בעיית תחזוק של קבוצה של איברים בגודל תחת הפעולות הבאות: insert(x) - להוסיף אל delete(x) - עבור , להסיר את מ . member(x) החזר כן אם ורק אם
אם ישנו יחס סדר על האיברים נוכל לבנות עץ חיפוש בינארי מאוזן ולתמוך בפעולות הנ״ל בזמן . לעתים לא נרצה יחס סדר כלשהו בין האברים כי הסדר לא בהכרח משנה לנו.
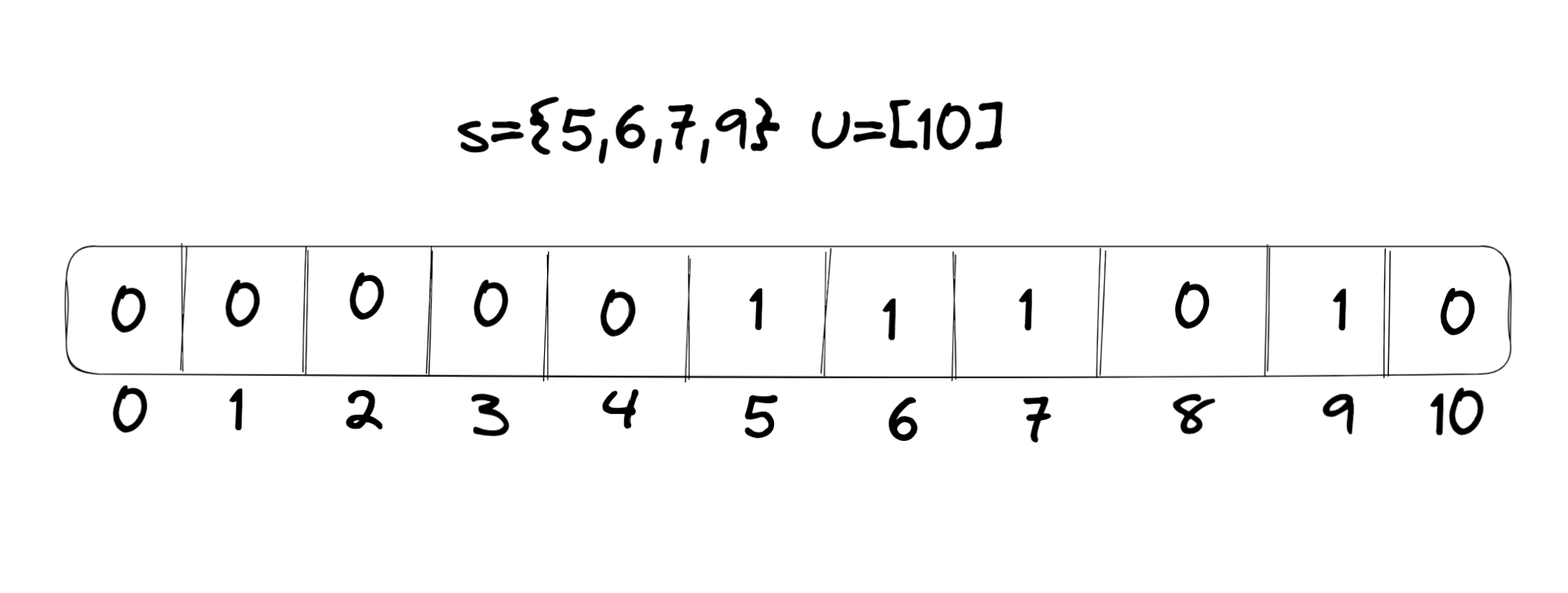
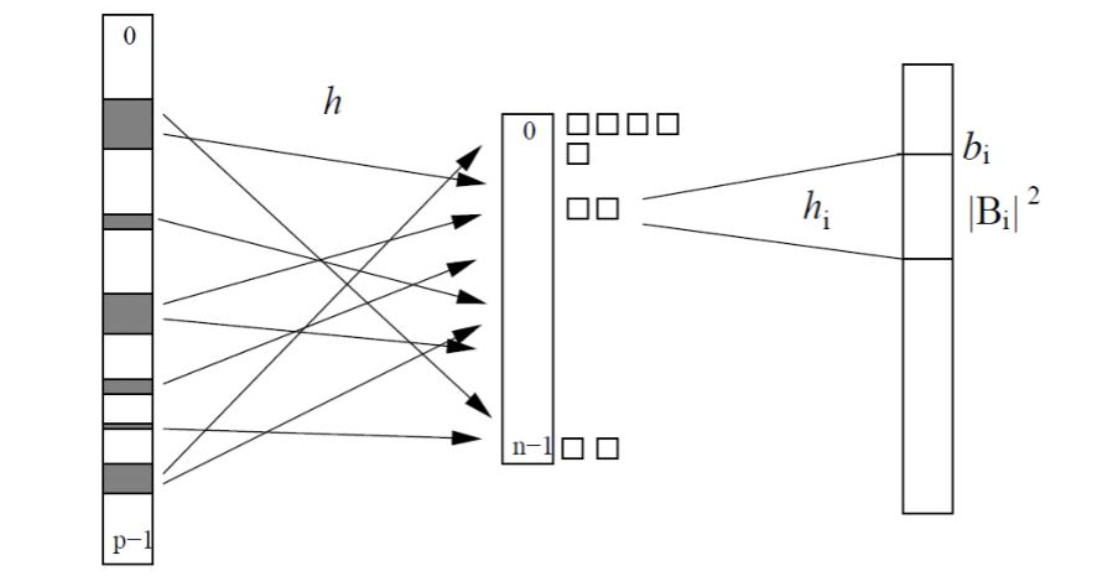
נניח שקבוצת האיברים שלנו נמצאת תחת עולם כלשהו נסמנו . ומתקיים .
אם כן אחד הדברים האינטואיטיביים שאפשר לעשות אם אין יחס סדר זה להשתמש במערך בינארי מגודל .
באופן הזה כל אחת מהפעולות שלנו תעלה . ניגש פשוט למקום ה ונחליף את הערך עבור הכנסה והוצאה ונחזיר את הערך כדי לדווח האם הוא member או לא.
חסרון
החסרון המשמעותי ביותר וגם הוא די אינטואיטיבי יהיה כאשר במצב זה מבזבזים המון זכרון. למשל אם הייתי משתמש בשיטה הזאת כדי לבדוק האם קיים או לא הייתי צריך להחזיר אוסף מידע בגודל וזה רק עבור IP/4 שלא לדבר על גרסאות כמו IP/6 שיכולות להחזיק אפילו יותר ערכים
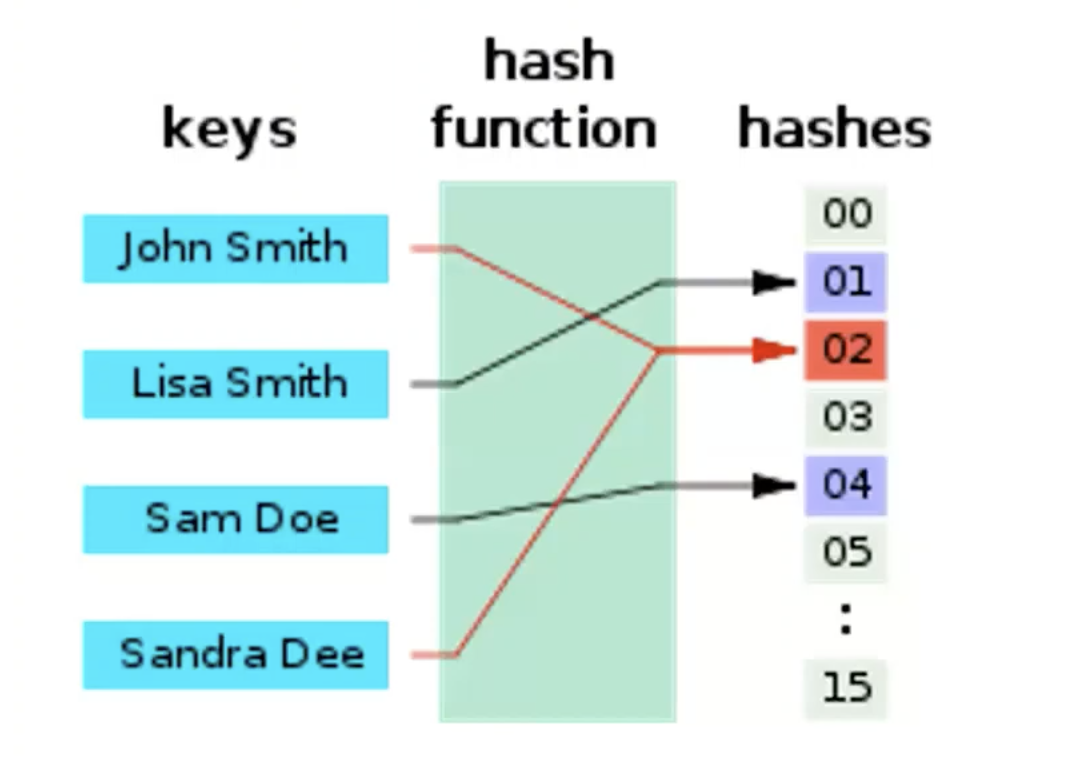
באופן כללי נרצה למפה מפתחות כלשהם לאיזשהו אינדקס בטבלת
פונקציית הגיבוב
רעיון לפתרון הבעיה- נמצא פונקצייה כאשר ש מצב אידיאלי מקיימת את התכונות הבאות
א) חוסר בהתנגשויות
ב) זמן חישוב של הוא קטן
ג) יחסית קטן בתקווה שהוא קרוב ל
אם תהיה לנו פונקצייה כזאת , נוכל ליישם את פתרון המערך שהראנו קודם. נגדיר מערך ויתקיים
נקראת טבלת גיבוב. והפונקצייה נקראת במצב זה perfect hash.
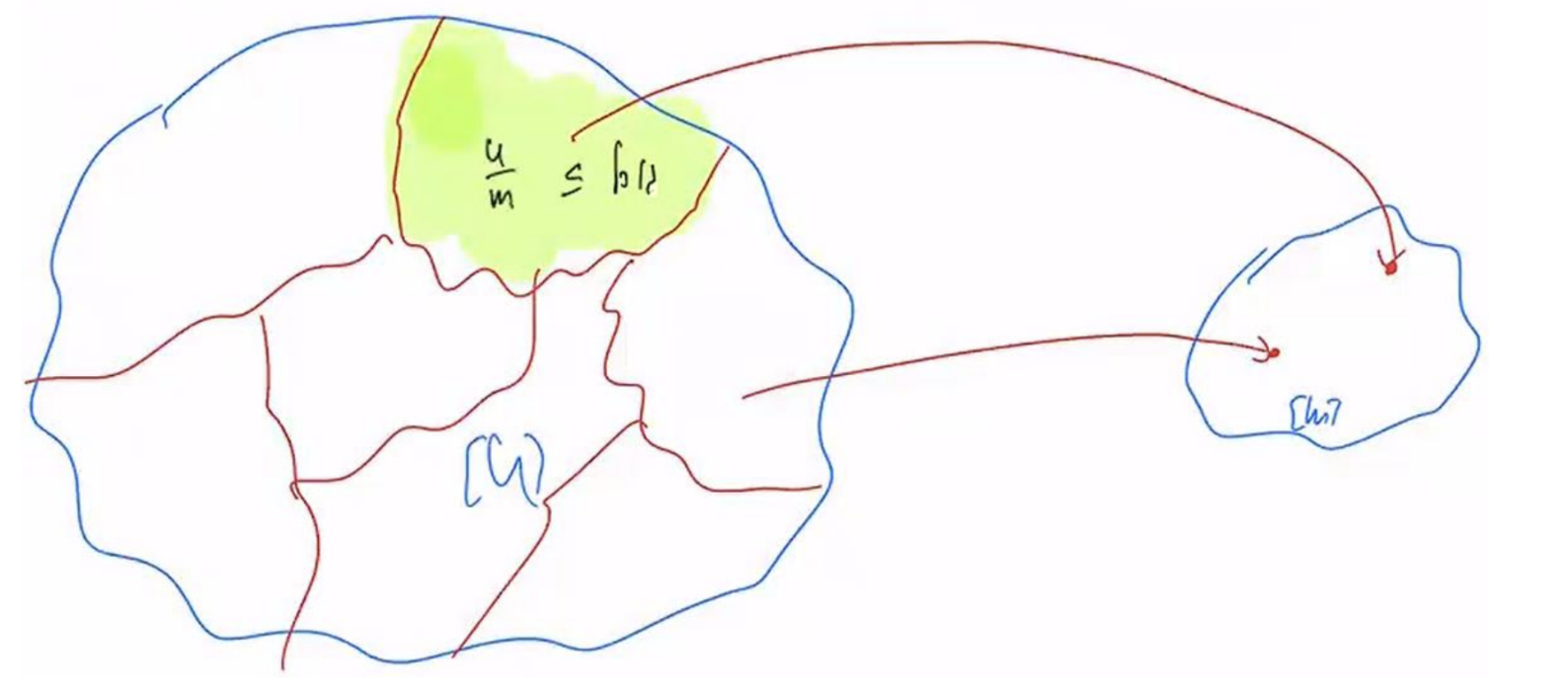
הרעיון זה שגם אם נביא מהעולם שהוא מספר מאוד גדול נוכל למפות אותו לעולם קטן יותר . זמן הריצה תלוי בזמן שלוקח לחשב את אם הוא קבוע אז שיטת המערך שלנו היא קבועה בידיוק כמו בדוגמה הראשונה.
כמובן שאנחנו יודעים שבסבירות מאוד גבוהה שכן יהיו התנגשויות עבור פונקצייה שממפה מתחום גדול לטווח קטן. מה קורה אם יש התנגשויות?
כלומר קיימים כך ש
אם אבל ניתן להבין את הבעיתיות בשיטה הזאת.
כלומר מטרת העל שלנו היא לבנות את הפונקצייה כך שיהיו כמה שפחות התנגשויות. כמה מטרות ביניים שנרצה להשיג יהיו:
בניית עם עלות בנייה קטנה שכן כפי שאמרנו היא משפיעה על זמן הריצה.
ש יהיה יחסית קטן כיוון שהוא ישפיע על סיבוכיות הזכרון שלנו. יש לו חשיבות גבוהה בבניות שנעשה בהמשך שכן, ככל שהוא גבוה יותר ככה נשלם בזכרון ונקבל בתמורה פחות סיכון להתנגשויות וככל שהוא קטן יותר הסיכוי להתנגשויות עולה.
נשים לב
המערך לא צריך להיות בינארי אפשר גם לרשום את הערכים עצמם אבל זה לא משפר או מתקן כלום שכן אם יש התנגשויות לא נדע כיצד להתמודד עם זה בידיוק באותו האופן שבוא לא ידענו עם המערך הבינארי
שימוש ברנדומיות
בהינתן קבוצה עם איברים מ .נגדיר את הפונקצייה שעבורה אין התנגשויות כ perfect hash.
זאת פונקצייה שממש קשה למצוא אותה ויש בכלל אפשרות שאם נעדכן את הקבוצה שלנו כמו שאנחנו צריכים לתמוך אז הפונקצייה הזאת כבר לא תהיה רלוונטית.
והחסרון הכי משמעותי הוא שצריך לרוב לבנות את הפונקצייה לפני שבכלל אנחנו יודעים מיהי . כמו כן מ שובך היונים אנחנו יודעים שאם נקבל פונקציית הרי שבהכרח עבור ישנה קבוצה כלשהי של איברים שכולה ממופה לאותו ערך .
המשמעות היא שאם במקרה תהיה הקבוצה הזאת אז פונקציית הגיבוב שלנו לא תעבוד בכלל.
הבעיה בשימוש באקראיות לקביעת
מספר הפונקציות שמתאימות לנו הוא וברובן יש הרבה התנגשויות. אנחנו רוצים לבחור את אחת מהפונקציות האלה למשל על ידי בחירה של מספר בטווח , הפונקצייה ש״שמורה״ במקום הזה תהיה . כלומר נתאר את על ידי המספר של הכניסה ברשימה. היכולת הזאת לשייך מספר לפונקצייה מצריכה זכרון, למעשה עבור קבוצה בגודל צריך ביטים לייצוג כל הקבוצות ובאופן דומה עבור צריך ביטים כדי לשדך מספר לפונקצייה. זה הופך להיות יקר מאוד מהר מאוד. כלומר שימוש בהתפלגות אחידה לבחירה של היא יקרה מדי.
המסקנה היא שלא נרצה לבחור את הפונקציות ממרחב כל הפונקציות אלא ננסה לרכז אוסף מסויים של תכונות כדי לצמצם את המרחב שממנו בוחרים את הפונקציות.
התכונות החשובות של מרחב הבחירה של h
Uniformity
נרצה שלכל יהיה סיכוי שווה להיות ממופה לכל אחד מהערכים ב כלומר
collisions
כלומר הסיכוי שהפונקצייה שבחרנו מתוך תקיים את הדרוש צריכה להיות לכל היותר .
הגדרה
אם תנאי ההתנגשות מתקיים נגיד ש היא משפחה אוניברסילית.
נקל טיפה את התנאי ונגדיר משפחה להיות כמעט אוניברסלית אם
דוגמאות לפונקציות גיבוב
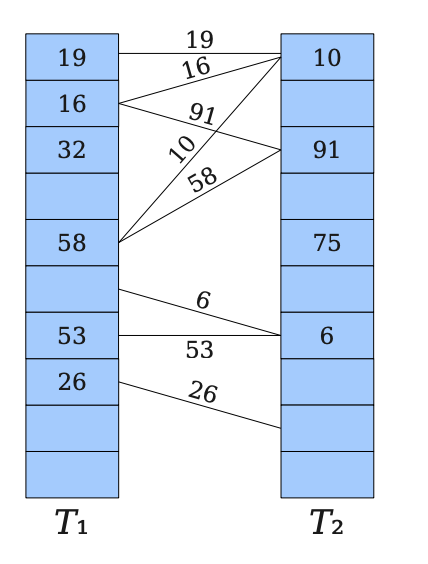
שיטת החלוקה
ברור שנקבל מספר בין ל .
שיטה זו לא טובה במיוחד למשל אם מוכלת בקבוצת המספרים הזוגיים ו הוא חזקה של . אז יש טווח גדול של ערכים שאנחנו לא משתמשים בו באמצעות הפונקצייה הזאת.
שיטת הכפל
כאשר היא פעולת החילוק ללא שארית (אפשר לדמיין את זה כמו casting ל int). נבחר בבחירה רנדומית ובשאיפה שיהיה אי זוגי. מייצג את מספר הביטים במילת מחשב. הביטוי זה בעצם כל המילים שניתן לייצג עם הגודל . הכפל נותן לי בעצם תוצאה שהיא בגודל של לכל היותר 2 מילות מחשב. פעולת המודולו לוקחת את החצי הימני של המילה. כיוון שכדי לתאר את קבוצת המספרים בין דרוש עד ביטים. מקיים שהוא כלומר . כאשר החלוקה מתרחשת אנחנו נפטרים מ הביטים החל מהLSB.
לא אכנס לעומק של נכונות הפונקצייה הזאת ברמה הפרקטית
דוגמה למשפחה אוניברסלית
כאשר איבר בקבוצה הוא מהצורה . ייבחרו באקראי מהתחום
ו ראשוני (תמיד יש כזה).
פעולת ה תבטיח שכל הערכים ייכנסו לטבלת הגיבוב שלנו.
זאת משפחה שקיימת את תכונת ההתנגשות אך לא אוכיח זאת
לפונקצייה זו יש תכונה חשובה מהסתברות שנקראת אי תלות בזוגות כלומר עבור פונקצייה יתקיים
ואם תכונת ה וuniformity מתקיימת אז
הבחנה
במקרה הזה בחירה של הפונקצייה תלויה בפרמטרים כלומר ההסתברות ש לפי שנבחרו היא
שיטות להתמודדות עם התנגשויות
אם כן ראינו וסיווגנו משפחות של פונקציות שנוכל להעזר בהן כפונקציות גיבוב אבל אין הבטחה חד משמעות שלא יהיו התנגשויות. כלומר יש הסתברות נמוכה לכך אבל זה לא מובטח שלא יהיו ולכן צריך למצוא דרך להתמודד עם התנגשויות.
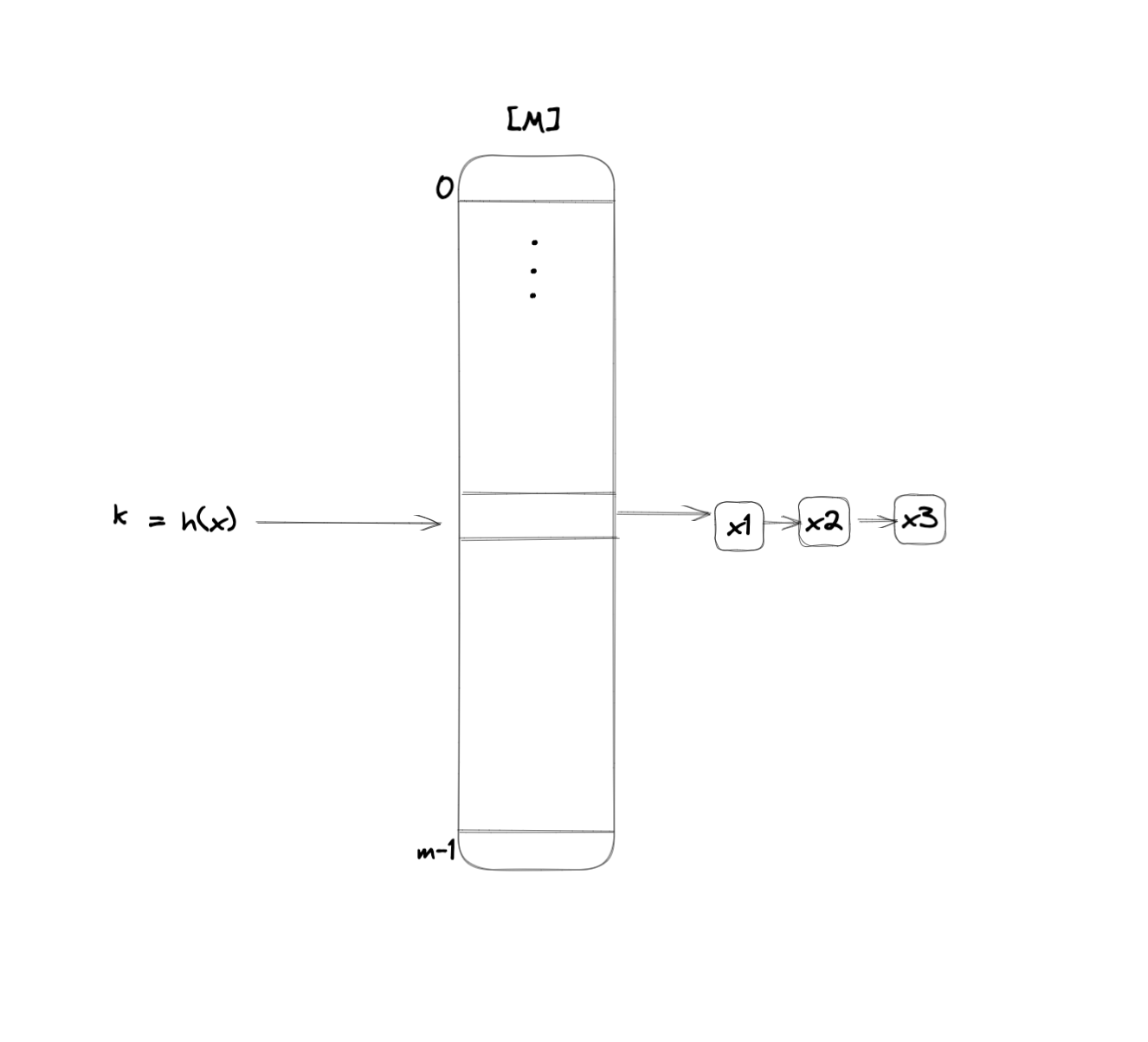
Chaining
במקום ה בטבלה מגודל תהיה רשימה מקושרת של כל האיברים שמופו לערך על ידי הפונקצייה .
במקרה הגרוע חיפוש האם יהיה שכן אם כל האיברים מופו לאותו ערך ואז במקום זה בטבלה יש רשימה מקושרת של כל האיברים ייתכן שצריך לסרוק את כולם.
נסמן את מספר האיברים מ שמופו אל כלומר מספר ההתנגשויות. במקרה גרוע.
המעבר האחרון נובע כי .
המשמעות היא קצת כמו במיון דלי . מספר האיברים המצופה שיהיה בכל תא בטבלה הוא . נסמן את זה כ load factor
נשים לב ש מאיך שהם מוגדרים ולכן .
סך הכל תוחלת זמן החיפוש תהיה חיפוש התא המתאים וחיפוש ברשימה שזה אומר
זמן המחיקה זהה לזמן החיפוש.
עלות להכנסה היא שכן מכניסים לתחילת הרשימה.
בסיכוי גבוה אורך השרשרת הארוכה ביותר הוא . נזכר שסיכוי גבוה הוא .
הבחנה
אנחנו בוחרים את הפונקצייה הגלובלית מבין משפחה של פונקציות גלובליות כלשהן. הייצוג של משפחה כזאת בביטים הוא קבוע כיוון שהוא תלוי בפרמטרים שאנחנו מגרילים באקראי למשל במשפחה שהראנו למעלה צריך להגריל וזה לא בעייה לייצג אותם בביטים. כלומר החסם לייצוג פונקציות שלנו בביטים הוא
כאשר הסיבה ששמנו היא בגלל שהחסם עליון של המספרים היא באותה מידה אם הייתי צריך לייצג גם את ואת הייתי מקדיש ביטים לייצוג. זה תלוי במספר שמחשבים או מגרילים.
למרות שאנחנו בוחרים מבין פחות אפשרויות אנחנו עדיין מקבלים תוחלת שנותנת התנהגות טובה יחסית שקרובה להתנהגות במצב שבו היינו מגרילים מכל הפונקציות האפשריות.
שיפורים
א) במקום רשימה מקושרת היה אפשר להשתמש במבנה נתונים אחר כמו עץ מאוזן אם יש יחס סדר.
ב) שימוש בשתי פונקציות
במקום פונקציית אחת נשתמש בשתי פונקציות . נכניס את לרשימה הקטנה יותר ואם אורך של שתי הרשימות זהה בוחרים אחת מהן. שם האלגוריתם נקרא power of two choices. זמן הריצה בסיכוי גבוה הוא
Open addressing
הרעיון - במקום פונקציית hash אחת נשתמש ב פונקציות גיבוב . ונניח שלכל מתקיים ש היא פרמוטציה של המספרים . כלומר כל אחת מהפונקציות ישלח אותי למספר אחר.
אלגוריתם החיפוש
כדי לבדוק האם נפעיל ונבדוק האם נמצא במקום הזה בטבלה. אם יש ערך אחר נפעיל את וככה נמשיך עד שנגיע למקום ריק או עד שנמצא את .
הכנסה
על מנת להכניס איבר נחפש את המקום הראשון שריק על ידי הפעלת הפונקציות הנ״ל ונכניס לשם את . בגלל ההנחה שמדובר בפרמוטצייה אנחנו יכולים להסיק שהאלגוריתם יעבוד, כלומר מובטח שיימצא איבר פנוי כל עוד הטבלה לא מלאה . אחרת אם לא נמצא מקום ל אנחנו בעצם מתמודדים עם טבלה מלאה ויש לבצע פעולה שהיא מחוץ ל סקופ שאדבר עליו כאן. בגדול מבצעים פעולת rehash להגדלת הטבלה.
תחת הנחת הגיבוב האחיד זמן החיפוש וההכנסה הוא .
מחיקה
מחיקה במיעון פתוח היא פעולה בעייתית. החיפוש אחר איבר מתבצע באמצעות מעבר על האיברים עד שמוצאים את או שהתא ריק. אם נמחק איבר, ייתכן שהחיפוש ימצא תא ריק לפני שימצא את למרות ש במבנה. כדי להתמודד עם זה הפתרון הפשוט ביותר הוא להכניס איבד temp שמסמן מקומות שבהם מחקנו איבר . אם נתקל באיבר מהסוג הזה אנחנו יודעים שמחקנו משם איבר ולכן בהכנסה נבצע השמה אבל בחיפוש נדלג.
בחירה נכונה של סדרת הפונקציות
Linear probing
בבדיקה ליניארית כאשר נמצא התנגשות נתחיל לסרוק את המערך תא אחרי תא (באופן ציקלי, כי זה בידיוק מה שקורה עבור הפעלה של הפונקצייה הבאה בסדרה) עד שנמצא תא ריק ובתא הזה נשים איבר חדש. בוחרים ומתקיים
החסרון בשיטה הזאת היא שעלול להיווצר עומס, כלומר הצטברות של איברים רצופים. אם יש בלוק של תאים רצופים ככל שהוא גדול יותר ככה בסבירות גבוהה יותר שאני אתנגש בו ואצטרך להתחיל לסרוק אותו כלומר ההסתברות שהאיבר הבא ייצטרף לסוף הרצף הזה ויאריך אותו היא . היתרון בשיטה הזאת היא בעיקר ברמה הפרקטית, סמיכות האיברים גורמת להם להיות גם באותה רמה של cache כלומר יהיו פחות cache misses .
quadratic hashing
הרחבה של הבדיקה הליניארית. נבחר כאשר ונקבע לפי
נשים לב שהבדיקה הליניארית היא מקרה פרטי של . היתרון בשיטה זו היא שלא נוצר עומס כמו במקרה הליניארי אבל עדיין יכול להווצר עומס מסדר שני. המשמעות היא שכל שיקיים ילך לאותו מסלול עבור הפעלת הפונקצייה וכן הלאה. במצב זה יש מסלולים שונים סך הכל. במקרה זה גם צריך לשים לב שהבחירה שלנו היא עדיין פרמוטצייה אחרי השמה של .
double hashing
נשתמש בשתי פונקציות hash נפרדות ונגדיר
כלומר בכל בדיקה של איבר נעבור מספר צעדים קבוע שהוא . אם נבחר את להיות מספר ראשוני, אז המסלול של כל איבר אכן יהיה פרמוטציה ולכן אם יש מקום פנוי במערך הוא יימצא. בשיטה זו כבר יש מסלולים שונים ולכן היא יותר קרובה להנחת הגיבוב האחיד. נשים לב שמקרה של הפרמוטציות הנחת הגיבוב האחיד אומרת שיש פרמוטציות שונות אבל בבחירות שלנו עד כה הצלחנו לבנות רק פרמוטציות שונות ועכשיו יש כלומר אנחנו משלמים באקראיות המלא ומאבדים חלק מהפרמוטציות אבל מקבלים בתמורה שיטה סדורה שמבטיחה סדר מסויים של מיקום האיברים בטבלה וטיפול יותר טוב בהתנגשויות , הכנסות ומחיקות.
שילוב – שיטת FKS
ראינו עד כה שתי דרכים לנהל טבלת גיבוב כדי לטפל בהתנגשויות ובחיפוש והכנסה כמו שרצינו. אבל עדיין לא הגענו למצב של גיבוב מושלם . נניח תיאורטית שהגודל של הוא סטטי ואנחנו לא תומכים בהכנסה. במצב זה היינו יכולים לקבוע
רעיון לבחור פונקציה כמעט אוניברסלית . אם אין התנגשויות כאשר מפעילים את על כל האיברים ב אז סיימנו. תוחלת מספר האיטרציות היא לכל היותר 2 כי ההסתברות להצלחה גדולה מ. אם יש התנגשויות נחזור על כל התהליך.
במצב זה הגיבוב הוא מושלם אבל נקבל טבלה גדולה מאוד רצינו ש . כמו כן חסרון משמעותי הוא העובדה שאני צריך להריץ את פונקציית הגיבוב שבחרתי פעמים על כל איברי כדי לוודא שאין התנגשויות.
אם כן כעת נוכל לדבר על שיטת FKS. שמשלבת בין השיטה הנ״ל לשיטת chaining. הסיבה לשילוב היא שאומנם בשרשור פונקציית הhash לא מושלמת אבל הטיפול בהתנגשויות במצב של הכנסה מושלם ובמקרה הסטטי שעכשיו תיארנו פונקציית הhash היא מושלמת אבל גודל הטבלה הוא גדול מדי.
הרעיון הוא להשתמש בפונקצייה כמעט אוניברסלית כמו מקודם. אבל נקבע . כמובן שבהתסברות גבוהה יותר שנקבל בחלק מהתאים התנגשות.
לכל מספר נסמן ב את מספר האיברים שמופו לתא ה
אם יש התנגשות.
כעת עבור נחפש פונקציית גיבוב מושלמת בידיוק כמו במצב הסטטי רק עבור הקבוצה . נמפה כל איבר בקבוצה למקום בטבלה ה שנקבע על פי
למעשה הרעיון הוא הפעלה של פונקציית hash פעמיים. פעם אחת כדי להיות ממופה לתא ה ובפעם השנייה כדי לקבל את המיקום הספציפי בטבלה לפי שהיא מושלמת.
חיפוש
דורש הפעלת שתי hash כלומר .
נשים לב שאין תמיכה בהכנסה ומחיקה
בנייה
עבור נשקיע זמן בתוחלת וגם זכרון. סך הכל
לא אכנס להוכחה אבל מתקיים ולכן בתוחלת הזמן לבנייה הוא שזה יתרון על בני הבנייה במקרה הסטטי.
גיבוב קוקיה
גיבוב הקוקייה קרוי על שם ציפור הקוקיה. שנוהגת להטיל את ביציה בקינים של ציפורים אחרות, לאחר שדואגת לזרוק את הביצים המקוריות שהיו בקן.
בשיטת גיבוב הקוקיה נשתמש בשתי פונקציות גיבוב בלתי תלויות. ונגדיר כבר עכשיו ש לטבלה שתשמור איברים. לכל איבר בעולם שלנו אם כך יש שני מקומות מתאימים בטבלה . שיטה זו יחסית פשוטה ביחס לשיטות אחרות אבל ישנם מקרי קצה שצריך לדון בהם.
search(x)
if x is in h0(x) or h1(x)
return x
return "x is not in the table" or NULL
delete(x)
if x = search(x) is not NULL
delete(x)
היתרון הברור של גיבוב הקוקיה על פני שיטות אחרות היא שחיפוש ומחיקה הם בזמן קבוע במקרה הגרוע ולא רק בתוחלת או בהסתברות גבוהה.
הכנסה
אלגוריתם ההכנסה דומה לאיך שעובדת ציפור הקוקיה בטבע. איבר חדש שנכנס למבנה עם הערך יישמר בתא . הבעיה היחידה היא מה קורה כאשר התא הזה תפוס על ידי . במצב זה נעביר את לתא אחר כלומר אם נמצא ב אז נעביר אותו ל . אם נמצא ב אז נעביר אותו ל
כמובן שכתוצאה מההכנסה הזאת אנחנו יכולים להתקל בבעיה חדשה כלומר, אותה הבעיה פשוט על התאים שעכשיו אנחנו רוצים להכניס את . כלומר נוכל לפתור את הבעיה באותו אופן. נחלק למקרים :
אם המשכנו את התהליך עד מציאת תא ריק - נכניס לתא הריק
אם ביצענו את התהליך פעמים אז נעצור את הריקורסייה ונבנה את כל המבנה מהתחלה במקום לנסות להמשיך לתקן. המשמעות היא שמגרילים שתי פונקציות גיבוב חדשות ומכניסים את כל האיברים לטבלה חדשה על פי הפונקציות האלו.
סוגי הכנסות
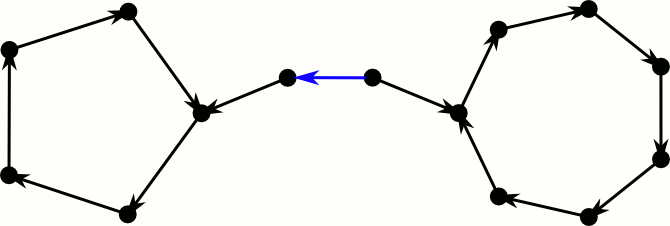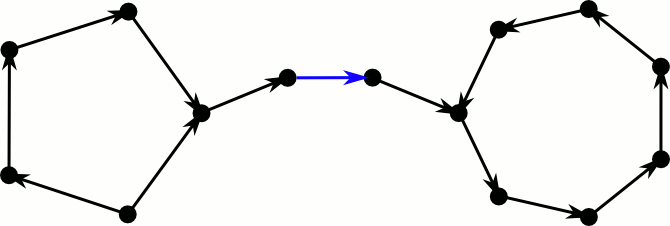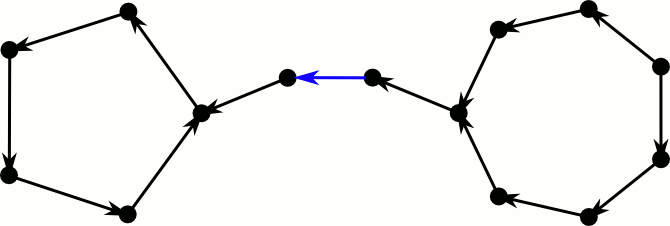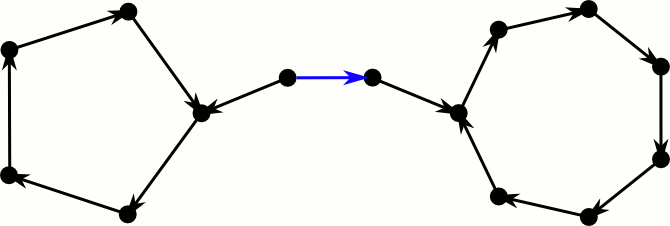
ברמה העקרונית ישנם שלושה סוגים של מסלולי הזזה- כלומר סדרות של מעברים של איברים כתוצאה מהכנסת איבר חדש. כדי להבין יותר טוב איך זה נראה נוכל להסתכל על הגרף התואם לטבלה. בגרף יהיו קודקודים- קודקוד אחד לכל תא, ו קשתות- כך שלכל נוסיף לגרף את הקשרת באופן לא מכוון. אם כן מסלולי ההזזה הם
א) מסלול פשוט סדרה של איברים שונים כך ש ומסלול זה מתחיל ב ובכל צעד מתקדם על הקשת (בכיוון המתאים ביחס לקודקוד שממנו באנו.) ומעבירים את האיבר ה מהתא בו הוא היה נמצא לתא השני שלו.
ב) מעגל אחד סדרה של איברים כך שבנקודה מסוימת איבר מופיע פעמיים. במקרה הזה אנחנו נחזור על עקבותנו עד להתחלה כלומר אבל עם איבר חדש ואז נעביר את האיבר החדש לאפשרות השנייה שלו על ידי הפעלת ונמשיך במסלול פשוט עד שנגיע לתא ריק. נשים לב שזה לא מעגל מהצורה שתגרום ללולאה אינסופית שכן הגענו לאותו אינדקס בטבלה הראשונה עם ערך חדש
ג) מעגל כפול - מצב שבוא מגיעים בטבלה הראשונה במקום לתא ריק נגיע לאיבר שכבר ביקרנו בו וכתוצאה מכך סדרת ההזזות תהיה אינסופית.
ניתוח
לא אכנס לניתוח המדוייק של זה כאן , אבל לסיכום זה יוצא