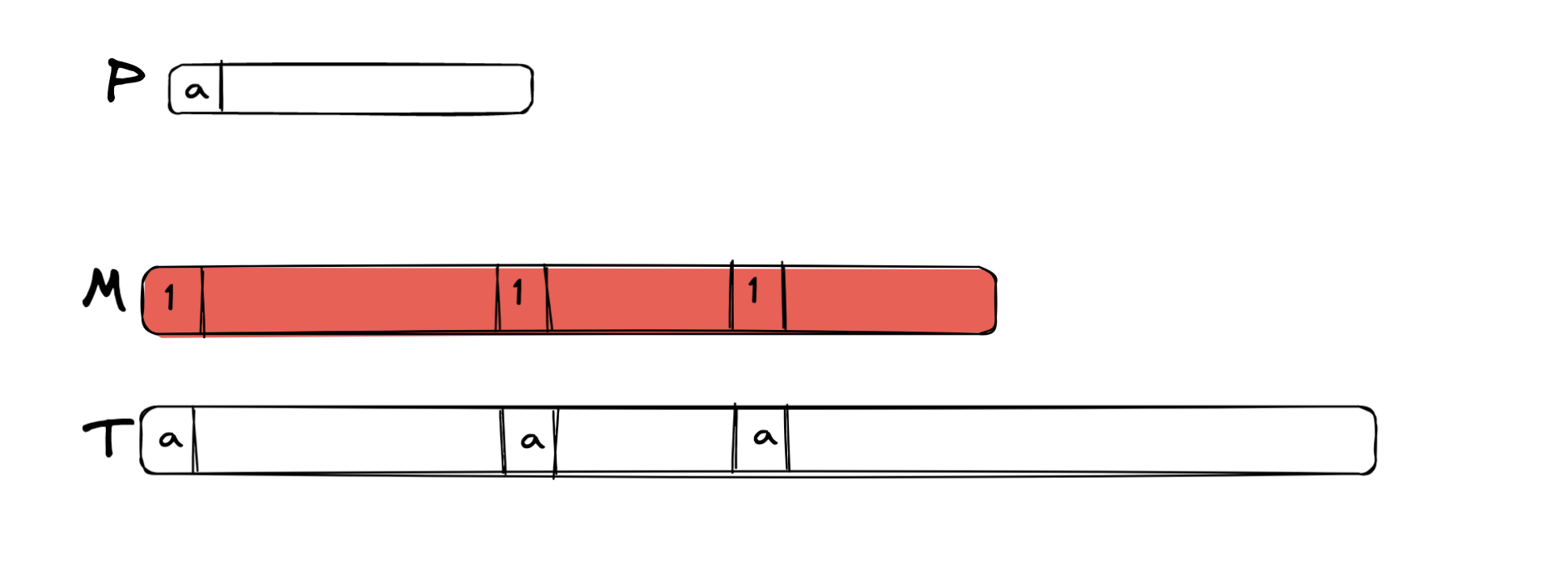
כאשר כל פעם שרואים
דוגמה:
עבור
נאתחל מערך בגודל
עדכנו את אותו האינדקס עבור שתי התווים כיוון שהם מיוצגים על ידי אותו ההיסט כלומר
ומשמעות הדבר היא שבהיסט במיקום הראשון יש שתי התאמות וההיסט במיקום החמישי הוא עם שתי התאמות וכל השאר בלי התאמות בכלל.
נשאלת השאלה איך מנהלים את זה באופן כללי?
כלומר נרצה לדעת בכמה מיקומים נמצא כל תו שאנחנו רואים ב
באופן פורמלי: נסמן לכל
בהנחה והא״ב סופי (בסבירות גבוהה שהוא יהיה) נוכל להחזיק מערך של רשימות מקושרות שהאינדקס ה

נשים לב שהאלגוריתם הזה לא יעיל במיוחד אם אנחנו יודעים שאות מסויימת בתבנית יכולה להופיע מספר רב מאוד של פעמים למשל עבור
באופן פורמלי, אם מספר המופעים של כל אות בתבנית חסום ב
אלגוריתם קל כבד
קיבלנו אם כן עבור הבעייה שלנו שתי אלגוריתמים שבמקרה הגרוע שלהם רצים בזמן
- אותיות שמופיעות בתבנית יותר מ
פעמים ייקראו כבדות - אותיות שמופיעות בתבנית פחות מ
פעמים ייקראו קלות.
אם כן התוסף היחיד שנעשה הוא הגדרת מערך מנייה שסופר עבור כל תו את מספר הפעמים שהוא נמצא בתבנית לאחר מכן נבדוק עבור כל תו האם הוא קל או כבד ולבצע את האלגוריתמים המתאימים.

הבחנה: בשלב 5 אפשר גם לרוץ על
זמן הריצה של האלגוריתם יהיה אם כן, מספר התווים הכבדים כפול זמן הריצה של האלגוריתם הראשון פלוס זמן הריצה של האלגוריתם השני על התווים הקלים. נשים לב שכמו בבעיית המשולשים גם כאן ניתן להגיד שמספר התווים הכבדים הוא לכל היותר
כעת נרצה לבחור
הערך המינימלי ביותר מתקיים כאשר הביטויים הנ״ל שווים , שכן אם נגיד ש
כלומר נבחר
הרעיון בפרדיגמת קל כבד היא שיש לפנינו שני אלגוריתמים ששניהם נורא יעילים עבור מקרים מנוגדים ומקרי הקצה שלהם נורא לא יעילים, כדי לאכול את כל העוגה נרצה לסווג את המידע ככה שאת המקרים שעבורם האלגוריתם הראשון יהיה יעיל נוכל להריץ עליו ובמקרים שהאלגוריתם השני יהיה יעיל נוכל להריץ על השני.
כדי למצוא את הערך הזה קודם כל נבטא אותו באופן כללי ונריץ את שתי האלגוריתמים לפי הסיווג הכללי שהגדנו