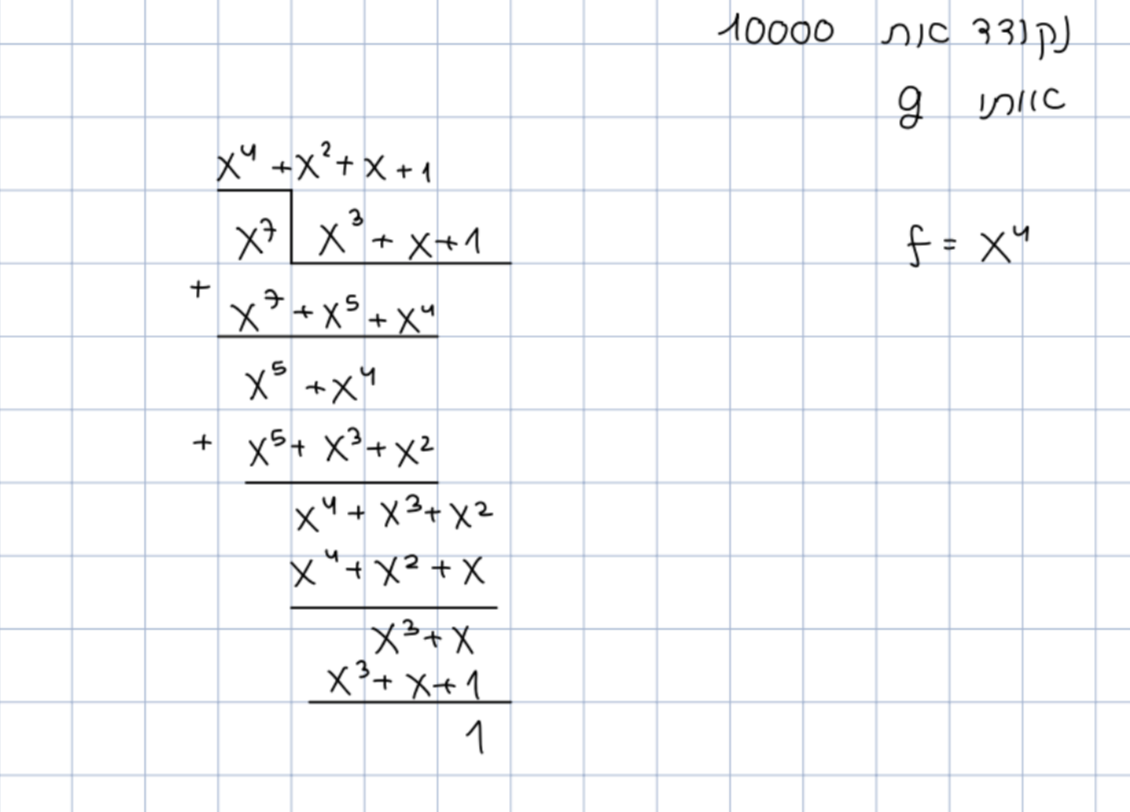מטרת הקידוד היא זיהוי ותיקון שגיאות בתהליך העברת המידע .דוגמא: כאשר נשלח מידע כלשהו (רצף של ביטים), נרצה לדעת שלא נפלה טעות בדרך. לשם כך, נוכל לשלוח את אותו המידע פעמיים. כך, מובטח שאם ביט אחד שובש, שתי פיסות המידע לא יהיו תקינות ונוכל לזהות שגיאה. אך, לא נוכל לדעת לתקן את השגיאה. לשם כך, נוכל לשלוח שלושה רצפים אחד אחרי השני, ובכך אם נפלה טעות אחד נוכל לתקן. נשים לב שזה לא פרקטי על מנת לזהות ולתקן שגיאות היינו צריכים להכפיל ואף לשלש את המידע.
קוד, מילה ויתירות
קוד הוא תת קבוצה של כלומר קבוצה של וקטורים בינאריים באורך .
מילה היא איבר בקבוצה . מילה תמיד מורכבת מ יתירות+מידע כאשר המידע והיתירות הן וקטורים בינארים מגדלים כך ש .
מילה נקראת חוקית כאשר היא קידוד של מידע כלשהו, כלומר ישנו איזשהו קופסה שחורה ״המקודד״ שיודע לקחת את המילה ולחלץ ממנה מידע. מילה לא חוקית משמעותה שנפלה שגיאה.
parity check
מזהה האם כמות השגיאות היא אי זוגית. אם היא זוגית לא נזהה את השגיאה.
נניח שהמידע שלנו הוא ונגדיר את המילה המקודדת כ כאשר הסכום הוא היתירות. לאחר העברת מידע ישנה מילה שמתקבלת בצד השני, נסמנה כ . נשים לב ש:
חשוב: כל המתמטיקה היא מעל חוג השאריות מסדר 2
אם המילה המתקבלת שווה למילה שנשלחה כלומר יתקיים
נזכר ש ונגדיר שגיאה באינדקס להיות . כעת במצב של שגיאה אחת יתקיים כלומר
כלומר ניתן לראות שבמצב שבו יש שגיאה אחת (או מספר שגיאות אי זוגי), התוצאה של הסכימה תהיה ולכן נוכל לזהות שגיאות כאשר מספר השגיאות הוא אי זוגי. אם לעומת זאת מספר השגיאות הוא זוגי נקבל בסכימה שזה כמו שנקבל במצב שאין שגיאות בכלל ולכן לא נזהה.
קידוד ליניארי
נגדיר קידוד ליניארי עם מטריצות. נסתכל על . ניצור ממנה את זוג המטריצות הבא
כאשר היא המטריצה המקודדת ו היא המטריצה המפענת.
המידע הוא כלומר וקטור בגודל כמות עמודות המטריצה והיתירות היא באורך כמות שורות המטריצה .
המילה המקודדת היא כלומר
כעת בנינו את המילה הנשלחת. איך מקודדים אותה ומזהים שגיאות?
הבחנה
אוסף המילים החוקיות הוא כלומר כל המילים
הצד השני בדומה לשיטה של בדיקת זוגיות, מקבל ומחשב במטרה לקבל וקטור . טענה: תהי מילה אזי
כלומר- קוד ליניארי הוא בעצם כלומר מרחב האפס של המטריצה .
הוכחה- : נניח אזי
סך הכל נקבל שלכל
: נניח , יהי כלשהו והמילה הנשלחת כדי ש תהיה מילה חוקית צריך להראות ש . אכן:
נשיב לב
מסקנה מההוכחה הזאת היא שיתירות של מילה היא יחידה והיא תמיד
דוגמה: , נשים לב שכמות העמודות = אורך המידע , כמות השורות = אורך היתירות, אם כן
ו ומתקיים
כיצד שגיאות משפיעות על התהליך?
נניח והתקבלה שגיאה אחת כלומר המילה שהגיע לצד השני היא ויתקיים
כלומר נזהה כל שגיאה יחידה אמ״מ ב אין עמודות אפסים (שזה שקול לדרישה שב לא יהיו עמודות ). אם למשל העמודה ה ב הייתה במקרה הנ״ל עדיין היינו מקבלים בתוצאה שזה לא טוב.
מה לגבי שתי שגיאות? יתקיים
אם אלו היו זהות אז היינו מקבלים גם כן בגלל שאנחנו מעל השדה מודולו 2. ולכן נזהה 2 שגיאות אמ״מ ב אין זוג עמודות זהות.
מסקנה
אם אין עמודות אפסים ב ואין 2 עמודות זהות, במצב זה נזהה כל 2 שגיאות ונוכל לתקן שגיאה יחידה
שאלה:
בהינתן ביטי יתירות מה יהיה אורך המידע הגדול ביותר עבורו תהיה ללא עומדת אפסים וללא זוג עמודות זהות?
זוהי שאלה קומבינטורית , אם יש ביטי יתירות זה אומר שיש שורות ב כלומר כל עמודה יכולה להחזיק בתוכה ערכים ולכן יש צירופים שונים לבניית עמודה (כולל עמודות האפסים.) כמו כן נשים לב ש מורכבת מ עמודות יחידה ולכן גם הן תפוסות לנו, סך הכל אורך המידע הגדול ביותר עבורו תהיה ללא עמודות אפסים וללא זוג עמודות זהו הוא
דוגמה נניח שיש 3 ביטי יתירות האפשרויות לעמודות של הן
כי . ולכן תיראה ככה
מרחק המינג
מרחק המינג היא בעייה ידועה בעולם האלגוריתמים. נוכל לראות איך היא עוזרת לנו לפתור בעיות הקשורות לקידוד.
משקל המינג:
נגיד משקל המינג של וקטור להיות מספר האחדות שבו. מרחק המינג:
מרחק המינג בין שני וקטורים הוא מספר השורות השונות בינהם. בגלל שאנחנו מעל שדה המודולו 2, ניתן לחשב את הנ״ל על ידי חישוב משקל המינג של .
דוגמה-
עבור יתקיים שמרחק המינג שלהם הוא
הגדרה- המרחק של קוד הוא המרחק המינימלי בין שתי מילות קוד שונות.
טענה 1- בקוד ליניארי המרחק שווה למשקל המינימלי של מילות קוד שאינן וקטור האפס. טענה 2- יהי קוד ליניארי עם מרחק . אם כאשר מספר כלשהו אז יצליח לזהות שגיאות ולתקן שגיאות אמ״מ אין ב המטריצה שהמילות החוקיות שייכות למרחב ה שלה היא מטריצה בלי עמודת 0 ובלי עמודות זהות.
דוגמה-
תהי המטריצה
נחשב את של הקוד שהוא מרחב האפסים של . ונראה כמה שגיאות ניתו להזות ולתקן.
נשים לב שסכימה של העמודות תניב כלומר יש וקטור ששייך למרחב האפסים של (כלומר הוא מילת קוד) והוא
המשקל של וקטור זה הוא ולכן . לפי הטענה הקודמה אנחנו יודעים ש אמ״מ אין במטריצה עמודת אפסים או עמודות זהות וזה בידיוק המצב אצלנו לכן . כלומר במצב זה ניתן לזהות עד שתי שגיאות ולתקן שגיאה אחת.
כיצד מתקנים שגיאה?
נניח ואירעה שגיאה אחת בידיוק במילת קוד . כפי שאמרנו התוצאה שנקבל היא העמודה ה של ולכן נוכל לדעת שהשגיאה קרתה בסיבית ה של וכדי לתקן נוכל פשוט להחזיר לצד המקבל את
קידוד פולינומי
נעסוק כעת בחוג הפולינומים מעל . איבר בחוג נראה ככה
כאשר המקדמים הם בינאריים.
נתרגם בין וקטורים בינאריים לפולינומים וההיפך לפי המקדמים למשל
כלומר מידע הוא מחרוזת בינארית שמתורגמת לפולינום כזה. אם מעבירים ביטים של מידע אז דרגת פולינום המידע היא .
משפט : יהי פולינומים מעל אזי קיימים פולינומים יחידים כך ש
ומתקיים .
תהליך הקידוד הפולינומי
יהי פולינום מדרגה ( מייצג את אורך היתירות) ויהי פולינום מידע ומדרגה חסומה .
נחשב
כדי להזיז את המידע ביטים בשביל לתת מקום ליתירות.
נחלק
היתירות היא שארית החלוקה כלומר היתירות יחידה. סך הכל המילה היא
טענה: מילים הן חוקיות אמ״מ הן מתחלקות ב . הוכחה-
דוגמה:
קודים ציקליים
יהי וקטור בינארי הזזה ציקלית שלו היא .
קוד נקרא ציקלי אם כל הזזה ציקלית של מילה חוקית היא גם מילה חוקית.
למה צריך קוד ציקלי?
היתירות עבור כל מילה היא ייחודית. ולכן כל שגיאה תהפוך את היתירות להיות יתירות שלא מתאימה למילה. מכיוון שניתן לעשות הזזות בקוד ציקלי נוכל להעביר את 𝑚 הביטים עם הטעות להיות ביטי היתירות וכך נוכל לזהות שישנה שגיאה.
למשל:
עבור הזזה ציקלית אחת תביא אותנו ל ומתקיים
נשים לב
לא מבצעים את ההזזות בפועל כי כשנגדיל את הפולינומים יהיו המון הזזות ונרצה דרך שונה לבדוק האם מילה היא חוקית או לא. אנחנו רק הוכחנו שאם ההזזה תביא למילה לא חוקית אז ניתן לזהות שגיאות.
טענה: עבור קוד ציקלי ומילה חוקית נניח ש התקבלה על ידי טעויות בטווח של ביטים. אזי איננה חוקית. הוכחה- נב״ש ששתיהן חוקיות, נבצע הזזות של ו כך שכל השגיאות ב יהיו ב הביטים האחרונים. נקבל שתי מילים חוקיות הנבדלות רק ביתירות, בסתירה .
טענה: הכפלה של פולינום ב שקולה לביצוע shift על המחרוזת הבינארית.
הזזה ציקלית באופן אלגברי
נתאר את פעולת ההזזה הציקלית באופן אלגבי: .
אם אז ההזזה היא ומתקיים .
אם אז , יש מיותר וחסר אחד ולכן ההזזה הציקלית הנכונה היא .
משפט: יהי מדרגה ונביט בקידוד של ביטי מידע. נסמן ויתקיים
הקוד ציקלי אמ״מ מחלק של